

本文主要内容如下:
- Paxos协议,以及在Zookeeper上的应用。
- Zookeeper原理,包括集群结构、特性等。
- Zookeeper的设计,包括QuorumPeer模型、leader选举、lead流程、followLeader流程、广播模式
Zookeeper写请求处理
1 Paxos
Zookeeper不管是leader选举,还是广播模式使用的都是paxos协议,确切来说是paxos协议的变种,所以我们首先了解一下Paxos。
1.1 分布式系统数据一致性问题
在基于消息投递的分布式系统中,可能存在参与者处理速度非常慢,宕机、重启、网络不稳定等的问题,从而导致消息可能会延迟、丢失或者重复。Paxos就是要解决分布式系统在上述任意异常情况下均能保持一致性的一个协议。
需要说明的是,此协议假设消息投递过程中不存在拜占庭问题,即消息不会出错。
1.2 故事
Lamport是通过故事的方式提出Paxos,故事如下;希腊岛屿Paxon 上的执法者(legislators)在议会大厅(chamber)中表决通过法律,并通过服务员传递纸条的方式交流信息,每个执法者会将通过的法律记录在自己的账目(ledger)上。问题在于执法者和服务员都不可靠,他们随时会因为各种事情离开议会大厅,并随时可能有新的执法者进入议会大厅进行法律表决,使用何种方式能够使得这个表决过程正常进行,且通过的法律不发生矛盾。
1.3 语义定义
1.3.1 角色
算法中的参与者主要分为三个角色,同时每个参与者又可兼领多个角色。
- Proposer
提案提出者。提出提案,提案信息包括提案编号和提议的value。 - acceptor
提案接受者。收到提案后可以接受提案。 - learner
提案学习者。只能"学习"被批准的提案,即获取被批准的提案。
1.3.2 基本语义
决议(value)只有在被proposers提出后才能被批准,未经批准的决议称为"提案(proposal)"。
在一次Paxos算法的执行实例中,只批准(chosen)一个value。
learners只能获得被批准(chosen)的value。
1.3.3 决议过程
通过一个决议分为两个阶段:Prepare阶段、Accepet阶段
1.3.3.1 prepare阶段
当Porposer希望提出方案V1,首先发出prepare请求至大多数Acceptor。Prepare请求内容为序列号;
当Acceptor接收到prepare请求时,检查自身上次回复过的prepare请求
- 如果SN2>SN1,则忽略此请求,直接结束本次批准过程;
- 否则检查上次批准的accept请求<SNx,Vx>,并且回复<SNx,Vx>;如果之前没有进行过批准,则简单回复;
1.3.3.2 accept阶段
Porposer经过一段时间,收到一些Acceptor回复,回复可分为以下几种:
回复数量满足多数派,并且所有的回复都是,则Porposer发出accept请求,请求内容为议案<SN1,V1>;
回复数量满足多数派,但有的回复为:<SN2,V2>,<SN3,V3>……则Porposer找到所有回复中超过半数的那个,假设为<SNx,Vx>,则发出accept请求,请求内容为议案<SN1,Vx>;
回复数量不满足多数派,Proposer尝试增加序列号为SN1+,转1继续执行;
Acceptor在不违背自己向其他Proposer的承诺的前提下,Acceptor收到accept请求后即接受并回复这个请求。
1.3.4 约束
根据上面的三个语义可演化为四个约束。(说明:P1表示prepare阶段;P2表示accept阶段).
- P1
一个acceptor必须接受(accept)第一次收到的提案; - P2a
一旦一个value的提案被批准(chosen),那么之后任何acceptor再次接受的提案必须具有value。 - P2b
一旦一个value的提案被批准(chosen),那么以后任何proposer提出的提案必须具有value。 - P2c
如果一个编号为n的提案具有value v,那么存在一个多数派,要么他们中所有人都没有接受(accept)编号小于n的任何提案,要么他们已经接受(accept)的所有编号小于n的提案中编号最大的那个提案具有value v。
1.4 缺点与简化
1.4.1 缺点
Paxos算法在出现竞争的情况下,其收敛速度很慢,甚至可能出现活锁的情况。例如当有三个及三个以上的proposer在发送prepare请求后,很难有一个proposer收到半数以上的回复,从而导致不断地执行第一阶段的协议。
1.4.2 简化
为了避免竞争,加快收敛的速度,在算法中引入了一个Leader这个角色,在正常情况下同时应该最多只能有一个参与者扮演Leader角色,而其它的参与者则扮演Acceptor的角色,同时所有的人又都扮演Learner的角色。
Multi-Paxos协议是经典的Paxos协议的简化版本,有谷歌公司的工程师所提出。二者最大的差别是Multi-Paxos包含有leader节点而Paxos没有。像chubby、zookeeper、megastore、spanner等中间件都是使用Multi-Paxos。
Multi Paxos先运行一次完整的paxos算法选举出leader,有leader处理所有的写请求,然后省略掉prepare过程。并由这个Leader唯一地提交value给各Acceptor进行表决。
2 Zookeeper原理
2.1 角色
| 角色 | 描述 |
|---|---|
| Leader | 主要负责投票的发起和决议;系统状态更新 |
| Learner-Follower | 参与投票过程,写请求转发给leader;接收客户端连接 |
| Learner-Observer | 不参与投票过程,写请求转发给leader;接收客户端连接。增加系统扩展性、读性能。 |
| Client | 请求发起方 |
Leader将状态变化发送给follower和observer。写操作的吞吐率取决于仲裁数量的大小,更大的仲裁数量,将导致更小的写操作吞吐率。引入observer的一个主要原因是提高读请求的扩展性,Observer不参与投票过程,所以对于写操作没有开销,同时因为保持和leader同步,所以可以支持更多读请求。
2.2 集群结构
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TbAN74WE-1624859190341)(img/Zookeeper原理/集群结构.png)]
注:此图来自网络。
2.3 特性
- 最终一致性
client不论连接到哪个Server,展示给它都是同一个视图,这是zookeeper最重要的性能。 - 可靠性
具有简单、健壮、良好的性能,如果消息m被到一台服务器接受,那么它将被所有的服务器接受。 - 实时性
Zookeeper保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息。但由于网络延时等原因,Zookeeper不能保证两个客户端能同时得到刚更新的数据,如果需要最新数据,应该在读数据之前调用sync()接口。 - 等待无关(wait-free):
慢的或者失效的client不得干预快速的client的请求,使得每个client都能有效的等待。 - 原子性
更新只能成功或者失败,没有中间状态。 - 顺序性
包括全局有序和偏序两种:全局有序是指如果在一台服务器上消息a在消息b前发布,则在所有Server上消息a都将在消息b前被发布;偏序是指如果一个消息b在消息a后被同一个发送者发布,a必将排在b前面。
2.4 原子广播协议(ZAB)
Zookeeper通过ZAB保证多个server之间的数据同步。
Zab协议分为:恢复模式(选主)和广播模式(同步)。当服务启动或者在leader崩溃后,Zab就进入了恢复模式,当leader被选举出来,且大多数Server完成了和leader的状态同步以后,恢复模式就结束了,接下来就进入广播模式。
3 Zookeeper设计
本部分将简要介绍Zookeeper的实现原理,详细内容见其他博客。
3.1 QuorumPeer模型
QuorumPeer是zookeeper server的核心,主要负责以下内容:
- 初始化状态时LOOKING,所以首先进行Leader选举,这其实算是加入集群的动作。
- 选Leader技术以后,确定出自己是follower或者leader;不同的角色分别执行不同的业务流程。
- 退出followLeader流程或lead流程时,状态会被置成LOOKING,即新一轮的循环再次开始。
3.2 leader选举
此图是简化的选举流程,只是用来标明主要过程,详细流程参考博客。
选举过程其实是Paxos协议执行的过程,选主过程如下:
- 自增logicalclock(也称之为electionEpoch),更新提议的proposal(第一次是提议自己为leader)。
- 发送选票信息给集群的其他acceptor。
- 收集并统计acceptor的回复结果。这个过程首先解决electionEpoch、zxid、提议leader的冲突,原则上选择大者作为下次提议的信息。
- 从统计结果中判断是否已经选出leader;如果没有选出或者如果已经选出leader但在判断leader是否有效时发现leader无效,则继续重复“发(更新后的)选票信息给其他acceptor” 步骤;否则说明leader已经选出,更新自己的状态,退出选举流程。
3.3 Lead流程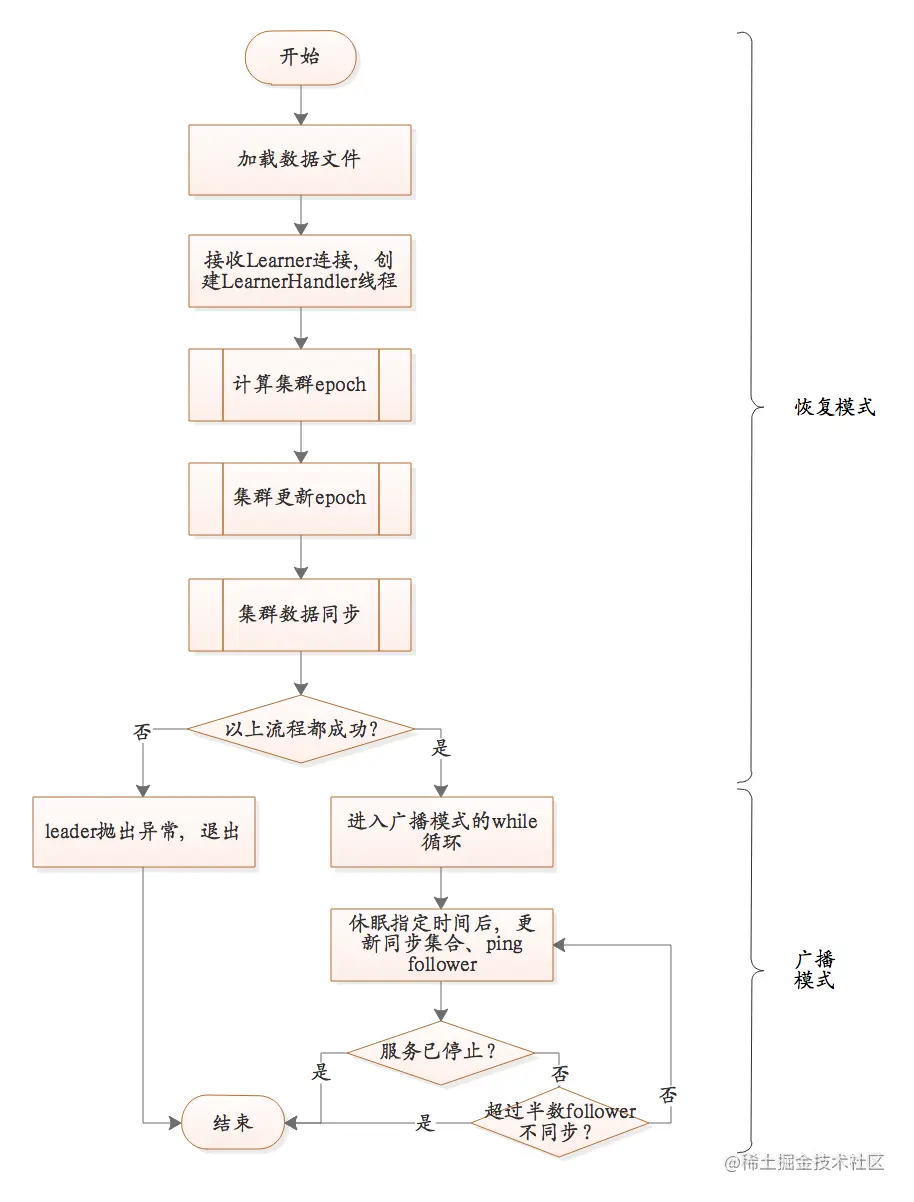
如图所示,leader主要负责以下内容:
- 为每一个follower、Observer创建LearnerHandler线程,处理于此服务器的所有交互。
- 确保收到超过半数服务器的acceptedEpoch,用于计算出集群新的epoch,否则退出lead流程。
- 确保超过半数的服务器的已经epoch更新事件,以保证整个集群多数派的epoch已经一致;否则退出lead流程。
- 确保超过半数的服务器已经和leader中已提交的数据同步了,以保证整个集群多数派处于一致状态,否则退出lead流程。
- 进入广播模式,接收请求,发出提议,统计并处理提议。
3.4 followLeader流程
如图所示,follower主要负责以下内容:
- 连接leader。
- 告知leader自己之前的AcceptedEpoch,以便于leader计算新集群的epoch
- 告知leader自己已经更新了epoch,以便于leader确认集群多数派的epoch已经统一。
- 从leader同步已经提交的提议,保持自己与leader同步。
- 进入广播模式,转发写请求到leader,接收提议、回复提议,提交提议等。
3.5 Leader广播模式
如上图所示,leader在广播模式下承担的职责主要包括:
- 接收写请求,然后将写请求作为提议发给acceptor(这里指的是follower)
- 接收follower对提议的回复信息,然后统计回复结果,发送commit给follower,通知observer提议已经committed。
- 接收心跳维护信息,延长与follower的session。
- 验证session有效性
3.6 follower广播模式
如上图所示,follower在广播模式下承担的职责主要包括:
- 接收leader的提议信息,回复leader。
- 接收leader的commit提议消息。
- 接收心跳维持信息,发送心跳给leader。
- 验证session有效性
- 接收sync消息,主动从leader同步消息,以保证客户端获取的信息时最新的。
4 Zookeeper请求的处理
Zookeeper在是现实使用的主要抽象概念是请求处理器,请求处理器是对不同阶段处理过程的一个抽象,每个服务器注册了一个不同的请求处理器序列。
4.1 请求模型
此图来自Zookeeper官网文档,表示请求过程。所有的写请求都通过ZAB协议保持集群数据一致性。
4.2 leader
4.2.1 注册RequestProcessor链示例代码
4.2.1.1 LeaderZooKeeperServer#setupRequestProcessors
protected void setupRequestProcessors() {
RequestProcessor finalProcessor = new FinalRequestProcessor(this);
RequestProcessor toBeAppliedProcessor = new Leader.ToBeAppliedRequestProcessor(
finalProcessor, getLeader().toBeApplied);
commitProcessor = new CommitProcessor(toBeAppliedProcessor,
Long.toString(getServerId()), false,
getZooKeeperServerListener());
commitProcessor.start();
ProposalRequestProcessor proposalProcessor = new ProposalRequestProcessor(this,
commitProcessor);
proposalProcessor.initialize();
firstProcessor = new PrepRequestProcessor(this, proposalProcessor);
((PrepRequestProcessor)firstProcessor).start();
}
4.2.1.2 ZooKeeperServer#setupRequestProcessors
protected void setupRequestProcessors() {
RequestProcessor finalProcessor = new FinalRequestProcessor(this);
RequestProcessor syncProcessor = new SyncRequestProcessor(this,
finalProcessor);
((SyncRequestProcessor)syncProcessor).start();
firstProcessor = new PrepRequestProcessor(this, syncProcessor);
((PrepRequestProcessor)firstProcessor).start();
}
4.2.2 模型
4.2.3 分析
- PrepRequestProcessor
接受客户端的请求并执行这个请求。 - ProposalRequestProcessor
如果是LearnerSyncRequest,表明是leader做为server提供给客户端服务,并且接受到客户端的sync请求。
如果不是是LearnerSyncRequest,则认为是需要进行投票决策,所以将request发送给leader,接着会发送给所有的follower进行投票。注意:请求可能来自于follower转发给leader的写请求,也可能是leader收到client的写请求
通过SyncRequestProcessor写request持久化到本地磁盘。
示例代码如下:
public void processRequest(Request request) throws RequestProcessorException {
/* In the following IF-THEN-ELSE block, we process syncs on the leader.
* If the sync is coming from a follower, then the follower
* handler adds it to syncHandler. Otherwise, if it is a client of
* the leader that issued the sync command, then syncHandler won't
* contain the handler. In this case, we add it to syncHandler, and
* call processRequest on the next processor.
*/
if(request instanceof LearnerSyncRequest){
zks.getLeader().processSync((LearnerSyncRequest)request);
} else {
nextProcessor.processRequest(request);
if (request.hdr != null) {
// We need to sync and get consensus on any transactions
try {
zks.getLeader().propose(request);
} catch (XidRolloverException e) {
throw new RequestProcessorException(e.getMessage(), e);
}
syncProcessor.processRequest(request);
}
}
}
- CommitProcessor
做为leader时,会在收集足够的Vote后,自己会给自己发送一次sync指令。
做为Follower时,会受到Leader发送的Sync指令,然后自己提交commit动作。 - Leader#ToBeAppliedRequestProcessor
记录当前正在提交到zkDatabase中的request数据,保证新的Follower连接上来时,能获取到这些处于内存中"正准备提交"的数据 - FinalRequestProcessor
处理最后的请求。如读/写请求,此时所有的server都会同步的写入数据。 - SyncRequestProcessor
负责把写request持久化到本地磁盘,为了提高写磁盘的效率,这里使用的是缓冲写,但是会周期性(1000个request)的调用flush操作,flush之后request已经确保写到磁盘了,这时会把请求传给AckRequestProcessor继续处理 - AckRequestProcessor
负责在SyncRequestProcessor完成事务日志记录后,向Proposal的投票收集器发送ACK反馈,以通知投票收集器当前服务器已经完成了对该Proposal的事务日志记录。
4.3 follower
4.3.1 注册RequestProcessor链示例代码
FollowerZooKeeperServer#setupRequestProcessors如下所示:
protected void setupRequestProcessors() {
RequestProcessor finalProcessor = new FinalRequestProcessor(this);
commitProcessor = new CommitProcessor(finalProcessor,
Long.toString(getServerId()), true,
getZooKeeperServerListener());
commitProcessor.start();
firstProcessor = new FollowerRequestProcessor(this, commitProcessor);
((FollowerRequestProcessor) firstProcessor).start();
syncProcessor = new SyncRequestProcessor(this,
new SendAckRequestProcessor((Learner)getFollower()));
syncProcessor.start();
}
4.3.2 模型
4.3.3 分析
- FollowerRequestProcessor
客户端接受请求后,针对一些写动作(如create,delete,setData,setAcl等),FollowerRequestProcessor会发起一个request,将写请求全部转发到leader,同时会将request请求递交到commitProcessor。 - CommitProcessor
见leader中的介绍 - FinalRequestProcessor
见leader中的介绍 - SyncRequestProcessor
见leader中的介绍 - SendAckRequestProcessor
为proposal发送一个ack给leader
5 博客
我的相关博客
ZAB协议恢复模式-数据同步
本文参考内容
Paxos算法与Zookeeper分析
blog.csdn.net/xhh198781/a…
Paxos 算法
baike.baidu.com/item/Paxos%…
- List item
