

{{ title }}
1,前言
前面我通过r.text把网页进行打印,输出,结果很好,我们都成功了
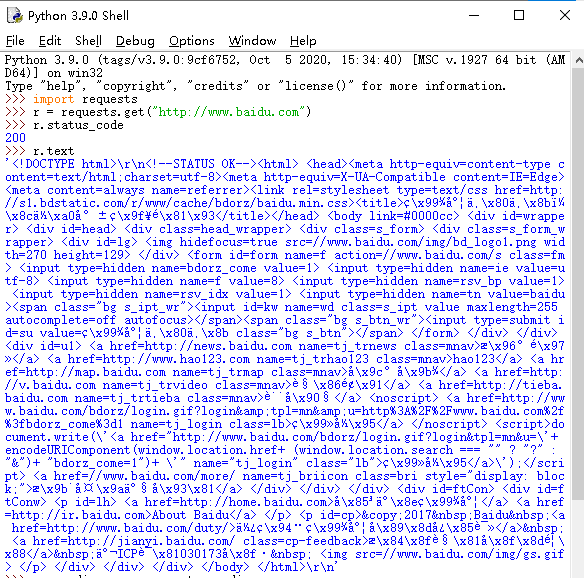
当然还有utf-8编码形式
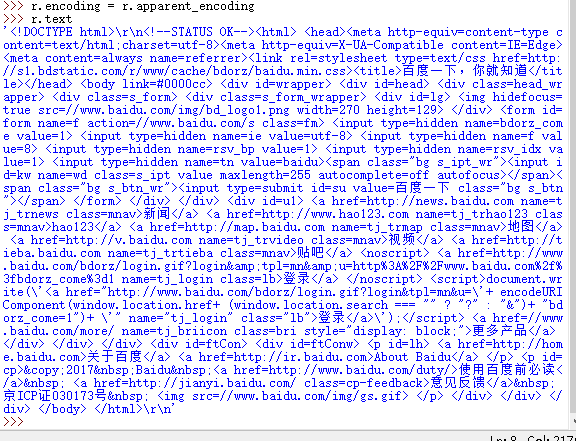
虽然在utf-8编码形式下可以看到一些文字,增加了阅读体验,但是我想问问还有没有更好的方法增加阅读体验
答案是肯定有的,我们一起来看看吧。
2,BeautifulSoup库的安装
2.1,官网介绍
[这是BeautifulSoup库的官网](Beautiful Soup: We called him Tortoise because he taught us. (crummy.com))
都是英文,反正我是看不懂,不看
人称外号“美味汤”,当然这是第三方库了。它可以解析HTML格式进行解析、提取相关信息。它的使用原来就是把你给的文本变成一锅汤,进行煲制,怪不得叫美味汤呢
2.2,安装
这个很简单吧,直接上代码
pip install BeautifulSoup4
即可进行安装。
2.3,测试
2.3.1,分析网页
安装成功了吗。我们测试一下不就知道了吗。
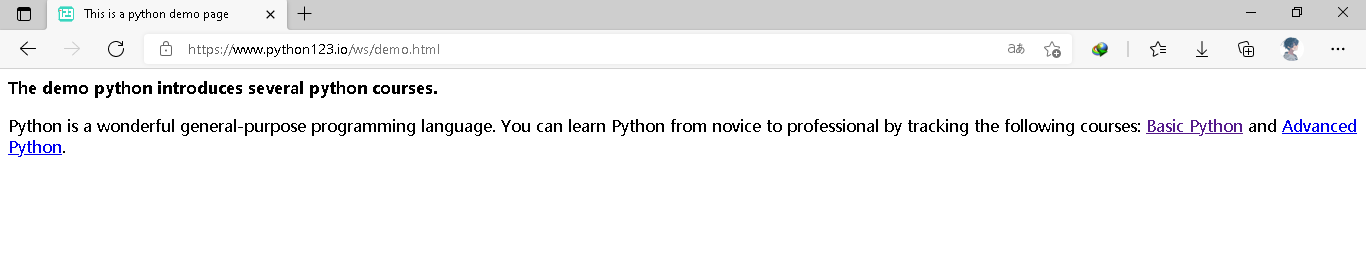
我们再看一下他的源代码
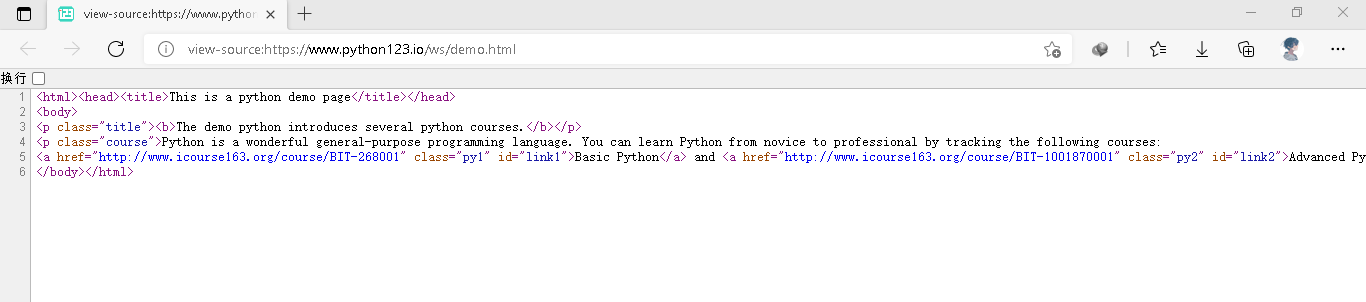
这应该就是前端知识吧HTML
是以<>为主所封装的一对信息。
2.3.2,实践
好!一切准备就绪,打开idle
-
获取源代码
获取源代码有两种方式
-
手动获取:如果是edge浏览器在当前页面Ctrl+U即可,之后你会发现就是上面的那张图
-
.get()方法我们应该学以致用,试试吧
>>> import requests >>> r = requests.get("https://www.python123.io/ws/demo.html") >>> r.status_code 200 >>> r.text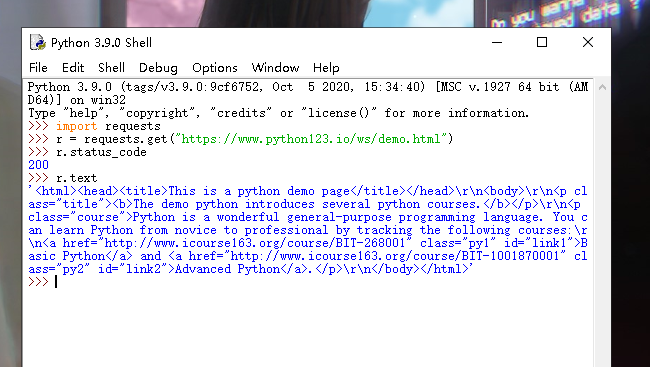
是不是很简单
-
-
BeautifulSoup库导人
定义一个demo变量
>>> demo = r.text导入库
>>> from bs4 import BeautifulSoup因为库名太长,所以我们用bs4来表示,因此
from bs4导入了一个类叫BeautifulSoup -
做汤
我们需要吧demo也面做成一个BeautifulSoup可以理解的汤
>>> soup = BeautifulSoup(demo, "html.parser") -
打印输出
>>> print(soup.prettify())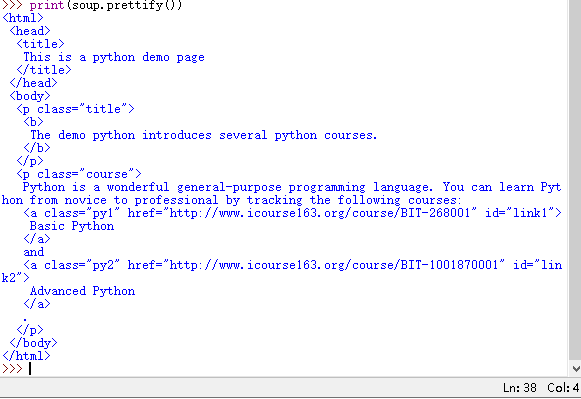
是不是比之前的好看多了
到这里,我们的BeautifulSoup4库也安装成功了。
2.3.3小结
怎么使用BeautifulSoup库呢,只需要两行代码
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup("<p>data</p>", "html.parser")
bs4导入BeautifulSoup类
我们做汤,用一个变量。里面有两个变量
-
"<p>data</p>":需要解析的信息 -
"html.parser":解析HTML时需要用到的解析器
3,BeautifulSoup库的基本元素
前面我们说是测试,实际上也算是一个小实例理解了BeautifulSoup库的原理,”熬汤“
那我们再来深入了解一下这个库
3.1,BeautifulSoup库的理解
-
理解这个,我们先了解一下什么是HTML文件
HTML文件打开会发现是以一对<>成对出现的,一组<>构成的标签组织起来的。标签之间存在上下级关系形成标签数。
可以说BeautifulSoup库是解析、遍历、维护“标签树”的功能库。
只要我们的文件是“标签树”类型,那么BeautifulSoup库都可以解析。
-
标签格式
理解了什么是HTML文件,那么每一个标签的具体格式又知多少
<p class="title"> .... </p>以p标签为例
-
首先可以看到是一对<>形成的。
-
<p>..</p>:标签 tag;p是标签的名称 name;在最开始和最后出现,表明这一个标签的范围。 -
class="title":属性域,包含0个或多个属性。属性是用来定义这个标签的特点的,class:属性名title:属性里的内容
任何一个属性都有它的特性和它的值,使用可以说属性是由键值对构成的 这样是不是明白了一些
-
3.2,BeautifulSoup库的导入
-
BeautifulSoup库,也叫 BeautifulSoup4或bs4
使用应该采用一些引用方式
-
常见方式
from bs4 import BeautifulSoup这个在前面我们就用过
从bs4库中引入了一个类型,这个类型叫BeautifulSoup
-
传统方式
import bs4这个使用起来比较广。
-
3.3,BeautifulSoup类
首先HTML文档与标签树是一一对应的,标签树经过BeautifulSoup类处理,标签树转换成eautifulSoup类。因此可以理解为BeautifulSoup类型可以代表标签树。
综上所述:html、标签树和BeautifulSoup类三者等价。
在这个基础上,通过BeautifulSoup类使得标签树形成一个变量,而对变量的处理就是对标签树的处理。
BeautifulSoup对应一个HTML/XML文档的全部内容
3.4,BeautifulSoup库解析器
前面提过解析器的作用,解析HTML/XML文档。当然
| 解析器 | 使用方法 | 条件 |
|---|---|---|
| bs4的HTML解析器 | BeautifulSoup(mk, "html.parser") | 安装bs4库 |
| lxml的HTML解析器 | BeautifulSoup(mk, "lxml") | pip install lxml |
| lxml的XML解析器 | BeautifulSoup(mk, "xml") | pip install lxml |
| html5lib解析器 | BeautifulSoup(mk, "html5lib") | pip install html5lib |
这里无论解析HTML/XML以上四种都可以,那还是有区别的如果有较高的体验,所以就
3.5,BeautifulSoup类的基本元素
| 基本元素 | 说明 |
|---|---|
| Tag | 标签,最基本的信息组织单元,分别用<>和</>标明开头和结尾。 |
| Name | 标签的名字,<p>...</p>的名字是“p”,格式:<tag>.name |
| Attributes | 标签的属性,字典形式组织,格式:<tag>.attrs |
| NavigableString | 标签内非属性字符串,<>...</>中字符串,格式:<tag>.string |
| Comment | 标签内字符串的注释部分,一种特殊的Comment类型 |
看的是不是眼花缭乱,好,我们照着敲一下,
在此把源代码放出来,咱们对照着敲:
-
tag标签
>>> soup.title<title>This is a python demo page</title>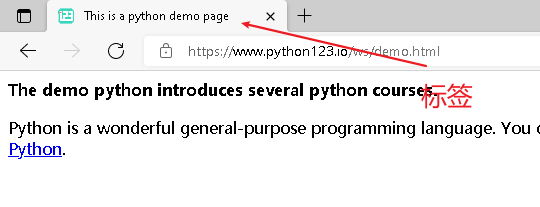 看标签就这样出来了。
看标签就这样出来了。 -
获取链接标签的内容
定义一个标签,获取HTML
<a>...</a>标签的内容,也就是链接标签的内容。>>> tag = soup.a>>> tag<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>
可以看到,
<a>...</a>标签内容输出了出来我怎么发现这里面还有
<a>...</a>标签 -
标签的名字
>>> soup.a.name'a'我们知道这个标签就是a,所以
soup.a.name如果不知道这个标签名字呢?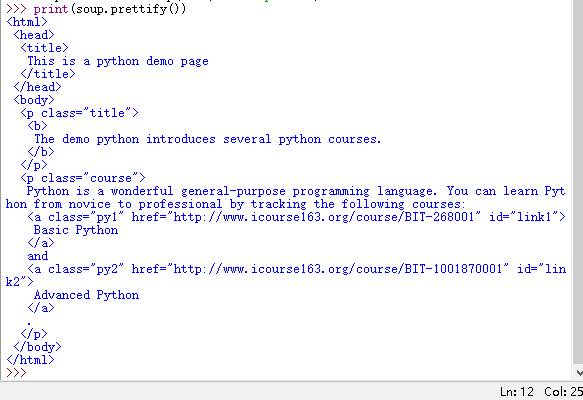
这里我们引出几个名字,子标签,父标签,爷······
查看
<a>....</a>的父标签,上一层标签>>> soup.a.parent.name'p'>>> soup.a.parent.parent.name'body'<p>..</p>是父标签,<body>..</body>是<p>..</p>的父标签,打印出来是字符串类型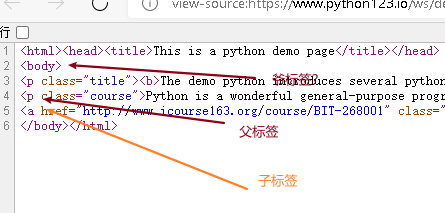
-
标签的属性信息
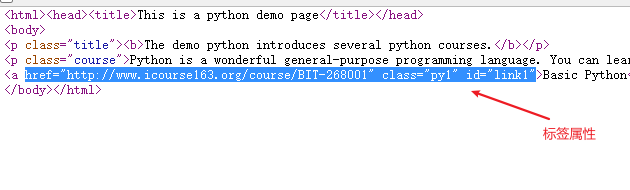
以
<a>..</a>为例>>> tag = soup.a>>> tag.attrs{'href': 'http://www.icourse163.org/course/BIT-268001', 'class': ['py1'], 'id': 'link1'}以字典形式出现
当然我们还可以对里面的信息进行提取
>>> tag.attrs['class']['py1']>>> tag.attrs['href']'http://www.icourse163.org/course/BIT-268001'>>> tag.attrs['id']'link1' -
标签的NavigableString元素
这是个字符串类型,表现的是尖括号标签之间的字符串
>>> soup.a<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>>>> soup.a.string'Basic Python'>>> soup.p<p class="title"><b>The demo python introduces several python courses.</b></p>>>> soup.p<p class="title"><b>The demo python introduces several python courses.</b></p>>>> soupp.p.string -
Comment类型
表格中说到,这是注释的意思,如果HTML页面中出现注释,该怎么处理。
我们重新做一锅汤
>>> newsoup = BeautifulSoup("<b><!--This is a comment--></b><p>This is not a comment</p>", "html.parser")>>> newsoup.b.string'This is a comment注意:
<!--...-->里的内容是注释,所以<p>...</p>里的不是注释。 好!到这里这一小部分就结束了。我们做个复盘,看图片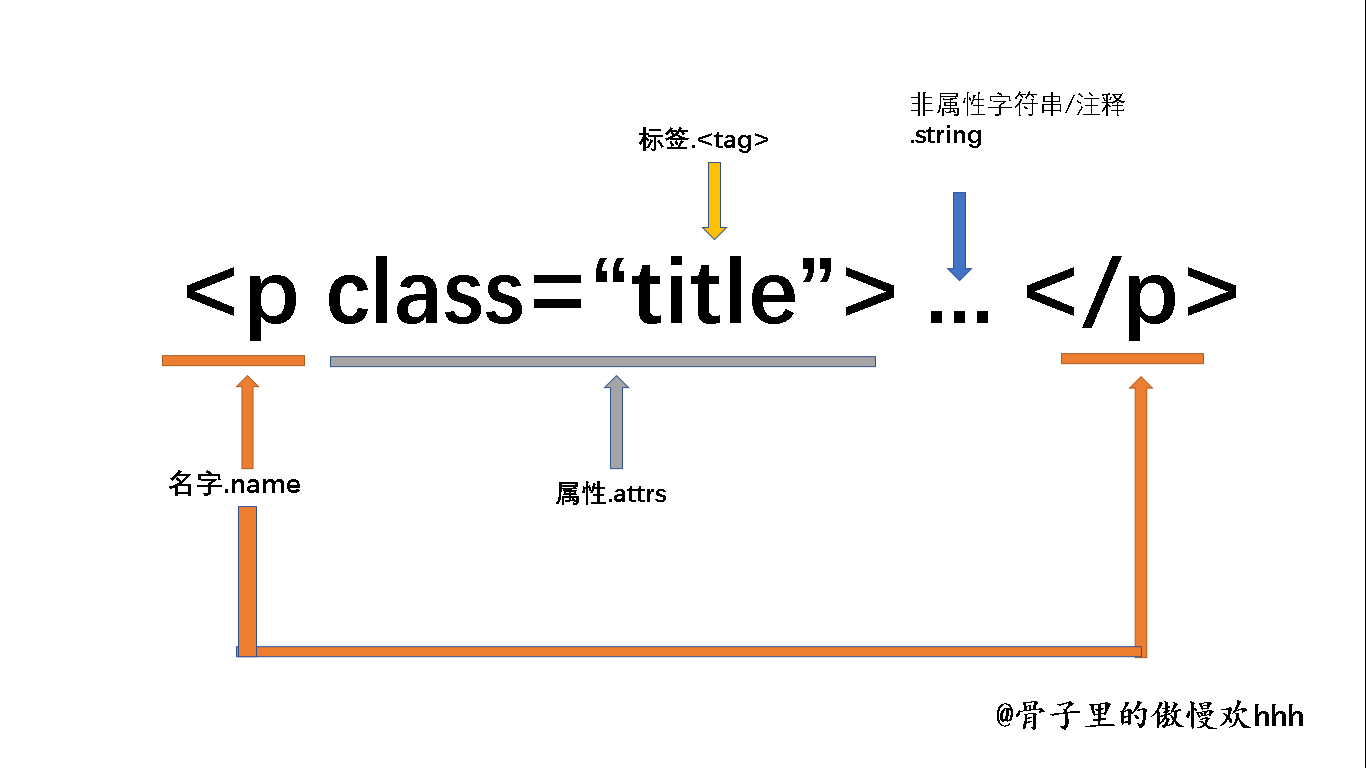
4,基于bs4库的HTML内容遍历方法
我们前面学习了如何整理HTML文本,变成一个树型结构。可以看到有很多标签,并且标明了标签与标签之间的关系。但还是有一些不方便看,我们把它换一种形式体现
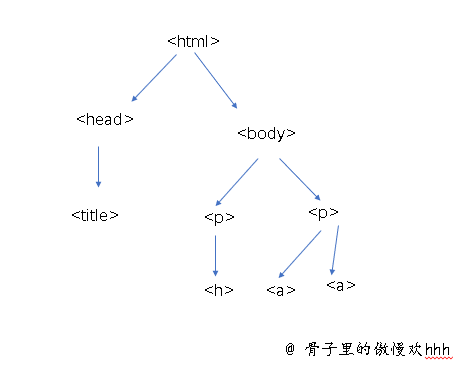
注意:<p>...</p>下的<h>...</h>应该是<b>...</b>,以下不在标注
注意:<p>...</p>下的<h>...</h>应该是<b>...</b>``,以下不在标注** **注意:
...
下的...应该是...``,以下不在标注
这是又一次整理之后的。是不是
我们把标签有称作节点。然鹅,我们可以进行遍历,有三种方式
- 下行遍历:从根节点向叶子节点方向遍历
- 上行遍历:和下行遍历相反,从叶子节点向根节点方向遍历。
- 平行遍历:互相遍历方式,平级
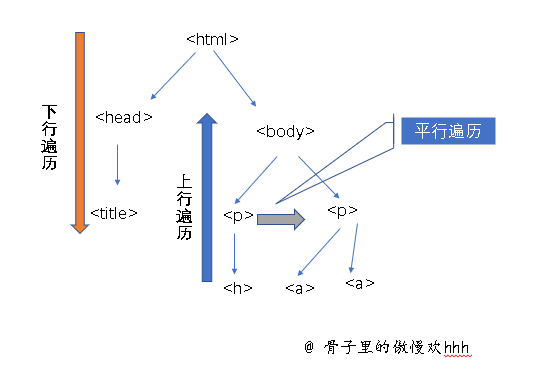
所以这段内容很容易理解。
同时他们有不同的遍历 方法,我们分别看一下哈
4.1,标签树的下行遍历
| 属性 | 说明 |
|---|---|
| .contents | 子节点的列表,将<tag>所有儿子节点存入列表。 |
| .childrea | 子节点的迭代类型,与.contets类似,用于循环遍历儿子节点 |
| .descendans | 子孙节点的迭代类型,包含所有子孙节点,用于循环遍历 |
我们分别对以上三种进行举例:
-
.contents我们看
<head>...</head>标签的儿子节点>>> soup.head.contents[<title>This is a python demo page</title>]是
<title>...</title>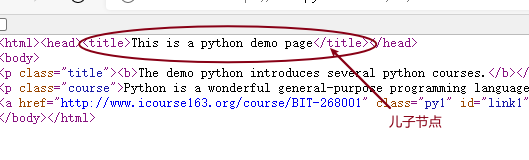
我先把这里理明白,下面怎么有点慢,
.contents是返回他的子节点,不包括儿子节点。由于返回的是列表信息,我们可以对信息进行检索
我们看一下
<body>...</body>下的.contents信息>>> soup.body.contents['\n', <p class="title"><b>The demo python introduces several python courses.</b></p>, '\n', <p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>, '\n']可以看到里面有很多信息,对应body不同元素,
我们注意,对于一个标签儿子节点,并不仅仅包括标签节点,还有字符串节点,
\n也会有。我们可以查看儿子节点数量
>>> len(soup.body.contents)55个
我们还可以进行检索,
>>> soup.body.contents[1]<p class="title"><b>The demo python introduces several python courses.</b></p>嘿嘿
<p>...</p>标签。 -
.childrea当然,我们还可以用这个
>>> for child in soup.body.children: print(child) <p class="title"><b>The demo python introduces several python courses.</b></p><p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>这应该是对
<body>...</body>标签下儿子节点的一个遍历一直有个疑问,为什么还会有a标签,现在懂了,p标签包含a标签
-
.descendans>>> for child2 in soup.body.descendants: print(child2) <p class="title"><b>The demo python introduces several python courses.</b></p><b>The demo python introduces several python courses.</b>The demo python introduces several python courses.<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>Basic Python and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>Advanced Python.一开始有点难理解,这个标签怎么会出现在这里,慢慢对照整理后的结构,有的标签时嵌套在里面的。很简单。
4.2,标签树的上行遍历
只有两个属性
| 属性 | 说明 |
|---|---|
| .parent | 节点的父亲标签 |
| .parents | 节点先辈标签的迭代类型,用于循环遍历先辈节点 |
有木有发现parent是父母的意思。分别看一下
-
.parent我们看一下
<title>...</title>标签的父亲>>> soup.title.parent<head><title>This is a python demo page</title></head>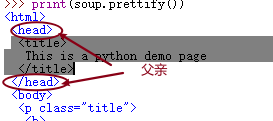
我们看一下
<html>...</html>标签的父亲>>> soup.html.parent<html><head><title>This is a python demo page</title></head><body><p class="title"><b>The demo python introduces several python courses.</b></p><p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p></body></html>因为
<html>...</html>标签在HTML文本中最高级标签,所以<html>...</html>标签的父亲是他自己。soup标签是一种特殊的标签,所以我们也可以进行打印
>>> soup.parent>>>会发现是空的,所以没有
-
.parents>>> for parent in soup.a.parents: if parent is None: print(parent) else: print(parent.name) pbodyhtml[document]这段代码表达什么呢?
对
<a>...</a>标签的所有的先辈的名字进行打印。但是为什么会有if--else语句呢?在遍历一个标签的所有先辈标签时,会遍历到soup本身,而soup里面并没有任何信息,所以就有一个区分,先辈是Name不可以打印。所以,这两个方法很容易理解
4.3,标签树的平行遍历
一共有四个四个属性
| 属性 | 说明 |
|---|---|
| .next_sibling | 返回按照HTML文本顺序的下一个平行节点标签 |
| .previous_sibling | 返回按照HTML文本顺序的上一个平行节点标签 |
| .next_siblings | 迭代类型,返回按照HTML文本顺序的后续所有平行节点标签 |
| .previous_siblings | 迭代类型,返回按照HTML文本顺序的前续所有平行节点标签 |
其实会发现他们是成对出现的,上下,前后
平行遍历还是有条件的:平行遍历发生同一个父节点的各节点间。同一父亲。
-
.next_sibling>>> soup.a.next_sibling' and 'a标签的平行标签是一个字符串,
在标签树中,虽然树型结构采用的是标签形式来组织,但是标签之间NavigableString类型也构成了标签树的节点。也就是说任何一个节点他的平行标签他的父亲标签儿子标签可能存在NavigableString类型,所以不要直接认为我们获得平行遍历的下一个节点就是标签类型
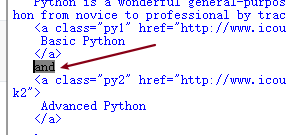
所以,就很形象
我们接着看看a标签的下一个平行标签的下一个平行标签
>>> soup.a.next_sibling.next_sibling<a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a> -
.previous_sibling
我们看一下a标签的前一个平行标签
>>> soup.a.previous_sibling'Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:\r\n'是一段文本
同样,我们对a标签的前一个平行标签的前一个平行标签
>>> soup.a.previous_sibling.previous_sibling>>>返回空,
不难发现a前面是空的,为什么不是右边那个a呢
-
.next_siblings>>> for sibing in soup.a.next_siblings: print(sibing) and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>是不是很熟悉呢。
-
.previous_siblings>>> for sibing in soup.a.previous_siblings: print(sibing) Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:所以就
5,基于bs4库的HTML格式输出
看到格式,我想到了字符串格式化,这里并不是清空的意思,如何让HTML文本更加”友好“的显示呢?
“友好”二字并非是使人们方便阅读,同时还是能被程序更好的读取和分析
5.1,bs4库的prettify()方法
我们来看一段代码:
>>> from bs4 import BeautifulSoup>>> soup = BeautifulSoup(demo, "html.parser")>>> soup.prettify()
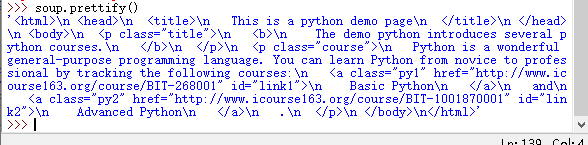
我们会发现有很多换行符,我们在打印出来。
>>> print(soup.prettify())
这样变得更加清晰,当然,这张图并不陌生。
所以
prettify():这个方法可以为HTML文本增加换行符,时它变得更加直观,也可以对每一个标签进行相关的处理。
比如我们打印soup中的<a>...</a>标签
>>> print(soup.a.prettify())<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1"> Basic Python</a>
在bs4库中有一个很重要的问题,就是编码, 在bs4库中将任何读入的HTML文件或字符串都转换成了utf-8编码。因此在做解析时,并没有什么障碍。
6,总结
还记得前一章requests库吗,将的应该是如何获取源代码,对URL进行增删改查,我们这里重点说获取源代码,有源代码后你会发现不便于阅读,所以我觉得这一章更重要的讲述对源代码怎么更好的阅读,解析器。同时还有一些操作。
这就是以上内容,我的笔记。
谢谢您的,如果文章有错误,欢迎你的指正;如果对您有帮助,是我的荣幸。
