

Dask
随着数据科学领域的迅速发展,处理大规模数据集已成为日常任务的一部分。
传统的数据处理库,如NumPy和Pandas,在单机环境下表现出色,但当数据集超出内存容量时,它们就显得力不从心。
Dask应运而生,作为一个开源的并行计算库,Dask旨在解决这一问题,它提供了分布式计算和并行计算的能力,扩展了现有Python生态系统的功能。
1/什么是dask
dask是一个python编写的,灵活的大数据并行计算库(框架),
是一个比spark更轻盈的分布式计算框架,
能在分布式集群中进行分布式并行计算,也可以在单机(多核心)中进行伪分布式并行计算。
dask是一个开源项目,提供了Numpy数组,pandas dataframe以及常规list的抽象。
与spark这些大数据处理引擎(框架)相比较,dask更轻。
dask更侧重与其他库(比如numpy,pandas,Scikit-learn)相结合来使用,
从而使这些库能更加方便进行分布式并行计算,变得更加强大。
目前dask支持5种主要的数据结构,分别是:
Array(用于存放类numpy的多维数组),
DataFrame(不用多说,类pandas的二维表结构的数据帧),
Bag(更简单的一个数组),
Delayed(对函数的异步处理封装,针对本地多进程与多线程),
Futures(对函数的分布式异步提交处理封装,比delayed多提供网络api)。

2/dask由两部分组成:
<1>针对计算优化的动态任务调度。
这与Airflow,Luigi,Celery或Make类似,但针对交互式计算工作负载进行了优化。
<2>“大数据”集合,像并行数组,数据框和列表一样,
它们将通用接口(如NumPy,pandas或Python迭代器)扩展到大于内存或分布式环境,
这些并行集合运行在动态任务调度器之上。
3/dask计算环境可以分为以下2类:
<1>单节点的伪分布式环境
单机模式,single-machine,多个核心
Dask单机调度程序利用笔记本电脑或大型工作站的全部CPU功率,
并将空间限制从“适合内存”更改为“适合磁盘”。
这个调度程序使用简单,没有大多数“大数据”系统的计算或概念开销。
<2>多节点的分布式集群并行环境
dask分布式调度程序协调集群中多台机器的操作。
它可以在任何地方从一台机器扩展到一千台机器,但不会超越其他机器。
单机调度程序对更多个人有用,分布式机器调度程序对大型机构,研究实验室或私人公司很有用。
4/dask存在三种最基本的数据结构
分别是:Arrays、DataFrame以及Bags。
这里详细介绍基于pandas Dataframe 改进的 Dask Dataframe数据结构。
dask Dataframe是基于pandas Dataframe改进的一个可以并行处理大数据量的数据结构,
即使对大于内存的数据也是能够处理的。
一个Dask Dataframe对象是由多个更小的pandas DataFrame对象组成的,以索引折分。
Dask DataFrame在单台机器上可进行大于内存的计算,也可运行在集群中,将空间限制由内存扩展为硬盘。
Dask DataFrame以行进行分区。

Dask DataFrame对象可通过多种方式创建,
我们以dask.dataframe.read_csv()创建方式为例(读取数据的时候,直接为dask dataframe结构)
来解析一下dask dataframe对象是如何进行分区的。
通过Dask DataFrame内置方法对每个文件进行一行一行的块划分,注意这里返回的是Delayed对象。
5/dask为什么可以处理超过内存大小的数据量?
其实dask并没有真正的把所有分块后的数据读入内存,
只是在内存中存放了一个指针,该指针指向了这些数据块,
这里涉及一个重要概念--Delayed(延迟计算)
6/dask dataframe 和 pandas dataframe的对比
下面的左图我们发现:
import dask.dataframe as dd
在通过dd.read_csv(file,npartitions=n)函数读取文件创建Dask DataFrame对象的速度是非常快的。
在执行append()函数时,速度也是很快的。
下面的右图我们发现:
import pandas as pd
pd.read_csv(file)函数在读取相同数据时要慢得多,在执行merge()操作时还会因内存不足导致无法执行。

7/什么场景下使用Dask DataFrame?
pandas dataframe主要适用于小数据量的数据,在内存中计算很快。
当数据量比较大的时候,数据不能完全放在内存中的时候,我们可以考虑使用dask dataframe
Dask DataFrame复制了大部分pandas DataFrame常用的API,切换无障碍。
8/Dask DataFrame API
Dask DataFrame复制了pandas dataframe 的常用方法,Dask DataFrame API是pandas API的子集
虽然很多pandas dataframe的函数可以被dask dataframe使用,
但是还是有一些函数,dask dataframe是不能用的。
pandas用户可以快速入门,只需做很少的改变。
详细API列表参见 https://docs.dask.org/en/stable/dataframe-api.html
Dask DataFrame支持正规匹配读取多个csv文件(csv文件header需要一致)

9/Dask DataFrame适用场景
Dask DataFrame可替代pandas dataframe使用,特别是数据量比较大的时候。
内存存放不了的大数据集
多CPU加速
大数据集的分布式计算,如pandas的groupby,join,time series计算
正则匹配读取多个文件
10/dask dataframe不适用的场景
如果数据量不是很大,内存完全可以处理,则没必要用dask dataframe,
因为pandas dataframe的api更加丰富。
Dask DataFrame不支持的功能也不适合使用dask dataframe,
因为dask dataframe的api是pandas dataframe的api的子集。
11/如何在Jupyter里使用Dask DataFrame?
# 想要使用dask dataframe,必须先创建dask dataframe数据对象
# 有2种方式创建
import dask.dataframe as dd
import pandas as pd
# 第一种
# 在读取数据的时候,直接创建dask dataframe
dd_df = dd.read_csv(file,npartitions=n)
# 第二种
# 先得到pandas dataframe数据对象,然后转位dask dataframe数据对象
data_df = pd.read_csv(file)
dd_df = dd.from_pandas(data_df,npartitions=n)
# 有了dask dataframe 数据对象之后,我们就可以使用相关的api进行计算了。
12/dask dataframe 使用demo
网址:
https://jupyter-share.corp.kuaishou.com/user/houzhen03/notebooks/gaozhenmin/dask/dask_dataframe.ipynb
13/分布式简介
在Dask分布式集群中,有三种角色:Client端,Scheduler端以及Worker端,
<1>Client负责提交Task给Scheduler,用户通过client端提交任务给schedeler
<2>Scheduler负责对提交的Task任务按照一定的策略分发给Worker
schedeler就像是一个大管家,把整个任务task按照一定的策略分发给不同的worker节点。
尽量公平均匀,不要造成数据倾斜。
<3>Worker进行实际的计算、数据存储,在此期间,Scheduler时刻关注着Worker的状态。
worker就是具体工作的工人,在工作的时候,时时刻刻受到上级领导(scheduler)的监视。
14/延时计算与即时计算
<1>延时计算:
· Delayed:
只需把普通的Python Function通过dask.delayed()函数进行封装,就能得到一个Delayed对象
只是构建了一个Task Graph,并没有进行实际的计算,只有调用compute的时候,才开始进行计算
<2>即时计算:
· Future:
对于Future是立即执行的,可以通过submit、map方法将一个Function提交给Scheduler,
在后台,Scheduler会对提交的任务进行处理并分发给Workers进行实际的计算。
当任务提交后,会返回一个指向任务运行结果的Key值,即Future对象,
我们可以跟踪其当前状态,当然我们也可以通过result和gather方法等待任务完成后从而将结果收集到本地
15/简单应用
#读取csv
import dask.dataframe as dd
dd.df = dd.read_csv('2015-*-*.csv')
df.groupby(dd.df.user_id).value.mean().compute()
# 最后使用.compute()获取计算结果
# 你如果把.compute()去掉,则的不到结果,会告诉你有多少个计算任务在等待。
#读取hdf5
import dask.array as da
f = h5py.File('myfile.hdf5')
x = da.from_array(f['/big-data'], chunks=(1000, 1000))
x - x.mean(axis=1).compute()
# 最后使用.compute()获取计算结果
# 你如果把.compute()去掉,则的不到结果,会告诉你有多少个计算任务在等待。
#Dask Bag
import dask.bag as db
b = db.read_text('2015-*-*.json.gz').map(json.loads)
b.pluck('name').frequencies().topk(10, lambda pair: pair[1]).compute()
#Dask delayed
from dask import delayed
L = []
for fn in filenames: # Use for loops to build up computation
data = delayed(load)(fn) # Delay execution of function
L.append(delayed(process)(data)) # Build connections between variables
result = delayed(summarize)(L)
result.compute()
# 最后使用.compute()获取计算结果
# 你如果把.compute()去掉,则的不到结果,会告诉你有多少个计算任务在等待。
#Client
client = Client(processes=True)
from_sequence(seq[, partition_size, npartitions]): Create a dask Bag from Python sequence.
dask.compute(): Compute several dask collections at once.
# 最后使用.compute()获取计算结果
# 你如果把.compute()去掉,则的不到结果,会告诉你有多少个计算任务在等待。
参考网址:
https://www.cnblogs.com/traditional/p/13766079.html
楔子
dask dataframe对象是由很多相对小一点的pandas dataframe对象构成的,沿着index索引分区。
Dask DataFrame对象是构建在Delayed对象上的更高级别的对象,
它是围绕着pandas DataFrame对象对Delayed对象进行了包装。
dask DataFrame API不需要你自己编写复杂的函数,因为它本身就包含了一整套转换方法,
比如:笛卡尔积、join、聚合、分组等等,可以说是非常普遍的操作了.
dask dataframe的API是pandas dataframe的API的子集,
也就是说,有一些pandas dataframe的API(函数)在dask dataframe中是不能用的,
比如说: pandas dataframe 有read_csv()和read_excel()2个读取文件的API函数,
但是dask dataframe 只有read_csv()API,没有read_excel()API。
为什么使用DataFrame这种数据结构
首先我们一般会将数据分为两种:结构化数据和非结构化数据。
其中结构化数据是由行和列组成,从简单的电子表格到复杂的关系型数据库系统,结构化数据是存储信息的一种很直观的方式。
作为数据科学家,我们非常喜欢结构化数据,因为它很直观,很容易将相关信息放在一个可视空间内。
至于结构化数据我想完全没必要在概念上多费口舌,直接把它想象成数据库的一张表即可。
因此,由于结构化数据的组织和存储方式,很容易想到由许多不同的方法来操作数据。
比如与人员信息的相关的结构化数据,我们可以很容易地找到最早的出生日期,过滤出与特定模式不匹配的人,根据姓名和姓氏将人员分组,或者根据年龄进行排序等等。
ids = [1, 2, 3]
names = ["夏色祭", "神乐mea", "碧居结衣"]
ages = [18, 38, 12]
我们创建了三个列表,我们肯定知道如何将其变成一个pandas DataFrame数据对象。
当然即使不使用pandas DataFrame这种数据结构,我们也依旧可以通过Python的方式实现相应的筛选、变换、聚合等操作。
但是对于结构化数据,没有一种结构能和DataFrame一样直观,所以,我们使用dataframe.
对于DataFrame来说,它除了具备二维表的特征之外,还有一些额外的术语:索引和轴。
我们先来看看,上面的那几个列表如果组成DataFrame的话是什么样子。
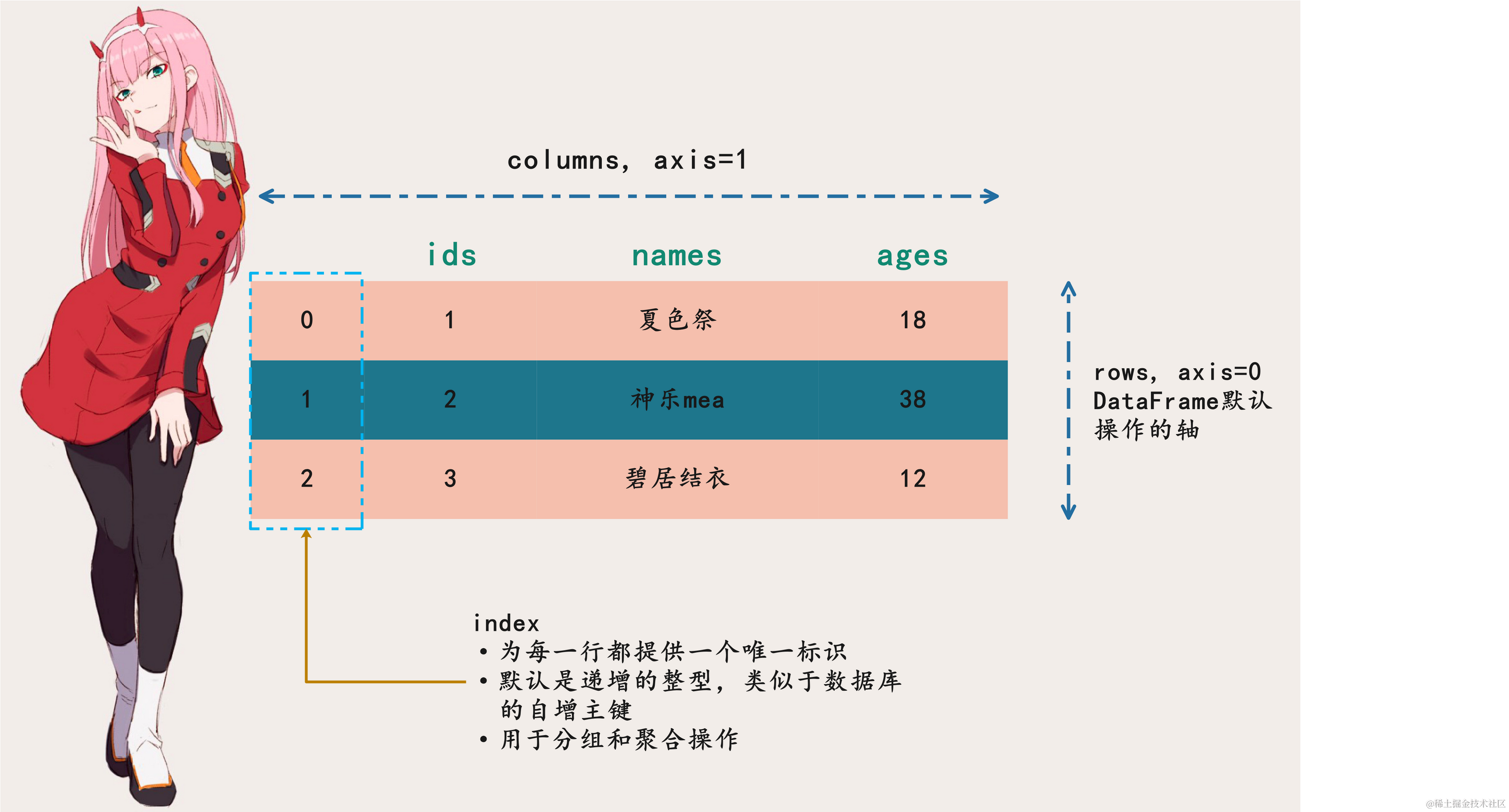
一个dataframe数据对象就是由以下3部分构成的:
df.index 索引,一个索引值就唯一标识一行数据
df.columns
df.values
dataframe的索引和轴
如上图所示,一定要注意DataFrame的索引和轴,
索引就是index,轴又包括2个:横轴和纵轴,及0轴和1轴。
在对DataFrame进行聚合、分隔、拼接的时候需要注意,DataFrame默认是沿着0轴操作的,
除非你显式地指定为1轴(axis=1),pandas中如此,Dask中亦是如此。
关于0轴和1轴估计有人会一直犯迷糊,这里我们用很通俗易懂的话来理解:
index方向是0轴
columns方向是1轴
一句话:沿着某个轴操作,可以理解成是在该轴所在的方向上进行伸缩。
光说不练假把式,我们来使用numpy操作一下,因为0轴和1轴的概念是在numpy中先出现的。
如下所示:2个array左右拼接在一起,行数没有发生变化,但是列数发生了变化,所以axis=1

DataFrame还有一个特点就是具有索引index,
这个索引和数据库中的索引是类似的,但是DataFrame的索引可以不是字段的一部分。
也就是当你打印data_df.columns时候,索引的名字是不在其中的。
对于索引,我们最好要保证唯一性(不唯一也可以,但最好唯一),我们可以将某一个或多个字段设置为索引,也可以使用默认的自增索引。
索引非常重要,我们后面会继续说,并且还会介绍常见的索引函数,总之先来看看索引是如何用来形成分区的。
dask和pandas
pandas适合小规模的结构化数据的分析,并且经过了高度优化,‘适应内存’,所以在小规模数据上很快。
但是一旦数据规模很大,pandas就没有优势了。
dask:从‘适应内存’到‘适应磁盘’,可以进行大规模数据的分析。
dask dataframe为pandas dataframe 提供了一个包装器,可以智能的将巨大的dataframe分拆成更小的片段,并将这些片段分散到多个worker节点中。
正如前面提到的,pandas在分析结构化数据方面非常的强大,但是它最大的限制就在于设计时没有考虑到可伸缩性,也就是说只能在单机模式下计算。
pandas特别适合处理小规模结构化数据,并且经过高度优化,可以对存储在内存中的数据执行快速高效的操作。
然而随着数据量的大幅度增加,单机肯定会读取不下的,通过集群的方式来处理是最好的选择。
这就是Dask DataFrame API发挥作用的地方:
通过为pandas提供一个包装器,可以智能的将巨大的pandas DataFrame分隔成更小的片段,
并将它们分散到多个worker节点中,因此可以更快、更可靠地完成对大规模数据的操作。
Dask DataFrame会被分割成多个分区partition,每个分区都是一个相对较小的pandas DataFrame(默认是大小是64MB),可以分配给任意worker节点,并在需要复制时维护其完整血统。
关于操作我们之前已经见到了,就是对每个分区单独操作(多个机器的话则可以并行),然后再将结果合并,其实从直观上也能推测出Dask肯定是这么做的。
管理DataFrame分区
因为分区对性能可以产生很大的影响,所以你或许会认为管理分区是一件非常苦难且乏味的事情。
但是不要担心,Dask会尝试通过一些明智的默认值和启发式方法,帮助你在不需要手动调优的情况下获得尽可能多的性能。
例如:当使用read_csv读取数据时,每个分区的默认大小是64MB(这也是默认块大小,当然早期的Hadoop也是这样的)。
对于现在机器来说,即便是个人使用的笔记本一般也是16G内存,64MB似乎有点小啊,但这里的64MB不是针对内存而言,而是因为它可以在网络之间快速的传输(太大的话,传输不了)。
如果数据量过大,那么在还没等数据传输完毕,某台机器可能就处理完任务了,那么之后就只能傻等着。
所以每一个块默认是64MB,虽然小,但是源源不断,细水长流。
另外,分区的数量我们也可以自己指定,在创建dask DataFrame的时候,通过npartitions参数指定即可。


dd_df.map_partitions(func_name).compute() # 对每个分区都执行相同的函数
如果我们对每个分区都执行了筛选的函数,那么筛选过后,每个分区剩余的数据量可能不同,
从而对后续的操作产生一定的影响,比如某个分区的数据量很大,导致数据倾斜。
所以用repartition()函数重置分区的数量,我们只需要重置分区的数量,dask就知道该怎么做。
dd_df.repartition(npartitions=1)
dd_df.npartitions # 检查有几个分区
什么是dask分布式并行计算框架中的shuffle
事实上,如果你了解spark的话你会很熟悉这个概念,因为shuffle也是spark中出现的。
shuffle是一个耗时的操作,至于为什么这么说我们来介绍一下。
在分布式并行计算中,shuffle是将所有分区数据广播给所有worker节点的过程。
当我们执行排序、分组、索引等操作时,shuffle是必须的,
因为DataFrame的每一行都要和其它行进行比较,来确定正确的相对位置。
所以这是一个在时间上代价比较昂贵的操作action,因为它需要在网络上传输大量数据。
比如我们要按照某个字段进行聚合,显然此时就不可以每个分区单独进行了。
假设我们要给salary(工资)这个字段的值加100,那么每个分区之间可以单独执行相同的操作,彼此之间是不受影响的;
但如果要是按照salary(工资)进行聚合来计算count,那么不好意思,此时就不是每个分区单独处理所能解决的了的。
比如我们有五个分区,每个分区都有salary值为8000的值,这个时候统计的话就需要将值在分区之间进行发送,所以它是一个比较昂贵的操作。
而且从名字上也能看出来,shuffle有洗牌的意思,如果把每一条数据想象成一张扑克牌,那么shuffle操作是不是需要将多个分区的数据混合在一起呢?
而一旦多个分区的数据需要进行交互,那么就意味着数据的传输,即网络IO,所以它是比较耗时的。
再比如排序,显然排序也是一个shuffle的操作,因为要涉及所有数据之间的对比。
由于我们需要对数据进行各种操作,因此想完全避免shuffle是不太现实的,但是我们可以做一些事情来执行shuffle操作的数据量达到最小,比如确保数据在存储的时候就是有序的,即可消除使用Dask对数据进行排序的需要。
如果可能的话,我们可以在源系统(比如关系型数据库)中进行排序,这样会比在分布式系统中排序更快、更有效。
其次,使用排序列作为DataFrame的索引将提高连接的效率。
所以数据排序之后的查找速度会非常快,因为可以通过DataFrame上定义的分区轻松确定某一行的分区位置。
最后,如果必须触发shuffle的操作,那么在资源允许的情况下可以对结果持久化,这样如果需要重新计算的话可以避免数据之间的再次移动。
Dask DataFrame的一些限制
现在相信你已经对dask DataFrame API的用途有了一个很好的了解,那么最后再介绍一下Dask DataFrame的一些限制吧。
首先也是最重要的,Dask DataFrame不会暴露pandas DataFrame的所有API,即使Dask DataFrame是由多个小型的pandas DataFrame组成的,因为pandas的一些功能虽然很好但却并不适合分布式环境。
也即是说: pandas dataframe的一些函数,在dask dataframe中是不能用的。
例如:改变数据格式的函数,insert()就不支持。
但是pandas的DataFrame则不一样,我们举个栗子:

pandas dataframe 是支持insert()函数直接在本地插入字段的,
但是对于Dask DataFrame则是不允许的,而且大型数据集也根本不适合这种灵巧的变换.
不过虽然dask dataframe不支持insert()函数,但pop()函数是支持的。
此外一些更复杂的窗口操作也不支持,比如:expanding和ewm方法,还有像stack和unstack这种方法也不支持,因为它们往往会导致大量的shuffle。
通常这些昂贵的操作并不需要在完整的原始数据集上运行,你应该使用Dask来完成所有常规的数据准备、过滤和转换,然后将最终的数据集交给pandas。
然后你可以对转化后的数据执行这些对于分布式来说非常昂贵的操作了(但对于pandas而言则没有什么昂贵的),Dask DataFrame和pandas DataFrame之间的交互非常容易,因此在使用Dask DataFrame分析数据时这个操作将会非常有用。
第二个受限制的地方是关系型操作,比如:join、merge、group by,以及rolling。
尽管这些操作Dask DataFrame也是支持的,它们可能会涉及大量的shuffle,而成为程序的性能瓶颈。
因此可以让Dask专注于其它操作,将数据量减小能够交给pandas dataframe,然后让pandas来执行这些操作;或者使用Dask执行这些操作的时候,只将它们作用在索引上。比如有两个DataFrame,一个与人员有关,一个与交易有关,按照person ID进行merge,那么我们可以将person ID作为索引并排好序,这样merge的时候速度会明显加快。
第三个受限制的地方就是索引方面会有一些挑战,如果你希望使用DataFrame中的列作为索引,来代替默认的数值索引(默认是递增的)的话,那么这个列最好是被排过序的,否则的话整个DataFrame会因为它进行大量的shuffle操作。因此最好的办法就是我们在构建数据的时候,就保证它是有序的,这样在计算时能够节省大量的时间。
在Dask处理reset_index这个方法时,你可能会注意到和pandas之间有一个明显的区别,pandas是在整个DataFrame中计算新的顺序索引,而Dask DataFrame中reset_index则类似于map_partitions。这意味着每个分区都有自己的从0开始的顺序索引,我们可以看一下Dask DataFrame在使用reset_index之后的样子。

在reset_index之后,索引会变成从0开始的自增索引。
但是对于Dask DataFrame而言,它是每一个分区都作用上reset_index,所以两个分区的索引都是0 1 2 3 4,因为它们都有5行记录。
那么可不可以对整体所有分区进行reset_index呢?就像pandas那样作用在所有数据集上,答案很不幸,没有一种简单的办法能做到这一点。
因此使用reset_index的时候一定要小心,使用reset_index就意味着你不打算使用索引来对DataFrame进行join、group、sort等操作。
最后,由于Dask DataFrame是由多个pandas DataFrame组成的,因此在pandas中效率低下的操作在Dask中效率也会同样低下。例如:通过apply和iterrows方法进行迭代在pandas中效率非常低,因此在使用Dask DataFrame时遵循pandas DataFrame的优化原则的话将会给你带来最佳的性能体验。
如果你已经熟悉了pandas,那么使用Dask将会是一件很轻松的事情,而且不仅可以让你更好地理解pandas,还能让你熟悉Dask和分布式原理。
如何巧妙的把pandas dataframe 和 dask dataframe 联合起来使用
我们已经知道了二者的区别,和各自的优势。
那么我们在实际的工作中,就可以把它们联合起来使用,各自发挥他们的优势。
pandas dataframe 适合小数据规模的数据操作,性能高度优化,api比较多。
dask dataframe 适合大规模数据的数据操作,并行处理。但是有很多api是不支持的。
而且有以下api,对于大规模数据来说,操作起来很费时,也可以说很'昂贵'。
因为dask dataframe是把所有的数据分发在不同的分区里的,在不同的worker节点上。
如果我们要做一些操作,可能会导致大量的shuffle。
所以,我们可以先通过dask dataframe处理一些复杂的操作,
然后等数据量变小了,在用pandas dataframe来处理数据。
总结
<1>Dask DataFrame由index,行(0轴,axis=0)和列(1轴,axis=1)3部分组成。
<2>DataFrame默认基于0轴进行操作,也即使默认是上下操作的,如果需要,可以根据axis参数修改。
<3>通过Dask DataFrame的divisions属性,可以知道DataFrame是如何分区的,是不是均衡的,还是数据倾斜的。
<4>对Dask DataFrame执行过滤操作会导致每个分区之间的数据量不平衡,为了获取最佳性能,分区大小应该一致。在过滤了大量数据之后,对DataFrame进行重分区是一个很好的做法。
<5>为了获取最佳性能,DataFrame应该按照逻辑列进行索引,根据它们的索引进行分区,并按照索引进行预分类。
dask dataframe的一些属性和函数
import dask.dataframe as dd
# 把pandas dataframe对象-->dask dataframe对象,并进行分区
dd_df = dd.from_pandas(data_df,npartitions=2)
dask_df.divisions # (0, 5, 9)
dask_df.npartitions # 2
#这里的divisions和npartitions是很有用的属性,因为它可以检测DataFrame是如何分区的。
#第一个属性:divisions`(0,5,9)`,显示了分区的边界`(注意:分区是在索引上创建的)`。
#可能你奇怪了,明明是两个分区,为什么边界里面会有三个值。
#其实聪明如你一定想到了,通过`(0, 5, 9)`可以得到`[0, 5]`和`[5, 9]`,
#所以这表示第一个分区处理索引为0到索引为5`(不包括)`的行,第二个分区处理索引为5到索引为9的行。
# 第二个属性:npartitions,这个没啥可说的,就是返回分区数量
dd_df.map_partitions(func_name).compute()
#通过map_partitions()可以对每一个分区都作用相同的函数,类比pandas中的map。
#pandas中的map是对整体数据集,map_partitions是对每一个分区,同样的道理。
#当然这个和spark也是类似的,spark中的RDD也是有分区的,对RDD使用map会作用在RDD的每一个分区上。
# dd_df筛选数据
# 把名字长度>3的行筛选出来,这个api和pandas的dataframe是一样的
dd_df = dd_df[ dd_df['name'].str.len() > 3 ]
# 筛选完之后,可能每个分区的数据量是不一样的,导致数据倾斜
# 通过repartition()函数对dask dataframe对象重新分区
dd_df = dd_df.repartition(npartitions=2)
