

背景
app采用混合开发模式,使用的是系统预置的webview。我们在一些机器上遇到了卡顿严重的问题,为了提升流畅度,我们打开了硬件加速,虽然很流畅,但偶尔会出现小卡顿和花屏问题。
这台机器的性能很差,cpu,gpu是2013年的旗舰手机htc one的水平,但也不至于加载个网页都卡,我一直认为是软件没有兼容好,但一直没有解决思路。正好遇到一个性能如此差的设备,就通过性能分析工具去看看卡顿的过程中发生了什么,粗略的学习一下webview。
卡顿的原因分析
我查了下网友们有在讨论webview的版本对性能的影响。碎片化问题确实一直是Andorid的痛,但谷歌为此付出了很大的努力:
Android4.4后谷歌以Chromium作为了webview的内核,提升了性能。
Android5.0后源码中抽出webview为单个应用程序,上架google play 以应用更新的方式给用户升级webview版本,解决各个厂商系统版本迭代慢,webview碎片化的问题。
从Android7.0系统开始,如果系统安装了Chrome (version>51),那么Chrome将会直接为应用的WebView提供渲染,WebView版本会随着Chrome的更新而更新,用户也可以选择WebView的服务提供方(在开发者选项->WebView Implementation里),WebView可以脱离应用,在一个独立的沙盒进程中渲染页面(需要在开发者选项里打开)
从Android8.0系统开始,默认开启WebView多进程模式,即WebView运行在独立的沙盒进程中,独立进程好处就是不占用主进程的内存。
以上摘录于:来源
WebView版本差异是这次问题的根本原因吗?
国内是没有GMS和google play的,同时国内一堆定制系统,android版本都不愿意升级,更何况是一个webview。所以碎片化问题在国内依旧存在。版本性能差异是肯定的,但我手上的设备就是Andorid 7,我用了较新webview版本还是卡。同时我在另一台性能稍微好一点的安卓9机器上跑又很流畅,在官方文档中可以看到在安卓8后,webview是默认多进程运行的,多进程最大的好处就是webview可用内存更大了!我这台机器运行app性能低不仅是webview碎片化的问题,机器性能瓶颈和安卓系统的版本也会有影响。
WebView单进程架构中渲染性能到底怎样?
WebView本质上就是一个View,webview和普通的view是一套渲染方式,view的渲染我们就很了解了,从Android L开始,android增加了UIThread和RenderThread。需要注意的是:当开启了硬件加速时,RenderThread才去承担渲染工作。
UIThread:
处理进程的 Message、处理 Input 事件、处理 Animation 逻辑、处理 Measure、Layout、Draw ,更新 DIsplayList。这部分工作都是在cpu进行。
RenderThread:
Render Thread要从Main Thread同步DIsplayList,传给Gpu进行渲染到buffer中,然后将buffer入队到QueueBuffer中,等待SurfaceFlinger去消费。这其中有些操作是在cpu进行,有些在gpu进行。
WebView的渲染逻辑中UIThread和RenderThread都干了啥?
我看了老罗关于webview的系列文章:
在android 4.4后 Android WebView加载了Chromium动态库之后,就可以启动Chromium渲染引擎了。Chromium渲染引擎由Browser、Render和GPU三端组成。
其中,Browser端负责将网页UI合成在屏幕上,Render端负责加载网页的URL和渲染网页的UI,GPU端负责执行Browser端和Render端请求的GPU命令。
在第一阶段,Android WebView会对Render端的CC Layer Tree进行绘制。这个CC Layer Tree描述的就是网页的UI,它会通过一个Synchronous Compositor绘制在一个Synchronous Compositor Output Surface上,最终得到一个Compositor Frame。这个Compositor Frame会保存在一个SharedRendererState对象中。
在第二阶段,保存在上述SharedRendererState对象中的Compositor Frame会同步给Android WebView会对Browser端的CC Layer Tree。Browser端的CC Layer Tree只有两个节点。一个是根节点,另一个是根节点的子节点,称为一个Delegated Renderer Layer。Render端绘制出来的Compositor Frame就是作为这个Delegated Renderer Layer的输入的。
在第三阶段,Android WebView会通过一个Hardware Renderer将Browser端的CC Layer Tree渲染在一个Parent Output Surface上,实际上就是通过GPU命令将Render端绘制出来的UI合成显示在App的UI窗口中。
性能的瓶颈到底是在UIThread还是在RenderThread?
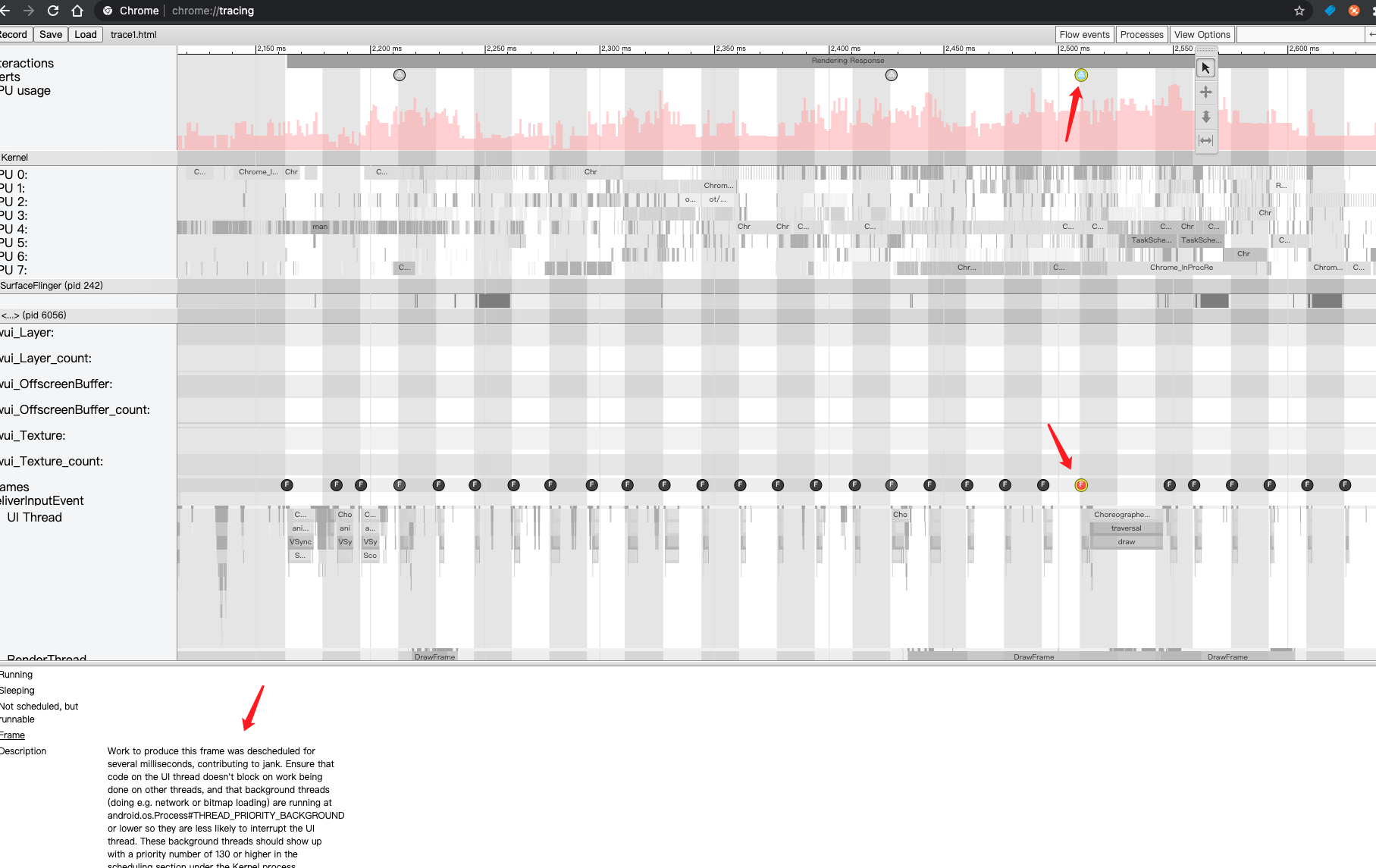
我通过Systrace去捕获了webview10秒内的数据进行分析:
Systrace 是 Android4.1 中新增的性能数据采样和分析工具。它可帮助开发者收集 Android 关键子系统(如 SurfaceFlinger/SystemServer/Kernel/Input/Display 等 Framework 部分关键模块、服务,View系统等)的运行信息,从而帮助开发者更直观的分析系统瓶颈,改进性能。
注意:文中图片全在github中,所以无法查看请用tz,或者改一下自己的host
先简单了解下界面:
- 右边的两个红框就是对应线程,这里也证实了webview和普通的view都是通过这个两个线程的配合进行界面的显示的。
- 在右边的一大块可以看到灰白相间的格子,箭头指向的黑白格子交界就是Vsync信号的到来,我的机器是60hz,所以Vsync 的时间间隔 = 1000/60ms。
- 在顶部分别有红色和绿色的圆形,F代表Frame,对就是每一帧。红色代表这一帧的时间超过了Vsync的时间间隔
我们看看那些花里胡哨的条形图是啥意思:
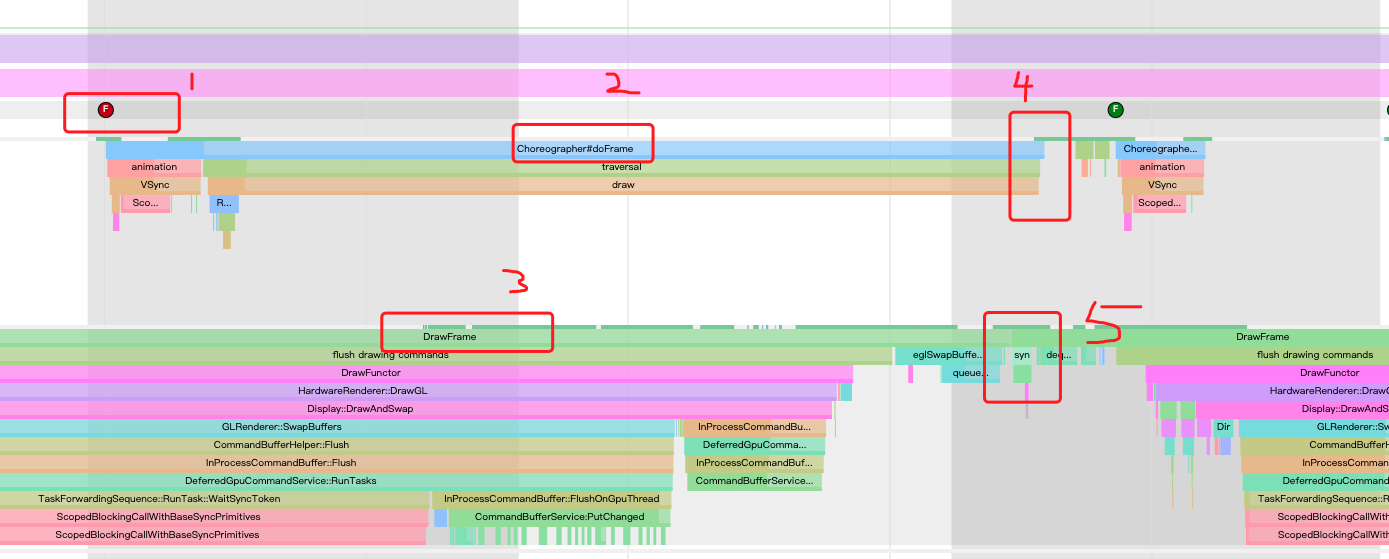
- 上文解释过,代表一帧。
- UIThread中的Choreographer在#doFrame。
- RenderThread在DrawFrame。
- UIThread中的Choreographer#doFrame结束
- RenderThread同步UIThread的DisplayList
上图中可以看到2的过程跨过了三个帧,在draw卡了多少秒,我们看看:
标记1
足足31毫秒,在UIThread的draw搞了太长时间,影响了三帧,这里的draw就是webview的onDraw方法,如下图所示:(该图片来源于罗老师的分析chromium的系列博客) 这里面是在webview渲染的第一第二阶段,Webview的Render端是直接跑在了UIThread中
看了老罗的文章后我知道:
由于render端是跑在UI线程,说明是可能存在性能瓶颈的。但谷歌也对此进行了优化:render端采用类似于UIThread和RenderThread的设计:
render端中,ui线程进行了网页ui的解析,生成了 Layer Tree,而在Layer Tree发生变化后,Compositor线程都会将其同步到Pending Layer Tree,并进行光栅化处理,然后给到Active Layer Tree,Active Layer Tree代表的是一个可以被Browser端合成的UI。
光栅化处理使用了gpu,然而browser端在RenderThread又渲染了一次,也就出现了重复渲染的问题。后来谷歌使用mailbox机制让gpu客户端进行纹理的共享,在render端渲染的纹理直接可以通过mailbox机制给到browser端,以达到减少重复渲染的目的。(任何需要使用gpu渲染的进程或线程都是gpu的客户端,这里的客户端指的是render端和browser端)
看到这里不得不叹息,谷歌真的好努力了,但让我觉得奇怪的是为啥解析网页这种耗时的操作也在ui线程玩?16ms真的能解析完网页吗?可能是我没读懂老罗的意思。
标记2
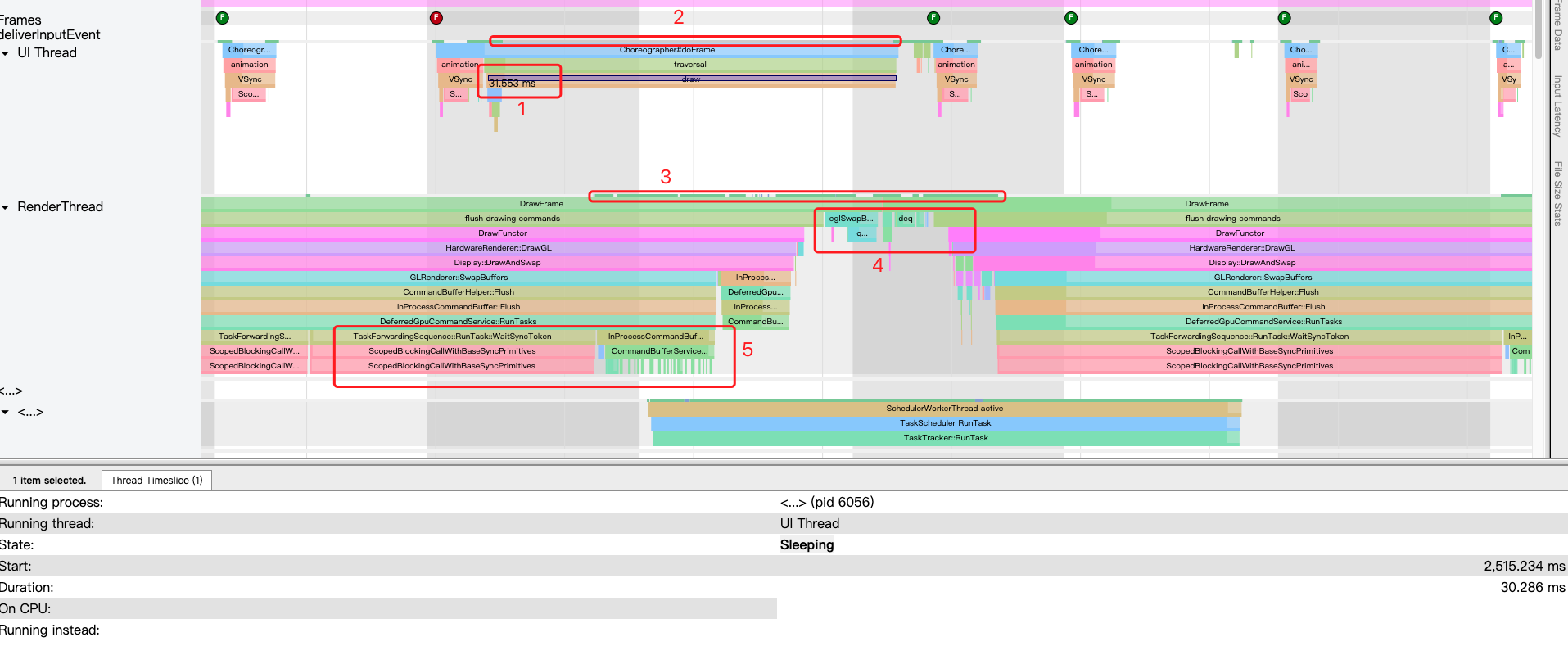
本应该是白色的,变成灰色是因为我选中了,选中后下面的信息栏中会出现线程在这段时间的状态,可以看到线程处于sleeping的状态,说明draw并没有被cpu执行。
我拉到最顶部,看到systrance也是这样说的:
标记3和标记2的红框竖向对比
可以看到过了一段时间后才从白色变成绿色,绿色代表cpu执行RenderThread,这个时候RenderThread应该是在渲染上次同步的DisplayList。
标记4
RenderThread将绘制命令给到Gpu渲染后的buffer入队到QueueBuffer中等待SurfaceFlinger消费,然后sync了主线程性新的DisplayList,同时RenderThread进行下一次的渲染。往上看标记2红框的末端,可以看到UIThread被重新执行,同时Choreographer的draw终于完成,Choreographer进入了下一次doFrame操作。
小结论
从标记2、3、4的分析可以得出一个结论:因为RenderThread在渲染上一次同步的DisplayList,阻塞了主线程的下一次sync,所以UIThread中Choreographer的doFrame一直被阻塞住,无法进行下一次的doFrame操作。举个不恰当的例子:生产者不断的生产,而消费者消费不过来,物料把仓库堆满了,生产者只能停工,等消费者先将仓库里的物料先消费。
所以往前几帧看了下,确实是A处的渲染时间太长了,也就是RenderThread太忙了,导致B处的渲染阻塞了。
RenderThread为什么在sleeping?
标记3和标记2的红框竖向对比后发现,过了一段时间后RenderThread状态才从sleeping到running,可以注意到标记5处,deferredGpuCommandService的RunTasks函数中出现了一大片红,看下红色块里面的英文描述是使用了个同步锁,在task执行时阻塞了RenderThread线程,导致InProcessCommandBuffer类的成员函数FlushOnGpuThread没有及时被调用。
补充知识
这里需要先补充一些知识再继续分析:
Render端需要渲染网页和光栅化,会将执行的操作抽象为Functor对象并写到Display List。上文也有提到Display List最终会被同步到RenderThread中。
Functor对象这里对应的是aw_gl_functor,从systrance捕获到的图看到drawFunctor发生了两次,第一次我没有放大,所以看不到内容,下面会给出的,但我们能看到第二次的drawFunctor
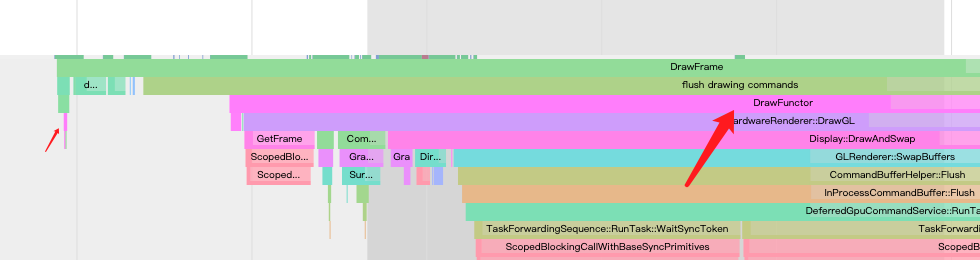
title为DrawFunchor的标记我只在aw_gl_functor.cc找到:
void AwGLFunctor::DrawGL(AwDrawGLInfo* draw_info) {
TRACE_EVENT0("android_webview,toplevel", "DrawFunctor");
bool save_restore = draw_info->version < 3;
switch (draw_info->mode) {
...
case AwDrawGLInfo::kModeSync:
TRACE_EVENT_INSTANT0("android_webview", "kModeSync",
TRACE_EVENT_SCOPE_THREAD);
}
//在RenderThread处理
render_thread_manager_.CommitFrameOnRT();
break;
case AwDrawGLInfo::kModeDraw: {
HardwareRendererDrawParams params{
draw_info->clip_left, draw_info->clip_top, draw_info->clip_right,
draw_info->clip_bottom, draw_info->width, draw_info->height,
draw_info->is_layer,
};
static_assert(base::size(decltype(draw_info->transform){}) ==
base::size(params.transform),
"transform size mismatch");
for (unsigned int i = 0; i < base::size(params.transform); ++i) {
params.transform[i] = draw_info->transform[i];
}
//在RenderThread处理
render_thread_manager_.DrawOnRT(save_restore, ¶ms);
break;
}
}
}
kModeSync代表将render端的CompositorFrame提交给Browser端,这就是第一次drawFunctor,需要将systrance的图放大后才能看到:
kModeDraw代表当前是render端正在重放DisplayList,前面有提到render端执行gpu指令的操作都会被。继续往下看:
在图中这里:
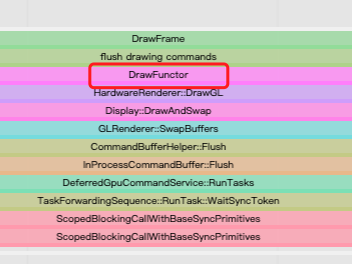
kModeDraw最终调用的是render_thread_manager_.DrawOnRT():
void RenderThreadManager::DrawOnRT(bool save_restore,
HardwareRendererDrawParams* params) {
// Force GL binding init if it's not yet initialized.
DeferredGpuCommandService::GetInstance();
ScopedAppGLStateRestore state_restore(ScopedAppGLStateRestore::MODE_DRAW,
save_restore);
ScopedAllowGL allow_gl;
if (!hardware_renderer_ && !IsInsideHardwareRelease() &&
HasFrameForHardwareRendererOnRT()) {
hardware_renderer_.reset(new HardwareRenderer(this));
hardware_renderer_->CommitFrame();
}
if (hardware_renderer_)
//注意这里
hardware_renderer_->DrawGL(params);
}
接下来就是由Hardware Renderer处理了:
hardware_renderer_ 就是Browser端的hardware_renderer_,如果hardware_renderer_为空,则分配一个HardwareRenderer,同时调用CommitFrame,把Render端上一次渲染的内容提交到Browser端,不过也奇怪,在kModeSync时不是提交过一次了吗,这里怎么又提交一次?说明可能在kModeSync调用 render_thread_manager_.CommitFrameOnRT();的时候,hardware_renderer为空,所以没提交成功,我们看看 render_thread_manager_.CommitFrameOnRT();方法:
void RenderThreadManager::CommitFrameOnRT() {
//确实是可能会错过提交
if (hardware_renderer_)
hardware_renderer_->CommitFrame();
}
但无论如何都会调用到HardwareRenderer::DrawGL, 然后又做了什么呢?看图:
就是在将Render端渲染的ui合成并显示到屏幕上,这里面涉及到了chromium的渲染流水线,我就不去分析他的过程了。
从下图中可以看出来 :执行CommandBufferHelper的Flush,最终调用到DeferredGpuCommandService执行Task去ipc通知gpu进程,达到提交CommandBuffer到gpu进程,并执行gpu指令的目的。CommandBufferHelper有个子类GLES2CmdHelper,它负责将Browser端需要执行的gpu指令写入到CommandBuffer中
执行的Task其实就是去执行下图标记的方法,task中调用了InProcessCommandBuffer::FlushOnGpuThread 最终调用到CommandBufferService:PutChanged,进而通知Gpu Scheduler从Command Buffer中读出新写入的GPU命令,并且调用相应的OpenGL函数进行处理。如下图所示:
注:最右下角有看到SchedulerWorker开始了工作,我忘了标记出来。
而前面分析到在InProcessCommandBuffer::FlushOnGpuThread 前阻塞了,一直在waitSyncToken,该方法得不到执行。
感觉gpu总是很”忙“的样子。使用系统自带的 GPU 渲染模式分析工具进行分析,发现下图中红色的 issue的时间是最长的,这就很符合我看到的:**InProcessCommandBuffer::FlushOnGpuThread无法被执行。**掉帧卡顿是必然的。为什么阻塞了?gpu在忙什么?
阻塞原因
我们看看deferredGpuCommandService源码分析RunTasks的过程,以及阻塞的原因:
void DeferredGpuCommandService::RunTasks() {
TRACE_EVENT0("android_webview", "DeferredGpuCommandService::RunTasks");
DCHECK_CALLED_ON_VALID_THREAD(task_queue_thread_checker_);
if (inside_run_tasks_)
return;
base::AutoReset<bool> inside(&inside_run_tasks_, true);
while (tasks_.size()) {
std::move(tasks_.front()).Run();
tasks_.pop_front();
}
}
这里有输出TRACE_EVENT,对照我从systrance获取到的图说明我找的没错。注意这里有个tasks_成员变量,他被定义在,deferredGpuCommandService.h中
base::circular_deque<base::OnceClosure> tasks_;
是个循环队列,存储的类型是OnceClosure,OnceClosure是个啥?
Tasks
一个 task 是一个继承自
base::OneClosure的对象,它会被添加到线程的 queue 里异步执行;一个
base::OneClosure会存储一个函数指针及其参数。它包含有一个Run()方法,该方法执行时,会通过函数指针调用函数,并传入绑定的参数。base::OneClosure对象可以通过base::BindOnce()来创建,具体可参考 Callback<> and Bind():
在哪里插入的队列呢?继续看deferredGpuCommandService源码:
// Called from different threads!
void DeferredGpuCommandService::ScheduleTask(base::OnceClosure task,
bool out_of_order) {
DCHECK_CALLED_ON_VALID_THREAD(task_queue_thread_checker_);
LOG_IF(FATAL, !ScopedAllowGL::IsAllowed())
<< "ScheduleTask outside of ScopedAllowGL";
if (out_of_order)
tasks_.emplace_front(std::move(task));
else
tasks_.emplace_back(std::move(task));
RunTasks();
}
可以看到由out_of_order参数决定使用emplace_front还是emplace_back插入了队列,上文有提到base::OneClosure 对象可以通过 base::BindOnce() 来创建,该方法是通过参数传入的,我们继续看deferredGpuCommandService源码:
TaskForwardingSequence是deferredGpuCommandService的子类,定义了task的执行:按照 task 投递的顺序来执行,同一时刻只有一个 task 被执行,但不同的 task 可能在不同的线程上执行。
我们先看TaskForwardingSequence的一部分源码:
// gpu::CommandBufferTaskExectuor::Sequence implementation that encapsulates a
// SyncPointOrderData, and posts tasks to the task executors global task queue.
class TaskForwardingSequence : public gpu::CommandBufferTaskExecutor::Sequence {
...
// Raw ptr is ok because the task executor (service) is guaranteed to outlive
// its task sequences.
DeferredGpuCommandService* const service_;
scoped_refptr<gpu::SyncPointOrderData> sync_point_order_data_;
base::WeakPtrFactory<TaskForwardingSequence> weak_ptr_factory_;
DISALLOW_COPY_AND_ASSIGN(TaskForwardingSequence);
...
void ScheduleTask(base::OnceClosure task,
std::vector<gpu::SyncToken> sync_token_fences) override {
uint32_t order_num =
sync_point_order_data_->GenerateUnprocessedOrderNumber();
// Use a weak ptr because the task executor holds the tasks, and the
// sequence will be destroyed before the task executor.
//service_就是DeferredGpuCommandService,这里调用了DeferredGpuCommandService 的ScheduleTask方法。并通过 //base::BindOnce创建了一个OneClosure,其中参数之一是TaskForwardingSequence的RunTask方法,
//说明DeferredGpuCommandService::RunTasks最终执行的是TaskForwardingSequence::RunTask。
//std::move(task), std::move(sync_token_fences), order_num)都是执行TaskForwardingSequence::RunTask时作为参数传入,false说明task是插入尾部。。
service_->ScheduleTask(
base::BindOnce(&TaskForwardingSequence::RunTask,
weak_ptr_factory_.GetWeakPtr(), std::move(task),
std::move(sync_token_fences), order_num),
false /* out_of_order */);
}
...
};
下面看看TaskForwardingSequence::RunTask:
private:
// Method to wrap scheduled task with the order number processing required for
// sync tokens.
void RunTask(base::OnceClosure task,
std::vector<gpu::SyncToken> sync_token_fences,
uint32_t order_num) {
// Block thread when waiting for sync token. This avoids blocking when we
// encounter the wait command later.
for (const auto& sync_token : sync_token_fences) {
base::WaitableEvent completion;
if (service_->sync_point_manager()->Wait(
sync_token, sync_point_order_data_->sequence_id(), order_num,
base::BindOnce(&base::WaitableEvent::Signal,
base::Unretained(&completion)))) {
TRACE_EVENT0("android_webview",
"TaskForwardingSequence::RunTask::WaitSyncToken");
completion.Wait();
}
}
sync_point_order_data_->BeginProcessingOrderNumber(order_num);
std::move(task).Run();
sync_point_order_data_->FinishProcessingOrderNumber(order_num);
}
task是TaskForwardingSequence::ScheduleTask的参数传入的,也是具体要执行的内容,这里其实是InProcessCommandBuffer::FlushOnGpuThread 方法。 从systrance捕获到的图看:是InProcessCommandBuffer类的成员函数Flush传入的task。
void InProcessCommandBuffer::Flush(int32_t put_offset) {
if (GetLastState().error != error::kNoError)
return;
if (last_put_offset_ == put_offset)
return;
TRACE_EVENT1("gpu", "InProcessCommandBuffer::Flush", "put_offset",
put_offset);
// Don't use std::move() for |sync_token_fences| because evaluation order for
// arguments is not defined.
ScheduleGpuTask(
base::BindOnce(&InProcessCommandBuffer::FlushOnGpuThread,
gpu_thread_weak_ptr_factory_.GetWeakPtr(), put_offset,
sync_token_fences, flush_timestamp),
sync_token_fences, std::move(reporting_callback));
}
再回到TaskForwardingSequence::RunTask:源码中看:使用了WaitableEvent,WaitableEvent是一个同步锁,注释也写的很清楚,阻塞线程并等待同步信号的到来。为什么要等?
private:
// Method to wrap scheduled task with the order number processing required for
// sync tokens.
void RunTask(base::OnceClosure task,
std::vector<gpu::SyncToken> sync_token_fences,
uint32_t order_num) {
// Block thread when waiting for sync token. This avoids blocking when we
// encounter the wait command later.
for (const auto& sync_token : sync_token_fences) {
//这里!!!
base::WaitableEvent completion;
if (service_->sync_point_manager()->Wait(
sync_token, sync_point_order_data_->sequence_id(), order_num,
base::BindOnce(&base::WaitableEvent::Signal,
base::Unretained(&completion)))) {
TRACE_EVENT0("android_webview",
"TaskForwardingSequence::RunTask::WaitSyncToken");
completion.Wait();
}
}
sync_point_order_data_->BeginProcessingOrderNumber(order_num);
std::move(task).Run();
sync_point_order_data_->FinishProcessingOrderNumber(order_num);
}
SyncToken机制
我去读了老罗的:Chromium硬件加速渲染的OpenGL上下文调度过程分析有提到GpeChannel的概念,其中GpuChannel的HandleMessage方法如下:
void GpuChannel::HandleMessage() {
handle_messages_scheduled_ = false;
if (deferred_messages_.empty())
return;
bool should_fast_track_ack = false;
IPC::Message* m = deferred_messages_.front();
GpuCommandBufferStub* stub = stubs_.Lookup(m->routing_id());
//这里是指GpuCommandBufferStub的状态是否属于自己放弃调度或者被抢占调度,我们是有可能在这里被阻塞的,因为这里没有通知客户端结束阻塞
do {
if (stub) {
if (!stub->IsScheduled())
return;
//被抢占了,继续OnScheduled()
if (stub->IsPreempted()) {
OnScheduled();
return;
}
}
scoped_ptr<IPC::Message> message(m);
deferred_messages_.pop_front();
bool message_processed = true;
currently_processing_message_ = message.get();
bool result;
if (message->routing_id() == MSG_ROUTING_CONTROL)
result = OnControlMessageReceived(*message);
else
result = router_.RouteMessage(*message);
currently_processing_message_ = NULL;
//如果当前是不认识的message,判断是否是同步消息,是的话会通知客户端结束等待
if (!result) {
// Respond to sync messages even if router failed to route.
if (message->is_sync()) {
IPC::Message* reply = IPC::SyncMessage::GenerateReply(&*message);
reply->set_reply_error();
Send(reply);
}
} else {
//如果是认识的message就说明缓冲区的指令还有未处理完的,就处理
// If the command buffer becomes unscheduled as a result of handling the
// message but still has more commands to process, synthesize an IPC
// message to flush that command buffer.
if (stub) {
if (stub->HasUnprocessedCommands()) {
deferred_messages_.push_front(new GpuCommandBufferMsg_Rescheduled(
stub->route_id()));
message_processed = false;
}
}
}
//如果message_processed等于true,说明消息处理完了
if (message_processed)
MessageProcessed();
...
}
这里阻塞的原因有很多,但我的情况是:
1.缓冲区的指令还有未处理完。
2.处于IsPreempted状态,也就是被抢占了。
因为老罗有提到,如果GpuCommandBufferStub收到的是GpuCommandBufferMsg_AsyncFlush消息,就是有指令未处理完,我从systrance捕获到的数据看,确实是一直收到该消息。如下图所示:
同时上面的源码中有看到,IsPreempted状态时,会调用OnScheduled(),这个方法就是向消息的队尾插入消息,不立即执行,简单的说就是在排队,这里就可能是上一次的指令未执行完,堆到了这里。
这里我去看了官方的文档,我英文不太好,所以先贴出官方文档,以免大家被我的理解误导。
我读完后理解是:
chromium中有browser端和render端,他们两个都是gpuClient,gpu进程的gpu线程就是gpuService。而browser端和render端有资源依赖,即:browser端渲染的资源输入来自于render端渲染结果的输出。gpuClient与gpuService间的ipc使用的是channels,而不同进程或线程的channels是不一样的,而这些channels之间是异步的,无法保证render端通知gpuService读取commandBuffer的消息在Browser端后面,所以就需要一个同步机制确保Browser端通知gpuService读取commandBuffer渲染的消息比render端晚。 所以客户端在将gpu指令提交给gpu进程前,验证令牌,但Gpu还在处理上一次给到的指令,并未通知客户端取消阻塞,也就是我们上面看到的客户端阻塞等待。
即然是browser端在等待render端,那为啥gpu会不断收到GpuCommandBufferMsg_AsyncFlush消息?到底是谁在Browser端合成前使用了gpu渲染?那应该是就是render端了。
同时我发现每一次都是在Choreographer的doFrame开始的时候发生掉帧,都被阻塞。
每次都发生,很有意思的一个点,因为每段数据都是我切换界面记录的,所以我开始怀疑是render端的输出太慢了,导致Browser端在等待。这一切都要回到开头去分析。
从头开始
我捕获这段数据10秒内,我点击了界面上的跳转按钮,然后又点击跳转回来,我这么操作是为了触发渲染。从下图可以看到是有收到的:
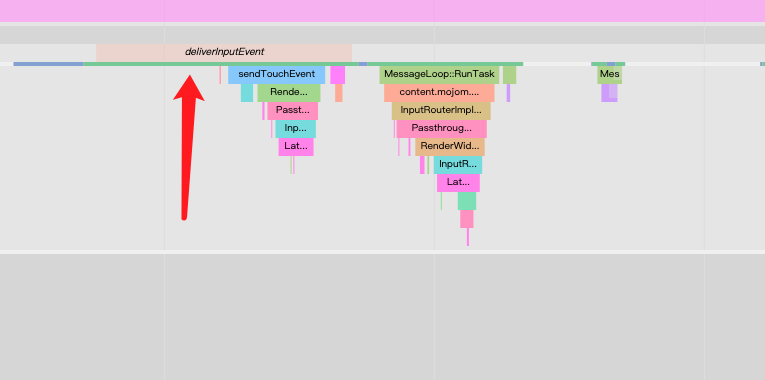
然后Blink渲染引擎的主线程也收到了事件,这里是不是懵逼?为什么是跑到Blink渲染引擎主线程收到事件?上文有提到,从老罗的分析系列文章看,render端是跑在UIThread中的,老罗给出了一张图,我在上文中也有贴出来。但是!我从systrance的图来看,这个说法感觉在较新版本的webview上,不太对,这下我慌了, 我应该是误解了老罗的意思。
render端到底跑在哪个线程?
看下图
框框中别看是说发给render进程,我这边看到的systrance其实是发给一个线程,我是否可以理解这个线程就是render端的主线程?render端其实不是跑在UIThread上的,是在另一个线程,当然有可能是UIThread的子线程。
小疑问0
那又会问自己,如果render端不在UIThread上那UIThread中的Choreographer的doFrame做了啥?其实在上文的补充知识中有提到:抽象Functor对象并写到Display List中。
小疑问1
上文中的补充知识一节中有提到:**Render端需要渲染网页和光栅化,会将执行的操作抽象为Functor对象并写到Display List。**我现在开始怀疑functor没有具体关于光栅化的操作,下面我看看能不能证明这个猜想。
接下来下看看render端收到触摸事件后发生了什么?从systrance的图中也是可以看到事件被分发到了render端线程中处理:
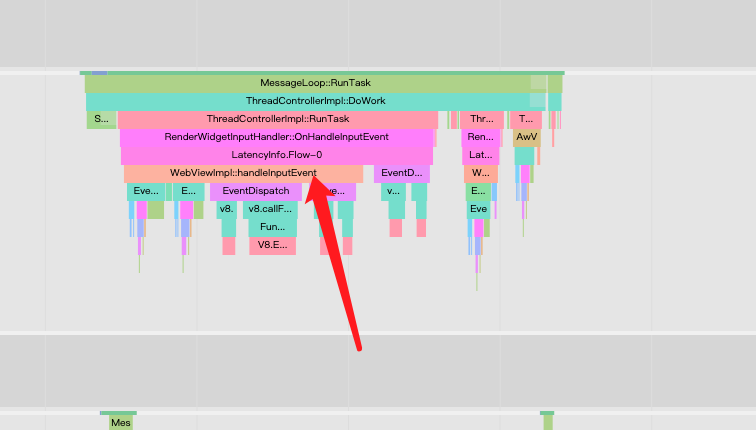
在事件分发后,v8引擎FunctionCall方法去执行前端写的js程序,因为我是点了跳转界面的按钮,接下来应该是会加载界面:
和原生应用的区别之一就是需要加载网页资源,资源加载这里错过了3个刷新信号,io必然耗时,我这应用的资源是本地,比从从网络下载要好一点,这是总所周知的性能瓶颈。加载资源这部分操作都是在Blink渲染引擎上的,如下图所示:
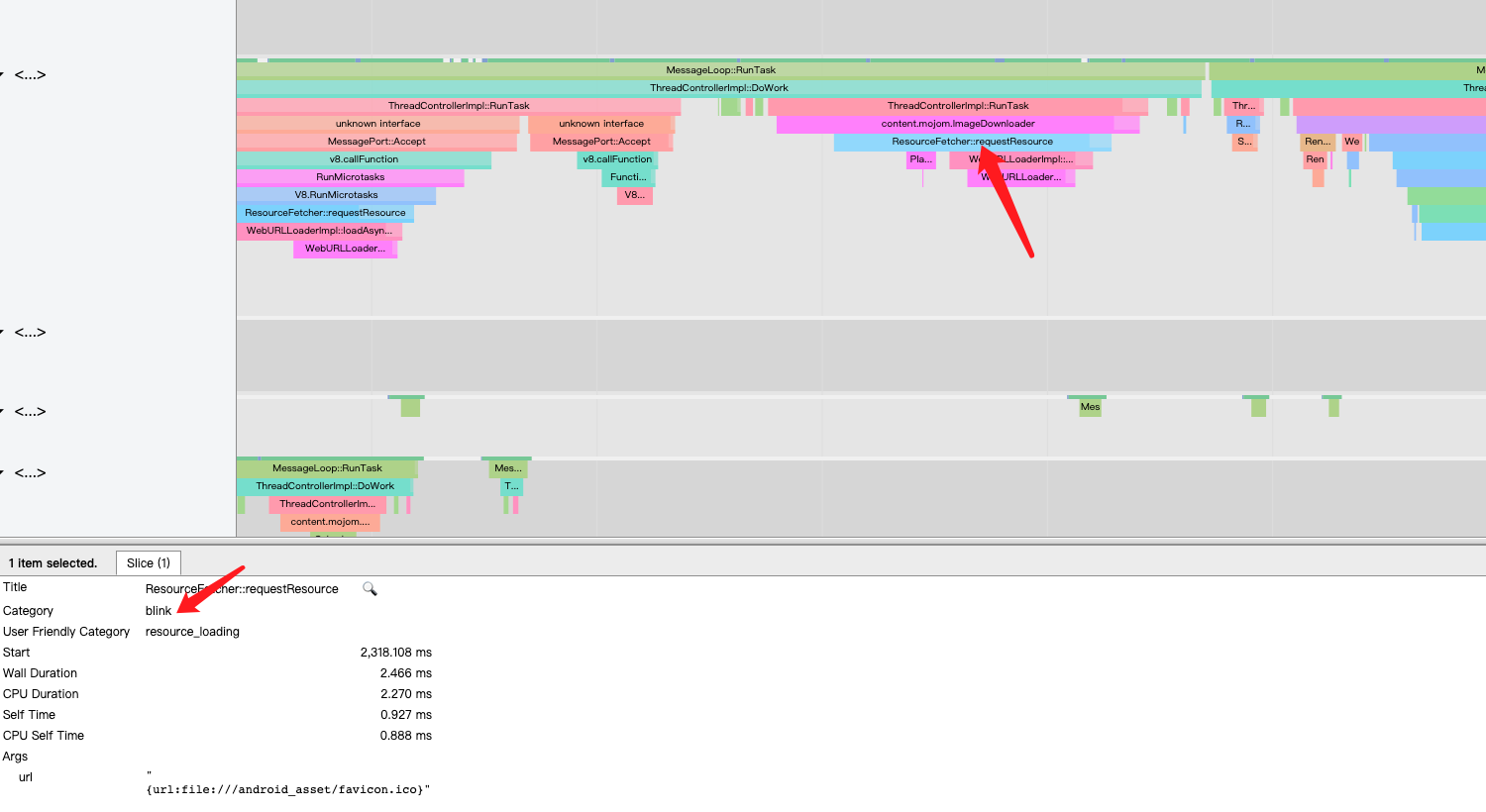
在加载完后,肯定是去解析界面,就是在 ThreadProxy::BeginMainFrame方法里 ,这个方法做的事情可多了,都是在Blink渲染引擎发生的。
Blink
Blink是啥:维基百科
我简单的看了下官方文档:how_cc_works 有人翻译了哈:How cc Works 中文译文 真的很感谢这些无私奉献的人!
文档里面有一句:
It is also embedded in the renderer process via Blink / RenderWidget.
这也就是我目前的情况:render端是使用Blink进行网页渲染的模式。我一步一步分析(要是客官看不下去,可以尝试看这个PPT)
先看个总体的图:
好家伙,搞了73毫秒,我手上这台设备,Geekbench5跑分,单核102,多核340这什么水平?也就是2013年旗舰手机HTC ONE的水平,8年前的水平!解析网页资源必然也耗时,也是可以理解的嘛!接下来的工作就是Blink渲染引擎负责了:
从上方框出的内容就是Blink的工作流程了,从左到右分别:
1.在处理Parse和Style相关工作
2.在处理Layout的相关工作
- CompositingUpdate分层,这里在做图层合成加速
图层合成加速:为提高渲染效率将整个页面按照一定规则分成多个图层,只渲染必要的图层,其他图层只需要参与合成。
-
在处理绘制指令,构建属性树,也就是paint阶段,可以看第一个Paint很长,还有个子过程,是在绘制Bitmap图,后面有看到DisplayItemList:

-
这个DisplayItemList不是DisplayList,而是ShareImage相关的东西,该文章有讲到:SharedImage是个啥?
这里需要注意的是里面有提到:
- GpuRasterBufferProvider这种光栅化模式的输出结果是存在了SharedImage
- ShareImage 机制从2018年开始引入,设计用来取代 Mailbox 机制
我从systrance捕获到的图里面也是这样的,所以本文前面标记1中提到的Mailbox机制,在这里可能并没用到。
paint了很多次,这里能看出加载的页面还是有点复杂度的。最后会调用到 ProxyMain::BeginMainFrame::commit

ProxyMain::BeginMainFrame::commit 提交后,还需要进行光栅化,而光栅化是在render端的Compositor线程上进行的:
Compositor线程中的TileManager方法中,并没有做光栅化操作,而是Assign Gpu Memory To Tiles,分配内存,查了资料后了解到Blink引擎光栅化是在CompositorTileWorker线程中分块进行的,如下图所示:
小疑问2
可以看到光栅化任务很重,这里我觉得挺奇怪的,为啥要一个一个执行,既然Compositor是打算分块进行,那能不能搞多几个CompositorTileWorker线程去做?这里是不是一个可以性能优化的点?
在CompositorTileWorker线程搞定后可以看到会同步消息给Compositor线程:
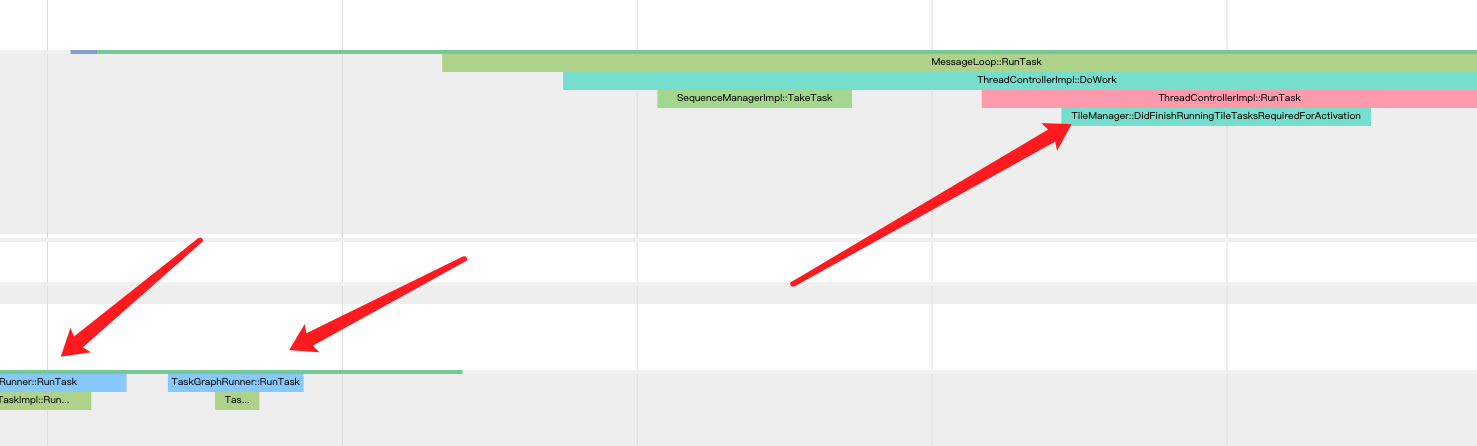
然后Compositor线程:
-
做了个检查
-
紧接着发了个消息给gpu
-
最后调用ProxyImpl::NotifyReadyToActivate方法。
当发送消息给gpu时,看那个最大的箭头那里,那就是gpu的服务端线程,直接就开始工作了!!!!所以前面说是谁的指令没执行完!还记得不?现在我知道答案了!
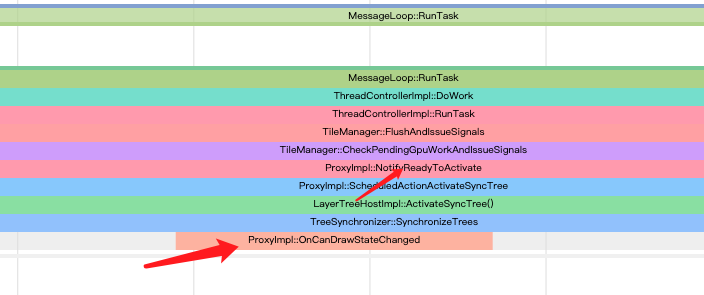
ProxyImpl::NotifyReadyToActivate,就是将Pending Tree拷贝到Activate Tree,这两颗树的差别老罗有讲到 :
网页分块的光栅化操作完成后,CC Pending Layer Tree就会激活为CC Active Layer Tree。CC Active Layer Tree代表用户当前在屏幕上看到的网页内容,它可以快速响应用户输入,例如滚动和缩放。
现在render端的任务差不多就完成了,是时候开始输出Frame给Browser端了:
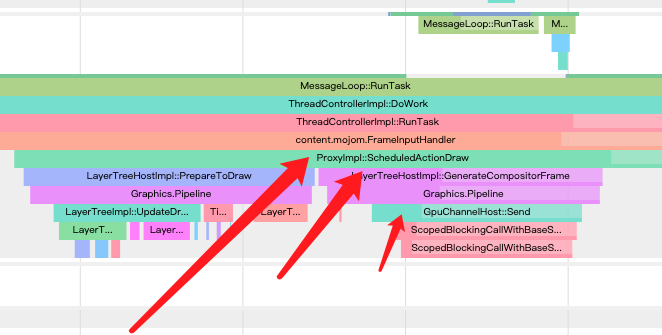
ProxyImpl::ScheduledActionDraw 中调用:LayerTreeHostImpl::GenerateCompositorFrame,意思就是生成CompositorFrame,也就是Render端在将结果输出,通过GpuCHannelHost通知到DeferredGpuCommandService,进而通知到此时也正好在等待render端输出的Browser端,Browser端的获取到frame后就会使用viz进行合成显示了,如下图所示:
这里也找到了了上文中的小疑问1的答案:render端的functor并不负责光栅等操作,这部分功能都是由Blink完成的。
为什么Browser端会恰好等待呢?这是因为Compositor在ScheduledActionDraw前就发出了渲染调度的信号:
然后Scheduler的BeginFrame会使得UIThread的Choreographer#doFrame 中的traversal调用,最终到AwContents.onDraw,这时候UIThread才有内容到DisplayList,RenderThread才有内容可以渲染,才开始渲染:
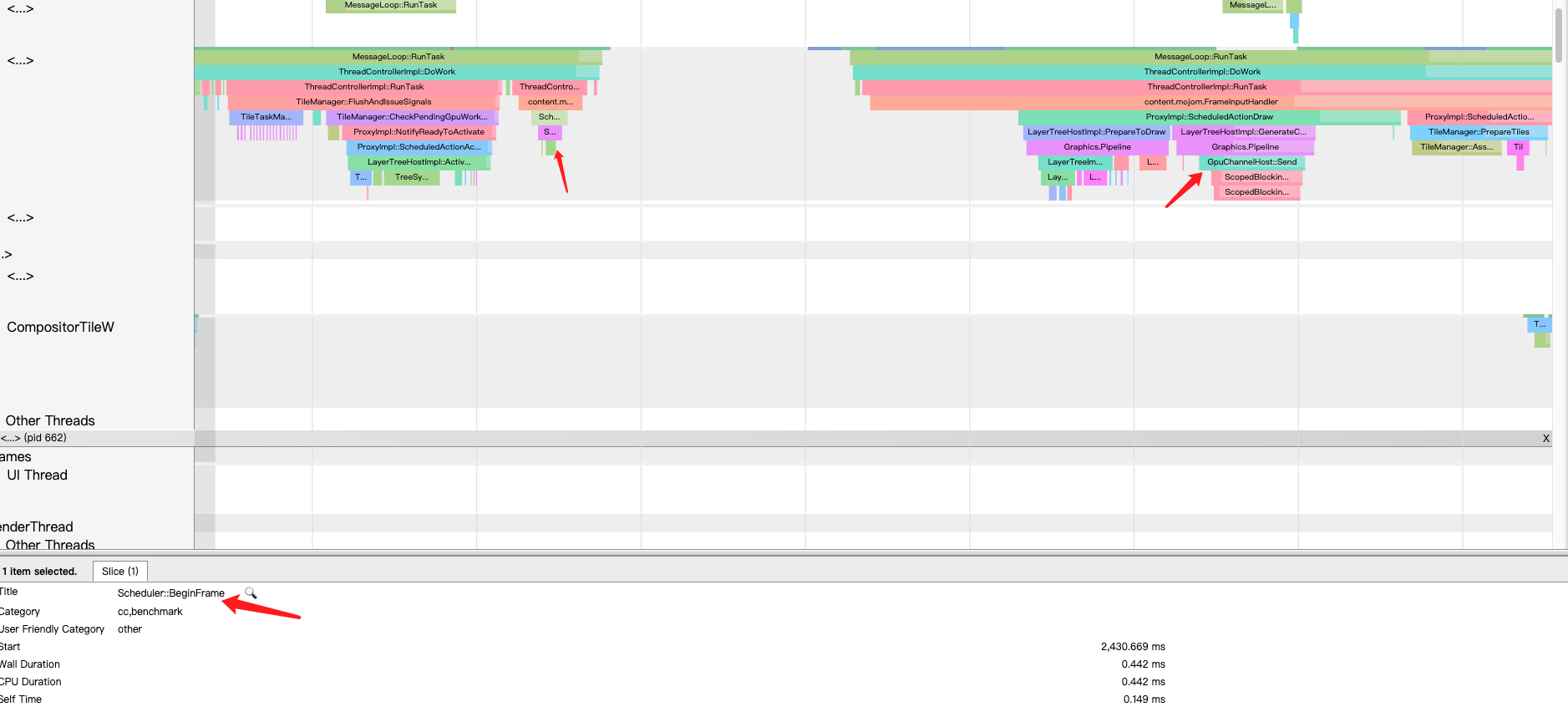
Raster Buffer Providers
后面的发生事情在上文都分析过了:Browser端在等,并且阻塞了,导致cpu将指令同步到gpu花了很长的时间。现在找到了阻塞的原因:render端的CompositorTileWorker线程在光栅化后,Compositor线程给gpu发了个消息,gpu在执行render端光栅化的指令,并且光栅化任务看起来挺重:
void TileManager::FlushAndIssueSignals() {
TRACE_EVENT0("cc", "TileManager::FlushAndIssueSignals");
tile_task_manager_->CheckForCompletedTasks();
did_check_for_completed_tasks_since_last_schedule_tasks_ = true;
raster_buffer_provider_->Flush();
CheckPendingGpuWorkAndIssueSignals();
}
代码中这个raster_buffer_provider_ ,据我了解,也有不同的模式:
我在官方文档又看到了这个:how_cc_works 有人翻译了哈:How cc Works 中文译文
Raster Buffer Providers
Apart from software vs hardware raster modes, Chrome can also run in software vs hardware display compositing modes. Chrome never mixes software compositing with hardware raster, but the other three combinations of raster mode x compositing mode are valid.
The compositing mode affects the choice of RasterBufferProvider that cc provides, which manages the raster process and resource management on the raster worker threads:
- BitmapRasterBufferProvider: rasters software bitmaps for software compositing
- OneCopyRasterBufferProvider: rasters software bitmaps for gpu compositing into shared memory, which are then uploaded in the gpu process
- ZeroCopyRasterBufferProvider: rasters software bitmaps for gpu compositing directly into a GpuMemoryBuffer (e.g. IOSurface), which can immediately be used by the display compositor
- GpuRasterBufferProvider: rasters gpu textures for gpu compositing over a command buffer via gl (for gpu raster) or via paint commands (for oop raster)
Note, due to locks on the context, gpu and oop raster are limited to one worker thread at a time, although image decoding can proceed in parallel on other threads. This single thread limitation is solved with a lock and not with thread affinity.
从上面的分析看,我这台设备的系统可能使用的就是是GpuRasterBufferProvider。
官方也回答了上文的**小疑问2:**为什么光栅化不采用多线程吗?上面的官方文档写了:由于需要在光栅化过程中锁定上下文,gpu 和 oop 光栅化目前不支持多线程并发运行。所以如果支持多线程并发光栅化,性能应该会提升一点。
个人拙见
- 可以看出webview有点强行和原生view体系牵线的感觉。假设原生窗体本身就有内容要绘制,webview要是能不依赖原生的view渲染流程,直接使用surfaceview在独立的线程渲染,不和activity的surface一起玩,是不是可以减少对UIThread的和RenderThread的影响?我们前面分析时就看到RenderThread太忙,导致UIThread无法running掉帧的情况。
- 渲染流程很长很复杂,这里必然会有一些开销,我不了解这些command buffer,viz ,gpu分块光栅化,分层渲染等技术的细节,所以也无法知道具备哪些可以优化的地方。但我知道这里webview的各个模块仅仅是多线程间通信,虽然进程通信少了,但是如果内存吃紧,开启了硬件加速的webview必然会受到影响,所以将webview放在独立进程去运行也是十分不错的一个选择,同时在性能好的的多核手机中,webview就没有合理的利用到并发的优势。
- 解析网页也是十分吃力,从本地网页解析都花了很长的时间,这点可能是机器cpu的性能差,我看了cpu每次都基本是满载运行,也可能是前端的网页比较复杂,对于开发者而言,只能优化前端的界面。
- 光栅化部分如果能多线程并发进行,性能上是否能好一些?因为在上文的分析中,光栅化十分的耗时。而webview又属于原生view的渲染机制,也就是要等到下一个刷新信号到来的时候才能被surfaceFlinger处理,因为你已经知道是耗时了,那为了流畅的渲染,在光栅化完后,立即显示,而不是要等下一个刷新信号,所以这里是否也可以使用surfaceview进行优化。
比Webview更好的解决方案
可以使用chromium的api自己写一个webview,但是在大佬同事的推荐下,我了解到英特尔为了解决移动端webview碎片化的问题,搞了个开源项目:github.com/crosswalk-p…
使用了surfaceview,从上文分析中,我列出了一些我个人认为webview还可以优化的地方,其中就有建议使用surfaceview的,我毫不犹豫就冲了,没有花屏,也没有原来严重掉帧的情况,大喜!但是英特尔已经不维护好多年,也有一些大佬自己去编了53、77版本的chromiu内核的库,目前我使用的情况是53问题比较多,77版本的问题比较少。77接入的sample:github.com/ks32/Crossw…
当然也一直提到我手上要适配的设备性能太差,现在市面上的机器都比我手上的好,这是百分之百的,所以我这里其实能做一个机型区分,如果是其他机型可以直接使用原生的webview加载。
结
经过漫长的分析,虽然看的很浅显,对我一个工作未满一年的小菜鸡而言,挺满足的了。至少了解了一些相关的知识,在看这些源码时,总是忍不住对它的设计,与自己做过的东西进行思考和对比。
例如渲染管线,我在开发屏保的时候就设计了下载流水线,这点真的很相似,对比后有很多启发。
在做渲染和动画时我也是设计了两个线程:1.加载图片绑定成纹理并抽象成shape,2.使用矩阵运算实现变换并使用gl绘制渲染。看完render端和browser端的设计后,也产生了些思考。
gpu的同步机制和TaskForwardingSequence,这个挺有意思的。我是直接使用kotlin的异步流做合并,进而处理来自多条流水线的输出,好处就是异步流直接处理了排队。
我还没有设计过调度模块,看到chromium要管好的一堆模块,搞了个渲染调度,得抽个时间详细了解一下。
最后
在这段时间看了罗升阳罗老师的很多chromium相关文章,不得不说罗老师太强大了。
systrance工具的使用是看了Gracker大佬的文章,Gracker的个人主页中写着:闻道有先后,术业有专攻,如是而已。和我的座右铭一致,很开心。
也看了易旭昕大佬和 龙泉寺扫地僧、教主大佬在知乎上发表的关于Blink渲染引擎的一些文章,受益匪浅。
感谢巨人们的肩膀。
