场景
- 在业务上现在有一个在线课堂的场景,老师通过在线画板绘制各种图案,学生看到画出来的图案,当然也可以理解为一个你画我猜的这样一个小游戏。
简单实现
const canvas = document.getElementById('canvas');
const ctx = canvas.getContext('2d');
ctx.fillStyle = 'green';
ctx.fillRect(10, 10, 150, 100);
const mes = {
type:'rect',
color:'green',
data:[10, 10, 150, 100]
}
cosnt im = new IM()
im.on((mes)=>{
draw(mes)
})
核心解析
- 实现的核心就是采集画笔数据通过网络传输到其他端再绘制。
- 数据结构:无非是画笔对应的类型,颜色,以及坐标位置。
痛点&&难点
- 坐标位置数据量过多过大
- 抽象一下即可得知:画布中的图形就是画布内部各种点的集合,而这些点则是由x轴,y轴两个坐标定义,例如[[1.123,2.342],[3.123,4.342]]这样数据可以表示多个点的集合,也就可以画出不同的图形,例如一条线等等等
- 画的图形越复杂,整个数据传输到其他端的数据量就越大
- 数据点越精确,例如[1.12387657,2.342687654]这样的数据精度越高,在其他端的还原度就越高,同样的数据量也会变得越大
- 总而言之:想要更大的图形,更清晰的图形效果,就需要多数据支持,想象一下,一个由几千个,上万个高精度点组成的数据会是什么样子呢?那是一个高达几M体积的json数据体,可是这下矛盾就出现了
- 传输消息体过大,不管是使用第三方的IM通信,还是自建的sokect在后端api的设计上面都有大小的限制,数据量过大就会导致传输受限
- 并且消息体过大,也会出现传输效率的问题。这是显而易见的,同样的网络情况,数据量越小传输速度肯定是越快的,不同网络更不用说
- 极致的体验就需要极致的创新,不管是否在弱网还是正常网络下,高效的数据传输是必然的要求,以达到极致的用户体验。
常用解决方案
- 数据切片,数据量大分页是最常规的操作,没有一次性查询所有数据列表的操作,都是使用分页查询的,这也是前后端api设计中最常见的方式。哪怕现在数据量不多,分页的设计依然是代码健壮性中不可或缺的一部分。
- 常规压缩算法,使用gizp这样常见方式,或者使用霍夫曼编码这样的压缩算法,还有一些基于经验的压缩算法
常见压缩算法浅析
- 替换:比如'hello lile';'hello hanmeimei'这两句话中hello这个单词同时出现我们是不是可以用假设用h1代替,那么数据就会变成 'h1 lile';'h1 hanmeimei'这样就实现数据压缩
- 二进制:上面的压缩还不是极致,如果使用0,1表示呢?数据结构更小。
- 基于数据相关:可以分析整个需要压缩的文本,hello 出现的比例比例越高,他对应的压缩替换字符就短,这样压缩的效果就越好。
- 基于经验数据:例如假设所有文章中 魑魅魍魉 这四个字永远是一起出现的,那么是不是就可以用 魑 一个字表示呢,或者假设数据中相邻的12345永远连在一起,那么是否根据3推测相邻的数据
- 其实我啥也不会,这些也就是我浅显的一个理解哈哈!!!

百尺竿头更进一步
- 难道这些就是我的尽头了吗?
- 有天突然我就想到一个场景,就是可以通过机器学习把几个G的高清视频保存为几百M,然后还可以还原播放!这个场景跟我现在岂不是很相近?
绝知此事要躬行
- 由此推彼:思考一下,我们整个场景肯定不是媒体压缩的场景,但是也是相近的
- 化繁为简:开始想到的视频肯定不是我们需要对标的场景,我们降一个维度,把视频换成图片,再把图片换成图形,一步一步的降低问题的复杂度,降低数据的维度,我们把压缩视频的场景降低到一个压缩图片的场景,再把一个压缩图片的场景降低到压缩图形的场景。
- 抽象思考:图片的本质是什么,如果是一个25像素的图片,它用数学是应该如何表示?是不是一个25*25的矩阵,每个点是不是0-255的像素值,还是太抽象了,看个图
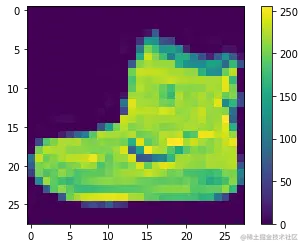
- 以终为始:假设图片可以用这样的抽象数据表示[[1,2,3,4],[1,2,3,4],[1,2,3,4],[1,2,3,4]],是不是跟之前的画笔数据[[1.123,2.342],[3.123,4.342]] 有些相似,既然视频可以压缩,那图片也可以压缩,那更简单的画笔数据肯定能压缩啊
- 寻找资料谷歌文档1,谷歌文档2,谷歌文档3等等等!!!
- 但是看了之后,蒙圈了,看不懂(数学好,真的是决定了程序员的上限)

放弃?怎么可能!
- 不管是否是程序员,我相信一点解决问题能力才是一个人职场的核心竞争力。正如我面试的时候特别喜欢一个面试者这样的回答:我不会但是我猜测一下是不是这样可以实现?而不是上来我不会,想不到就结束了。这样的面试态度也可能是工作态度,遇到解决不了的问题难道就不解决了,错了,不管职场也好,生活也好其实都是一定程度的结果导向型的,扯远了!
- 看了那么多也不是一点思路没有?至少我学到了一个新的知识叫做伪代码
- 其实目标不是很明确吗?难道我们不是需要把数据压缩,然后传输,接收数据,再还原数据,再渲染?我们解决的核心问题就是输入输出的问题!第一阶段大数据输入,小数据输出;第二阶段小数据输入,大数据输出!
- 核心实现是不是如下
const outputDraw = D(inputDraw)
const outputShow = E(outputDraw)

具体实现思路

- 扩展想象:难道仅限画笔数据吗?肯定不是!!!直播视频流传输是不是也可以使用这样的方式提示传输效率,正如硅谷电视剧中的剧情一样。
代码实现(参数调优就不写了)
import tensorflow as tf
from sklearn.decomposition import PCA
import numpy as np
x1 =[(1,2),(3,4),(5,6),(7,8)]
x2 =[(9,10),(11,12),(13,14),(15,16)]
x = x1 + x2
x = np.array(x)
print(x)
[[ 1 2]
[ 3 4]
[ 5 6]
[ 7 8]
[ 9 10]
[11 12]
[13 14]
[15 16]]
pca = PCA(n_components=1)
y = pca.fit_transform(x)
print(y)
[[ 9.89949494]
[ 7.07106781]
[ 4.24264069]
[ 1.41421356]
[-1.41421356]
[-4.24264069]
[-7.07106781]
[-9.89949494]]
x_train = [[[1,2],[3,4],[5,6],[7,8]],[[9,10],[11,12],[13,14],[15,16]]]
y_train = [[[9.89949494],[1.41421356]],[[-1.41421356],[-9.89949494]]]
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(4, 2)),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(256, activation='relu'),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(32, activation='relu'),
tf.keras.layers.Dense(16, activation='relu'),
tf.keras.layers.Dense(2, activation='relu'),
tf.keras.layers.Reshape((2,1))
])
print(model.output_shape)
print(model.input_shape)
model.compile(
optimizer='adam',
loss='mse',
metrics=['mae', 'mse']
)
model.fit(x_train, y_train, epochs=100,batch_size=1)
z = [[(1,2),(3,4),(5,6),(7,8)]]
train_datas = np.asarray(z)
predictions= model.predict(train_datas)
print(predictions)
[[[9.896617]
[0. ]]]
x_train = [[[9.89949494],[1.41421356]],[[-1.41421356],[-9.89949494]]]
y_train = [[[1,2],[3,4],[5,6],[7,8]],[[9,10],[11,12],[13,14],[15,16]]]
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(2, 1)),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(256, activation='relu'),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(32, activation='relu'),
tf.keras.layers.Dense(16, activation='relu'),
tf.keras.layers.Dense(8, activation='relu'),
tf.keras.layers.Reshape((4,2))
])
print(model.output_shape)
print(model.input_shape)
model.compile(
optimizer='adam',
loss='mse',
metrics=['mae', 'mse']
)
model.fit(x_train, y_train, epochs=100,batch_size=1)
z = [[[9.896617],[0]]]
train_datas = np.asarray(z)
predictions= model.predict(train_datas)
print(predictions)
[[[1.1542983 0. ]
[3.2397153 4.428882 ]
[0. 6.42444 ]
[7.5104036 8.566071 ]]]
总结
- 技术一定要基于场景,不管设计模式也好,机器学习也好,都是基于当前业务的场景,不能说我学了机器学习,所以要在后端管理系统搞个机器学习,不管我就要!
- 技能和知识的广度会提供更多的解决方案,在众多解决方案中寻找最优解!
- 不管是基于CNN,RNN还是真正专业的机器学习用法一定是比我写的更好的,这也是自己不断努力的方向,做一件事做好的时间是十年前,其次是现在!
- 希望自己在前端领域中机器学习最牛B,在机器学习领域中前端最牛B,加油加油!


