什么是无监督学习
无监督学习是一类用于在数据集中寻找模式的机器学习技术。
无监督学习算法使用的输入数据都是没有标注过(及没有label)的,
这意味着数据只给出了输入变量(自变量),而没有给出相应的输出变量(因变量)。
人工智能研究的领军人物Yan Lecun解释道:
无监督学习能够自己进行学习,而不需要告知他们所做的一切是否正确,这是实现真正的人工智能的关键!
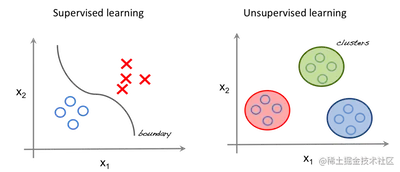
监督学习 VS 无监督学习
在监督学习中,系统试图从之前给出的示例中学习。(这些示例已经被标注过了)
而在无监督学习中,系统试图从给定的示例中直接找到模式。
因此,如果数据集被标注过了,这就是一个监督学习问题;
而如果数据没有被标注过,这就是一个无监督学习问题。
下图左侧是有监督学习,它使用回归技术找到在各个特征之间的最佳拟合曲线。
右侧是无监督学习,根据特征对输入数据进行划分,并且根据数据所属的簇进行预测。
常用的聚类算法
K-means聚类、层次聚类、t-SNE聚类、DBSCAN密度聚类
重要的术语:
示例:数据集中的一行数据。一个示例包含一个或多个特征,可能还有一个标签。
特征:进行预测时使用的输入变量。
预测值:给定一个输入示例时的模型输出。
标签:特征对应的真实结果(与预测相对应)。
什么是聚类分析
在聚类分析中,数据被划分为不同的几组。
简而言之,这一步旨在将具有相似特征的数据点从整体数据中分离出来,并将它们分配到簇中。
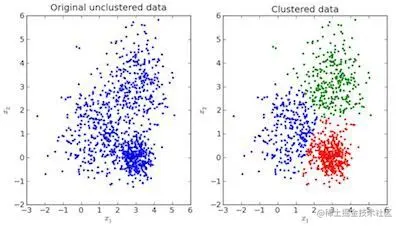
如上图所示,左图是没有进行聚类的原始数据,右图聚类之后的数据(根据数据本身的特征将其分类)。
当给出一个待预测的输入时,它会基于其特征查看自己从属于哪一个簇,并以此为根据进行预测。
层次聚类:
下图就是层次聚类
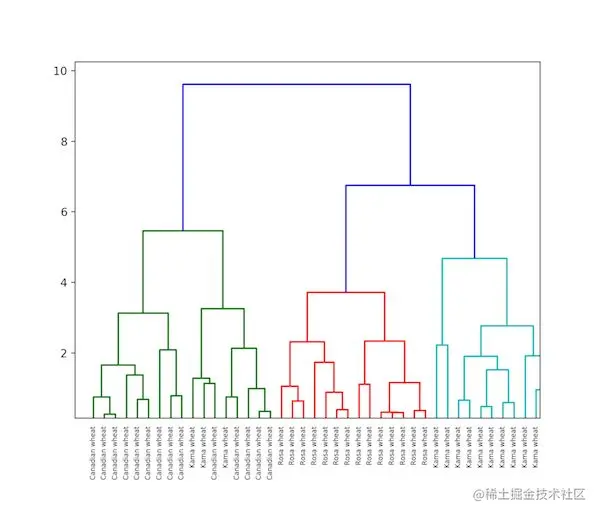
K-means聚类和层次聚类的差别
层次聚类不能很好地处理大数据(因为当数据量很大的时候,改算法会很复杂),而K-means聚类可以。
原因在于K均值算法的时间复杂度是线性的,即 O(n);而层次聚类的时间复杂度是平方级的,即O(n2)。
在K均值聚类中,由于我们最初随机地选择初始聚类中心,多次运行算法得到的结果可能会有较大差异。
而层次聚类的结果是可以复现的。
研究表明,当簇的形状为超球面(例如:二维空间中的圆、三维空间中的球)时,K 均值算法性能良好。
K均值算法抗噪声数据的能力很差(对噪声数据鲁棒性较差),而层次聚类可直接使用噪声数据进行聚类分析。
kmeans++是kmean的升级版,解决了初始聚类中心的选择问题,但是依然没有解决簇的数量的问题。
dbscan算法可以识别出噪声数据(离群点)
总结
1/k-means聚类:
对所有的数据点都会进行聚类,不能识别出其中的离群点,所以受离群点影响比较大。
每次随机选择初始聚类中心,所以每次聚类的结果可能是不同的。
需要提前指定簇的数量。
2/k-means++聚类
对所有的数据点都会进行聚类,不能识别出其中的离群点,所以受离群点影响比较大。
这一点和k-means一样,并没有改进。
相比于k-means算法,k-means++算法解决了初始聚类中心的选择问题,但是也依然没有解决簇的个数问题。
3/dbscan
基于密度聚类
可以把离群点识别出来,不受离群点的影响
需要提前指定半径和minpoints(密度阈值)


