文/ 阿里云流量产品团队 - 希贤
智能化技术迸发的时代,其在各方面的应用层出不穷,围绕「提效」二字,阿里云流量产品前端团队在丰富的中后台业务场景下,提出了一种利用图片识别技术的前端智能化代码生成方案。
在探索的过程中,随着平台能力不断的完善,对生成的代码不再满足于 React 组件 render 函数的堆砌,所以,生成符合日常开发风格的 Dva 模块此时遍刻不容缓,本文将介绍本团队 D2C 整体思路,以及大致的解决方案。
背景
Dumbo 是一个利用图像识别算法,一键生成前端代码的智能开发平台。目前已经落地于多个阿里云控制台及中后台项目。

首先,Dumbo 的基本链路为通过一张图片,利用智能化技术生成符合约定规范的 JSON 描述(即 Schema ),再通过可视化搭建平台进行人工微调修正,最后生成 React 模块代码。当然,对于一些对于设计不强烈的需求,用户甚至可以直接在搭建平台上进行拖拽,然后生成代码。
可能有人不禁疑惑,已经有了搭建平台,即说明了已经有了能让 JSON 描述直接渲染的 Runtime,为何还要再生成代码?对于中后台应用,一张静态图片对于需求的描述非常有限,此外复杂的交互场景以及非标准化的 UI 无法避免,工程师的目标是完成需求,为了避免平台过度复杂化,对智能生成的代码进行二次开发是符合团队当下人力的最优解。
思路
在实现生成 Dva 模块之前,代码生成仅仅是利用有限的 Schema 信息对于 index.jsx 的输出。此外,初步的实现中,最终的代码生成,会根据 Schema 节点,手动的去创建 AST 节点,最终根据 Schema 生成整张 AST,从而获得最终的代码。但是操纵 AST 的成本较高,再加上 AST 的可读性也几乎没有,对于某些需要优化的场景,AST 笨重且臃肿,所以此次方案摒弃 AST,参考集团的一些代码生成的经验,采用直接字符串拼接的方案。为了尽可能的减少不必要的人工干预,整体代码生成的流程,可以简单的描述为:

其中,Schema 预处理部分所处理的内容为智能算法识别后的初步补充和调整;在 Schema 预处理后,用户可以利用 Dumbo 平台,对现有的 Schema 进行一系列的人工调整干预、细节补充等,然后会进入到Schema 增强部分,主要为最后生成代码的风格做一系列的调整;最后,完成的 Schema 会包含整个项目的所有信息,拼装成代码。
方案
下面我们分别对每个步骤进行展开,简要阐述下具体的实现过程。
Schema 预处理
首先是预处理部分。对于图片识别而言,图片识别的结果为一个组件数组,组件的属性包含名字和组件的位置信息,仅此而已。通过一系列的位置处理、嵌套组装,会得到一个非常初级的,符合阿里经济体中后台标准协议规范的 Schema 树,下图中,我们描述其为 Dumbo Schema。由于图片识别无法对交互、动作等做出更深层次的判断,所以此时 Schema 树内包含的信息非常有限,为了最后生成的代码尽可能的饱满,我们需要在此处进行预处理,添加常用功能的交互动作。
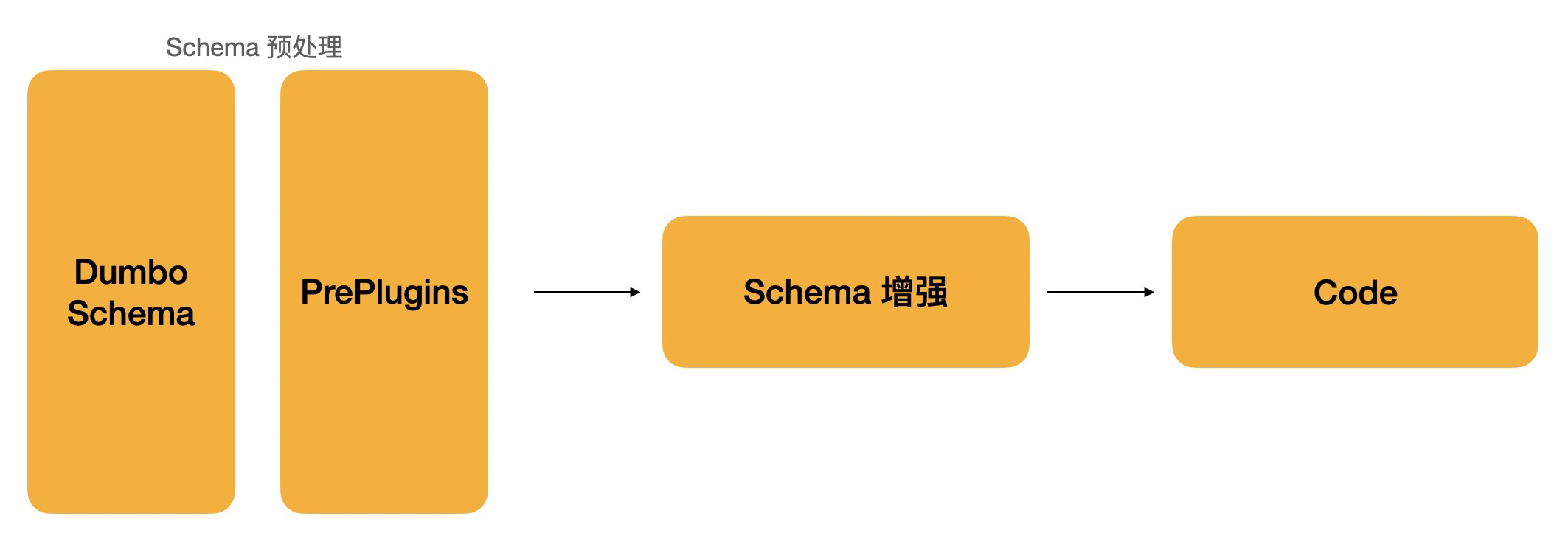
PrePlugins
我们以 Table 为例,简述下 PrePlugins 此时所完成的内容:针对 Table, 会在此处为 Table 节点添加 loading 属性,同样的属性值会置为 this.state 的对应值。会根据 Schema 上已有的信息,为 Table 节点添加 onSort、rowSelection 属性,并将属性值分别置为一个简化版的示例函数;此外,为保证 Schema 的完整性,会在 Schema.methods 上挂载 fetchTableData 方法,方法内会实现简单的 isLoadingTableData 联动,最后,会在 Schema.lifeCycles.componentDidMount 上调用一次 fetchTableData。
Schema 增强
在生成代码前,我们需要将初步生成的 Schema 投放到画布,用户会进行一系列的调整。调整后的 Schema 到到代码仍有一系列的问题需要处理,主要工位为代码风格的修正、对 Dva 的支持等。这里是最后操纵 Schema 的阶段。增强后的 Schema 会直接进行遍历从而生成对应的代码 Chunk,最后拼接成完整的代码。
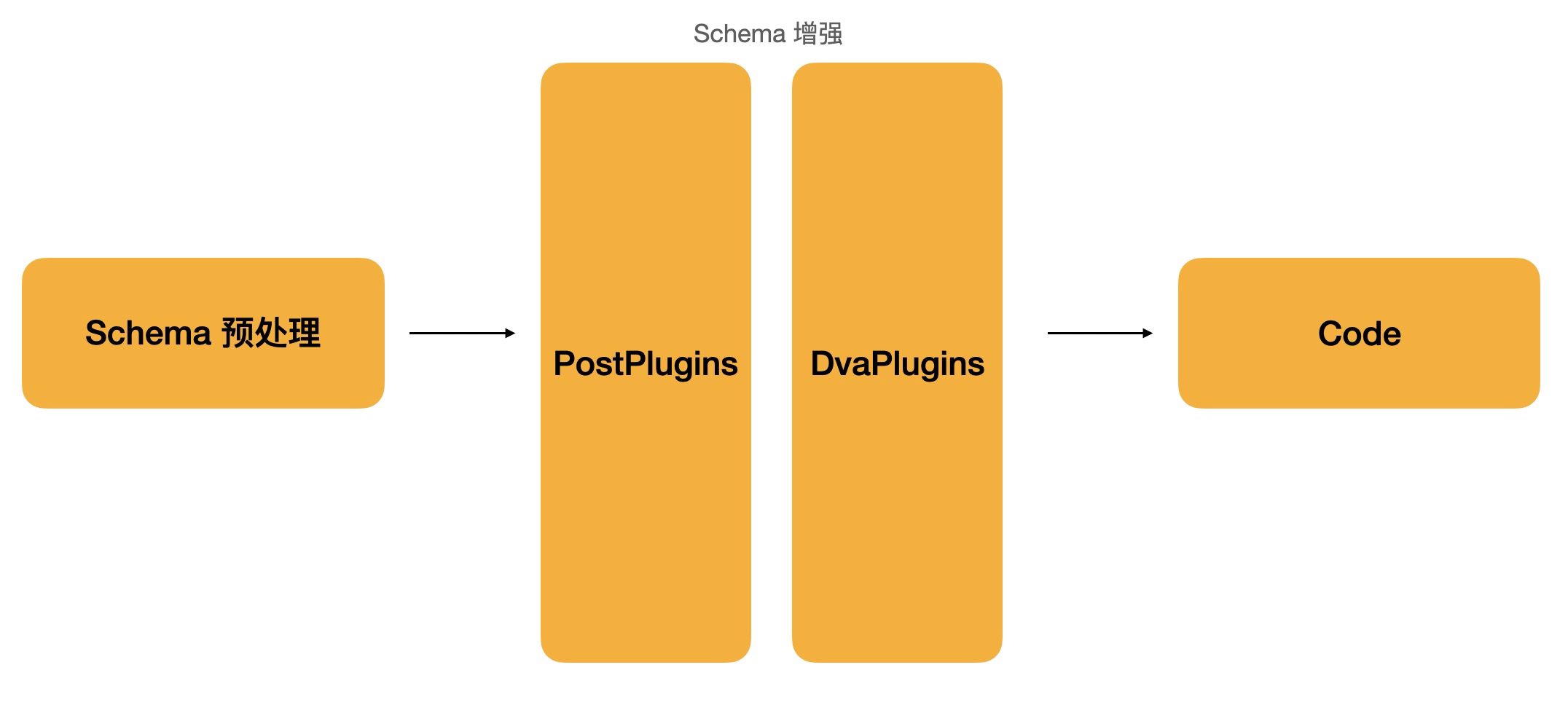
PostPlugins
这里仍以 Table 为例,简述下 PostPlugins 此时所完成的内容:在 Table 场景下,如果按照默认的代码输出格式,整个 Table 和 Table.Column 会直接输出,不符合我们正常的代码编写风格,这里需要将 Table 下的所有子元素提取出来,以 map 的形式加入到循环中去。
DvaPlugins
原则上,DvaPlugins 也应该属于 PostPlugins 的一种,由于其特殊性,这里单独说明下。需要指出的是,此时的 Dva model 设计,是有一定不足的。
原则上,action 以及 sage 的出现,需要大量承担业务逻辑,从而保证视图层的简洁。但是由于目前的搭建画布上对于整个前端应用的上下文掌控有限,即使完成了 Dva 模块的最终生成,结果仍然是单页单独的 store,且 store 也只处理了异步请求的情况,对于业务逻辑的承担非常小。在 Dumbo 中,由于逻辑的多样性,只能在这种“风格”下完成 model 的生成,实属无奈。
以目前团队项目为例,一个正经的 dva 模块,包括 actions.js、index.js、model.js、selectors.js、service.js 这 5 个文件,其中 actions.js、selectors.js 中的内容相对固定,index.js 为页面主体内容,service.js 为页面发起请求的集合,而 model.js 则为 dva 生成的重中之重。
既然所有的 dva 围绕异步数据生成,则所有数据的交互请求,都可以根据集团规范 Schema 中的 dataSource 属性来配置。在生成代码的逻辑里,为了更好的输出 Dva 模块中副作用函数,以及对于 model 中 State 的初始化,我们约定数据源的 ID 为 xxxTypeAsync 的格式。其中,xxx 为用户自定义的数据名,请使用小驼峰的命名格式;Type 为数据类型;Async 为固定标识;生成的代码里,会将 api 返回的 data 字段下的所有内容挂载到 state 上,对于不需要挂载到 state 上的副作用,请将 xxxTypeAsync 中 xxx 以 set 开头。
dva 模块生成设计的基本原则,是保证画布正常渲染。也就是所有的配置,需要保证在画布能够直接运行正常且生效,导出的代码才会正常。
Code 生成
到此为止,Schema 包含了画布上已有内容的所有信息。这里我们需要遍历 Schema 的每一个节点,将每个节点拼接生成一个 Chunk 对象。每个 Chunk 对象至少包含 name、content、linkAfter 三个属性,分别表示当前 Chunk 的名字,当前节点所表示的代码片段,以及该 Chunk 的位置。其中,linkAfter 中为 其他 Chunk 对象 name 属性的数组,用来表示当前的 Chunk 应该出现在这些内容以后,用以控制 Chunk 输出顺序。content 的拼接过程,主要为节点的递归拼接过程,每个独立的节点可以通过摒弃上线文信息独立的表示出当前节点所代表的代码片段,耐心处理边界条件即可。
拼接过程,是多次循环遍历 Chunk 的过程。每次循环,会找到所有 linkAfter 的长度为 0 的 Chunk,记录其 name, 将其 Content 拼接到结果字符串中,然后删除其他所有 Chunk 的 linkAfter 中的该 name。如此这般,直至所有 Chunk 的 linkAfter 皆为空,然后按照顺序完成最终的拼接,即为生成的代码。
示例
千言万语不及一颗栗子。
初始请求
根据规范,数据配置只能在最外层的 Page 节点上,所以先点击画布最外层的 Page 容器;然后,点击右侧配置插件中的“数据”;最后,点击新增自定义数据源,即可打开数据配置表单。
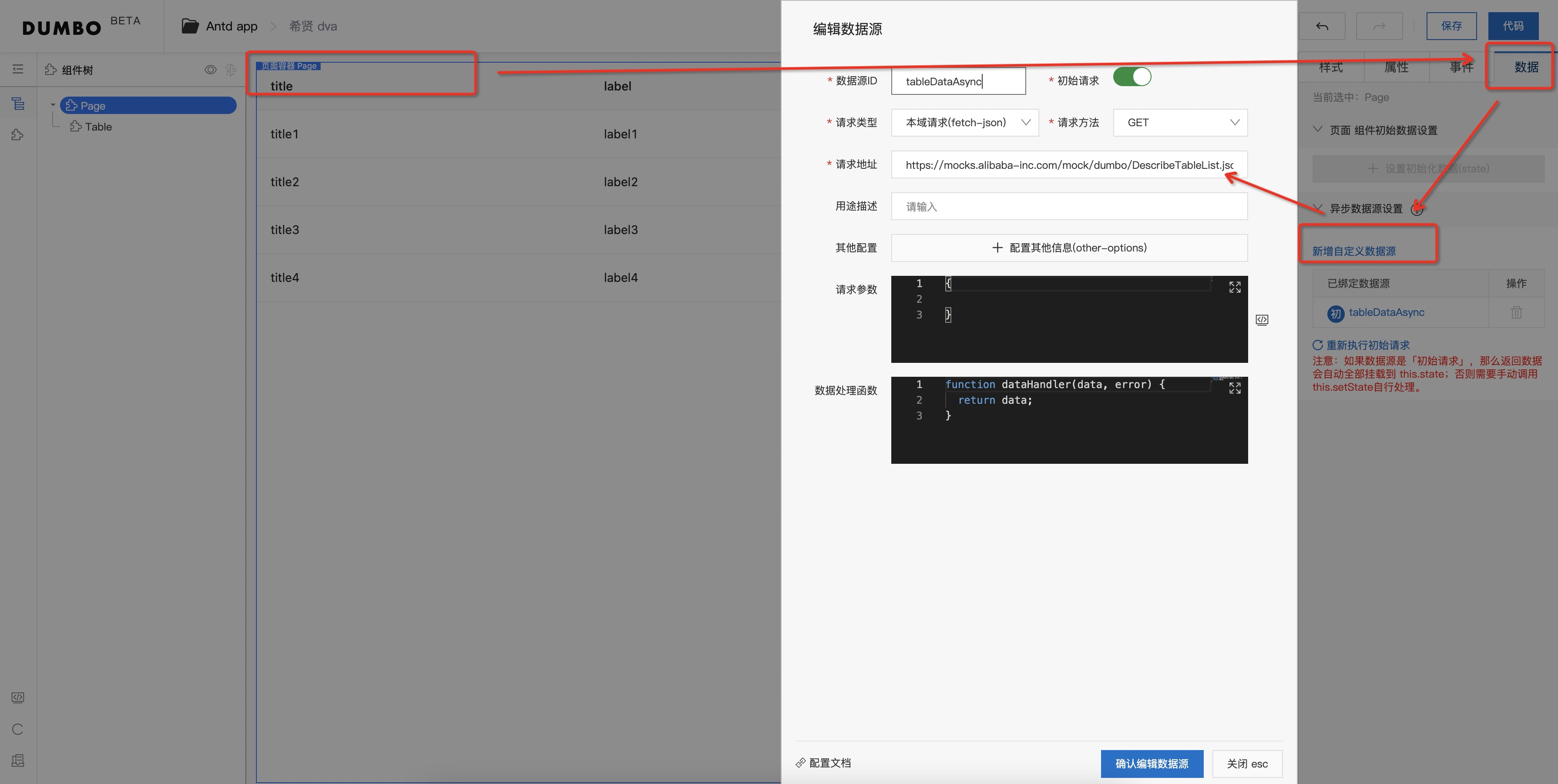
简单填写后,画布上,我们拖进来一个 antd 的普通 Table,编辑右侧属性中的表格列配置,根据接口字段,调整 Table 的列配置。在数据数组这里,选择使用变量,填充 this.state.tableDataAsync.data.List,来看下这个字段,看着很长,不要孩怕,tableDataAsync 就是刚刚我们起的数据源ID,后面的 data.List 为数据源的字段层级。
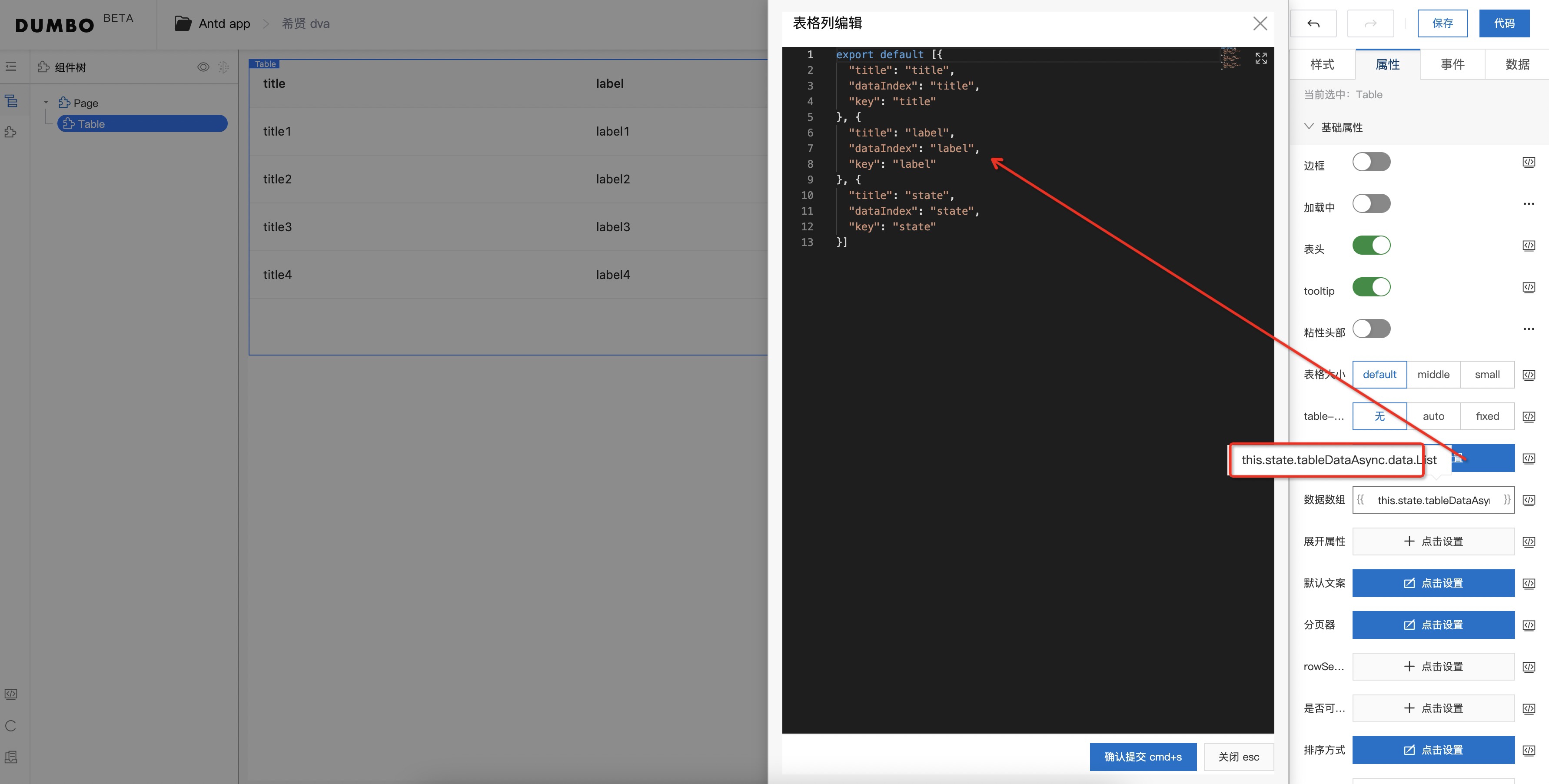
此时,画布已经被真实数据渲染。
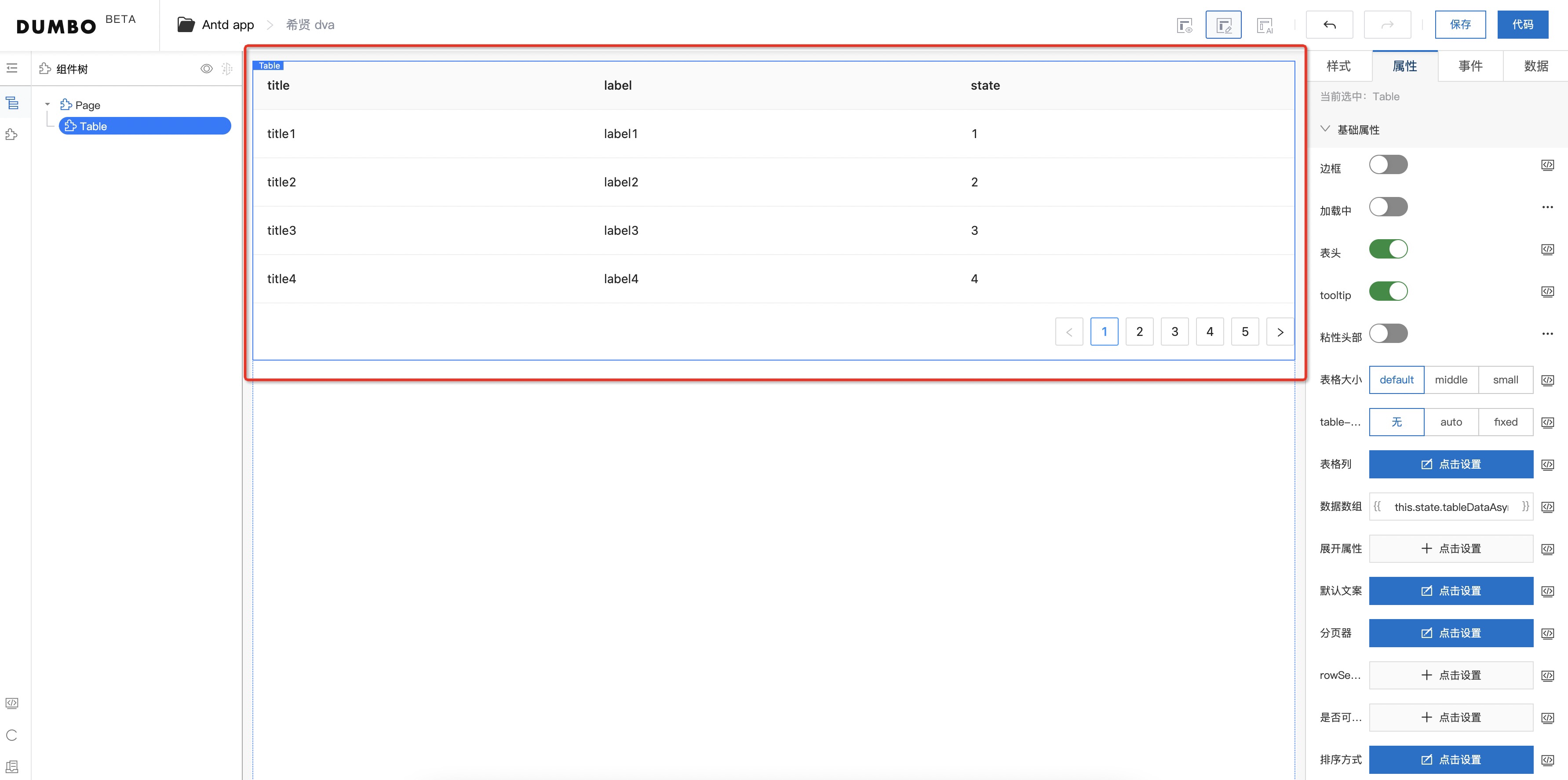
数据源主动触发
现在我们对表格进行翻页配置,同样的是上面的 Table 组件,在右侧 属性 下面,点击分页器,添加分页器的 onChange 属性,这里注意调用方式
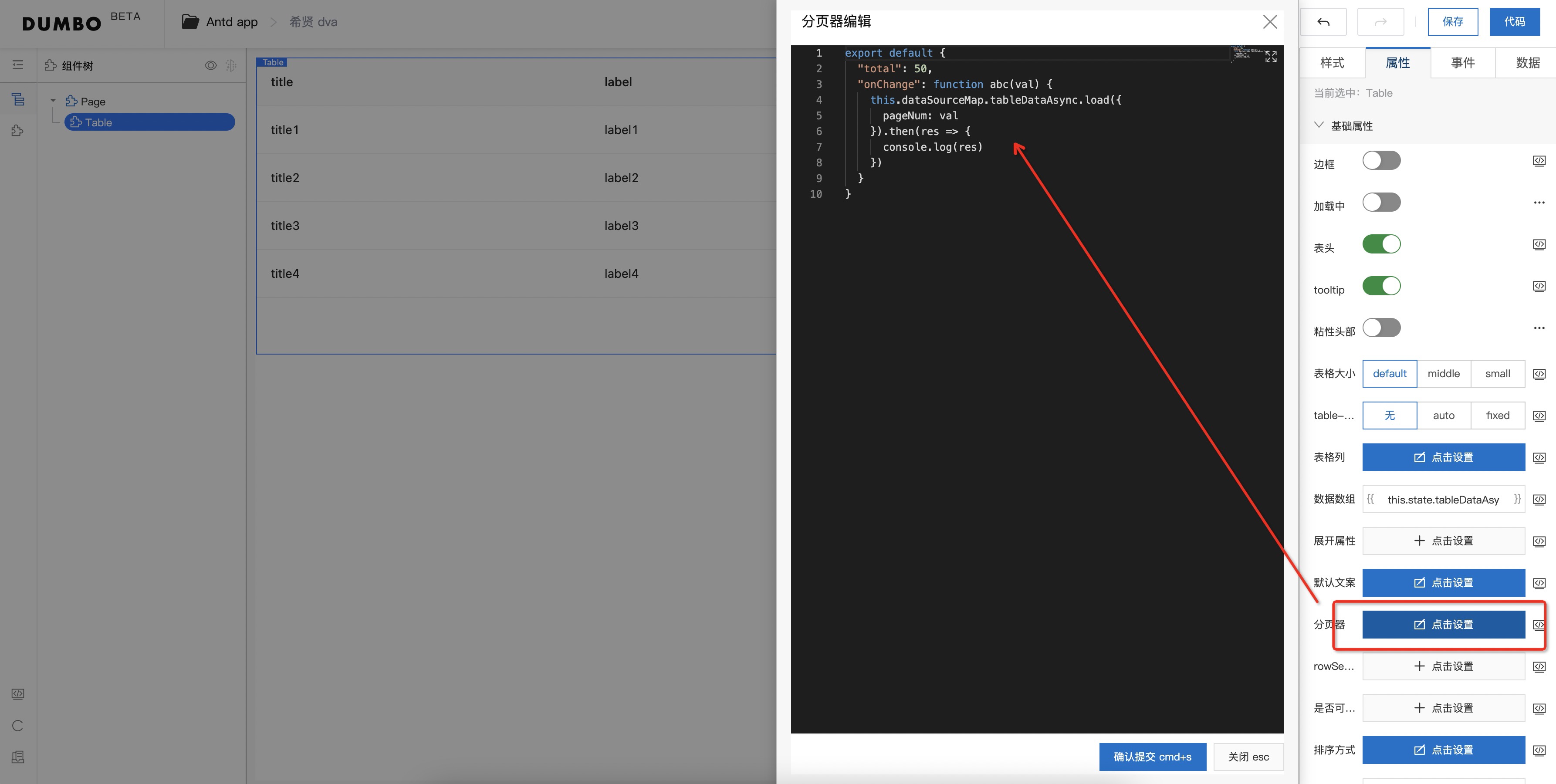
根据集团规范,数据源的调用,必须使用 dataSourceMap 作为标识。这里 tableDataAsync 仍然为上面配置项中的数据源 ID,调用 load 方法,进行传参即可。此外,load 方法返回为 promise,支持 then 链式调用。如果需要在 then 后继续请求,则继续嵌套 load 函数即可。
function(val) {
this.dataSourceMap.tableDataAsync.load({
pageNum: val
}).then(res => {
this.setState({
tableDataAsync: res
})
})
}
查看代码
最后点击右上角的查看代码,即可得到
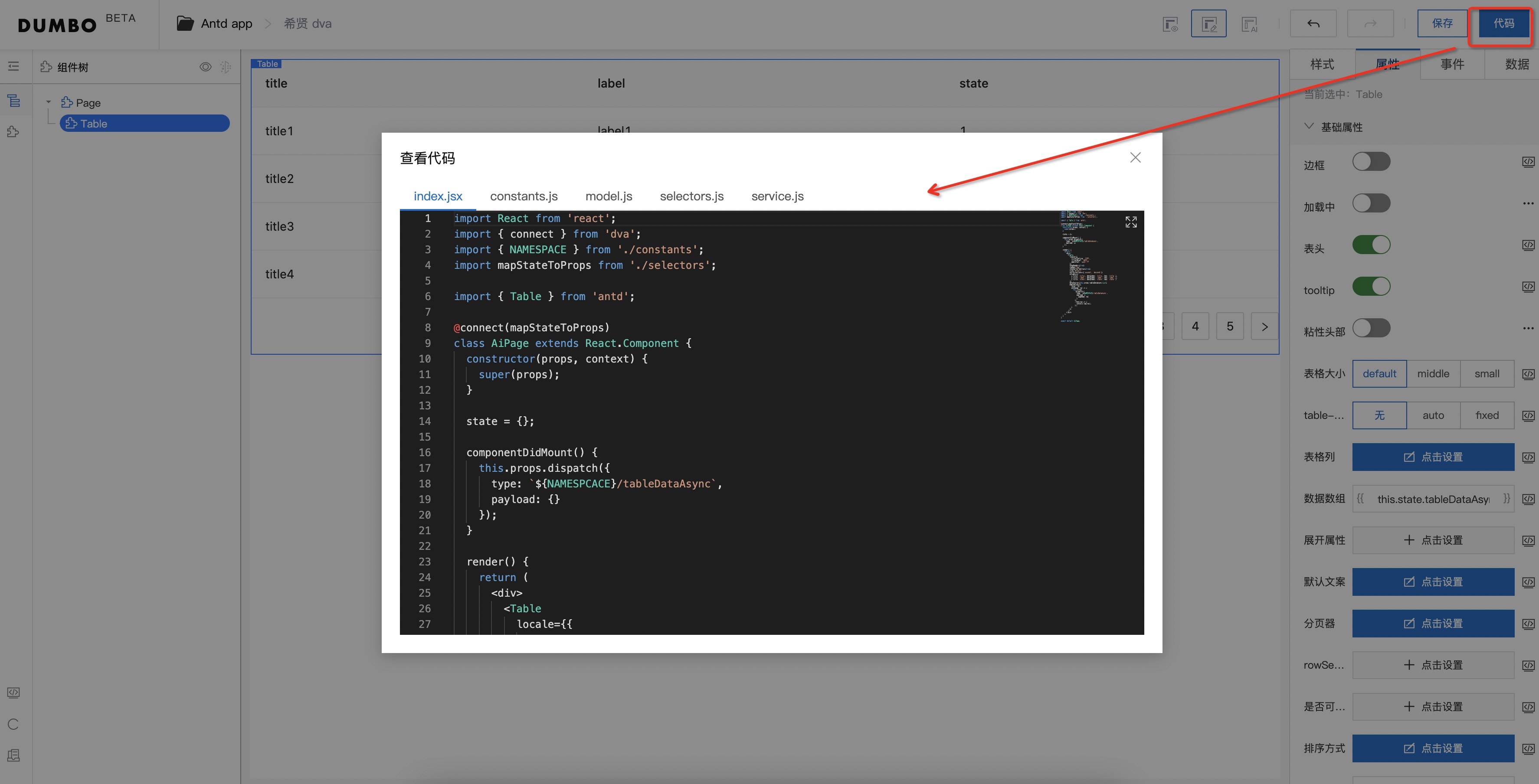
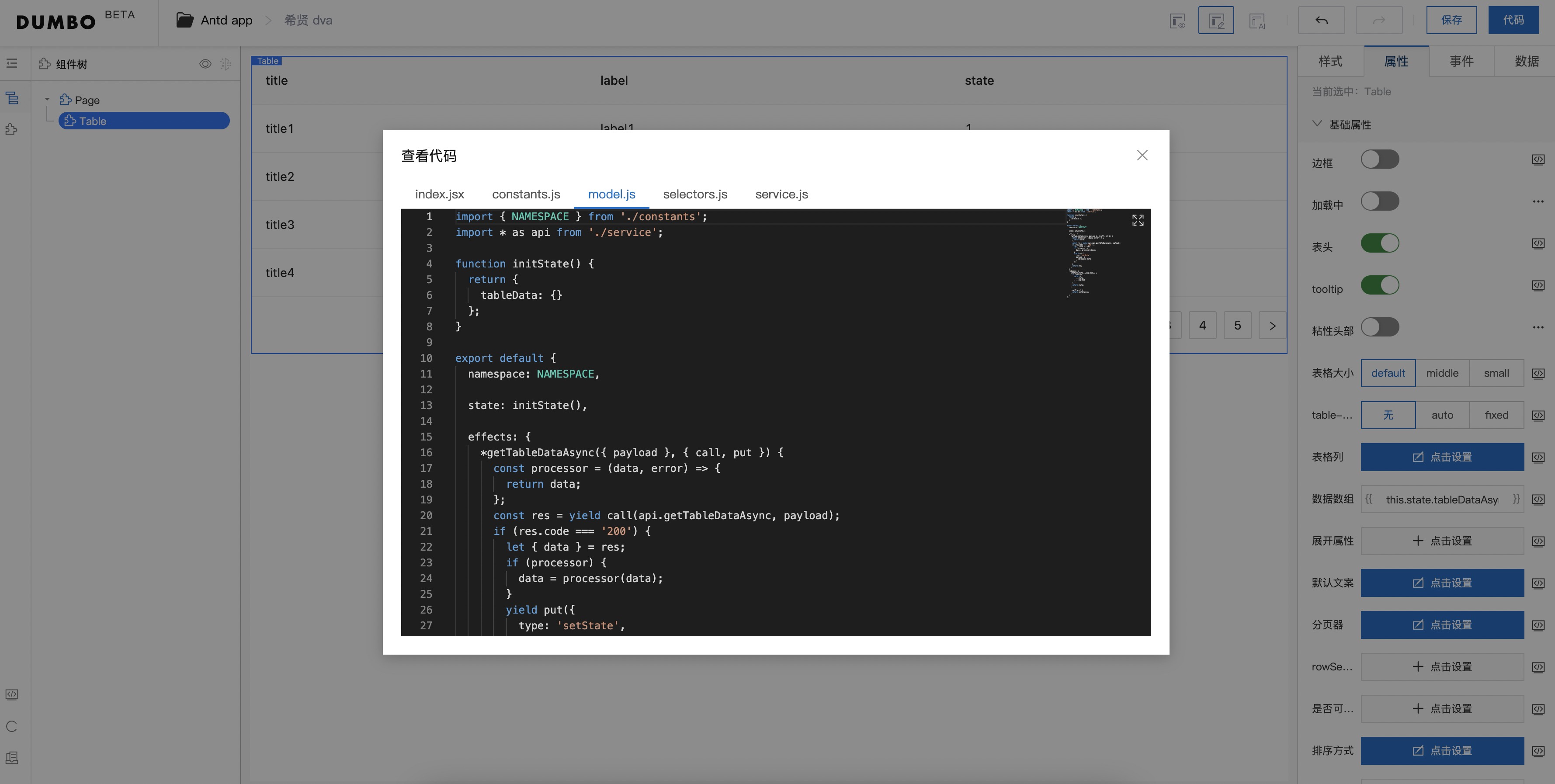
最后代码生成的细节处理这里再次强调下:
- 所有的数据源 ID 需要符合 xxxTypeAsync 的格式。
- 副作用的命名为 get${数据源ID},且默认会将返回数据的 data 内容挂载到 state 上,也就是 res.data,注意接口的返回。
- 如果数据源 ID 为 /^set(\w+)/,则不会有挂载到 state 的操作。
- index.jsx 中的代码,目前只是控制了跟数据源 ID 有关 state,会转成对应的 props,其他的暂无处理,后续是否将所有 state 投放到 model 中,需要额外讨论。
问题
- 数据定义后,根据集团 dataSource 规范,在非初始化请求的情况下,需要使用 this.dataSource['xxxTypeAsync'] 进行触发,对于非前端同学使用有一定的复杂度。
- 生成的 Dva 模块是根据 Schema 上的信息进行处理,对于 dva 原本应该承担的业务逻辑,暂时没有太好的办法。
- 目前画布上 dataSource 的 uri 需要接口自身支持 cors 跨域。
展望
目前画布侧所有的操作,都是依靠集团规范进行统一处理,为了配合生成 Dva 模块代码,我们做了一系列的约定。数据相关的配置完成后,需要在按照约定主动调用配置的数据,用以在页面中触发 Ajax 的调用,后续会在这里持续关注,优化使用方式。此外,后续数据接口的转发关会通过网关来支持,对实现真实数据的转发操作,完备画布和代码。
最后,感谢您能读到最后,目前整个项目仍然处于高速迭代中,我们有很多想法,因为人力问题做了不少妥协,如果您感兴趣,愿意和我们一起利用智能化技术在前端做一点点小事,请随时联系 yaoli.pt@alibaba-inc.com,期待在智能化的道路上,我们一起前进!