参考网址
zhuanlan.zhihu.com/p/58160982
1/什么是FM算法
FM即Factorization Machine,因子分解机
2/为什么需要FM
1/特征组合是许多机器学习建模过程中遇到的问题,如果对特征直接建模,很有可能忽略掉特征与特征之间的关联信息,因此可以通过构建新的交叉特征这一特征组合的方式来提高模型的效果。
2/高维的稀疏矩阵是实际工程中常见的问题,并且直接导致计算量过大,特征权值更新缓慢。
试想一个10000100的表,每一列都有8种元素,经过one-hot编码之后,会产生一个10000800的表。因此表中每一元素只有100个值为1,700个值为0
3/而FM的优势就在于对这两方面问题的处理。首先是特征组合,通过两两特征组合,引入交叉项特征(二阶特征),提高模型得分;其次是高维灾难,通过引入隐向量(对参数矩阵进行分解),完成特征参数的估计
3/FM用在哪
我们已经知道FM可以解决特征组合以及高维稀疏矩阵问题,而实际业务场景中,电商、豆瓣等推荐系统的场景是使用最广泛的领域,
打个比方,小王只在豆瓣上浏览过20部电影,而豆瓣上面有20000部电影,如果构建一个基于小王的电影矩阵,毫无疑问,里面讲有199980个元素全为0.而类似这样的问题就可以通过FM来解决
1/什么是fm模型
什么是FM模型呢?FM英文全称是“Factorization Machine”,简称FM模型,中文名“因子分解机”。
FM模型其实有些年头了,是2010年由Rendle提出的,但是真正在各大厂大规模在CTR预估和推荐领域广泛使用,其实也就是最近几年的事。
2/从lr到svm到fm模型
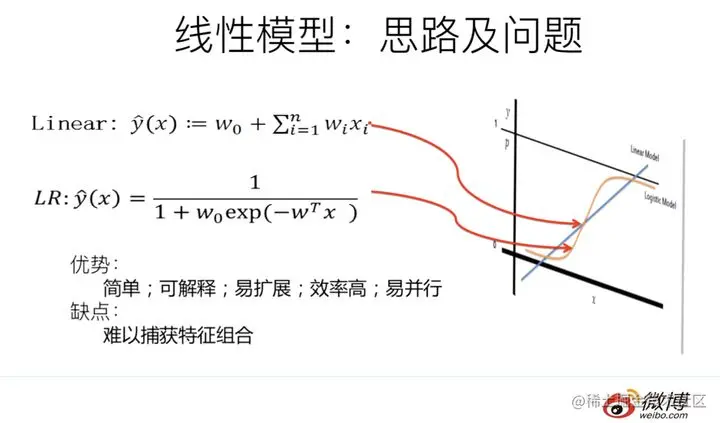
LR模型是CTR预估领域`早期`最成功的模型,大多工业推荐排序系统采取LR这种“线性模型+人工特征组合引入非线性”的模式。
因为LR模型具有简单方便易解释容易上规模等诸多好处,所以目前仍然有不少实际系统仍然采取这种模式。
但是,LR模型最大的缺陷就是人工特征工程,耗时费力费人力资源,那么能否将特征组合的能力体现在模型层面呢?

其实想达到这一点并不难,如上图在计算公式里加入二阶特征组合即可,任意两个特征进行组合,可以将这个组合出的特征看作一个新特征,融入线性模型中。
而组合特征的权重可以用来表示,和一阶特征权重一样,这个组合特征权重在训练阶段学习获得。
其实这种二阶特征组合的使用方式,和多项式核SVM是等价的。
虽然这个模型看上去貌似解决了二阶特征组合问题了,但是它有个潜在的问题:它对组合特征建模,泛化能力比较弱,尤其是在大规模稀疏特征存在的场景下,这个毛病尤其突出,比如CTR预估和推荐排序,这些场景的最大特点就是特征的大规模稀疏。
所以上述模型并未在工业界广泛采用。那么,有什么办法能够解决这个问题吗?
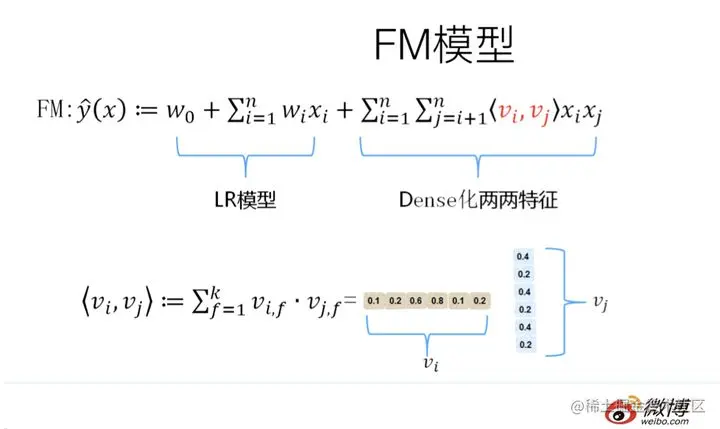
于是,FM模型此刻可以闪亮登场了。
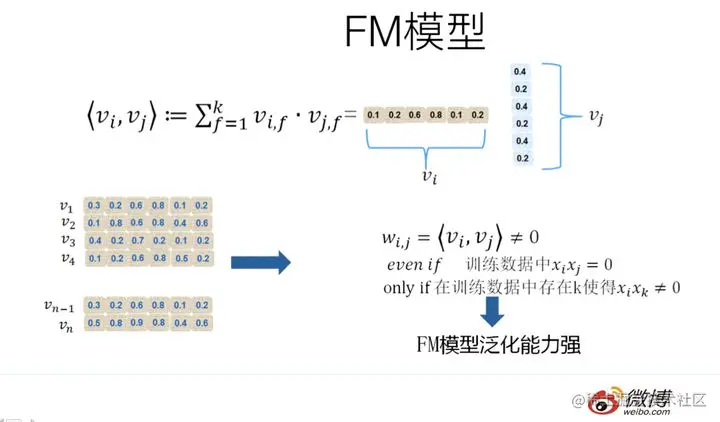
如上图所示,FM模型也直接引入任意两个特征的二阶特征组合,
和SVM模型最大的不同,在于特征组合权重的计算方法。
FM对于每个特征,学习一个大小为k的一维向量,于是,两个特征xi 和xj的特征组合的权重值是通过特征对应的向量vi和vj 的内积<vi,vj>来表示。