


- 原文地址:JSON encoding/decoding with Python
- 原文作者:Martin Thoma
- 译文出自:掘金翻译计划
- 本文永久链接:github.com/xitu/gold-m…
- 译者:洛竹、雪刺
- 校对者:Zoe
REST API 是 在全世界使用标准化的消息格式。JSON 是互联网上数据交换的基石,作为 JavaScript 的一个子集,它从一开始就获得了巨大的推广。它特别清晰易读的语法也有利于推广。
据我所知各种语言都有 JSON 库用于序列化和反序列化。实际上在 Python 中就有很多种 JSON 库。在下文中,我将为大家比较它们的异同。
引用库
CPython 本身具有一个 json 模块。它最初是由 Bob Ippolito 作为 simplejson 开发的,并被合并到 Python 2.4 中(源代码)。CPython 遵循 Python 软件基金会(Python Software Foundation)许可协议。
simplejson 仍然作为一个单独的库存在,你可以通过 pip 安装它。它是带有可选 C 扩展的纯 Python 库。 Simplejson 遵循 MIT 和 Academic Free License(AFL)许可协议。
ujson 是对 C 语言库 Ultra JSON 的绑定。Ultra JSON 由 ESN(一家电子艺术工作室公司)开发,并获得了 3条款BSD许可。 Ultra JSON 在 Github 上拥有 3k 星,305 个 fork,50 个贡献者,最近一次提交的日期只有 12 天,而最后一次提交是在 5 天之前发布的。我听说它处于“维护模式”(来源),表明没有新的进展。
pysimdjson 是对 C ++ 库 simdjson 的绑定。 SIMDjson 从加拿大获得资助。simdjson 在 Github 上有 12.2k 颗星,611 个分支,63 个贡献者,最后一次提交是 11 小时前,而最后一个 issue 是 2 小时前创建的。
python-rapidjson 是对 C ++ 库 RapidJSON 的绑定。 RapidJSON 由 腾讯 开发。 RapidJSON 在 GitHub 上有 9.8k 个星,2.7k 个 fork,150 个贡献者,最近一次提交大约在 2 个月前,而最后一个 issue 是 17 天前创建的。
orjson 是一个 Python 软件包,依靠 Rust 来完成繁重的工作。
成熟度和操作安全性
上面所有提到的库都可以毫无问题地用作 benchmark 示例,切换 JSON 模块也不是什么大问题,但我仍然想确定相关模块是否支持。
CPython,simplejson,ujson 和 orjson 都认为他们自己已经可以投产了。
python-rapidjson 将自身标记为 alpha,但是一位维护人员说这是一个错误,并将很快得到修复(资源)。
问题
判断一个库的问题是否能够被顺利解决,一个直接的方式是直接去它的仓库创建 issue,并观察后续的跟进反馈:
- SimpleJSON:第二天我得到了答复,回答很明确,易于理解,友善。 Bob Ippolito 回答了我。他是最初开发这个库的人,并且在 JSON 模块的 Python 文档中也提到了他!
- uJSON:30分钟内,我得到了一个清晰,友好,易于遵循的答案。 @hugovank
- ORJSON:10天没有反应,然后关闭,没有任何评论。
- [PySIMDJSON]:15天后无人答复。
- Python-RapidJSON:在30分钟内,我得到了一个清晰,友好,易于遵循的答案。十天后合并了一个简单的PR。
通过以上操作我得出一个答案,它们基本上没有相互关系。
基准测试(Benchmark)
为了正确地对不同的库进行基准测试,我考虑了以下情况:
- API:交换信息的 Web 服务。它可能包含 Unicode 并具有嵌套结构。 Twitter API 的 JSON 文件听起来不错,可以对此进行测试。
- API JSON错误:我很好奇如果 JSON API 格式有错误,性能会如何变化。因此,我在中间删除了一个大括号。
- GeoJSON:我首先通过一个开源街道地图导出器 Overpass Turbo 得到了 GeoJSON 格式的 JSON 文件。你将获得疯狂多的 JSON 文件,这些文件大多具有坐标,而且还很嵌套。
- 机器学习:只是大量的浮点数列表。这些可能是神经网络层的权重。
- JSON行:结构化日志在行业中大量使用。如果分析这些日志,可能需要遍历千兆字节的数据。它们都是带有日期时间对象、消息、记录器、日志状态等信息的简单字集。
反序列化速度
我将我的硬盘驱动器的读取速度设置了一个较低的上限,在以下3个图表中将以它作为基准。
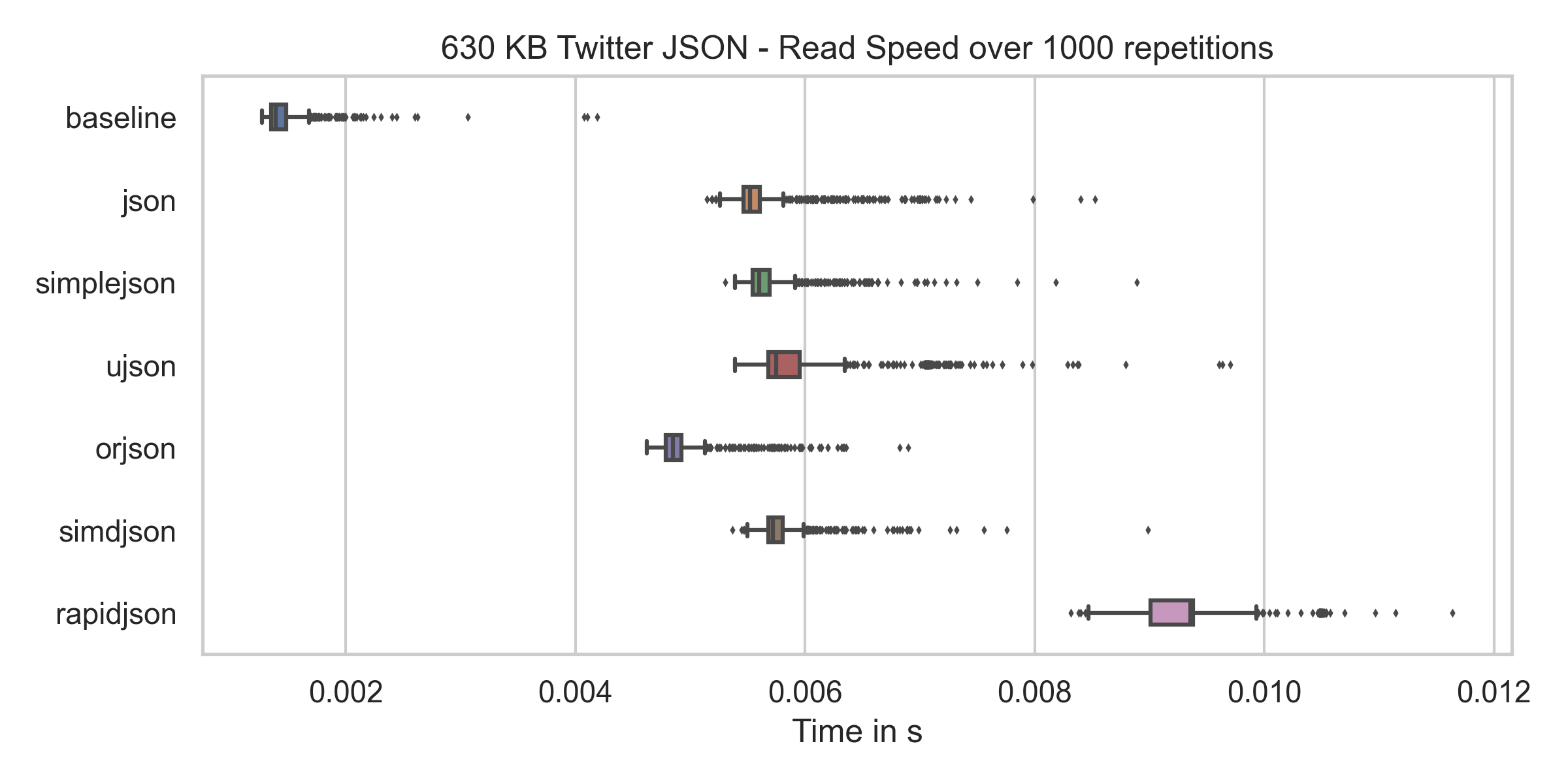
由此得出的结论是:
- Rapidjson 速度很慢,但是对于像 twitter.json 这样的小型 JSON,你不会注意到有什么不同。可以通过结构化日志看到这一点。
- simdjson,orjson 和 ujson 都快得惊人。
- 对于大多数库而言,读取包含结构错误的 JSON 文件的速度相同。一个值得注意的例外是 Rapidjson。我猜一旦发现错误,它将中止读取文件。
序列化速度
在这里,我预先创建了 JSON 字符串,并以写入磁盘的时间作为基线测量了所需的时间。
我由此得出的结论是:
- orjson 非常快,超级接近我的硬盘驱动器写入速度。 ujson 也非常接近。
- Rapidjson 也很快,但与 orjson 或 ujson 不在同一级别。
- simdjson 很慢。
专业的 JSON 工作流
最后总结一下,我想指出一些我之前看到并记录下来的问题:
-
调用变量
foo_json:JSON 是一种字符串格式。如果不是字符串,则不是 JSON。 如果使用bar = json.loads(foo)反序列化 JSON,则 bar 不是 JSON。你可以将 bar 序列化为与 JSON
foo等效的 JSON,但 bar 不是 JSON,这是一个 Python 对象,很像一个字典对象,就将它当作foo_json。 -
属性会在各处进行检查:如果你收到 JSON 数据,很轻松就可以转换为 Python 对象(例如字典)并使用它。这对于概念验证代码或很小的 JSON 字符串来说是很好的选择。如果你不将其转换为 dataclass 之类的,它将一团糟。
pydantic 是一个超级有用的验证库。你可以使用自己喜欢的 JSON 库将 JSON 字符串解析为带有 字典/列表/字符串/数字/布尔值的 Python 基本表示形式,然后再使用 Pydantic 对其进行解析。这样做的好处是你知道以后要处理的内容。不再只是将 Dict[str, Any] 用作 type annotation,不再用没用的的编辑器自动完成,不再检查属性是否在整个代码中都存在。
要引入除默认 json 以外的其他 json 包,我建议使用此模式
import ujson as json
对于 Flask,你可以使用其他 编码器/解码器,如下所示:
from simplejson import JSONEncoder, JSONDecoder
app.json_encoder = JSONEncoder
app.json_decoder = JSONDecoder
还可以看看
- Daniel Lemire: Parsing JSON Really Quickly: Lessons Learned
- Ng Wai Foong: Introduction to orjson
- Nicolas Seriot: Parsing JSON is a Minefield
如果发现译文存在错误或其他需要改进的地方,欢迎到 掘金翻译计划 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 本文永久链接 即为本文在 GitHub 上的 MarkDown 链接。
掘金翻译计划 是一个翻译优质互联网技术文章的社区,文章来源为 掘金 上的英文分享文章。内容覆盖 Android、iOS、前端、后端、区块链、产品、设计、人工智能等领域,想要查看更多优质译文请持续关注 掘金翻译计划、官方微博、知乎专栏。
