

情感分析(Sentiment Analysis)
情感分析(Sentiment analysis),又称倾向性分析,意见抽取(Opinion extraction),意见挖掘(Opinion mining),情感挖掘(Sentiment mining),主观分析(Subjectivity analysis),它是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。
- 主流思想:
基于情感词典:是指根据已构建的情感词典,对待分析文本进行文本处理抽取情感词,计算该文本的情感倾向,即根据语义和依存关系来量化文本的情感色彩。最终分类效果取决于情感词库的完善性,另外需要很好的语言学基础,也就是说需要知道一个句子通常在什么情况为表现为Positive和Negative。
基于机器学习:是指选取情感词作为特征词,将文本矩阵化,利用logistic Regression, 朴素贝叶斯(Naive Bayes),支持向量机(SVM)等方法进行分类。最终分类效果取决于训练文本的选择以及正确的情感标注。
数据集
有三个数据集,一开始我做的只有2分类和4分类。但是发现4分类的效果很差,就用9分类的数据验证一下是数据的问题还是模型的问题。
分词
中文分词可利用jieba, THULAC,ICTCLAS
jieba:易用,可以添加自定义词库或者删除“无效词”(stopwords)。自定义词库按需求添加,可以不适用;但是“无效词”表达情感时没有明确的情感指向但却很常用(词频很高),因此这些词的TF-IDF仍然可能非常高,所以需要主动删除,以避免引入噪声。
向量词构造
TF-IDF用于计算词库中最具代表性的词 。
TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索与资讯探勘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜寻引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了TF-IDF以外,因特网上的搜寻引擎还会使用基于连结分析的评级方法,以确定文件在搜寻结果中出现的顺序
模型选择
文本预处理
- 数据降维(stopwords)
- 样本不均衡 (过采样:直接复制负样本,SMOTE算法)
这里我们看到样本是不均衡,差评明显少于好评。解决的方法就是过采样。文本分类的两个思路就是词频和词向量。分别对应到朴素贝叶斯和LSTM。
朴素贝叶斯
原始数据
在样本不均衡的情况下负样本的召回率明显有问题,ROC曲线也有问题,假正率为零真正率也很小 过采样之后负样本召回率也很高,假正率为零真正率也很高
过采样之后
过采样之后召回率和f1-score 都很高。roc曲线面积也很大,假正率为零时,真正率也很大
LSTM
二分类的效果这么好呢,那么4分类呢。四分类的数据集包括:喜悦,愤怒,厌恶,低落。凭直觉来说后面三类应该不是那么好区分。
微博四分类数据
再来看一下微博的长度,主要集中在50-100.这里就把很多的特征不明显的微博剔除掉。
训练集loss慢慢减小,验证集loss逐渐增大。说明有问题,一可能是模型过拟合,二可能是数据集本身有问题
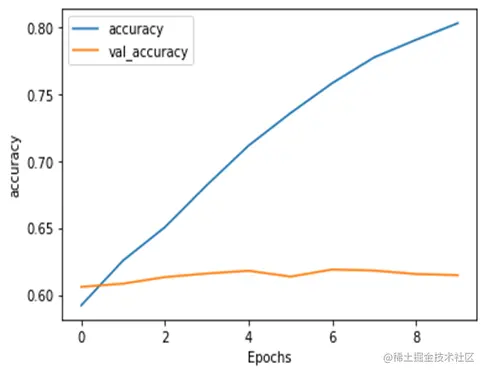
除了喜悦,其他三类召回率和精准率都不是很理想。
文本9分类
训练loss减少,验证loss增加。要么是模型有问题,过拟合化,要么是数据本身就有问题。然后我就找了一个9分类的数据集。
