

ViTransformer深入浅出一_ViT入门讲解
This article was original written by Jin Tian, you are welcomed to repost, first publish at blog.tsuai.cn. Please keep this copyright info, thanks, any question could be asked via wechat:
jintianiloveu
在很久很久以前,我写了一篇: <万字长文讲解transoformer>的文章, 那篇内容大多是综述性质的东西,未曾从算法层面去讲解,也没有详细的介绍现在的transformer的进展,以及哪些结构目前来说比较优化. 这篇文章力求给大家一个比较详尽的全貌, 这当中将会包含的内容比较分散, 主线当然是你可能能够从文章得到的答案的这几个问题:
- 我想知道Vit怎么运用? 它的基本结构, 输入输出等;
- 什么是Vit Token, 这个和火币的那个区块链token有啥区别;
- 这些token有哪些玩法;
- 什么是最优传输算法,它和transformer有啥关系.
- 拷问灵魂的问题: transformer的本质是什么?
- 为什么说距离问题是现代机器学习问题尤其是GAN以及transformer的奠基石;
- 那么GAN和Transform又存在哪些联系呢? 你为什么要提到GAN呢?
- Transform可以和CNN一样来分割或者回归吗?挑战是什么?
- ...
FBI WARNING: 本文为一系列VisTransformer的基础入门文章, 包含大量非公式性数学原理(人话), 里面也包含大量连我自己都看不懂的术语, 可能夹杂着一些有误导性的个人主观见解, 通篇也可能毫无逻辑废话连篇甚至味同嚼蜡, 请大家谨慎使用, 也欢迎大家评论礼貌探讨. 但你看完我保证你醍醐灌顶, 会有打通任督二脉之感, 如有感觉, 请点赞加转发加评论三连. 也不枉我写这篇文章写了三天三夜....
带着这一系列疑问, 我想先从大家熟知的东西开始讲起, 不是CNN, 也不是GAN, 而是电商.咋回事?现在全民拼多多了?当然不是,我们要谈论的是电商里面一个很经典的问题: 仓库配送问题. 简单来说,这个问题是这样的:
我们有M个仓库,例如假设全国我们有100个仓库,然后我们现在899个客户在订阅我们的放在仓库里面的产品,例如说GTX3090的显卡. 那么现在的问题是,我们想要传输成本最低,因为每个仓库都有一个和每一个客户的距离,我们想让每个客户都能从最近的仓库拿到货,这样就实现了距离和时间最优.这个问题的约束就是每个仓库存储的GTX3090是有数量限制的.那么问题来了: 如何设计一套仓库调配方案,使得总的成本最低,同时每个用户又能拿到心爱的GTX3090.
我相信许多人其实知道这个问题,或者遇到过这种问题的变体,这本质上就是一个动态规划问题,在约束条件下寻找最优解,当然这种问题不一定有最优解,也可能具有多个不同的最优解.我们为什么要在将Transform的时候讲解这个问题呢?准确的来说,我们要讲解并不是Transform这个架构,而是一个从0开始的机器学习里 "分布拟合" 问题的总结和回顾, 再由浅入深的把这一整条知识脉络连接成线, 不然我直接丢给你一个Sinkhorn Transformer, 你肯定以为我是因为基金下跌而疯了的人. 其实这个问题, 本质上我们可以理解为分布的转换问题,怎么说呢. 你可以这么理解,卡在仓库内是一种分布,在用户手里是另外一种分布,而最优的配送方案就是这个最优传输问题也就是分布转换问题的最优解. 很好,能理解到这一步我们已经前进了一大步,接下来是另一个遗失的概念,也就是距离,上面那个所谓的代价,事实上大部分机器学习的分布转换问题都可以归结为"距离问题". 很多人可能会说了,距离问题不是很简单吗?L1 L2我都知道, 我还知道很多其他的距离,那我问你,你知道每一个距离背后的数学理论吗?他们对于分布的转换或者评价有什么影响吗?为什么说KL散度虽然可以表征两个分布的差别但却不是距离? 为什么两个正态分布,其中一个是另一个的极小平移, 计算二者的KL却可能是无穷大?
事实上, 所有距离的评价指标都应该满足对称性,因为你从A搬运到B和B搬运到A应该是一样的,否则这个距离就无意义.因此你回过头去看KL散度这个指标就是非对称的,我从p到q的互信息和q到p的可能就是不一样的值,这样就是为什么GAN里面不会用KL散度, 也不会用JS散度, 而是用EM(Wasserstein)距离来衡量生成器和判别器的相似度.
我们都知道WD在GAN中彻底解决了它的梯度爆炸问题, 并且非常适用于在其他衡量两个分布相似度的场合, 即使他们之间没有交集. 但WD在几何上却有着极其深刻的内涵, 如果是x是一个黎曼流形, P(x) 是x上面的概率测度所构成的空间, 如果P(x)上的距离就是Wasserstein distance, 那么相对熵在P(x)上具有凸性 和 x具有非负Riccci曲率是为等价结论.
一不小心又把GAN复习了一道, 有人要问了, 你这和Transformer有啥关系呢? 有关系, 我们之所以提到WD是因为我们要讨论 最优传输问题. 我们再回到这个问题. 我们接下来要进一步探讨这个问题, 前面已经给大家回顾了KL散度以及WD距离, 那么Wasserstein距离是万能的嘛? 它又具有什么局限性呢?
引入Sinkhorn描述
先来回答一下上面提出的问题, 我们知道Wasserstein距离解决了任意不相关分布的距离度量问题, 而且有着深刻的黎曼几何意义, 但其实也引入了一个问题, 准确的来说, 我们有时候会在这个基础上添加一个小小的需求, 我们希望模型在复杂度上拟合程度上取一个折中, 换句话说, 我们鼓励转移的分布更加的趋近于更为均匀的分布.
要做到这一点就得引入Sinkhorn距离表征. 实际上就是在WD的基础之上, 再添加一个正则项.
这边是Sinkhorn距离. 有人可能要问了, 为什么加入了正则项, 就可以限制模型的复杂度呢? 这其实是一个很基础的问题了, 我们都知道正则的作用是什么, 就是为了防止过拟合, 那么为什么正则可以防止过拟合呢? 依赖的途径就是限制模型的复杂度. 有的同学就得问题, 为什么你可以限制模型的复杂度呢? 请定义一下模型的复杂度.
我们其实可以回归一下L1正则和L2正则:
这两个朴实无华的正则项, 就是通过限制参数量的波动来限制模型复杂度的. 换句话说, 你认为参数非0的数目越多, 就选L1, 你觉得波动越大的模型越复杂, 那么就用L2来正则它.
好了, 我们知道Sinkhorn在WD距离的基础上, 加入了一个正则项, 来进一步的约束模型的复杂度. 使得模型的transport更加的符合我们想要的复杂度, 进而约束模型的复杂性.
那么问题来了, 可是这和Transorformer有啥关系呢? 有关系, 刚才我们是不是提到了一个词: transport. 这看起来和transformer很像.
Transformer的本质
我们为什么花了很多时间来讲解最优化传输问题呢, 因为我想让它更靠近问题最本质的东西. 我不想在这里再po任何关于transformer的原理图, 相反, 我想只研究一个东西, 那就是Attention的计算方法. 大家都知道transformer实际上就是一系列的attention的机制, 但你知道他们是怎么计算的么? 又是怎么在建构模型中work的呢?
先来看一张图:
这是NLP领域早期一个一目了然的问题图. 从这张图里面我们可以看到所谓的Attention的本质, 其实就是最优化传输问题. CV领域嫁接的transformer类似的结构也逃脱不了这么一个本质. 为了说明这个观点, 我这里再po一张图
Transformer 与 VSlam
好家伙, 你这不扯则已, 一扯就还要拉上Slam? 这和人家VSlam又有毛关系啊? 有关系, 而且关系很大. 我们局限于传统的视觉任务太深, 以至于人家Deep-VSlam领域已经百花齐放了.. 诸如图网络, transformer.. 能用的高科技人家都已经用了一个遍了. 我现在赶个晚集, 来扯一下二者的关系. 你要说二者的联系, 我能找到的切合点就是 特征比对.
我们就以那篇MagicLeap的神论文来掰扯吧. SuperGlue这篇论文的牛逼效果自不必说, 我们主要讲解里么AttentionGNN部分, 这里面说白了就是加了一个self-attention的GNN模型, 这倒没有什么, 关键是这里面的匹配过程比较有意思. 在vSLAM领域, 或者说任何SLAM的应用, 对两针数据进行匹配找到位姿变换关系是最核心的内容之一. SuperGlue内的这个GNN便是模拟人类寻找匹配关键点的过程. 我们主要关心的是这个匹配, 而不是具体的实现.
这个算法的思路是, 首先我们有一个初始的特征点, 这个特征点由位置特征和外观特征组成, 这可以通过一个MLP的高纬输出向量来表达. 二者还可以通过注意力机制进行耦合, 从而用一个向量即可表征. 接着论文构建一个完全图, 这张图里面有两种边, 一种是self edge, 它连接了图像内部的特征点, 一种是cross edge, 它连接了本图特征点与另一张图的所有特征点. 这里面在构建模型的过程中就应用了attention的机制.
X-Formers
当文章写到这个地方, 我发觉事情并没有想象的那么简单, transformer这个家族真的是百花齐放, 每一个版本都有着它的特点和局限性. 这一段才是本文的核心 大家可以把其他的爱看不看, 这一段才是真正有价值的东西啊! 我们要提出一个非常重要的概念叫做: transformer mode.
怎么说? transformer还分为不同的模式, 准去的来说, 我们可以按照使用的方式来分类:
- 只有encoder, 例如用于图像分类;
- 只有decoder, 例如一些预训练的语言模型;
- encoder-decoder, 例如机器翻译.
对于encoder-decoder架构就是比较传统简单的transformer, 它的encoder和decoder可能都包含多头的自注意力机制模块.
上图有奖竞答: 哪一个是encoder, 哪一个是decoder?
有趣的是, 在encoder的设计模式中, 并没有限制self-attention的机制必须要是因果方式, 也可能是非因果的. 但是decoder的self-attention的机制中, 必须要是因果关系的.
人们已经花费了很多时间从不同的角度 来优化transformer的结构, 从上面的图你可以看到Vanilla得到transformer的计算复杂度是非常高的. 这个计算的复杂度放到现在来说, 落地很难. 这也push这人们去不断地优化.
这张语义地图告诉你的信息就是现在的最前沿的一些学术论文都在从哪个方向去优化架构. 这里我们也列出来一些现如今的优化算法他们的计算复杂度都是什么样的:
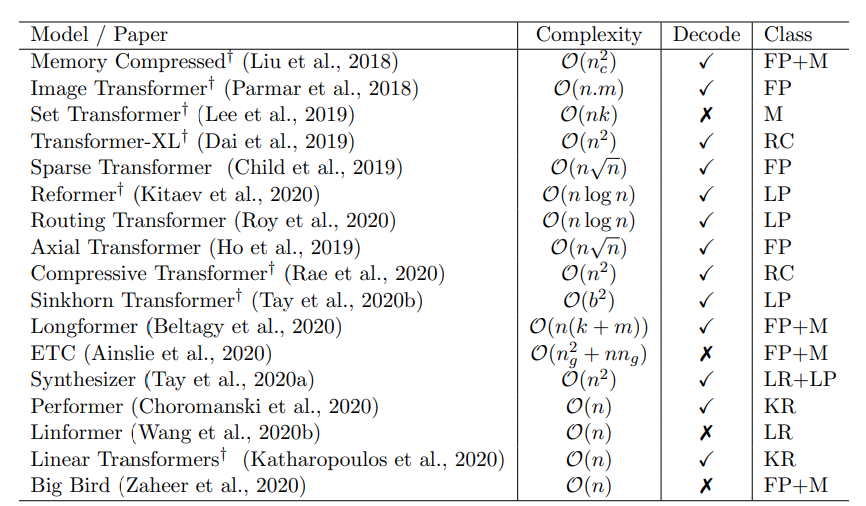
这里的类别分别含义是:
- FP: fixed patterns
- M: memory;
- LP: learnable patterns;
- KR: kernel
- RC: recurrence
这些简写描述了不同的发力点, 也即是提高transformer效率的突破口. 可以看到, 到如今, 大家的发力点似乎变得更倾向于 KR和LR方向. 接下来会给大家讲述一个稀疏transformer的工作就是这个方向.
这里我简单的讲解一下这些不同的优化方向吧:
- FP: 也就是限定的固定不变的优化模式, 比如局部窗口或者变动步幅窗口等来优化attention matrix;
- Blocwise Patterns: 它将输入序列分为固定的快, 考虑局部感受野, 说白了就是对输入的序列分块或者说取一个bucket, 然后在进行计算, 等于是把输入原子化, 这样原来N^2 就变成了 B^2, 当B远远小于N的时候, 就可以大大的降低计算的开销. 这个本质上没有修改网络的结构, 只是改变了输入的组织方式;
- Stried Pattern: 说白了这个就是Sparse transformer, 通过增加更大的窗口的步长来降低计算;
- Compressed Pattern: 将输入直接进行下采样这样当输入的长度降低之后, 总之宗旨也是通过降低输入来减少计算量;
- CP: 组合的优化方案, 那这个就是将许多不同的点进行融合, 比如说Sparse transformer将一部分的多头注意力组合进入其他模块, 在结合一些步长以及local attention的方式来降低运算;
- LP: 可学习的模式来优化. LP的核心就是确定不同token之间相互关系, 将token分配给不同的bucket或者cluster. 例如在Reformer中的引入了一个基于哈希的相似度度量方法, 有效的将token聚类为对应的bucket, 注意了注意了!! 这里有再一次的提到了度量, 也就是距离或者分布的度量, 再一次升华了本文的核心思想!. 再比如Sinkhorn排序网络引入了一个Sortnet来多输入序列的blocks进行排序来显示出attention weights的重要度 Sparsity. 这些相似函数与loss函数放到了一起进行端到端的训练. Lp优化方式的关键就是保持了固定的模式, 但是这类方法的的自动token聚类, 使得他们可以得到一个更优化的序列全局图.
- M: 另一种方式是全局内存方法, 这部分设计方式是直接从输入序列的token来学习聚类;
- K: 这是最近比较流行的一个提高效率的方法, 通过核函数来查看attention的机制, 核函数的使用可以让self-attention机制进行巧妙地重写. 避免显式的去计算NxN的矩阵, 从而大大的降低计算量, 也可以被认为是Lowrank的一种特例;
- R: 通过递归的方式来链接这些块, 从而学习这些突破口.
关于每个具体突破点的效率对比, 大家可以拉到最后的参考中查看对应论文的具体细节, 这里我不展开来讲. 我直接说一下结论.
尽管大家都在忙着更新不同的transformer结构并且使用各种手段去优化他们. 但几乎没有一种简单的方法可以对他们的效果进行对比. 再加上许多论文使用的评价指标不尽相同, 折让对比更加的困难. 因此, 哪一个方法更为基础高效的transofmer blocks, 至今为止仍然是一个未解之谜.
一方面,有多种模型集中在generative modeling,展示了提出的Transformer单元在序列AR(auto-regressive)建模上的能力。 为此,Sparse Transformers, Adaptive Transformers, Routing Transformers 和 Reformers主要集中在generative modeling任务。 这些基准通常涉及在诸如Wikitext、enwik8和/或ImageNet / CIFAR之类的数据集上进行语言建模和/或逐像素生成图像。 而segment based recurrence模型(例如Transformer-XL和Compressive Transformers)也专注于大范围语言建模任务,例如PG-19。
一方面,一些模型主要集中于**编码(encoding only)**的任务,例如问题解答、阅读理解和/或从Glue基准中选择。 例如ETC模型仅在回答问题基准上进行实验,如NaturalQuestions或TriviaQA。 另一方面,Linformer专注于GLUE基准测试子集。 这种分解是非常自然和直观的,因为ETC和Linformer之类的模型无法以AR(auto-regressive)方式使用,即不能用于解码。 这加剧了这些编码器模型与其他模型进行比较的难度。
有些模型着眼于上述两者的平衡。 Longformer试图通过在生成建模和编码器任务上运行基准来平衡这一点。 Sinkhorn Transformer对生成建模任务和仅编码任务进行比较。
好了, 到目前为止, transformer领域的所有进展差不多屡清楚了.
Sinkhorn Transformer
这个变种提出的一种transfomer结构, 我在前面铺垫了一大堆, 终于可以丢出这篇paper了:
因为我知道假如我一开始就丢出这篇论文, 98%的人是看不懂的, 也不知道我在说什么. 总结来说, 现如今的transformer结构不够memory efficient ,所以你去看很多paper都会说, CNN虽然参数多但是速度更快. 原因就在于现有的架构或者说工具链在计算Transformer的时候都无法做到高效.
而这篇论文主要过得贡献就是:
提出了一种稀疏的基于Sinkhorn算法的Attention机制. 而且这个高效的表征是可导的. 这个内存节约的attention方法比传统的attention机制效果相当, 并且高于在这之前提出的Sparse transformers.
现有的transformer由于在attention layer上的数值复杂度, 以及受限于输入序列的长度限制, 通常会导致整个模型处于一个欠优化的状态. 并且整个的运算效率并不是最优的.
这篇论文的思路是把attention问题转化成了一个排序问题:
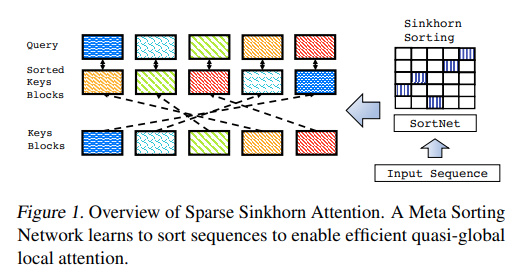
上面提到的transformer提高效率几个途径之一, 它走的路子就是LP方向, 也就是在进行attention matrix的优化, 并且通过一种自学习的方式去学习这个矩阵的稀疏性. 它使用的技巧便是我们提出了很久的sinkhorn算法, 也即是通过这一算法实现了token和对应block的匹配, 并且这个操作可以加入到模型当中进行端到端的训练.
总结
事实上transformer的发展并没有想象的那么令人满意, 我认为目前主要的阻碍是:
- 从我们上面的分析你可以看出现在transformer还存在效率低, 评测指标不统一, 变种太多, 评测任务不统一等问题;
- 你所看到的一些工作大部分是overall的工作, 没有specific在某个领域, 比如专门做Vision, 专门做语音等等, 而现有的一些非常Specific的工作又非常的specific, 以至于你不知道这个transofmer结构是不是一种先天的优势, 无论我们将其用到任何任务.
最后, 还是那句话, 实践出真知, 只有放到自己的问题中, 你才知道这个玩意到底有没有用.
预告
下一篇我们将对接到具体的视觉问题, 来做实验看看transformer的效果到底如何.
Reference
- csdn blog
- 黄裕. 2020年9月谷歌研究给出的综述“Efficient Transformers: A Survey”
- Bert若干问
- Efficient Transformers: A Survey
如果你想学习人工智能,对前沿的AI技术比较感兴趣,可以加入我们的知识星球,获取第一时间资讯,前沿学术动态,业界新闻等等!你的支持将会鼓励我们更频繁的创作,我们也会帮助你开启更深入的深度学习之旅!
