

一, 什么是ConcurrentHashMap
ConcurrentHashMap和HashMap一样是一个用来存储键值对<key,value>的集合类,但和HashMap不同的是ConcurrentHashMap是线程安全的,也就是多个线程同时对ConcurrentHashMap进行修改或者删除增加操作不会出现数据错误的问题.
二, 实现原理
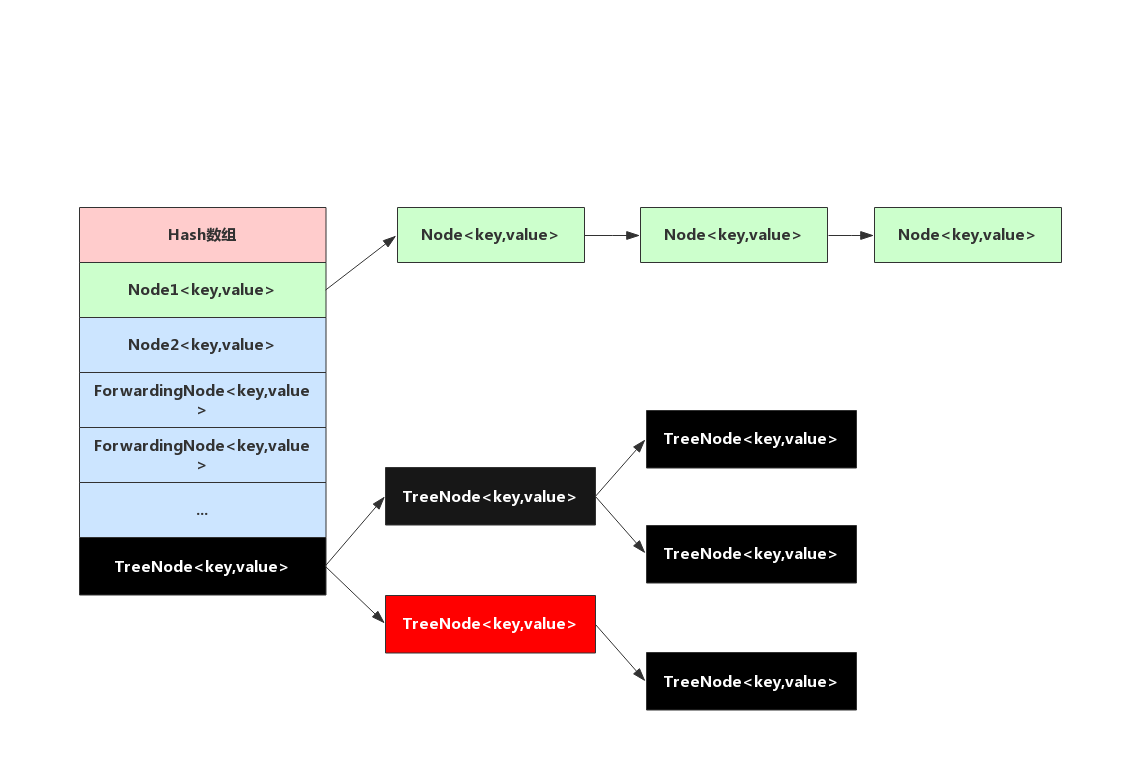
和HashMap一样采用数组+链表+红黑树实现
但和HashMap不同的是,数组中存储的节点类型有所增加,包括Node<key,value>,TreeNode<key,value>,ForwardingNode<key,value>,新增这个节点的目的就是为了线程并发协助扩容时使用
三, 基本属性介绍
//01111111111111111111111111111111 该值可以保证计算出来的哈希值为正数
static final int HASH_BITS = 0x7fffffff; // usable bits of normal node hash
//该属性用在扩容时生成一个负值,表示正在扩容
//The number of bits used for generation stamp in sizeCtl.
//sizeCtl中用于生成戳记的位数。
//Must be at least 6 for 32bit arrays.
//对于32位数组,必须至少为6。
private static int RESIZE_STAMP_BITS = 16;
//和上面一样,也是为了在扩容时生成一个负值,具体在代码中解释
//The bit shift for recording size stamp in sizeCtl.
//在sizeCtl中记录大小戳的位移位。
private static final int RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS;
//表示当前桶位正在被迁移
//Encodings for Node hash fields. See above for explanation.
static final int MOVED = -1;
//表示当前桶是以树来存储节点的
static final int TREEBIN = -2;
//Number of CPUS, to place bounds on some sizings
//cpu的数量,用来计算元素数量时限制CounterCell数组大小
static final int NCPU = Runtime.getRuntime().availableProcessors();
/**
* The next table to use; non-null only while resizing.
* 用来扩容的哈希表
*/
private transient volatile Node<K, V>[] nextTable;
/**
* Base counter value, used mainly when there is no contention, but also as a fallback during table initialization
* races. Updated via CAS.
* 哈希表元素数量,通过longAdder来维护
*/
private transient volatile long baseCount;
/**
* Table initialization and resizing control.
* 哈希表初始化和扩容大小控制.
* When negative, the table is being initialized or resized:
* 当这个值为负数时,表示哈希表正在初始化或重新计算大小
* -1 for initialization,
* -1 表示正在初始化了
* else -(1 + the number of active resizing threads).
* 表示哈希表正在扩容,-(1+n),表示此时有n个线程正在共同完成哈希表的扩容
* Otherwise, when table is null, holds the initial table size to use upon creation,or 0 for default.
* 否则,当哈希表为空时, 保留要创建哈希表的大小0或默认(16)
* After initialization, holds the next element count value upon which to resize the table.
* 初始化完成之后,保留下一次需要扩容的阈值
*/
private transient volatile int sizeCtl;
/**
* The next table index (plus one) to split while resizing.
* 扩容时的当前转移下标
*/
private transient volatile int transferIndex;
/**
* Spinlock (locked via CAS) used when resizing and/or creating CounterCells.
* 获取计算集合元素容量的CounterCell对象的锁
*/
private transient volatile int cellsBusy;
/**
* Table of counter cells. When non-null, size is a power of 2.
* 计算元素数量的数组
*/
private transient volatile CounterCell[] counterCells;
四, 构造函数
/**
* 和HashMap构造函数不同的是,数组容量的计算总是大于传入容量的2的幂
* 即如果传入32则数组初始容量为64,而不是32,而HashMap计算出来为32
*/
public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0)
throw new IllegalArgumentException();
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY : tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
this.sizeCtl = cap;
}
五, 常用方法介绍
/**
* 这个方法就是HashMap中的hash方法,用来计算哈希值
*/
static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS;
}
获取节点
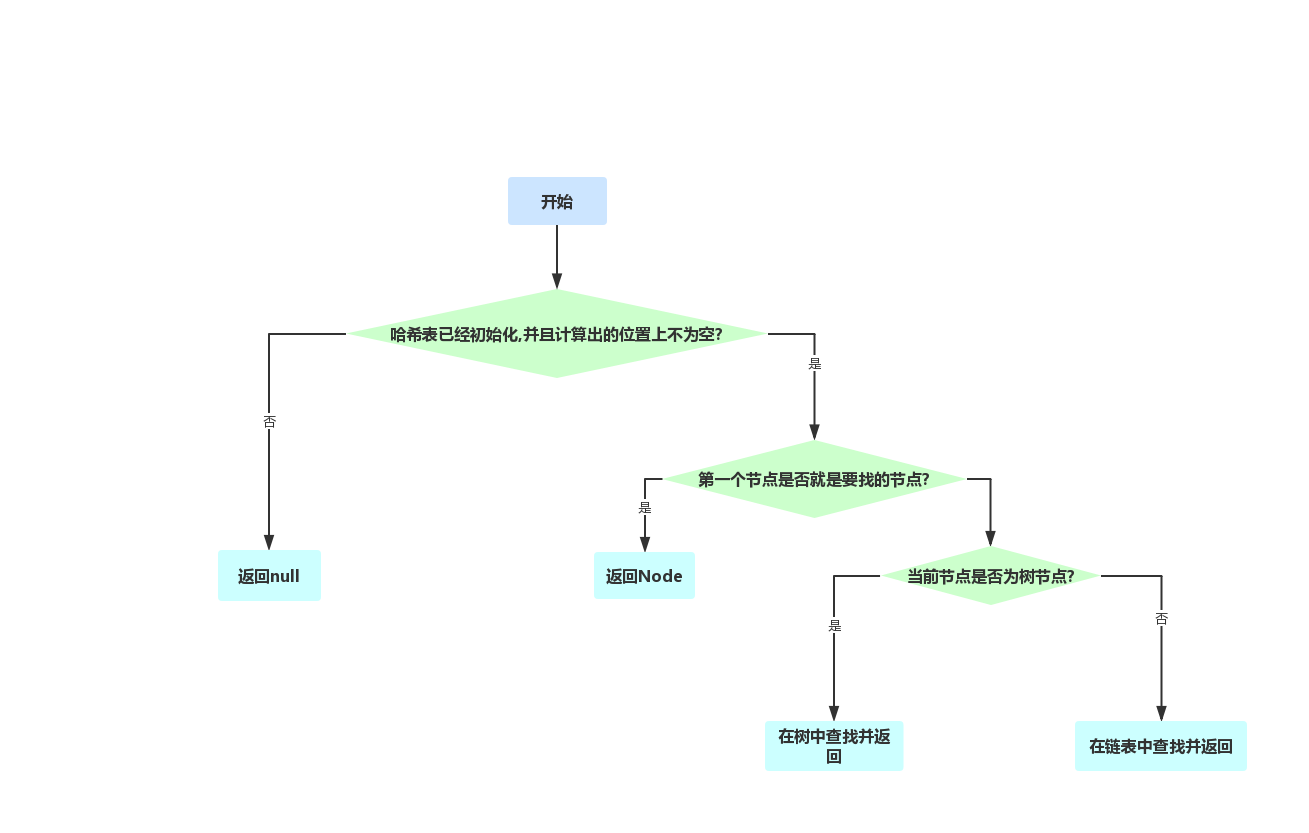
public V get(Object key) {
Node<K, V>[] tab;
Node<K, V> e, p;
int n, eh;
K ek;
//计算散列值
int h = spread(key.hashCode());
//计算下标(这一块同HashMap不再赘述)
if ((tab = table) != null && (n = tab.length) > 0 && (e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
} else if (eh < 0)
//哈希值小于0,表示为树节点,从树中寻找,这一步和HashMap一致
return (p = e.find(h, key)) != null ? p.val : null;
//在链表中寻找
while ((e = e.next) != null) {
if (e.hash == h && ((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
插入节点
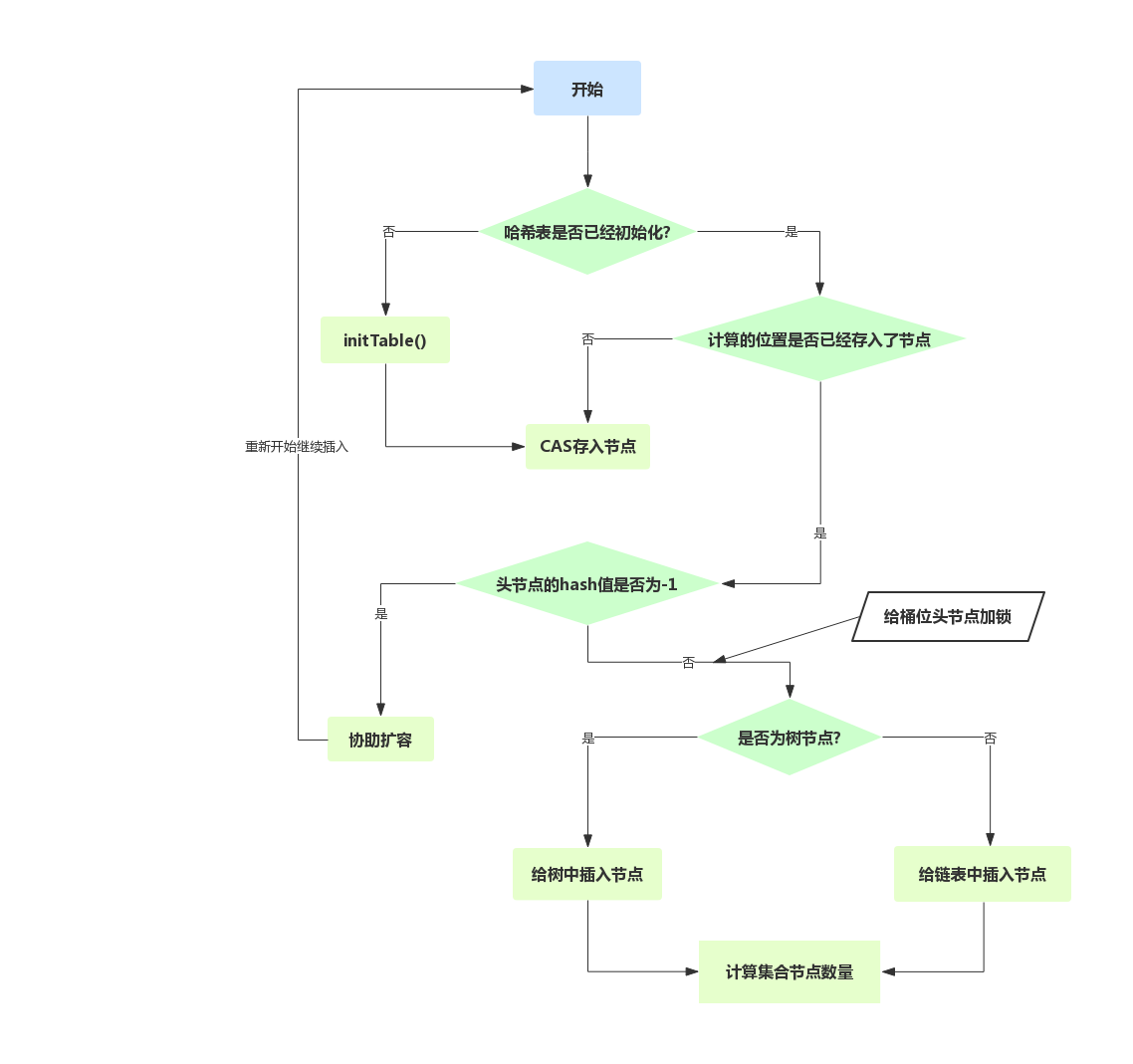
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
//计算哈希值
int hash = spread(key.hashCode());
//插入桶的节点数量
int binCount = 0;
//使用死循环,目的是可能有的线程正在协助扩容,之后还需要插入或者更新,或者需要操作的节点所在的桶已经被其他线程锁定,需要等待其他线程执行完之后再执行
for (Node<K, V>[] tab = table; ; ) {
Node<K, V> f;
int n, i, fh;
if (tab == null || (n = tab.length) == 0)
//初始化哈希表
tab = initTable();
else if
//计算下标,并且计算该下标是否有元素
((f = tabAt(tab, i = (n - 1) & hash)) == null) {
//cas插入,这一步不需要锁,因为当前桶为空
if (casTabAt(tab, i, null, new Node<K, V>(hash, key, value, null)))
break;
} else if
//代表当前节点已经被移动,正在扩容,需要当前线程协助扩容
((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
//锁住头节点,保证所有线程的插入都是线程安全的
synchronized (f) {
//这一步判断的原因是,可能插入元素之后会造成链表树化,需要插入的位置已经发生了变化
if (tabAt(tab, i) == f) {
if (fh >= 0) {
//当前桶上有多少个节点
binCount = 1;
for (Node<K, V> e = f; ; ++binCount) {
K ek;
//查找到了key相同的节点,直接修改值并返回旧的值
if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K, V> pred = e;
//没有找到相同的key,直接向链表尾部插入节点
if ((e = e.next) == null) {
pred.next = new Node<K, V>(hash, key, value, null);
break;
}
}
} else if (f instanceof TreeBin) {
//给树里面插入节点
Node<K, V> p;
binCount = 2;
if ((p = ((TreeBin<K, V>) f).putTreeVal(hash, key, value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
//需要树化
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
//修改旧值,直接将旧值返回
if (oldVal != null)
return oldVal;
break;
}
}
}
//计算节点数量
addCount(1L, binCount);
return null;
}
初始化哈希表
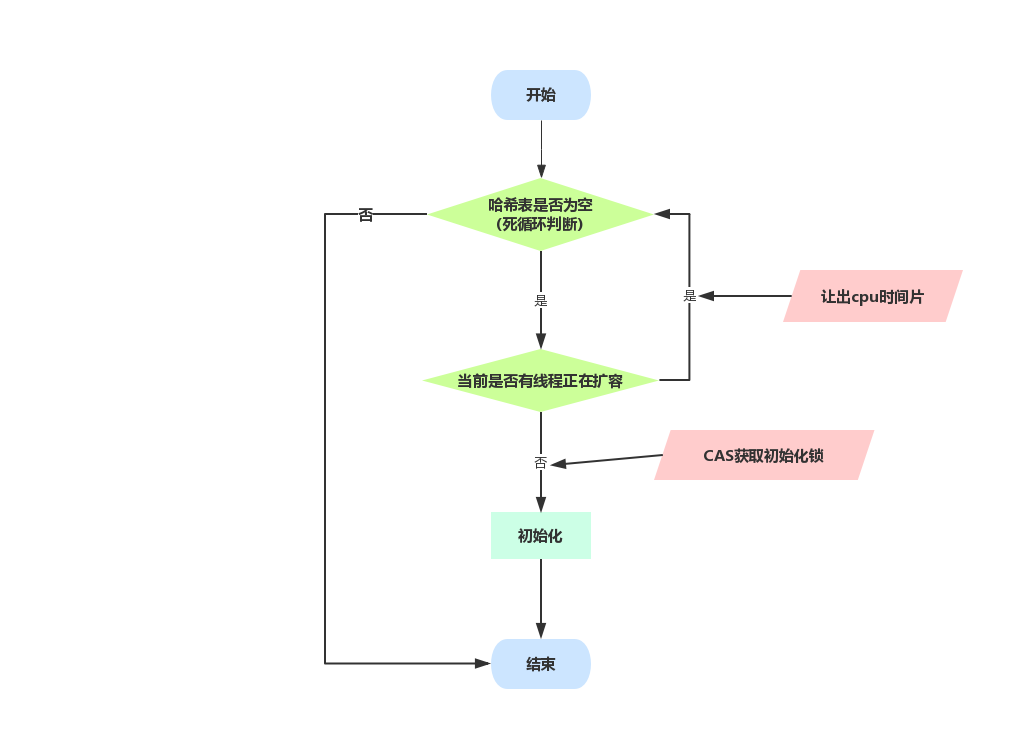
private final Node<K, V>[] initTable() {
Node<K, V>[] tab;
int sc;
while ((tab = table) == null || tab.length == 0) {
//小于0表示正在初始化或者正在扩容,让出cpu
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
else if
//判断sc是否与SIZECTL是否相等,如果相等,则将SIZECTL设置为-1,表示当前正在初始化(只有一个线程能进行此操作,其他线程会被挡在前面的判断上)
(U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
//防止有线程已经初始化了1
if ((tab = table) == null || tab.length == 0) {
//该sc如果在构造器上传入了,则会被计算为大于其的2次幂,否则会按照默认值初始化
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K, V>[] nt = (Node<K, V>[]) new Node<?, ?>[n];
table = tab = nt;
//设置下一次扩容的阈值 n - (n >>> 2) = n - n / 4 = (3 / 4) * n = 0.75n,即下一次的扩容阈值为当前哈希表数量的0.75*n
sc = n - (n >>> 2);
}
} finally {
//设置sizeCtl为-1,表示初始化动作已经有线程在执行了
sizeCtl = sc;
}
break;
}
}
return tab;
}
计算节点数量
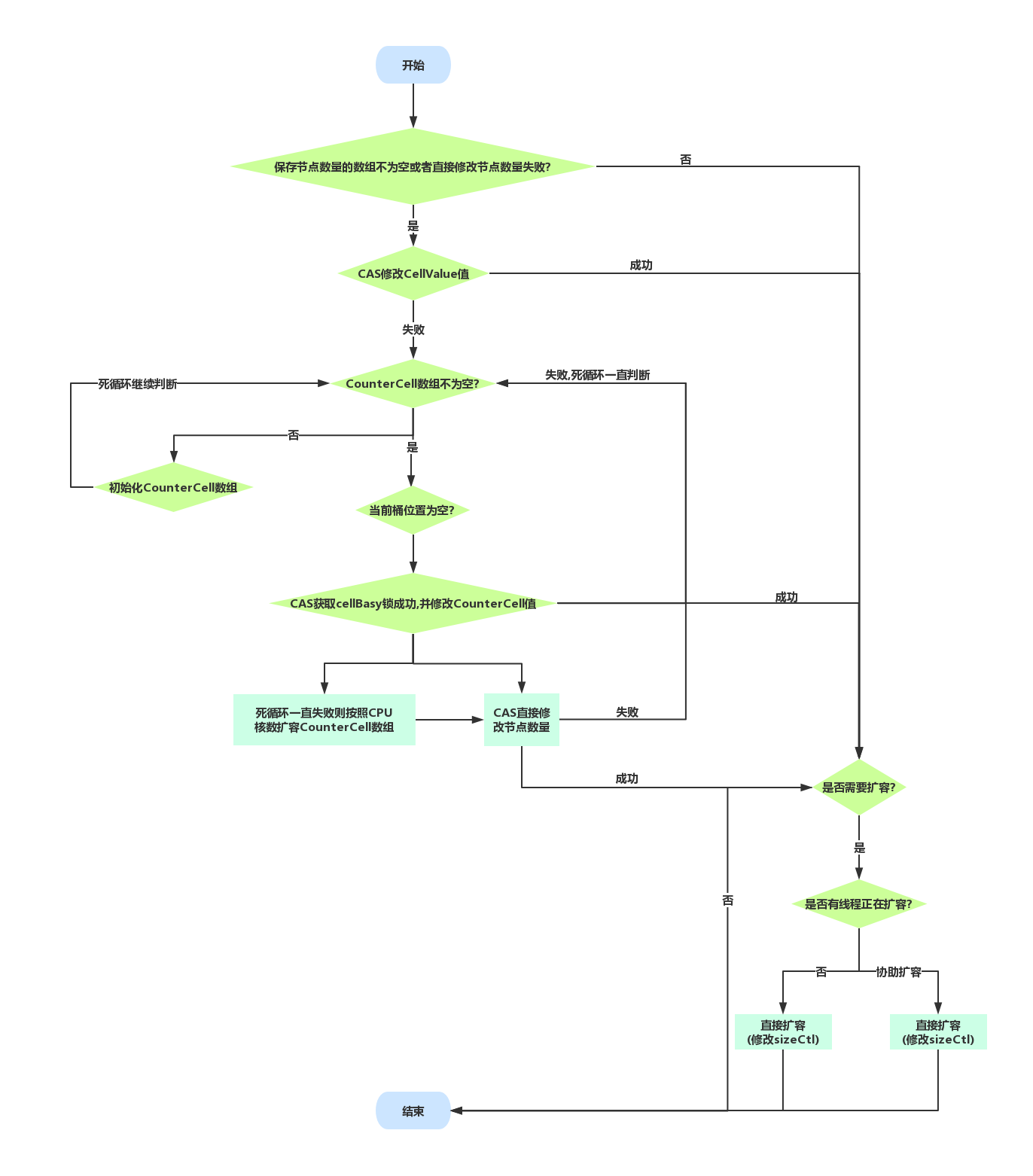
private final void addCount(long x, int check) {
CounterCell[] as;
long b, s;
/*
* 维护数组长度
*/
//尝试cas直接修改值,如果修改失败
if ((as = counterCells) != null || !U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell a;
long v;
int m;
boolean uncontended = true;
//数组为空或者长度小于0或者对应的位置为空或者直接修改数组对应位置上的值失败,则进行修改操作
if (as == null || (m = as.length - 1) < 0 || (a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended = U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
fullAddCount(x, uncontended);
return;
}
//桶上的节点数量小于等于1,不需要判断扩容,直接退出
if (check <= 1)
return;
//获取当前数组的元素数量
s = sumCount();
}
/*
* 判断是否需要扩容
*/
if (check >= 0) {
Node<K, V>[] tab, nt;
int n, sc;
//当前节点数量大于扩容阈值,并且数组不为空并且数组长度小于最大值则需要扩容
while (s >= (long) (sc = sizeCtl) && (tab = table) != null && (n = tab.length) < MAXIMUM_CAPACITY) {
//获取一个负值
int rs = resizeStamp(n);
//如果sc小于0,说明正在扩容,需要协助扩容
if (sc < 0) {
//判断扩容是否完成
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 || sc == rs + MAX_RESIZERS || (nt = nextTable) == null || transferIndex <= 0)
break;
//协助扩容,这里sc+1代表新加入一个线程协助扩容
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
} else if
/*
* 假设 rs = 00000000 00000000 10000000 00000000
* 将其向左移16位结果为 10000000 00000000 00000000 00000000 可以看出该值为负
* 这一步尝试将sc设置为负数
*/
(U.compareAndSwapInt(this, SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2))
//将旧数组置空,里面会创建一个新的数组
transfer(tab, null);
//计算集合元素数量
s = sumCount();
}
}
}
private final void fullAddCount(long x, boolean wasUncontended) {
int h;
//获取当前线程的hash值
if ((h = ThreadLocalRandom.getProbe()) == 0) {
ThreadLocalRandom.localInit(); // force initialization
h = ThreadLocalRandom.getProbe();
wasUncontended = true;
}
//检测是否有冲突,如果最后一个桶不为null,则为true
boolean collide = false;
for (; ; ) {
CounterCell[] as;
CounterCell a;
int n;
long v;
//数组如果不为空,则优先对CounterCell里面的counterCell的value进行累加
if ((as = counterCells) != null && (n = as.length) > 0) {
//当前位置为空
if ((a = as[(n - 1) & h]) == null) {
//当前没有线程尝试修改该值
if (cellsBusy == 0) {
CounterCell r = new CounterCell(x);
//抢占修改的锁
if (cellsBusy == 0 && U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
boolean created = false;
try {
CounterCell[] rs;
int m, j;
if ((rs = counterCells) != null && (m = rs.length) > 0 && rs[j = (m - 1) & h] == null) {
rs[j] = r;
created = true;
}
} finally {
//释放锁
cellsBusy = 0;
}
if (created)
break;
continue; // Slot is now non-empty
}
}
//抢占失败
collide = false;
} else if
//桶位不为空,重新计算线程hash值,继续循环
(!wasUncontended) // CAS already known to fail
wasUncontended = true; // Continue after rehash
/*
* 重新计算hash值之后,对应的桶位还是不为空,对value进行累加
* 尝试cas对value加值
*/
else if (U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))
break;
//数组长度已经大于等于CPU的核数了,不需要再扩容了
else if (counterCells != as || n >= NCPU)
collide = false;
//当没有冲突,修改为有冲突,重新计算hash值,继续循环
else if (!collide)
collide = true;
else if
//多次循环没有设置成功值,则对原数组进行扩容
(cellsBusy == 0 && U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
try {
if (counterCells == as) {// Expand table unless stale
//数组长度没有超过cpu核数,将数组扩容两倍
CounterCell[] rs = new CounterCell[n << 1];
for (int i = 0; i < n; ++i)
//扩容使用
rs[i] = as[i];
counterCells = rs;
}
} finally {
cellsBusy = 0;
}
collide = false;
continue; // Retry with expanded table
}
//重新计算随机值
h = ThreadLocalRandom.advanceProbe(h);
} else if
//初始进来数组为空,需要初始化数组
(cellsBusy == 0 && counterCells == as && U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
boolean init = false;
try {
if (counterCells == as) {
CounterCell[] rs = new CounterCell[2];
rs[h & 1] = new CounterCell(x);
counterCells = rs;
init = true;
}
} finally {
cellsBusy = 0;
}
if (init)
break;
} else if
//数组为空并且有其他线程正在创建数组,尝试直接对baseCount进行累加
(U.compareAndSwapLong(this, BASECOUNT, v = baseCount, v + x))
break; // Fall back on using base
}
}
扩容并迁移
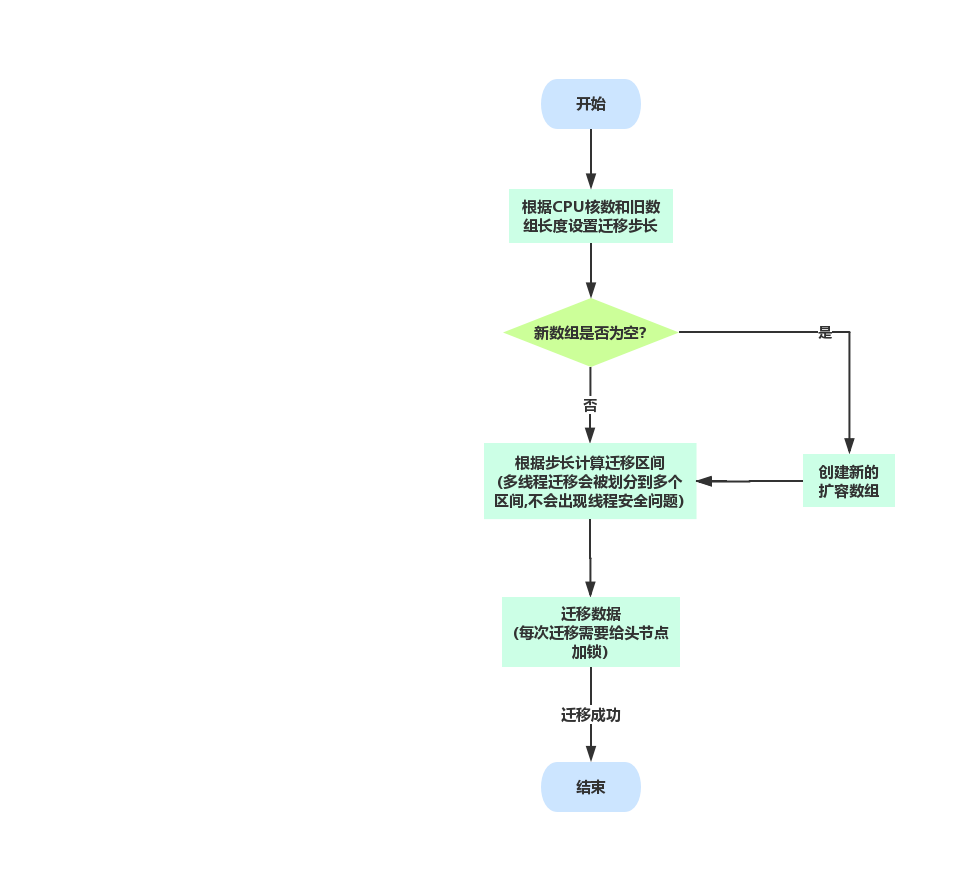
private final void transfer(Node<K, V>[] tab, Node<K, V>[] nextTab) {
//stride表示迁移数据的区间
int n = tab.length, stride;
/*
* 这里计算每个CPU负责迁移元素的个数
* 如果这里的跨度区间小于16,则按照最小区间16来计算
*/
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE;
//这里表示为第一个线程来扩容
if (nextTab == null) {
try {
//扩容为两倍
@SuppressWarnings("unchecked")
Node<K, V>[] nt = (Node<K, V>[]) new Node<?, ?>[n << 1];
nextTab = nt;
} catch (Throwable ex) {
sizeCtl = Integer.MAX_VALUE;
return;
}
nextTable = nextTab;
//迁移数据的index
transferIndex = n;
}
//新扩容数组的长度
int nextn = nextTab.length;
//创建头节点,该节点会被标识为MOVED表示数据正在迁移中
ForwardingNode<K, V> fwd = new ForwardingNode<K, V>(nextTab);
boolean advance = true;
boolean finishing = false; // to ensure sweep before committing nextTab
//从后向前迁移
for (int i = 0, bound = 0; ; ) {
Node<K, V> f;
int fh;
while (advance) {
int nextIndex, nextBound;
//不属于自己的迁移位置或者已经迁移完成直接退出
if (--i >= bound || finishing)
advance = false;
else if
//下一个迁移位置小于等于0直接退出
((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
} else if
//计算迁移位置(多线程会划分多个区间)
(U.compareAndSwapInt(this, TRANSFERINDEX, nextIndex, nextBound = (nextIndex > stride ? nextIndex - stride : 0))) {
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
//判断是否所有的线程都做完了任务
if (finishing) {
nextTable = null;
table = nextTab;
//等于0.75 * 2n,也就是新数组扩容2倍*扩容因子
sizeCtl = (n << 1) - (n >>> 1);
return;
}
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
//判断扩容是否成功
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
finishing = advance = true;
i = n; // recheck before commit
}
} else if
//如果当前位置为空,直接插入fwd节点,表示当前节点正在被迁移
((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
else if ((fh = f.hash) == MOVED)
//正在被迁移,需要重新计算位置
advance = true; // already processed
else {
//迁移代码
synchronized (f) {
if (tabAt(tab, i) == f) {
Node<K, V> ln, hn;
if (fh >= 0) {
int runBit = fh & n;
Node<K, V> lastRun = f;
for (Node<K, V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
if (runBit == 0) {
ln = lastRun;
hn = null;
} else {
hn = lastRun;
ln = null;
}
for (Node<K, V> p = f; p != lastRun; p = p.next) {
int ph = p.hash;
K pk = p.key;
V pv = p.val;
if ((ph & n) == 0)
ln = new Node<K, V>(ph, pk, pv, ln);
else
hn = new Node<K, V>(ph, pk, pv, hn);
}
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
//迁移完成,设置头节点为fwd
setTabAt(tab, i, fwd);
advance = true;
} else if (f instanceof TreeBin) {
TreeBin<K, V> t = (TreeBin<K, V>) f;
TreeNode<K, V> lo = null, loTail = null;
TreeNode<K, V> hi = null, hiTail = null;
int lc = 0, hc = 0;
for (Node<K, V> e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode<K, V> p = new TreeNode<K, V>
(h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
} else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin<K, V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin<K, V>(hi) : t;
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
//迁移完成,设置头节点为fwd
setTabAt(tab, i, fwd);
//重新计算位置继续迁移
advance = true;
}
}
}
}
}
}
获取节点数量
public int size() {
long n = sumCount();
return ((n < 0L) ? 0 : (n > (long) Integer.MAX_VALUE) ? Integer.MAX_VALUE : (int) n);
}
/**
* 获取哈希表中节点的数量(非线程安全)
* 这个方法返回的数据不一定准确,因为可能在调用该方法的时候,有其他线程正在尝试给数组中的节点加值
*/
final long sumCount() {
CounterCell[] as = counterCells;
CounterCell a;
long sum = baseCount;
if (as != null) {
for (CounterCell counterCell : as) {
if ((a = counterCell) != null)
sum += a.value;
}
}
return sum;
}
