

为保证阅读体验,强烈建议点击原文链接阅读
原文链接:凡尔赛沙雕语录,究竟有多沙雕?
大家好,我是小一
前一阵子,凡尔赛文学突然爆火网络,特别是在知乎上竟然出现了大量的凡尔赛语录
随便点进去一个问题一看,确实一张口就是老凡学家了,够沙雕
甚至有的问题回答竟然有好几百,关注和浏览量都还挺高。
突发奇想,要不?把这些回答爬下来,分析一下【凡学家们】究竟有多沙雕?
凡尔赛问题定位
首先,搜索【凡尔赛语录】,发现有几个相关问题
其中第二个和我们要的结果比较相似
点进去后可以发现这其实是个回答,关于这个提问共有 225 个回答。
可以看到当前网址是下面这个
https://www.zhihu.com/question/429548386/answer/1575062220
去掉 answer 以及后面的部分就是这个问题的网址,这个网址我们会在后面的爬虫中用到。
特别是后面的一串数字是问题 id,作为知乎问题的唯一标识。
https://www.zhihu.com/question/429548386
爬取问题回答
研究一下上面的网址,我们发现需要爬取两部分数据:
一部分是问题的详情,包括创建时间、关注人数、浏览量、问题描述等。
一部分是问题的回答,包括每个答主的用户名、粉丝数等信息,问题回答的具体内容、发布时间、评论数、点赞数等信息。
其中,问题详情可以直接爬取上面的网址,通过 bs4 解析页面内容拿到数据
而问题的回答则需要通过下面的链接,通过设置每页的起始下标和页面内容偏移量确定,有点类似于分页内容的爬取。
def init_url(question_id, limit, offset):
base_url_start = "https://www.zhihu.com/api/v4/questions/"
base_url_end = "/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_labeled%2Cis_recognized%2Cpaid_info%2Cpaid_info_content%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%2A%5D.topics&limit={0}&offset={1}".format(limit, offset)
return base_url_start + question_id + base_url_end
设置每页回答数 limit=20,offset 则可以是0、20、40...
而 question_id 则是上面提到的网址后面的一串数字,这里是 429548386
逻辑想明白之后就是通过写爬虫获取数据了,文末有完整的爬虫代码获取方式,运行的时候你只需要修改问题的 id 即可。
由于篇幅问题,这里只贴主要的代码:
if __name__ == '__main__':
question_id = '429548386'
url = "https://www.zhihu.com/question/" + question_id
"""获取问题的详细描述"""
title, question, follower, watched, answer_count, tag_list = get_question_base_info(url)
print("问题url:"+ url)
print("问题标题:" + title)
print("问题描述:" + question)
print("该问题被定义的标签为:" + '、'.join(tag_list))
print("该问题关注人数:{0},已经被 {1} 人浏览过".format(follower, watched))
print("截止 {},该问题有 {} 个回答".format(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), answer_count))
"""获取问题的回答数据"""
# 构造url
limit, offset = 20, 0
page_cnt = int(answer_count/limit) + 1
answer_data = pd.DataFrame()
for page_index in range(page_cnt):
answer_url = init_url(question_id, limit, offset+page_index*limit)
# 获取数据
data_per_page = get_answer_info(answer_url, page_index)
answer_data = answer_data.append(data_per_page)
sleep(3)
answer_data.to_csv('凡尔赛沙雕语录_{0}.csv'.format(question_id), encoding='utf-8', index=False)
爬虫运行截图如下:
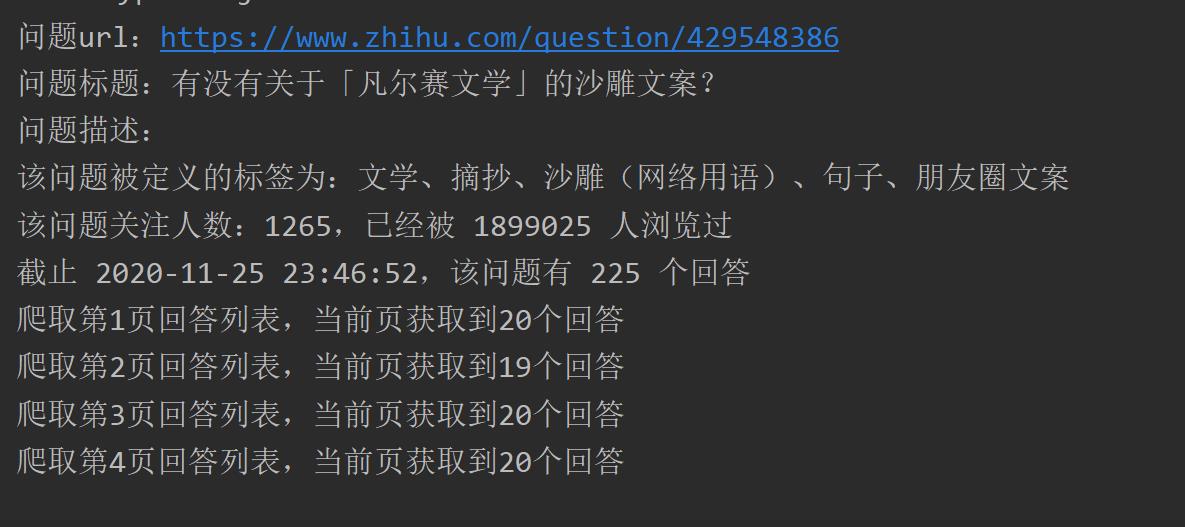
最终,该问题现有的 225 条回答都已经成功爬到
分析回答数据
每个答主都有自己的粉丝,粉丝多的答主应该回答质量比较高,才会受到大家的广泛关注。那,像这种沙雕语录他们也有涉及吗?
先来看一下粉丝数和赞同数的关系
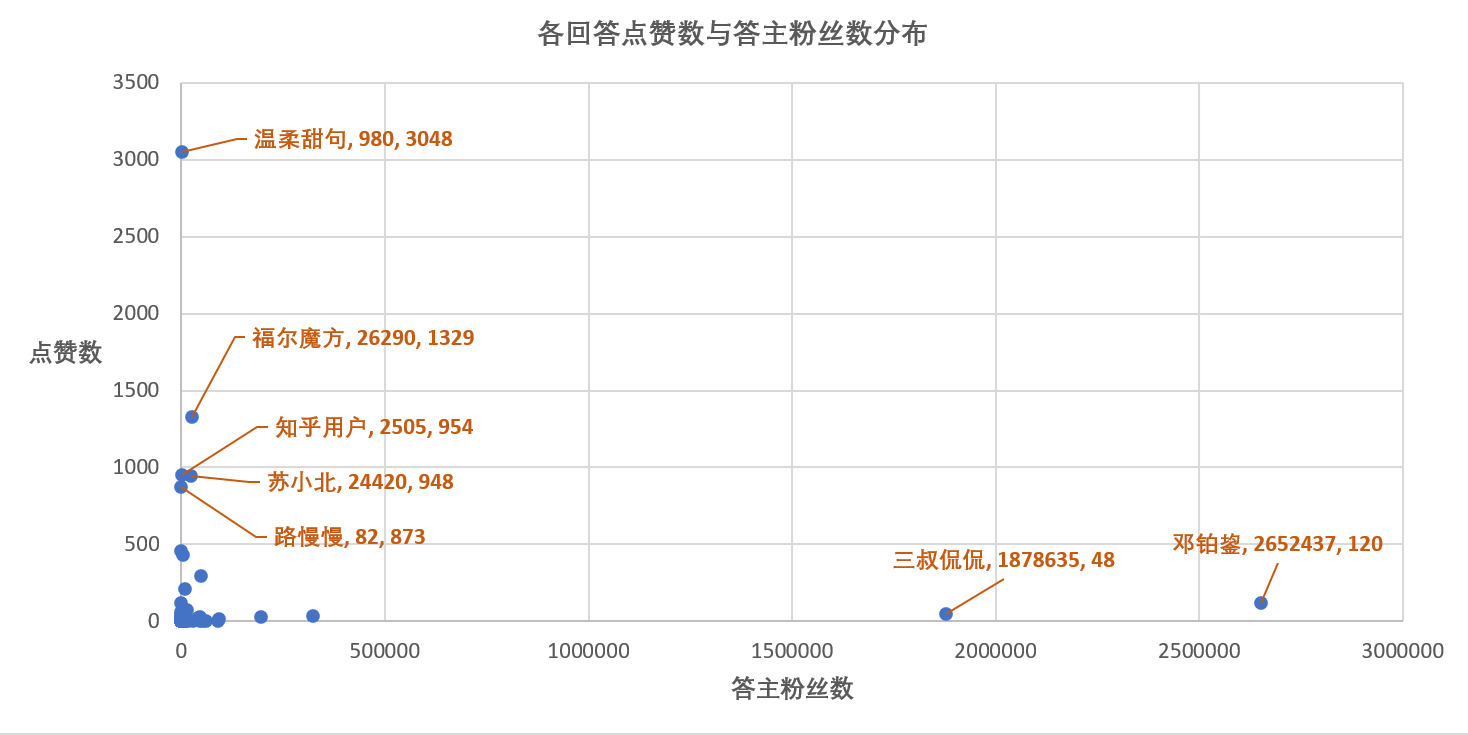
可以发现,粉丝数多的答主的问题回答赞同数不一定高,反倒是粉丝数少的答主回答更沙雕些,广受大家认可。
那,赞同数多的回答评论数应该也不少,毕竟大家都会前排吃瓜,围观沙雕
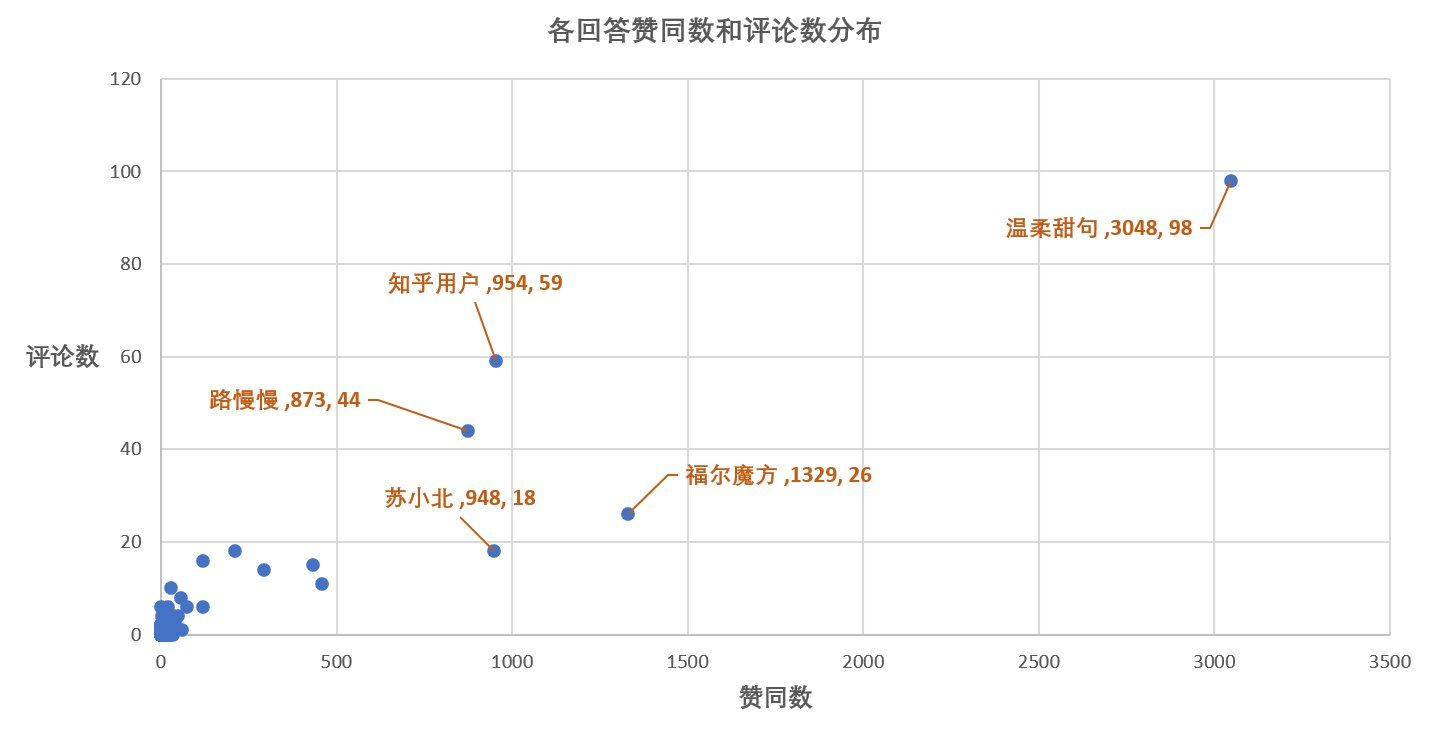
果然,问题回答的赞同数和评论数基本呈线性分布
基于常识,越早的问题回答应该越容易受到关注,会吸引一大波吃瓜群众前来围观,时间越往后可能热度就过去了,也就少有人关注了。
看一下分布图:
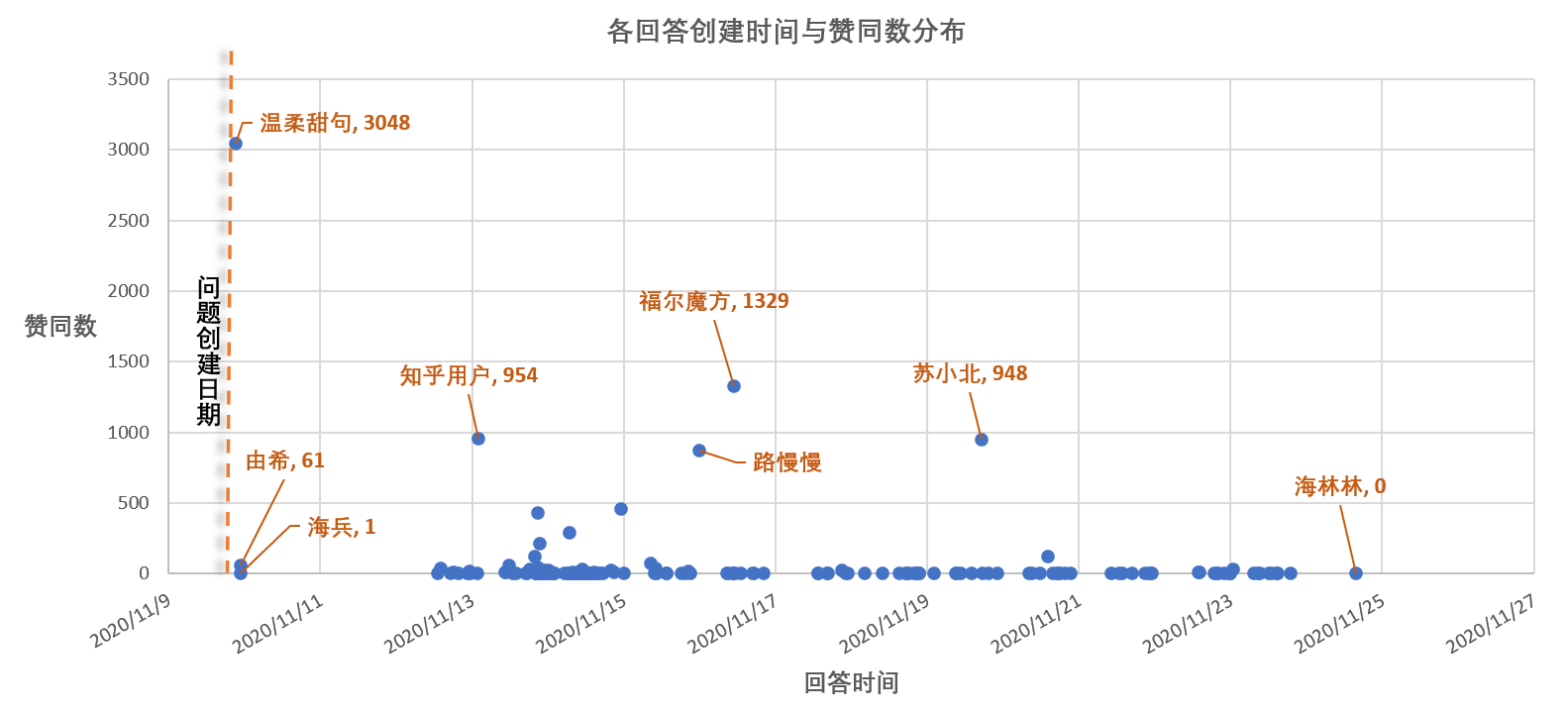
可以看到,这个话题的关注度持续时间比较久,甚至十天后还有近千赞的回答产生,相比微博的热搜知乎热搜似乎持续时间更久一些。
最后,一起欣赏一下新时代的凡尔赛沙雕语录
一开口就是老凡尔赛人了!
说出来挺不好意思的,我是最近才知道鸡蛋有壳的,以前都是吃管家剥好的,一直以为鸡蛋都是白色的软软的
好烦,睡过了马尔代夫的航班,只能专机去了

今天,我的姐妹说要开跑车来接我下班,我说不要,打工人怎么能用跑车下班?
家里已经帮我包了一辆公车了,年卡,随我刷。
打工可能会少活十年,不打工我一天也活不了
早晨我把“早安打工人”发给了数位好友,无一人回复。后来我才意识到,打工的只有我一个,他们这些人上人还在睡觉。
对不起,是我认真了。

雇主让我早点去安空调
我说:“就不能晚点安吗?”
他说:“不能,打工人就是要早安!”
写在后面的话
本节语录+图片均来源于网络,侵权可以后台联系小一删除。
本节相关的爬虫代码已经整理完毕,原文 后台回复【凡尔赛】 获取源码。
文章说明
文章作者:xiaoyi 数据分析从业者,金融风控爱好者
文章首发:公众号【小一的学习笔记】
原文链接:凡尔赛沙雕语录,究竟有多沙雕?
我是小一,坚持向暮光所走的人,终将成为耀眼的存在。
期待你的 三连,我们下节见。
