Producer构造函数流程
如何创建KafkaProducer
private static Map<String,Object> configMap = new HashMap<>();
static {
configMap.put("bootstrap.servers","172.16.0.202:9092");
configMap.put("clientId","producer-1");
configMap.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
configMap.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
}
KafkaProducer kafkaProducer = new KafkaProducer(configMap);
- kafka构造函数需要通过配置指定 server的地址以及k-v序列化器(也可以通过构造函数参数来传递)
重要属性解析
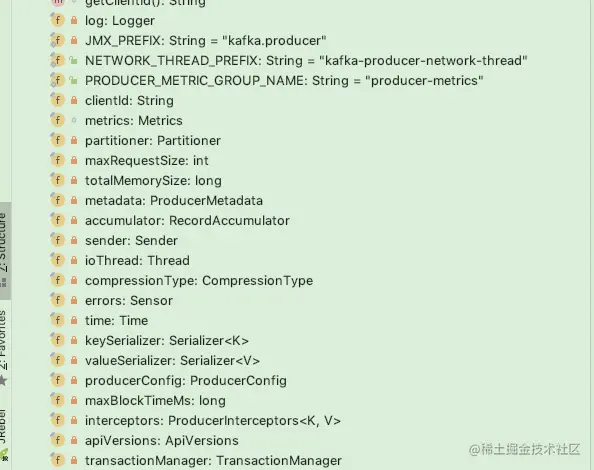
- client producer的唯一标识符
- metrics 监控相关
- partitioner:分区器
- maxRequestSize:最大消息长度 包含了消息头 消息体
- totalMemorySize : 发送单个消息的缓冲区大小
- accumulator : 用于收集并缓存消息 等待sender线程发送
- sender sender线程 负责消息的具体发送逻辑
- ioThread:kafka自己实现的thread
- compressionType:压缩类型 目前支持 none,gzip,snappy,lz4,zstd压缩类型
- key(value)Serialize : key和value的序列化和反序列化器
- producerConfig : 生产者配置类
- maxBlockTimeMs:等待kafka收集元数据的最大时长
- interceptors:拦截器 list
- transactionManager事物管理器
源代码解析
KafkaProducer(Map<String, Object> configs,
Serializer<K> keySerializer,
Serializer<V> valueSerializer,
ProducerMetadata metadata,
KafkaClient kafkaClient,
ProducerInterceptors<K, V> interceptors,
Time time) {
//加载配置
ProducerConfig config = new ProducerConfig(ProducerConfig.appendSerializerToConfig(configs, keySerializer,
valueSerializer))
try {
Map<String, Object> userProvidedConfigs = config.originals()
this.producerConfig = config
this.time = time
/**省略事物id*/
//初始化唯一标识符
this.clientId = config.getString(ProducerConfig.CLIENT_ID_CONFIG)
/**省略监控相关内容*/
// 分区器
this.partitioner = config.getConfiguredInstance(ProducerConfig.PARTITIONER_CLASS_CONFIG, Partitioner.class)
long retryBackoffMs = config.getLong(ProducerConfig.RETRY_BACKOFF_MS_CONFIG)
if (keySerializer == null) {
this.keySerializer = config.getConfiguredInstance(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
Serializer.class)
//k-v 序列化和反序列化器初始化开始 this.keySerializer.configure(config.originals(Collections.singletonMap(ProducerConfig.CLIENT_ID_CONFIG, clientId)), true)
} else {
config.ignore(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG)
this.keySerializer = keySerializer
}
if (valueSerializer == null) {
this.valueSerializer = config.getConfiguredInstance(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
Serializer.class)
this.valueSerializer.configure(config.originals(Collections.singletonMap(ProducerConfig.CLIENT_ID_CONFIG, clientId)), false)
} else {
config.ignore(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG)
this.valueSerializer = valueSerializer
}
// load interceptors and make sure they get clientId
userProvidedConfigs.put(ProducerConfig.CLIENT_ID_CONFIG, clientId)
//初始化拦截器 list
List<ProducerInterceptor<K, V>> interceptorList = (List) configWithClientId.getConfiguredInstances(
ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, ProducerInterceptor.class)
if (interceptors != null)
this.interceptors = interceptors
else
this.interceptors = new ProducerInterceptors<>(interceptorList)
ClusterResourceListeners clusterResourceListeners = configureClusterResourceListeners(keySerializer,
valueSerializer, interceptorList, reporters)
//消息的最大长度
this.maxRequestSize = config.getInt(ProducerConfig.MAX_REQUEST_SIZE_CONFIG)
//单个消息的缓冲区大小
this.totalMemorySize = config.getLong(ProducerConfig.BUFFER_MEMORY_CONFIG)
//压缩类型
this.compressionType = CompressionType.forName(config.getString(ProducerConfig.COMPRESSION_TYPE_CONFIG))
//等待kafka收集元数据的最大时长
this.maxBlockTimeMs = config.getLong(ProducerConfig.MAX_BLOCK_MS_CONFIG)
int deliveryTimeoutMs = configureDeliveryTimeout(config, log)
this.apiVersions = new ApiVersions()
//初始化消息收集器(也可以理解为消息缓冲取)
this.accumulator = new RecordAccumulator(logContext,
config.getInt(ProducerConfig.BATCH_SIZE_CONFIG),
this.compressionType,
lingerMs(config),
retryBackoffMs,
deliveryTimeoutMs,
metrics,
PRODUCER_METRIC_GROUP_NAME,
time,
apiVersions,
transactionManager,
new BufferPool(this.totalMemorySize, config.getInt(ProducerConfig.BATCH_SIZE_CONFIG), metrics, time, PRODUCER_METRIC_GROUP_NAME))
//解析server地址
List<InetSocketAddress> addresses = ClientUtils.parseAndValidateAddresses(
config.getList(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG),
config.getString(ProducerConfig.CLIENT_DNS_LOOKUP_CONFIG))
if (metadata != null) {
this.metadata = metadata
} else {
//初始化元数据类
this.metadata = new ProducerMetadata(retryBackoffMs,
config.getLong(ProducerConfig.METADATA_MAX_AGE_CONFIG),
config.getLong(ProducerConfig.METADATA_MAX_IDLE_CONFIG),
logContext,
clusterResourceListeners,
Time.SYSTEM)
this.metadata.bootstrap(addresses)
}
//初始化sender线程
this.sender = newSender(logContext, kafkaClient, this.metadata)
String ioThreadName = NETWORK_THREAD_PREFIX + " | " + clientId
this.ioThread = new KafkaThread(ioThreadName, this.sender, true)
//启动sender线程
this.ioThread.start()
config.logUnused()
AppInfoParser.registerAppInfo(JMX_PREFIX, clientId, metrics, time.milliseconds())
log.debug("Kafka producer started")
} catch (Throwable t) {
// call close methods if internal objects are already constructed this is to prevent resource leak. see KAFKA-2121
close(Duration.ofMillis(0), true)
// now propagate the exception
throw new KafkaException("Failed to construct kafka producer", t)
}
}
- 可以看到 kafka首先加载的是配置 并且解析配置 生成一个专门的配置对象 ProducerConfig 所有的配置信息都可以从这个对象中获取
- 先初始化分区器 在初始化序列化器 (注意 1.这只是构造函数的初始化顺序 不是发送消息分区器和执行器的初始化顺序 2. 分区器和序列化器都可以实现Configurable接口 在对象创建后 都会调用其configure方法进行一些初始化操作 这种方式值得借鉴)
- 初始化保存元数据的对象
- 初始化accumulator消息收集器
- 创建sender线程 并且启动sender线程


