

前言
本文将介绍 Redis 数据库重要的数据结构之一——字典。什么是字典?Redis 如何实现字典?字典的基本操作和应用有哪些?下面围绕这三个问题来逐步讲解。
什么是字典
字典,又称为符号表(symbol table)、关联数组(associative array)或映射表(map),是一种用于保存键值对(key-value pair)的抽象数据结构。
在字典中,一个键(key)可以和一个值(value)进行关联(或者说将键映射为值),这些关联的键或值就称为键值对。
字典中每个键都是独一无二的,程序可以在字典中根据键查找与之关联的值,或者通过键来更新值,又或者根据键来删除整个键值对,等等。
字典经常作为一种数据结构内置在很多高级编程语言里面,但 Redis 所使用的 C 语言并没有内置这种数据结构,因此 Redis 构建了自己的字典实现。
字典在 Redis 中的应用相当广泛,比如 Redis 的数据库就是使用字典来作为底层实现的,对数据库的增、删、改、查操作也是构建在对字典的操作之上的。
举个例子:当我们执行命令:
127.0.0.1:6379> set msg "hello world"
OK
在数据库中创建一个键为“msg”,值为“hello world”的键值对时,这个键值对就是保存在代表数据库的字典里面的。
除了用于表示数据库之外,字典还是哈希键的底层实现之一,当一个哈希键包含的键值对比较多,又或者键值对中的元素都是比较长的字符串时,Redis 就会使用字典作为哈希键的底层实现。
举个例子,website 是一个包含 10086 个键值对的哈希键,这个哈希键的键都是一些数据库的名字,而键的值就是数据库的主页网址:
127.0.0.1:6379> hlen website
(integer) 10086
127.0.0.1:6379> hgetall website
1) "Redis"
2) "Redis.io"
3) "MariaDB"
4) "MariaDB.org"
5) "MongoDB"
6) "MongoDB.org"
# ...
website 键的底层实现就是一个字典,字典中包含了 10086 个键值对,例如:
- 键值对的键为“Redis”,值为“Redis.io”
- 键值对的键为“MariaDB”,值为“MariaDB.org”
- 键值对的键为“MongoDB”,值为“MongoDB.org”
如何设计一个字典
在上面我们提到过,C 语言是没有字典这种数据结构的,因此 Redis 要自己设计字典数据结构。Redis 整个数据库就是用字典来存储的,根据 Redis 数据库的特点,可知字典有如下特征:
- 可以存储海量数据,键值对是映射关系,可以根据键以 O(1) 的时间复杂度取出或插入关联值。
- 键值对中键的类型可以是字符串、整型、浮点型等,且键是唯一的。 例如:执行 set test "hello world" 命令,此时的键 test 类型为字符串,如果 test 这个键存在数据库中,则为修改操作,否则为插入操作。
- 键值对中值的类型可为 String、Hash、List、Set、SortedSet。
接下来,我们围绕上述 3 个特征,逐步讲解字典这个数据结构该如何去设计。
特征一:海量数据存储,O(1) 复杂度取值
既然我们要实现海量数据存储,那么我们的字典数据结构中第一个字段应该为 data,用于指向数据存储的内存地址。
“海量数据中可以 O(1) 的时间复杂度去取值”,能实现这个特征的数据结构我们首先想到的 C 数组,既可以存储海量数据,又可以根据下标以 O(1) 的时间复杂度取值。此时我们暂定第一个字段 data 应该是一个数组。接下来,让我们研究一下 C 数组实现原理,来看一下为何 C 数组会如此高效。
C 数组原理
有限个类型相同的对象的集合称为 数组,组成数组的各个对象称为数组的 元素,用于区分数组的各个元素的数字编号称为 下标,元素的类型可为:数组、字符、指针、结构体等。
那么 C 数组时如何做到以 O(1) 的时间复杂度读取数据呢?
我们先来声明一个数组变量:
int a[10];
我们用 C 语言声明了一个长度为 10 的数组 a,换句话说,数组 a 是由 10 个相同类型的对象组成的集合,这 10 个对象存储在一块连续的内存中,默认 a 指向的是首地址。
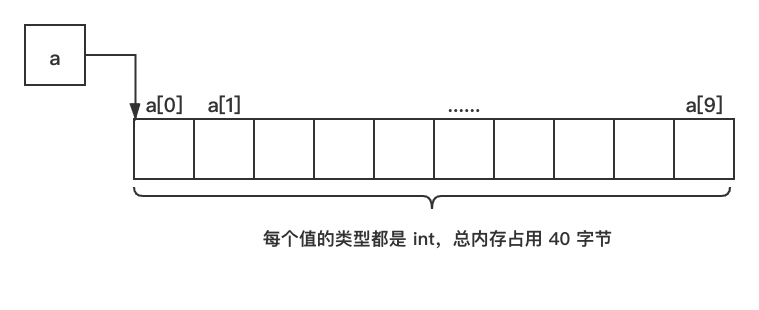
当需要对数组 a 中元素进行操作时,C 语言需通过下标找到其对应的内存地址,然后才能对这块内存进行对应的操作。例如,当我们要读取 a[9] 的值,C 语言实际上先转化为 *(a+9) 的形式,a[9] 与 *(a+9) 这两种形式是等价的,我们对等式两边再取地址,便可得出 &[a]==a+9,也就是说,要得到 a[9] 的地址,可以通过对数组 a 的首地址偏移 9 个元素就行,由此也可以知道,数组根据下标取值时,是通过头指针和偏移量来实现。如下图所示:
![a[9] 读取示意](https://github.com/wys1996/imageRepository/blob/master/dict_image/a%5B9%5D%20%E8%AF%BB%E5%8F%96%E7%A4%BA%E6%84%8F.png?raw=true)
当一个数据中数据非常海量时,通过头指针+偏移量的方式也能以 O(1) 的时间复杂度定位到数据所在的内存地址,然后进行对应的操作。C 数组的这个特征,显然是解决海量数据存储并使其能快速读取的不二之选。
通过数组介绍可知,C 数组通过下标可以快速定位到元素,且只要内存够用,也可以存储海量的数据,基本满足第一个特征。
因此,满足特征一的字典数据结构示意图可设计如下图:

特征二:键是唯一的,可为字符串、整型、浮点型等
通过前文数组介绍可知,“下标”的含义是数组中第几个元素的意思,只能为整数。而在特征二中,键值对中的键的类型可以为字符串、整型、浮点型等,显然不能直接当成下标使用,此时,需要对键做一些特殊处理,处理的过程我们称之为 Hash。
Hash 函数
Hash 一般翻译为“散列”,也有直接音译为“哈希”,作用是把任意长度的输入通过散列算法转换成固定类型、固定长度的散列值,换句话说,Hash 函数可以把不同键转换成唯一的整型数据。散列函数一般拥有如下特征:
- 相同的输入经 Hash 计算后得出相同输出;
- 不同的输入经 Hash 计算后一般得出不同输出值,但也可能会出现相同输出值。
所以,好的 Hash 算法是经过 Hash 计算后其输出值具有强随机分布性,例如 Daniel J.Bernstein 在 comp.lang.c 上发布的“times 33”散列函数,其使用的核心算法是:hash(i)=hash(i-1)*33+str[i],这是针对字符串已知的最好的散列函数之一,因为其计算速度快,而且输出值分布得很好。
在应用上,通常使用现成的开源 Hash 算法,例如 Redis 自带客户端就是使用 “times 33” 散列函数来计算字符串的 Hash 值,Redis 服务端的 Hash 函数使用的是 siphash 算法,主要功能与客户端 Hash 函数类似,其优点是针对有规律的键计算出来的 Hash 值也具有强随机分布性,但算法较为负责,因此,我们以客户端的 Hash 函数作为示例,来理解 Hash 算法,
static unsigned int dictGenHashFunction (const unsigned char *buf, int len) {
unsigned int hash = 5381;
while (len--)
hash = ((hash << 5) + hash) + (*buff++) /* hash * 33 + c */
return hash;
}
hash << 5 即 hash * 32,(hash << 5) + hash) 即 hash * 33。
dictGenHashFunction 函数的主要作用是:入参是任意长度的字符串,通过 Hash 计算后返回无符号整型数据。 因此,我们可以通过 Hash 函数,将任意输入的键转换成整型数据,使其可以当做数组的下标使用。
读到这里,我们可能内心充满了疑惑,之前我们说了字典中的第二个特征是“键的类型可以为字符串、整型、浮点型等”,而 Hash 函数只把字符串转换成整型数据,当遇到键的类型为非字符串时该如何处理呢?
其实呢,答案很简单,键的类型是在客户端感知的,而 Redis 服务端收到客户端发送的键实际都是字符串。
虽然 Hash 函数可以将任意输出的键转换成整型数据输出,但是又引进了一个新的问题,键的 Hash 值非常大,直接拿来用于当做数组下标显然不太行,数据的下标过大,就会导致数组所占的内存过大。那我们就应该给这个数组的大小设限,当数据快要用完时,需要给数组扩容,还需要一个已存入数据量的字段,因此,我们设计的字典数据结构还需要添加两个字段:① 总容量——size 字段;② 已存入数据量 used 字段。 加入这两个字段之后,字典数据结构示意图如下:
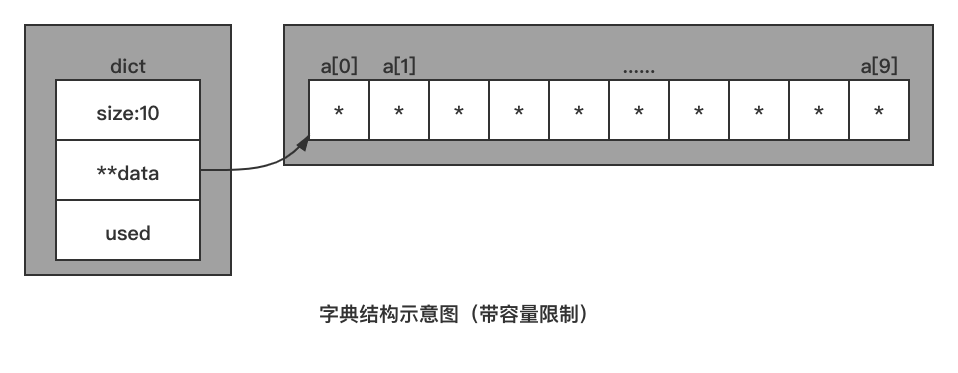
那过大的 Hash 值与较小的数组下标怎么关联呢?最简单的办法是,用 Hash 值与数组容量取余,会得到一个永远小于数组容量大小的值,此时的值也就恰好可以当做数组下标来使用,我们把取余之后的值称为键在该字典中的索引值,即“索引值==数组下标值”。 但是该方法是有问题的,就是容易导致 Hash 冲突。
Hash 冲突
通过前面 Hash 简介可知,不同的键输入经 Hash 计算后的值具有强随机分布性,但也有小概率是相同的值,此时会导致键最终计算的索引值相同,也就是说,此时两个不相同的键会关联上同一个数组的下标,我们称这些键出现了冲突。
为了解决 Hash 冲突,所以数组中的元素除了应把键值对中的“值”存储外,还应该存储“键”信息和一个 next 指针,next 指针可以把冲突的键值对串成单链表,“键”信息用于判断是否为当前要查找的键。 此时数组中元素的字段也明确了,字典数据结构示意图如下所示:
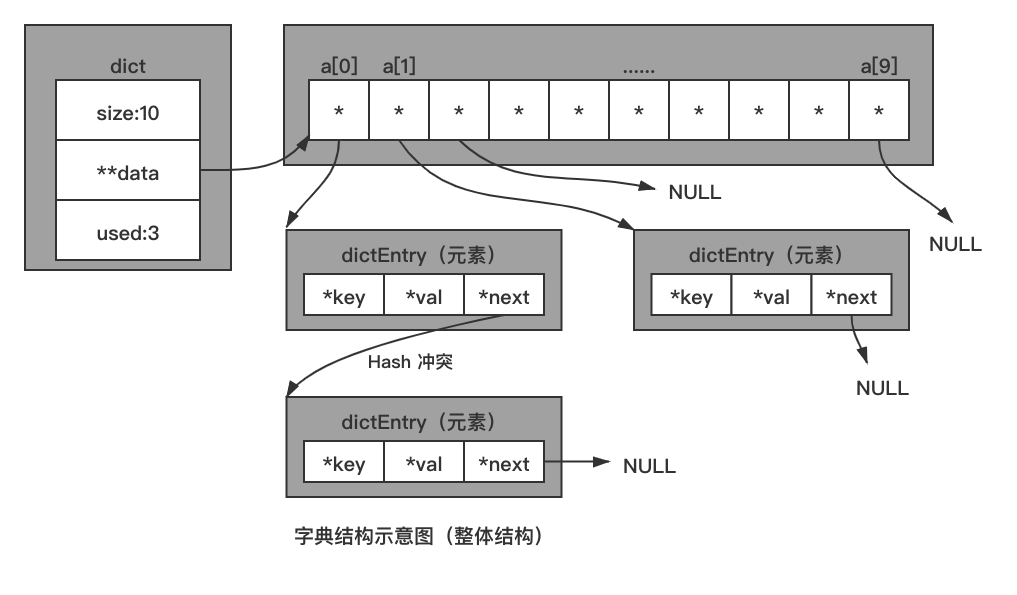
当根据键去找值时,分为如下几步:
- 键通过 Hash、取余等操作得到索引值,根据索引值找到对应元素。
- 判断元素中键与查找的键是否相等,相等则读取元素中的值返回,否则判断 next 指针是否有值,如果存在值,则读取 next 指向元素,回到第 2 步继续执行,如果不存在值,则代表此键在字典中不存在,返回 NULL。
字典数据结构设计到这,第二个特征的前半部分也就实现了,还有一个特征是“键是唯一的”,所以在每次键值对插入字典前都执行一遍上述查找操作,如果键已经存在则修改该元素中的值就行,否则执行插入操作。
特征三:键值对中值的类型可为 String、Hash、List、Set 等
我们如何保证键值对中值的类型可以是各种类型呢,其实这个也很简单,就是将数组元素中的 val 字段设置成指针,通过指针指向值所在任意内存。
至此,我们对字典这个数据结构的设计就完成了,想必我们也已经知道字典产生的前因后果了,接下来我们一起来看下 Redis 中字典是如何实现的。
Redis 中字典的实现
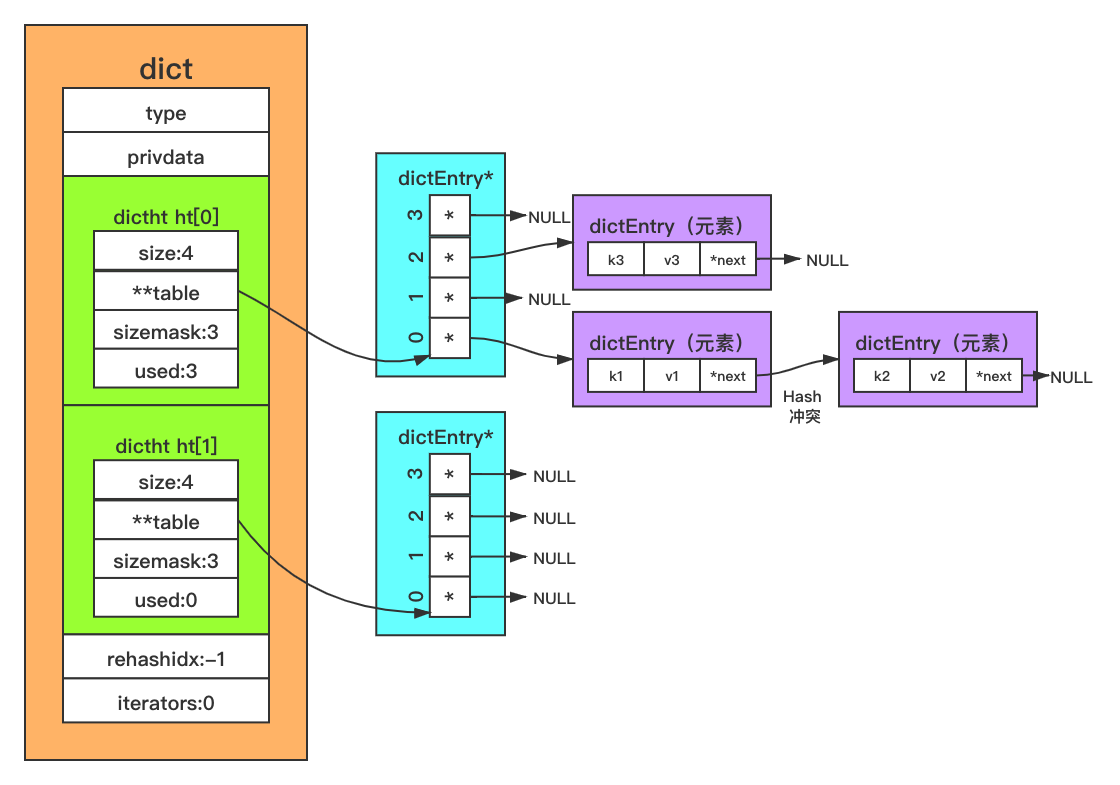
Redis 字典结构使用 Hash 表作为底层实现,一个 Hash 表里面可以有多个 Hash 表节点,而每个 Hash 表节点就保存字典中的一个键值对。接下来,我们就分别介绍 Hash 表、Hash 表节点以及字典实现,内容参考源码 dict.c 和 dict.h
Hash 表
typedef struct dictht {
dictEntry **table; /* 指针数组,用于存储键值对 */
unsigned long size; /* table 数组的大小 */
unsigned long sizemask; /* 掩码 = size - 1 */
unsigned long used; /* table 数组中已存元素个数,包含 next 单链表数据 */
} dictht;
上述结构就是 Hash 表结构,每个字典中有两个这样的结构,用于字典 rehash 使用。后续我们会看到。
Hash 表整体结构占 32 字节(8 + 8 + 8 + 8)。其中 table、size、used 字段相信我们已经清楚了其代表的含义。
- table:数组,存储键值对,该数组中的元素指向的是 dictEntry 的结构体,每个 dictEntry 里面存有键值对;
- size:table 数组的总大小;
- used:table 数组已存键值对个数;
我们来看看 sizemask 字段。sizemask 字段用来计算键的索引值,sizemask 的值恒等于 size - 1。引入这个字段是为了加速将散列值转化为数组索引。
那么 Redis 是如何通过 sizemask 字段来提高散列值转化成数组索引速度呢,步骤如下:
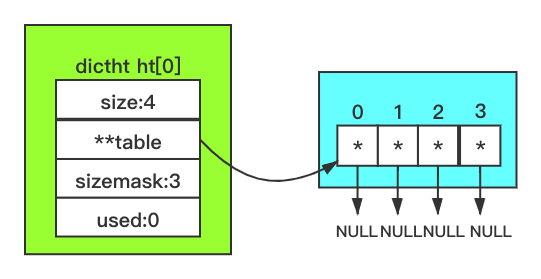
- 人为设定 Hash 表的数组容量初始值为 4,随着键值对存储量的增加,就需对 Hash 表扩容,新扩容的容量大小设定为当前容量大小的一倍,也就是说,Hash 表的容量大小只能为 4,8,16,32……。而 sizemask 掩码的值就只能为 3,7,15,31……,对应二进制为 11,111,1111,11111……。因此掩码的二进制肯定是每一位都为 1。
- 索引值 = Hash 值 & 掩码值。对应 Redis 源码为:
idx = hash & d->ht[table].sizemask,其计算结果等同 Hash 值与 Hash 表容量取余,而计算机的位运算要比取余运算快很多。
空 Hash 表结构示意图如下:
Hash 表节点
Hash 表中的元素是用 dictEntry 结构体来封装的,主要作用是存储键值对,具体结构如下:
typedef struct dictEntry {
void *key; /* 存储键 */
union { /* 使用联合体存储,不同时刻使用不同的值,只能存放一个被选中的成员 */
void *val; /* db.dict 中的 val */
uint64_t u64;
int64_t s64; /* db.expires 中存储过期时间 */
double d;
} v; /* 值,是个联合体 */
struct dictEntry *next; /* 当 Hash 冲突时,指向冲突的元素,形成单链表 */
} dictEntry;
dictEntry 成员特性如下:
- key 是一个指针,表示键值对中的键,是 void* 类型,代表其可以指向任意类型,依靠这一点 dict 便可以实现键的伪泛型;
- v 是联合体,表示键值对中的值。不论是 val、u64、s64、d 都是 8 字节大小。同时由于 val 是 void* 类型,代表其可以指向任意类型,依靠这一点可以实现值的伪泛型。每个 dictEntry 中的 v 只会为一种类型。
- next 是指向下一节点的指针,用于解决 Hash 冲突(链地址法)。
关键点:
-
Hash 表中元素结构体 dictEntry 整体结构占用 24 字节(8 + 8 + 8,联合体的大小取其中类类型最长字节的大小)。
-
联合体 v 在不同场景下使用不同字段,例如:
- 用字典存储整个 Redis 数据库所有的键值对时,用的是 *val 字段,可以指向不同类型的值;
- 字典被用作记录键的过期时间是,用的是 s64 字段存储;
-
当出现了 Hash 冲突时,next 字段用来指向冲突的元素,通过 头插法,形成单链表。
当有三个键值对,分别依次添加 k2=>v2、k1=>v1、k3=>v3,假设 k1 与 k2 Hash 出现冲突,那么这是 3 个键值对在字典中存储结构示意图如下图所示:
.png?raw=true)
注:图中 dictEntry* 是一个指针数组。
字典
Redis 字典实现除了包含前面介绍的两个结构体 Hash 表以及 Hash 表节点外,还在最外面一层封装了一个叫字典的数据结构,其主要作用是对散列表再进行一层封装,当字典需要进行一些特殊操作时要用到里面的辅助字段。具体结构如下:
typedef struct dict {
dictType *type; /* 该字典对应的特定操作函数 */
void *privdata; /* 该字典依赖的数据 */
dictht ht[2]; /* Hash 表,键值对存储在此。有两个,用于 rehash 时候使用 */
long rehashidx; /* rehash 标识。默认值为 -1,代表没进行 rehash 操作;不为 -1 时,代表正进行 rehash 操作,存储的值表示 Hash 表 ht[0] 的 rehash 操作进行到了哪个索引值 */
unsigned long iterators; /* 当前运行的迭代器数 */
} dict;
字典这个结构整体占用 96 字节(8 + 8 + 32*2 + 8 + 8)。其中 type 字段,指向 dictType 结构体,里面包含了对该字典操作的函数指针,具体如下:
typedef struct dictType {
uint64_t (*hashFunction)(const void *key); /* 该字典对应的哈希函数 */
void *(*keyDup)(void *privdata, const void *key); /* 键对应的复制函数 */
void *(*valDup)(void *privdata, const void *obj); /* 值对应的复制函数 */
int (*keyCompare)(void *privdata, const void *key1, const void *key2); /* 键的比较函数 */
void (*keyDestructor)(void *privdata, void *key); /* 键的销毁函数 */
void (*valDestructor)(void *privdata, void *obj); /* 值的销毁函数 */
} dictType;
Redis 字典这个数据结构,除了主数据库的 K-V 数据存储外,还有很多其它地方会用到。例如:Redis 的哨兵模式,就用字典存储管理所有的 Master 节点及 Slave 节点;再如,数据库中的键值对的值为 Hash 类型时,存储这个 Hash 类型的值也是用的字典。在不同的应用中,字典中的键值对形态都可能不同,而 dictType 结构体,则是为了实现各种形态的字典而抽象出来的一组操作函数。
其它字段含义如下:
-
privdata 字段:私有数据,配合 type 字段指向的函数一起使用;
-
ht 字段:是个大小为 2 的数组,该数组存储的元素类型为 dictht,虽然有两个元素,但一般情况下,只会使用 ht[0],只有当该字典扩容、缩容需要进行 rehash,才会用到 ht[1],后续我们会详细介绍这部分内容。
-
rehashidx 字段:用来标记该字典是否在进行 rehash,没进行 rehash 时,值为 -1,否则,该值用来表示 Hash 表 ht[0] 执行 rehash 到了哪个元素,并记录该元素的数组下标值。
-
iterators 字段:用来记录当前运行的安全迭代器数,当有安全迭代器绑定到该字典时,会暂停 rehash 操作。Redis 很多场景下都会用到迭代器,例如:执行 keys 命令会创建一个安全迭代器,此时 iterators 会加 1,命令执行完毕则减 1,而执行 sort 命令时会创建普通迭代器,该字段不会改变,关于迭代器我们后续详细介绍。
因此,一个完整的 Redis 字典数据结构如下图所示:
基本操作
前面我们讲解了字典的概念、如何设计一个字典以及 Redis 字典的实现,接下来我们通过执行命令以及阅读源码,来看一下 Redis 字典是如何进行初始化以及添加、修改、查找、删除元素的。
字典初始化
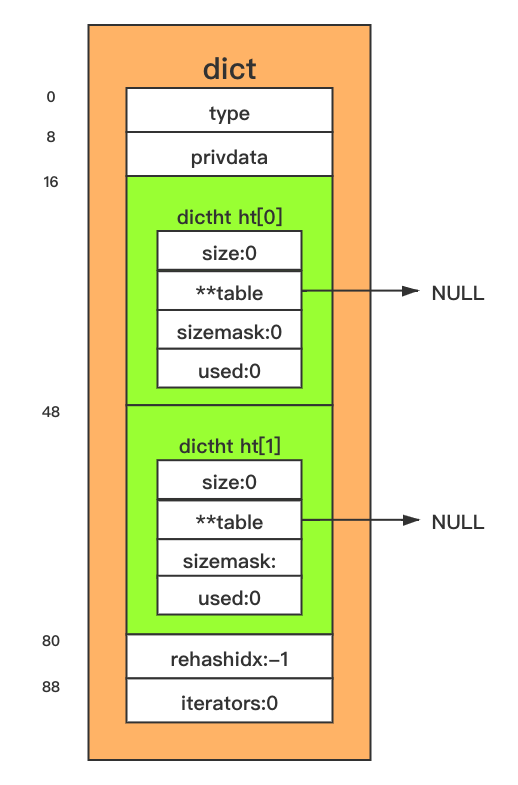
在 redis-server 启动中,整个数据库会先初始化一个空的字典用于存储整个数据库的键值对,初始化一个空字典,调用的是 dictCreate 方法。
/* dict-benchmark [count] */
int main(int argc, char **argv) {
long j;
long long start, elapsed;
dict *dict = dictCreate(&BenchmarkDictType,NULL);
...
创建字典的方法 dictCreate 源代码如下,该方法首先为字典数据结构申请一块内存,然后调用 _dictInit 方法为字典结构体初始化值。
/* 创建一个新的 Hash 表 */
dict *dictCreate(dictType *type,
void *privDataPtr)
{
dict *d = zmalloc(sizeof(*d)); // 为字典分配内存,共 96 字节
_dictInit(d,type,privDataPtr); // 结构体初始化值
return d;
}
结构体初始化值的方法 _dictInit 源代码如下,该方法将结构体中字段 type 和 privdate 赋值,并将 rehashidx 字段设置为 -1,代表没有执行 rehash 操作,将 iterators 字段设置为 0,代表此时没有安全迭代器绑定到该字典,并调用了 _dictReset 方法为该字典中两个 Hash 表初始化值。
/* 初始化 Hash 表 */
int _dictInit(dict *d, dictType *type,
void *privDataPtr)
{
_dictReset(&d->ht[0]);
_dictReset(&d->ht[1]);
d->type = type;
d->privdata = privDataPtr;
d->rehashidx = -1;
d->iterators = 0;
return DICT_OK;
}
Hash 表初始化值的方法 _dictReset 源代码如下,该方法将 Hash 表结构体的各个成员设置为默认值。
static void _dictReset(dict *ht) {
ht->table = NULL;
ht->size = 0;
ht->sizemask = 0;
ht->used = 0;
}
一句话总结 dictCreate 函数初始化一个空字典的主要步骤:申请空间、调用 _dictInit 函数,给字典的各个字段赋予初始值。 初始化后,一个字典内存占用情况如下图所示:
添加元素
在 Bash 中,我们添加一个键值对,命令如下:
127.0.0.1:6379> set k1 v1
OK
该命令就是向 Redis Server 端发送一条添加元素的命令,Server 端收到命令后,最终会执行到 void setKey(redisDb *db, robj *key, robj *val) 函数。我们在前面说到,字典的特性中有一条,即每个键必须是唯一的,所以元素添加需要如下几步才能完成:先查找该键是否存在,存在则执行修改,否则添加键值对。而 setKey 函数的主要逻辑也是如此,其主要流程如下:调用 dictFind 函数,查询键是否存在,是则调用 DBOverwrite 函数修改键值对,否则调用 dbAdd 函数 添加元素。
void setKey(redisDb *db, robj *key, robj *val) {
if (lookupKeyWrite(db,key) == NULL) { /* 查找 key 是否存在 */
dbAdd(db,key,val); /* 不存在则添加 key */
} else {
dbOverwrite(db,key,val); /* 存在则覆盖 */
}
incrRefCount(val); /* 增加值的引用计数 */
removeExpire(db,key); /* 充值键在数据库里的过期时间 */
signalModifiedKey(db,key); /* 发送修改键的通知 */
}
我们研究一下 dbAdd 方法。
void dbAdd(redisDb *db, robj *key, robj *val) {
sds copy = sdsdup(key->ptr); /* 复制键名 */
int retval = dictAdd(db->dict, copy, val); /* 尝试添加键值对 */
serverAssertWithInfo(NULL,key,retval == DICT_OK); /* 如果键已存在,那么停止 */
if (val->type == OBJ_LIST ||
val->type == OBJ_ZSET)
signalKeyAsReady(db, key); /* 将该键添加到 server.ready_keys 链表中 */
if (server.cluster_enabled) slotToKeyAdd(key); /* 如果开启了集群模式,那么将键保存到槽里面 */
}
我们可以看到,dbAdd 方法最终实际调用了 dictAdd 方法来插入键值对,因此,我们主要研究下该方法。
dictAdd 方法源代码如下:
/* 添加一个元素到目标 Hash 表中 */
int dictAdd(dict *d, void *key, void *val)
{
dictEntry *entry = dictAddRaw(d,key,NULL); /* 添加键,字典中键已存在则返回 NULL,否则添加键至新节点中,返回新节点 */
if (!entry) return DICT_ERR; /* 键存在则返回错误 */
dictSetVal(d, entry, val); /* 设置值 */
return DICT_OK;
}
dictAdd 函数方法的逻辑也很简单,即:
- 调用
dictAddRow函数,添加键,字典中键已存在则返回 NULL,否则添加键至 Hash 表,并返回新加的 Hash 节点; - 给返回的新节点设置值,即更新其 val 字段。
我们再来看一下 dictAddRow 函数是如何做到添加键或者查找键,代码如下:
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing) /* 入参字典、键、Hash 表节点地址 */
{
long index;
dictEntry *entry;
dictht *ht;
if (dictIsRehashing(d)) _dictRehashStep(d); /* 该字典是否在进行 rehash 操作,是则执行一次 rehash */
if ((index = _dictKeyIndex(d, key, dictHashKey(d,key), existing)) == -1) /* 查找键,找到则直接返回 -1,并把老节点存入 existing 字段,否则把新节点的索引值返回。如果遇到 Hash 表容量不足,则进行扩容 */
return NULL;
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0]; /* 是否在进行 rehash 操作中,是则插入至散列表 ht[1] 中,否则插入散列表 ht[0] */
entry = zmalloc(sizeof(*entry)); /* 申请新节点内存 */
entry->next = ht->table[index]; /* 将该节点的 next 指针指向 ht->table[index] 指针指向的位置 */
ht->table[index] = entry; /* 将 ht->table[index] 指针指向该节点 */
ht->used++;
dictSetKey(d, entry, key); /* 给新节点存入键信息 */
return entry;
}
dictAddRaw 函数主要作用是添加或查找键:
-
如果查找成功返回 NULL,并将老节点存入 existing 字段。
-
否则添加该节点,并返回,步骤如下:
- 获取索引位置 index;
- 首先判断是否在进行 rehash,是则插入至散列表 ht[1] 中,否则插入散列表 ht[0]
- 为新节点申请内存;
- 更新该节点的 next 指针,为 ht->table[index] 指针指向的位置;
- 更新 ht->table[index] 指针指向新节点(头插法);
- 给新节点存入键信息;
- 返回节点。
_dictKeyIndex 函数方法源码如下:
static int _dictKeyIndex(dict *ht, const void *key) {
unsigned int h;
dictEntry *he;
if (_dictExpandIfNeeded(ht) == DICT_ERR) /* 如果需要则扩展 Hash 表 */
return -1;
h = dictHashKey(ht, key) & ht->sizemask; /* 计算 key 的 Hash 值 */
/* 搜索该位置是否已经包含该 key */
he = ht->table[h];
while(he) {
if (dictCompareHashKeys(ht, key, he->key))
return -1;
he = he->next;
}
return h;
}
该方法的作用是得到键的索引值,索引值的获取与前面介绍的类似,主要有这么两步:
dictHashKey(ht, key):调用该字典的 Hash 函数得到键的 Hash 值;dictHashKey(ht, key) & ht->sizemask:用键的 Hash 值与字典掩码取余,得到索引值。
dictAddRaw 函数拿到键的索引值后则可直接定位“键值对”要存入的位置,新创建一个节点存入即可。执行完添加键值对操作后,字典对应的内存占用结构示意图如下:
.png?raw=true)
说明:dictEntry 中 key 与 v.val 实际为指针,为展示方便,故将值直接写入 dictEntry 中。
字典扩容
随着 Redis 数据库添加操作逐步进行,存储键值对的字典会出现容量不足,达到上限,此时就需要对字典的 Hash 表进行扩容,扩容代码如下:
int dictExpand(dict *d, unsigned long size)
{
if (dictIsRehashing(d) || d->ht[0].used > size) /* 如果此时正在扩容,或者是扩容大小小于 ht[0] 的表大小,则抛错 */
return DICT_ERR;
dictht n; /* 新 hash 表 */
unsigned long realsize = _dictNextPower(size); /* 重新计算扩容后的值,必须为 2 的 N 次方幂 */
/* Rehashing to the same table size is not useful. */
if (realsize == d->ht[0].size) return DICT_ERR; /* 重新计算的值如果和原来的 size 相等,则无效 */
/* 分配新 Hash 表,并初始化所有指针为 NULL */
n.size = realsize;
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
/* 初始化的情况,而不是进行 rehash 操作,就用 ht[0] 来接收值 */
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
/* 准备第二个 Hash 表,以便执行渐进式哈希操作 */
d->ht[1] = n; /* 扩容后的新内存放入 ht[1] 中 */
d->rehashidx = 0; /* 非默认的 -1,表示需进行 rehash */
return DICT_OK;
}
扩容的主要流程为:
- 申请一块新内存,初次申请时默认容量大小为 4 个 dictEntry;非初次申请时,申请内存的大小为当前 Hash 表容量的一倍;
- 把新申请的内存地址赋值给 ht[1],并把字典的 rehashidx 标识由 -1 改为 0,表示之后需要进行 rehash 操作。
此时,字典的内存结构示意图如下图所示:
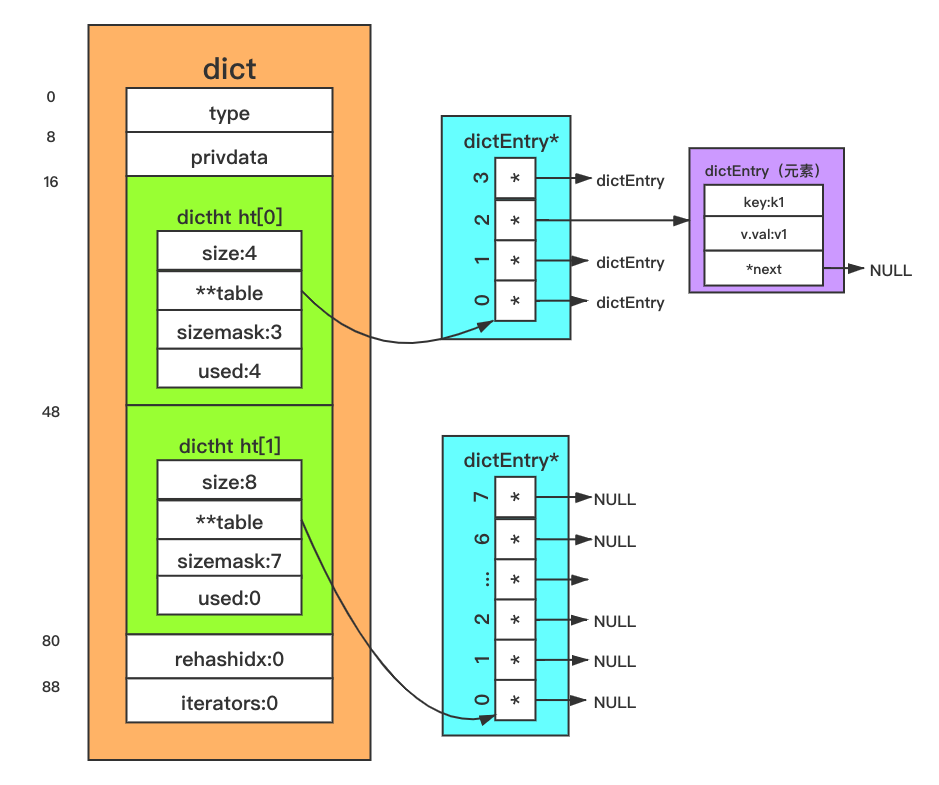
注意:扩容后,字典容量及掩码值会发生改变,同一个键与掩码经位运算后得到的索引值就会发生改变,从而导致根据键查找不到值的情况。解决这个问题的方法是:新扩容的内存放到一个全新的 Hash 表中(ht[1]),并给字典打上在进行 rehash 操作中的标识(即 rehashidx != -1)。此后,新添加的键值对都往新的 Hash 表中存储;而修改、删除、查找操作需要在 ht[0]、ht[1] 中进行检查,然后再决定对哪个 Hash 表操作。
我们在上面添加元素的时候,还谈到了 _dictExpandIfNeeded 函数,那么我们再来看一下这个函数时做什么的。
static int _dictExpandIfNeeded(dict *d)
{
if (dictIsRehashing(d)) return DICT_OK; /* 正在进行 rehash,则返回 */
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE); /* 如果表容量为 0 ,则设置表容量为初始值 4 */
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio)) /* 判断是否需要扩容 */
{
return dictExpand(d, d->ht[0].used*2);
}
return DICT_OK;
}
从这里我们可以看到,这个函数的实际作用是判断是否需要扩容,那么什么时候需要扩容呢?
- 正在 rehash 不会进行扩容。
- Hash 表的大小为 0, 扩容至初始值 4。
- 正常情况下,ict_can_resize 为 1,哈希表中键值对个数大于等于哈希表大小,就会扩容到键值对个数的两倍。
- 有些情况下 dict_can_resize 为 0,redis 就会避免扩容,但是如果哈希表已经很满(负载因子大于 5),这时候会强制扩容。
除此之外,还需要把老 Hash 表(ht[0])中的数据重新计算索引值后全部迁移插入到新的 Hash 表(ht[1])中,此迁移过程称作 rehash,下面我们来看一下 rehash 的实现。
渐进式 rehash
rehash 操作除了扩容时会触发,缩容时也会触发。rehash 代码如下:
int dictRehash(dict *d, int n) {
int empty_visits = n*10; /* 最大访问的空桶的数量,n*10 */
if (!dictIsRehashing(d)) return 0; /* dict 没有正在进行 rehash 时,直接返回 */
while(n-- && d->ht[0].used != 0) { /* n 为最多迁移元素数量 */
dictEntry *de, *nextde;
assert(d->ht[0].size > (unsigned long)d->rehashidx); /* 为防止 rehashidx 越界,当 rehashidx 大于 ht[0] 的数组大小时,不继续执行 */
while(d->ht[0].table[d->rehashidx] == NULL) { /* 当 rehashidx 位置的桶为空时,继续向下遍历,直到桶不为空或者达到最大访问空桶的数量 */
d->rehashidx++;
if (--empty_visits == 0) return 1; /* 最大访问空桶数量--,减完后,如果为 0,则退出 */
}
de = d->ht[0].table[d->rehashidx]; /* 当前桶中的元素,dictEntry 指针 */
while(de) { /* 遍历桶中元素,将元素从旧表移动到新表 */
uint64_t h;
nextde = de->next;
h = dictHashKey(d, de->key) & d->ht[1].sizemask; /* 获取 key 在 ht[1] 表中的索引 */
de->next = d->ht[1].table[h]; /* 头结点插入 */
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL; /* ht[0] 对应桶置为空 */
d->rehashidx++;
}
if (d->ht[0].used == 0) { /* 检查是否已经 rehash 完成 */
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
return 1;
}
rehash 的原理其实很简单,就是将 ht[0] 中表的数据重建索引放到 ht[1] 中。那么为什么要有 渐进式哈希 这个概念呢?
我们知道,Redis 可以提供高性能的线上服务,而且是单进程模式,当数据库中键值对数量达到了百万、千万、亿级别时,整个 rehash 过程将非常缓慢,如果不优化 rehash 过程,可能会造成很严重的服务不可用现象。Redis 的优化的思想很巧妙,利用分而治之的思想进行 rehash 操作。大致的步骤如下:
- 执行插入、删除、查找、修改等操作前,都先判断当前字典 rehash 操作是否在进行中,进行中则调用
dictRehashStep函数进行 rehash 操作(每次只对 1 个节点进行 rehash 操作,共执行 1 次)。 - 除这些操作外,当服务空闲时,如果当前字典也需要进行 rehash 操作,则会调用
incrementallyRehash函数进行批量 rehash 操作(每次对 100 个节点进行 rehash 操作,共执行 1 毫秒)。
在经历 N 次 rehash 操作后,整个 ht[0] 的数据都会迁移到 ht[1] 中,这样做的好处就是把本应集中处理的时间分散到了上百万、千万、亿次操作中,所以其耗时可忽略不计。
那么单次 rehash 操作是如何实现渐进式呢,其实是:
- 用
n来存储最多迁移的数量,每迁移一个 key,n--; - 或者是维护一个
empty_visits字段,用来表示最多访问空桶的数量,值为n*10,每当方位一个空桶的时候,就执行--empty_visits。
当上述 n 或 empty_visits 中任意一个字段为 0 时,都跳出循环。
当然渐进式哈希操作中还要注意下面几点:
- key 从 ht[0] 移到 ht[1] 中时,需要重新计算 hash 值。
- 插入 ht[1] 中采用头结点插入;
rehashidx++;- 当
ht[0].used == 0时,需要将 rehashidx 字段值为 -1。
这些,我们上面都讲到了,就不详细说了。
查找元素
dictEntry *dictFind(dict *d, const void *key)
{
dictEntry *he;
uint64_t h, idx, table;
if (d->ht[0].used + d->ht[1].used == 0) return NULL; /* dict 为空时直接返回 */
if (dictIsRehashing(d)) _dictRehashStep(d); /* 如果正在进行 rehash,调用 _dictRehashStep 方法,向前推进 rehash 过程 */
h = dictHashKey(d, key); /* 计算 hash 值 */
for (table = 0; table <= 1; table++) { /* 先从第一个 hash 表 ht[0] 中查找,如果正在进行 rehash,再从 ht[1] 中查找 */
idx = h & d->ht[table].sizemask; /* 计算索引 */
he = d->ht[table].table[idx];
while(he) { /* 遍历查找 key */
if (key==he->key || dictCompareKeys(d, key, he->key))
return he;
he = he->next;
}
if (!dictIsRehashing(d)) return NULL; /* 如果没有 rehash,直接返回,否则继续去 ht[1] 中查找 */
}
return NULL;
}
static void _dictRehashStep(dict *d) {
if (d->iterators == 0) dictRehash(d,1);
}
查找键的过程,也很简单,主要分为以下几个步骤:
- 根据键调用 Hash 函数取得其 Hash 值;
- 根据 Hash 值取得索引值;
- 遍历字典的两个 Hash 表,读取索引对应元素;
- 遍历该元素单链表,如找到了与自身键匹配的键,则返回该元素;
- 找不到则返回 NULL;
需要注意的是:
- 如果正在进行 rehash 操作,那么就向前推进一步,正如在上面我们提到的一样。
- 如果 rehashidx != -1,那么说明两个表都有数据,ht[0] 查不到,要去 ht[1] 中去查。
修改元素
void dbOverwrite(redisDb *db, robj *key, robj *val) {
dictEntry *de = dictFind(db->dict,key->ptr); /* 查找键是否存在,返回存在的节点 */
serverAssertWithInfo(NULL,key,de != NULL); /* 不存在则中断执行 */
dictEntry auxentry = *de;
robj *old = dictGetVal(de); /* 获取老节点的值 val */
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
val->lru = old->lru;
}
dictSetVal(db->dict, de, val); /* 给节点设置新值 */
if (server.lazyfree_lazy_server_del) {
freeObjAsync(old);
dictSetVal(db->dict, &auxentry, NULL);
}
dictFreeVal(db->dict, &auxentry); /* 释放节点旧 val 内存 */
}
修改键的源码,虽然没有调用 dict.h 中的方法去修改字典中元素,但修改过程基本类似,Redis修改键值对,整个过程主要分如下几个步骤:
- 调用
dictFind查找键是否存在; - 不存在则中断执行;
- 修改节点键值对中的值为新值;
- 释放旧值内存。
删除元素
static int dictDelete(dict *ht, const void *key) {
unsigned int h;
dictEntry *de, *prevde;
if (ht->size == 0) /* 如果 hash 表容量为 0,直接返回错误 */
return DICT_ERR;
h = dictHashKey(ht, key) & ht->sizemask; /* 获取 hash 值 */
de = ht->table[h];
prevde = NULL;
while(de) {
if (dictCompareHashKeys(ht,key,de->key)) { /* 比较元素 key */
if (prevde)
prevde->next = de->next;
else
ht->table[h] = de->next;
dictFreeEntryKey(ht,de); /* 释放 key */
dictFreeEntryVal(ht,de); /* 释放 val */
free(de);
ht->used--;
return DICT_OK;
}
prevde = de;
de = de->next;
}
return DICT_ERR;
}
删除元素的主要的执行过程为:
- 查找该键是否存在于该字典中;
- 存在则把该节点从单链表中剔除;
- 释放该节点对应键占用的内存、值占用的内存,以及本身占用的内存;
- 给对应的 Hash 表的 used 字典减 1 操作。
当字典中数据经过一系列操作后,使用量不到总空间 <10% 时,就会进行缩容操作,将 Redis 数据库占用内存保持在合理的范围内,不浪费内存。
缩容函数如下:
#define HASHTABLE_MIN_FILL 10 /* hash 表最少填充 10% */
void tryResizeHashTables(int dbid) {
if (htNeedsResize(server.db[dbid].dict)) /* 判断是否需要缩容,used/size<10% */
dictResize(server.db[dbid].dict); /* 执行缩容操作 */
if (htNeedsResize(server.db[dbid].expires))
dictResize(server.db[dbid].expires);
}
int dictResize(dict *d) /* 缩容函数 */
{
int minimal;
if (!dict_can_resize || dictIsRehashing(d)) return DICT_ERR;
minimal = d->ht[0].used;
if (minimal < DICT_HT_INITIAL_SIZE) /* 容量最小值为 4 */
minimal = DICT_HT_INITIAL_SIZE;
return dictExpand(d, minimal); /* 调用扩容函数,实际进行的是缩容 */
}
整个缩容的步骤大致为:判断当前的容量是否达到最低阈值,即 used/size<10%,达到了则调用dictResize 函数进行缩容,缩容后的函数容量实质为 used 的最小 2^N 整数。缩容操作和扩容操作实质差不多,最终调用的都是 dictExpand 函数,之后的操作与扩容一致,这里就不在赘述了。
字典的遍历
前面已经讲解了字典的基本概念、基本操作,接下来我们再说一说字典的遍历操作,遍历数据库的原则为:
- 不重复出现数据;
- 不遗漏任何数据;
我们大家应该知道,遍历 Redis 整个数据库主要有两种方式:全遍历(例如 keys 命令)、间断遍历(hscan 命令):
- 全遍历:一次命令执行就遍历整个数据库;
- 间断遍历:每次命令执行只取部分数据,分多次遍历;
下面我们就来学习一下这两种遍历方式。
迭代器遍历
迭代器——可在容器(容器可为字典、链表等数据结构)上访问的接口,设计人员无需关心容器的内容,调用迭代器固定的接口就可遍历数据,在很多高级语言中都有实现。
字典迭代器主要用于迭代字典这个数据结构中的数据,既然是迭代字典中的数据,必然会出现一个问题,迭代过程中,如果发生了数据增删,则可能导致字典触发 rehash 操作,或迭代器开始时字典正在进行 rehash 操作,从而导致一条数据可能多次遍历到。那 Redis 如何解决这个问题呢?带着这个疑问,接下来我们一起看一下迭代器的实现。
Redis 源码中迭代器实现的基本数据结构如下:
typedef struct dictIterator {
dict *d; /* 迭代的词典 */
long index; /* 当前迭代到 Hash 表中哪个索引值 */
int table, safe; /* table 用于表示当前正在迭代的 Hash 表,即 ht[0] 和 ht[1],safe 用于表示当前创建的是否为安全迭代器 */
dictEntry *entry, *nextEntry; /* 当前节点,下一个节点 */
long long fingerprint; /* 字典的指纹,当字典未发生改变时,改值不变,发生改变时则值也随着改变 */
} dictIterator;
整个数据结构占用了 48 字节(8 + 8 + 4 + 4 + 8 + 8 + 8),其中:
- d 字段指向需要迭代的字典;
- index 字段代表当前读取到 Hash 表中哪个索引值;
- table 字段表示当前正在迭代的 Hash 表(即 ht[0] 与 ht[1] 中的 0 和 1);
- safe 字段表示当前创建的迭代器是否为安全模式;
- entry 字段表示正在读取的节点数据;
- nextEntry 字段表示 entry 节点中的 next 字段所指向的数据。
- fingerprint 字段是一个 64 位的整数,表示在给定时间内字典的状态。在这里称其为字典的指纹,因为该字典的值为字典(dict 结构体)中所有字段值组合在一起生成的 Hash 值,所以当字典中数据发生任何变化时,其值都会不同,生成的算法是
dict.c文件中的dictFingerprint函数。
为了让迭代过程变得简单,Redis 也提供了迭代相关的 API 函数,主要为:
dictIterator *dictGetIterator(dict *d); /* 初始化迭代器 */
dictIterator *dictGetSafeIterator(dict *d); /* 初始化安全的迭代器 */
dictEntry *dictNext(dictIterator *iter); /* 通过迭代器获取下一个节点 */
void dictReleaseIterator(dictIterator *iter); /* 释放迭代器 */
简单介绍完迭代器的基本结构、字段含义及 API,我们来看下 Redis 如何解决增删数据的同时不出现读取数据重复的问题。Redis 为单进程单线程模式,不存在两个命令同时执行的情况,因此只有当执行的命令在遍历的同时删除了数据,才会触发前面的问题。 我们把迭代器遍历数据分为两类:
- 普通迭代器:只遍历数据;
- 安全迭代器:遍历的同时删除数据。
1. 普通迭代器
普通迭代器迭代字典中数据时,会对迭代器中 fingerprint 字段的值做严格的校验,来保证迭代过程中字典结构不发生任何变化,确保读取出的数据不出现重复。
当 Redis 执行部分命令时会使用普通迭代器迭代字典数据,例如 sort 命令。sort 命令主要作用是对给定列表、集合、有序集合的元素进行排序,如果给定的是有序集合,其成员名存储用的是字典,分值存储用的是跳跃表,则执行 sort 命令读取数据的时候会用到迭代器来遍历整个字典。
普通迭代器迭代数据的过程比较简单,主要分为如下几个步骤:
-
调用
dictGetIterator函数初始化一个普通迭代器,此时会把 iter->safe 值置为 0,表示初始化的迭代器为普通迭代器。 -
循环调用
dictNext函数依次遍历字典中 Hash 表的节点,首次遍历时会通过dictFingerprint函数拿到当前字典的指纹值。- 注意:entry 与 nextEntry 两个指针分别指向 Hash 冲突后的两个父子节点,如果在安全模式下,删除了 entry 节点,nextEntry 字段可以保证后续迭代数据不丢失。
-
当调用 dictNext 函数遍历完字典 Hash 表中节点数据后,释放迭代器会继续调用
dictFingerprint函数计算字典的指纹值,并与首次拿到的指纹值作比较,不相等则输出异常“=== ASSERTION FAILED ===”,且退出程序执行。
普通迭代器通过步骤 1、步骤 3 指纹值对比,来限制整个迭代过程中只能进行迭代操作,即迭代过程中的字典数据的修改、添加、删除、查找等操作都不能进行,只能调用 dictNext 函数迭代整个字典,否则就报异常,由此来保证迭代器取出数据的准确性。
注意:对字典进行修改、添加、删除、查找操作都会调用 dictRehashStep 函数,进行渐进式 rehash 操作,从而导致 fingerprint 值发生改变。
2. 安全迭代器
安全迭代器和普通迭代器迭代数据原理类似,也是通过循环调用 dictNext 函数依次遍历字典中 Hash 表的节点。安全迭代器确保读取数据的准确性,不是通过限制字典的部分操作来实现的,而是通过限制 rehash 的进行来确保数据的准确性,因此迭代过程中可以对字典进行增删改查操作。
我们知道,对字典的增删改查操作会调用 dictRehashStep 函数进行渐进式 rehash 操作,那如何对 rehash 操作进行限制呢?我们一起看下 dictRehashStep 函数源码实现:
static void _dictRehashStep(dict *d) {
if (d->iterators == 0) dictRehash(d,1);
}
原理上很简单,如果当前字典有安全迭代器运行,则不进行渐进式 rehash 操作,rehash 操作暂停,字典中数据就不会被重复遍历,由此确保了读取数据的准确性。
当 Redis 执行部分命令时会使用安全磁轭带起迭代字典数据,例如 keys 命令,keys 命令主要作用是通过模式匹配,返回给定模式的所有 keys 列表,遇到过期的键会进行删除操作。Redis 数据键值对都存储在字典中,因此 keys 命令会通过安全迭代器来遍历整个字典。安全迭代器整个迭代过程也较为简单,主要分为如下几个步骤:
- 调用
dictGetSafeIterator函数初始化一个安全迭代器,此时会把 iteration->safe 值置为 1,表示初始化的迭代器为安全迭代器。 - 循环调用
dictNext函数依次遍历字典中 Hash 表的节点,首次遍历会把字典中 iterators 字段进行加 1 操作,确保迭代过程中渐进式 rehash 操作会被中断执行。 - 当调用
dictNext函数遍历完字典 Hash 表中节点数据后,释放迭代器时会把字典中 iterators 字段进行减 1 操作,确保迭代后渐进式 rehash 操作能正常进行。安全迭代器时通过步骤 1、步骤 3 中对字典的 iteratorss 子弹进行修改,使得迭代过程中渐进式 rehash 操作被中断,由此来保证迭代器读取数据的准确性。
间断遍历
上面我们讲解了“全遍历”字典的实现,但有一个问题凸显出来,当数据库中有海量数据时,执行 keys 命令进行一次数据库全遍历,耗时肯定不短,会造成短暂的 Redis 不可用,所以在 Redis 在 2.8.0 版本后新增了 scan 操作,也就是“间断遍历”。而 dictScan 是“间断遍历”中的一种实现,主要在迭代字典中数据时使用,例如 hscan 命令迭代整个数据库中的 key,以及 zscan 命令迭代有序集合所有成员与值时,都是通过 dictScan 函数来实现的字典遍历,dictScan 遍历字典过程中是可以进行 rehash 操作的,通过算法来保证所有的数据都能被遍历到。
我们来看下 dictScan 函数介绍:
unsigned long dictScan(dict *d,
unsigned long v,
dictScanFunction *fn,
dictScanBucketFunction* bucketfn,
void *privdata)
- 变量 d 是当前迭代的字典;
- 变量 v 标识迭代开始的游标(即 Hash 表中数组索引),每次遍历会返回新的游标值,整个遍历过程都是围绕这个游标值的改动进行,来保证所有的数据能被遍历到;
- fn 是函数指针,每遍历一个节点则调用该函数处理;
- bucketfn 函数在整理碎片时调用;
- privdata 是回调函数 fn 所需参数。
执行 hscan 命令时外层调用 dictScan 函数示例:
long maxiterations = count * 10; /* count 为 hscan 命令传入的 count 值,代表获取数据个数。Hash 表处于病态时(例如大部分的节点为空时),最大迭代次数为 10*n */
do {
cursor = dictScan(ht, cursor, scanCallback, NULL, privdata); /* 调用 dictScan 函数迭代字典数据,cursor 字段初始值为 hscan 命令传入值,代表迭代 Hash 数组的游标起始值 */
} while (cursor && maxiterations-- && listLength(keys) < (unsigned long)count);
dictScan 函数间断遍历字典过程中会遇到如下 3 种情况:
- 从迭代开始到结束,散列表没有进行 rehash 操作。
- 从迭代开始到结束,散列表进行了扩容或缩容操作,且恰好为两次迭代间隔期间完成了 rehash 操作。
- 从迭代开始到结束,某次或某几次迭代时,散列表正在进行 rehash 操作。
1. 遍历过程中始终未遇到 rehash 操作
每次迭代都没有遇到 rehash 操作,也就是遍历字典只遇到第 1 或第 2 种情况。其实第 1 中情况,只要依次按照顺序遍历 Hash 表 ht[0] 中节点即可,第 2 中情况因为在遍历的整个过程中,期间字典可能发生了扩容或缩容操作,如果依次按照顺序遍历,则可能会出现数据重复读取的现象。假设下标为 0 的键值对在扩容依次后可能分布在下标为 0 或 4 的节点中,倘若第 1 次遍历了 0 下标节点的数据,第 2 次遍历时字典已经进行了一次扩容操作,后续若依次遍历,则原先 0 下标节点的数据可能重复出现。Redis 为了做到不漏数据且尽量不重复数据,统一采用了一种叫做 reverse binary iteration 的方法来进行间断数据迭代。接下来看其主要源码实现,迭代的代码如下:
t0 = &(d->ht[0]);
m0 = t0->sizemask;
de = t0->table[v & m0]; /* 避免缩容后游标超出 Hash 表最大值 */
while (de) { /* 遍历循环当前节点的单链表 */
next = de->next;
fn(privdata, de); /* 依次将节点中键值对存入 privdata 字段中的单链表 */
de = next;
}
整个迭代过程强依赖游标值 v 变量,根据 v 找到当前需要读取的 Hash 表元素,然后遍历该元素单链表上所有的键值对,依次执行 fn 函数指针执行的函数,对键值对进行读取操作。
为了兼容迭代间隔期间可能发生的缩容和扩容操作,每次迭代都会对 v 变量(游标值)进行修改,以确保迭代出的数据无遗漏,游标具体变更算法为:
v |= ~m0;
v = rev(v); //二进制逆转
v++;
v = rev(v); //二进制逆转
具体算法在这里不过多介绍,如果感兴趣可以自行学习。
2. 遍历过程中遇到 rehash 操作
从迭代开始到结束,某次或某几次迭代时散列表正在进行 rehash 操作,rehash 操作中会同时并存两个 Hash 表:一张为扩容或缩容后的表 ht[1],一张为老表 ht[0],ht[0] 的数据通过渐进式 rehash 会逐步迁移到 ht[1] 中,最终完成整个迁移过程。
因为大小两表并存,所以需要从 ht[0] 和 ht[1] 中都取出数据,整个遍历过程为:先找到两个散列表中更小的表,先对小的 Hash 表遍历,然后对大的 Hash 表遍历,迭代代码如下:
t0 = &d->ht[0];
t1 = &d->ht[1];
if (t0->size > t1->size) {
t0 = &d->ht[1];
t1 = &d->ht[0];
}
m0 = t0->sizemask;
m1 = t1->sizemask;
de = t0->table[v & m0];
while (de) { /* 迭代第一张小 Hash 表 */
next = de->next;
fn(privdata, de);
de = next;
}
do { /* 迭代第二张大 Hash 表 */
de = t1->table[v & m1];
while (de) {
next = de->next;
fn(privdata, de);
de = next;
}
v |= ~m1;
v = rev(v);
v++;
v = rev(v);
} while (v & (m0 ^ m1));
除了这种情况的迭代外,还有两种情况:
- 迭代过程中某几次遇到了字典扩容 rehash 操作;
- 迭代过程中某几次遇到了字典缩容的 rehash 操作。
在这里不详细介绍该部分内容,如果感兴趣,大家可以结合源码学习。
总之,这套算法能够满足不遗漏也不重复迭代数据,主要是巧妙地利用了扩容及缩容正好为整数倍增长或减少的原理,根据这个特征,很容易就能推导出同一个节点的数据扩容/缩容后再新的 Hash 表中的分布位置,从而避免了重复遍历或漏遍历。
总结
本文我们主要介绍了 Redis 字典这个数据结构。
首先,我们说了什么是字典、为什么 Redis 需要设计一个字典,然后讲了如何设计一个字典,包括 存储数据的数组、支持各种形式 key 的 hash 函数,以及 hash 冲突后的链表结构。
然后我们讲了在 Redis 中的字典结构,包括三个部分:字典 dict、哈希表 dictht、哈希表节点 dictEntry。我们需要对各个结构字段了解。
我们又讲了字典的基本操作方法,比如字典添加元素、删除元素等。其中比较重要的一个方法是渐进式 rehash, 我们需要掌握:
- rehash 执行流程是怎样的?
- 遍历 ht[0] 表,计算 hash 值,放入 ht[1] 表,更新 used、rehashidx 字段,执行一定数量停止 rehash 操作。
- 什么是渐进式 rehash?
- 将整个 rehash 操作分摊到每个增删改查操作上。
- 在进行 rehash 操作过程中,新添加到字典中的数据一律添加到 ht[1] 上,ht[0] 不进行任何添加操作。
- 除了增删改查的操作外,Redis 还会在空闲操作时,执行 rehash。
- 哈希表什么时候进行扩容?
- 正在 rehash 不会进行扩容
- 哈希表的大小为 0,扩容到初始大小 DICT_HT_INITIAL_SIZE
- 正常情况下 dict_can_resize 为 1,哈希表中键值对个数大于等于哈希表大小,就会扩容到键值对个数的两倍
- 有些情况下 dict_can_resize 为 0,redis 就会避免扩容,但是如果哈希表已经很满(负载因子大于 5),这时候会强制扩容的
- Redis 会主动 rehash 吗?
- 会的!
希望大家能够有所收获!
参考文档
- 《Redis 设计与实现》—— 黄健宏著
- 《Redis5 设计与源码分析》—— 陈雷著
