

背景介绍
我负责一个物联网平台的开发与运维工作,2020年12月18日的一天,恰逢周五,本来以为可以划划水就可以过愉快的周末了,一大早让我看下昨天的设备上报的数据情况,打开浏览器输入网址,无法正常登录,提示服务器内部错误!我心里一想不对呀,本人照看的系统已经稳定运行很长一段时间了,怎么会这样?都坐下,不要慌,我们慢慢的来处理。
处理过程
首先,通过我的FinalShell工具通过ssh登录服务器,一眼就看到了让我震惊的结果,我开始慌了。。。
有个java进程居然内存和CPU占用都这么高,然后我简单看了一下进程号,定位到是物联网平台的后台服务进程(由于该平台是采用docker部署的,因此需要进入docker容器内部进行查看)
docker exec -it cfe1916c608a /bin/bash
通过docker exec进入容器内部,首先还是使用我们比较常用top看下情况
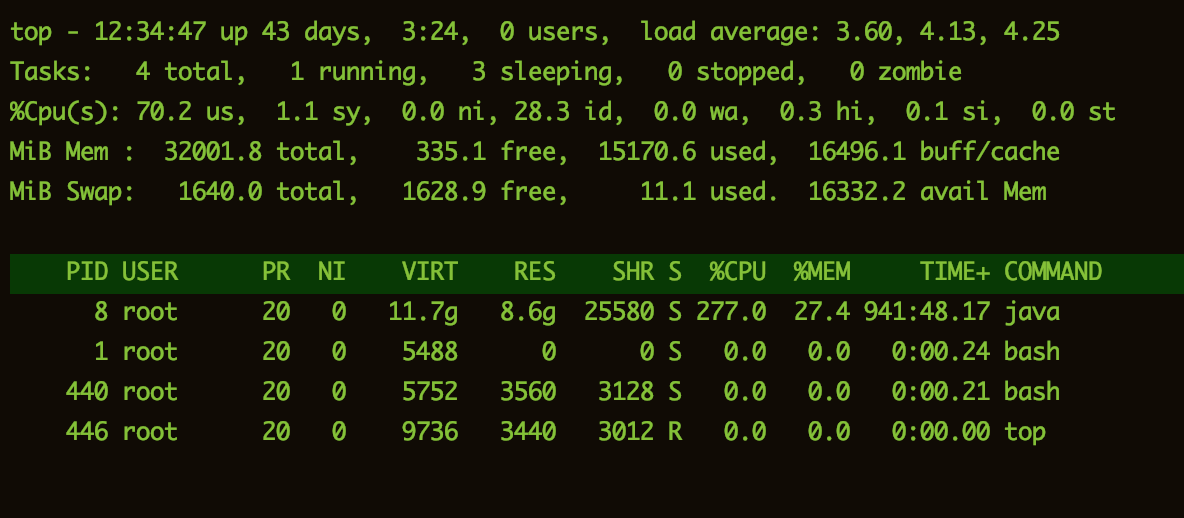
果然,与我们看到的现象一致,有个java进程RES占有高达8.6g,%CPU高达277.0,这时突然有些兴奋呀,我又可以躺坑了,事后会被作为经验文章分享出来,也就是你现在看到的样子😂。然后我们一步步来分析和处理。。。
接下来,我们主要从CPU升高的方向先入手分析。复制该进程的id号8,通过执行top -Hp查看当前进程的各个线程执行情况
top -Hp 8
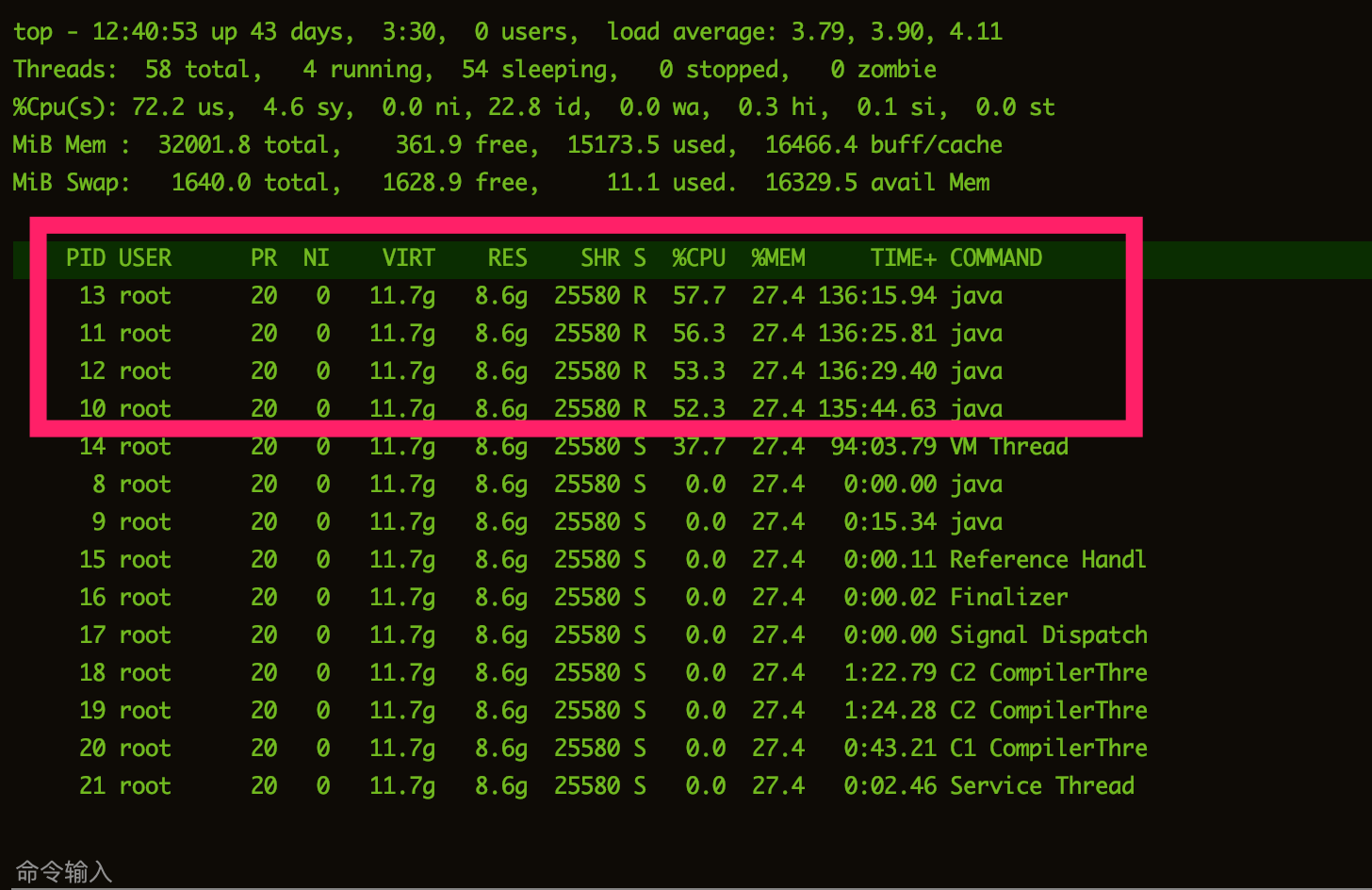
可以看到,前面几个线程的CPU占用都非常高,我们随机挑选一个PID为13的线程进行分析,需要注意的是,在jstack命令展示中,线程id都是转化成的十六进制形式,使用以下命令打印线程id的16进制结果

重点来了,执行jstack查看堆栈信息情况
jstack 8 |grep d
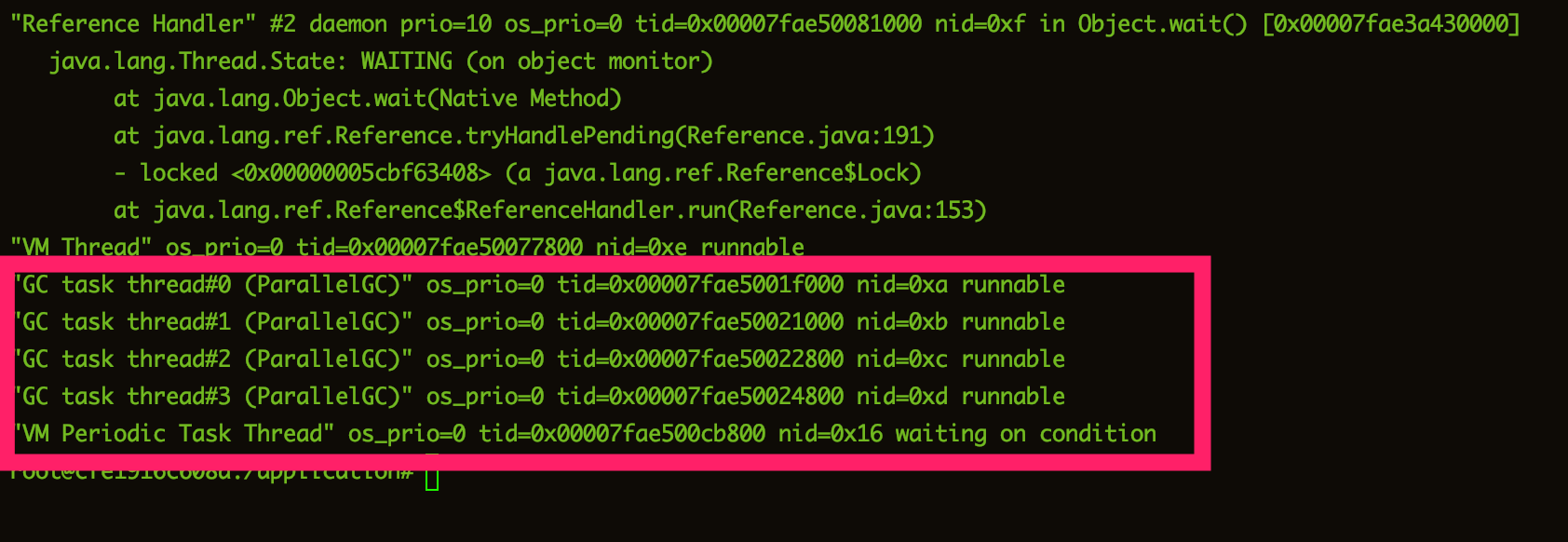
终于发现因为什么导致CPU升高了,可以看到a,b,c,d都是代表GC线程(PS:上图中的10~13这几个都是GC线程),我们大概猜测应该就是因为GC进行频繁的垃圾回收,导致其他业务无法正常的工作。好的,我们还是通过jstat验证一下
jstat -gcutil 8 2000 10
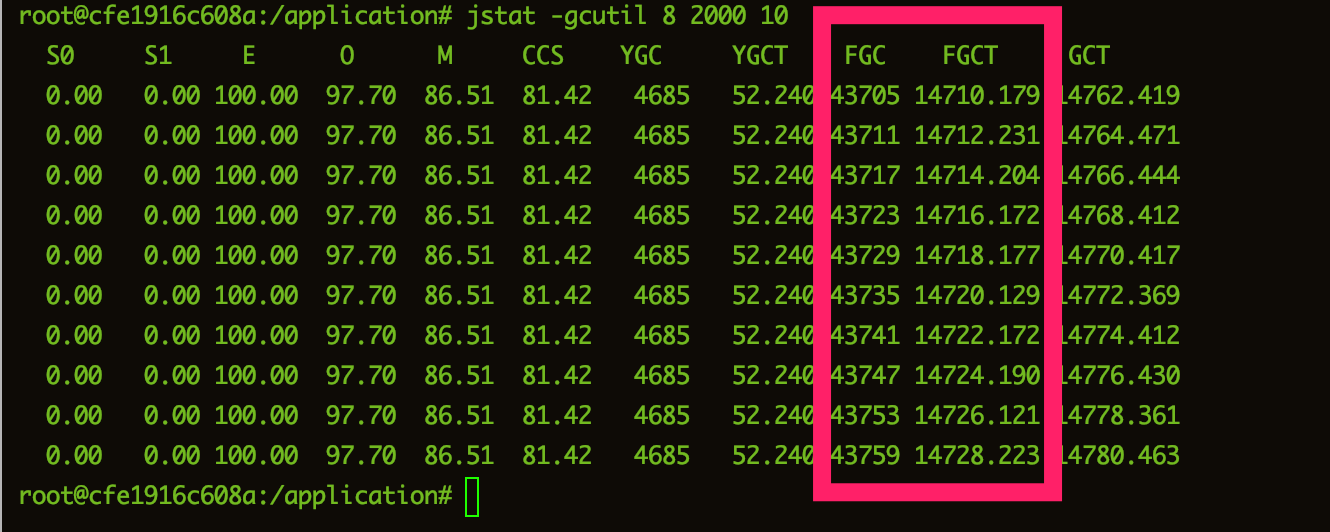
果然,这个FGC与FGCT显示的fullGC的次数和时间是不是让你头皮发麻 😫。然后,给大家一个小技巧,我们先通过jmap -histo命令先大致查看下堆内存的对象数量和大小情况
jmap -histo:live 8 | more
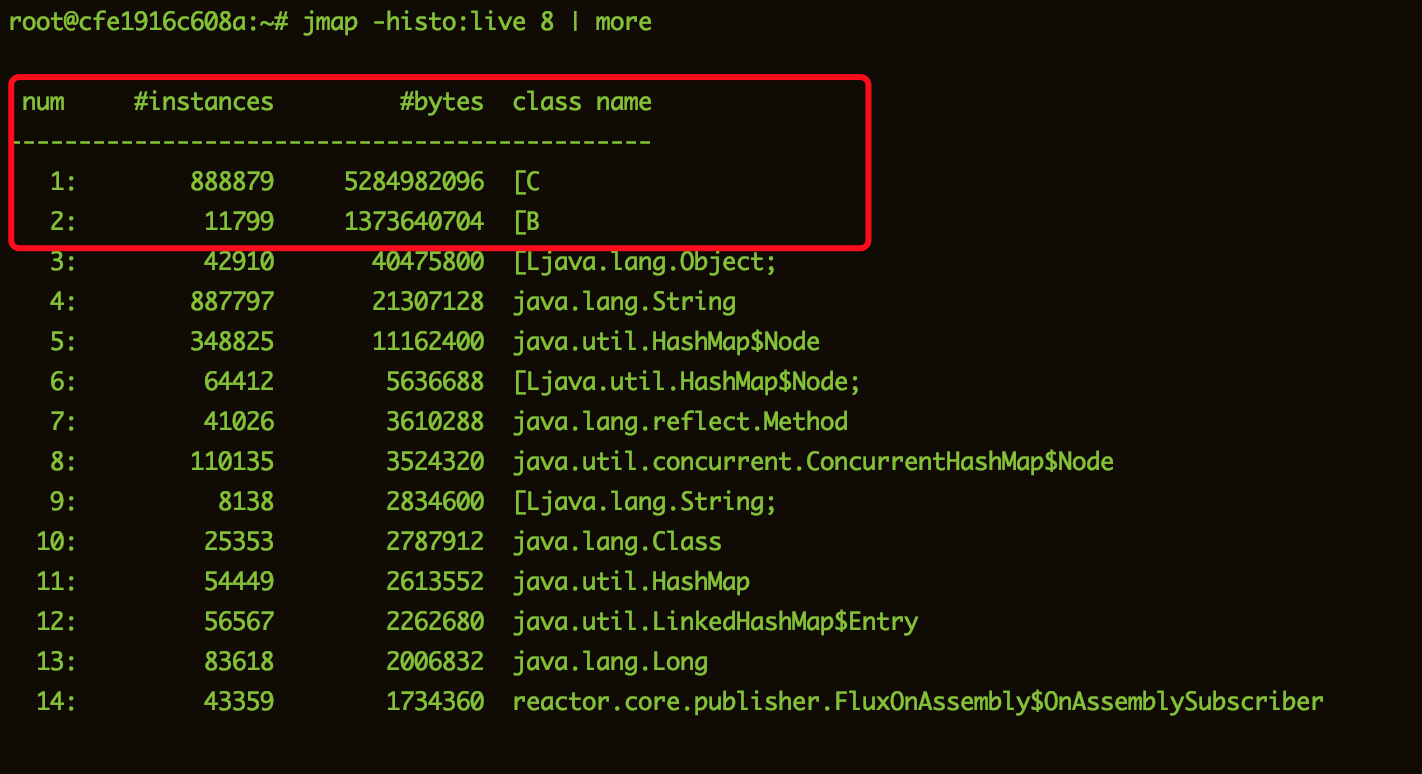
从分析中我们可以看到【B与【C占有都非常高,这是什么玩意?其实这个Byte和Char数组,大胆猜测可能是有大量的String字符串。。。
class name是对象类型,说明如下:
- B byte
- C char
- D double
- F float
- I int
- J long
- Z boolean
- [ 数组,如[I表示int[]
- [L+类名 其他对象
我们还是来好好分析下,到底是什么原因导致的GC经过这么努力在释放堆内存还是释放不出来,帮帮JVM虚拟机诊断下病因,这个时候其实大家应该已经知道我们应该看下堆内存里面到底是什么
首先,我们通过jmap -dump导出现在JVM的堆内存日志情况
jmap -dump:format=b,file=dump.dat 8

然后,从服务器下载dump.dat文件到本机,通过Eclipse Memory Analyzer工具对其进行分析查看
内存使用整体情况
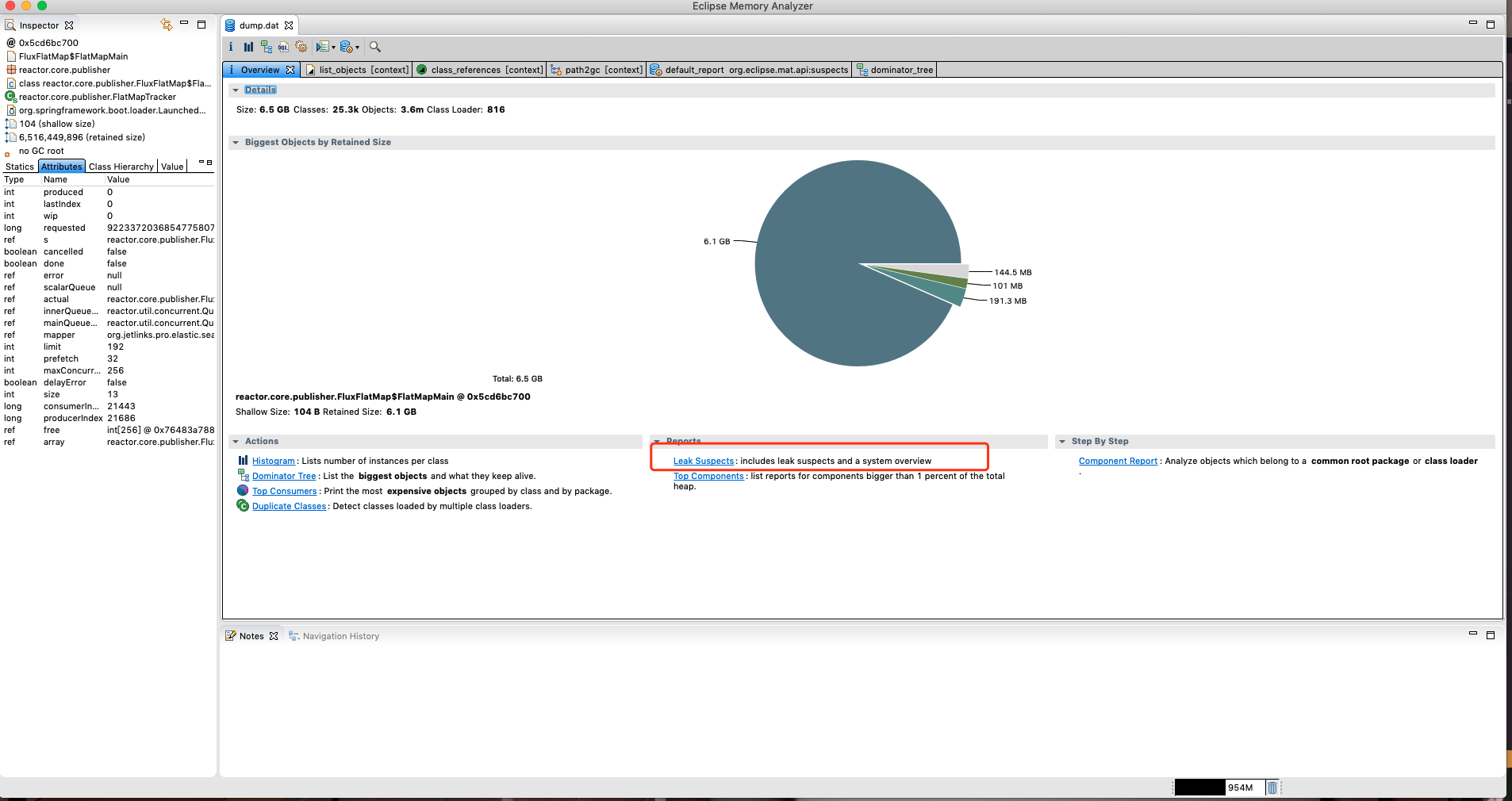
直接点击下方Reports→Leak Suspects链接来生成报告,查看导致内存泄露的罪魁祸首
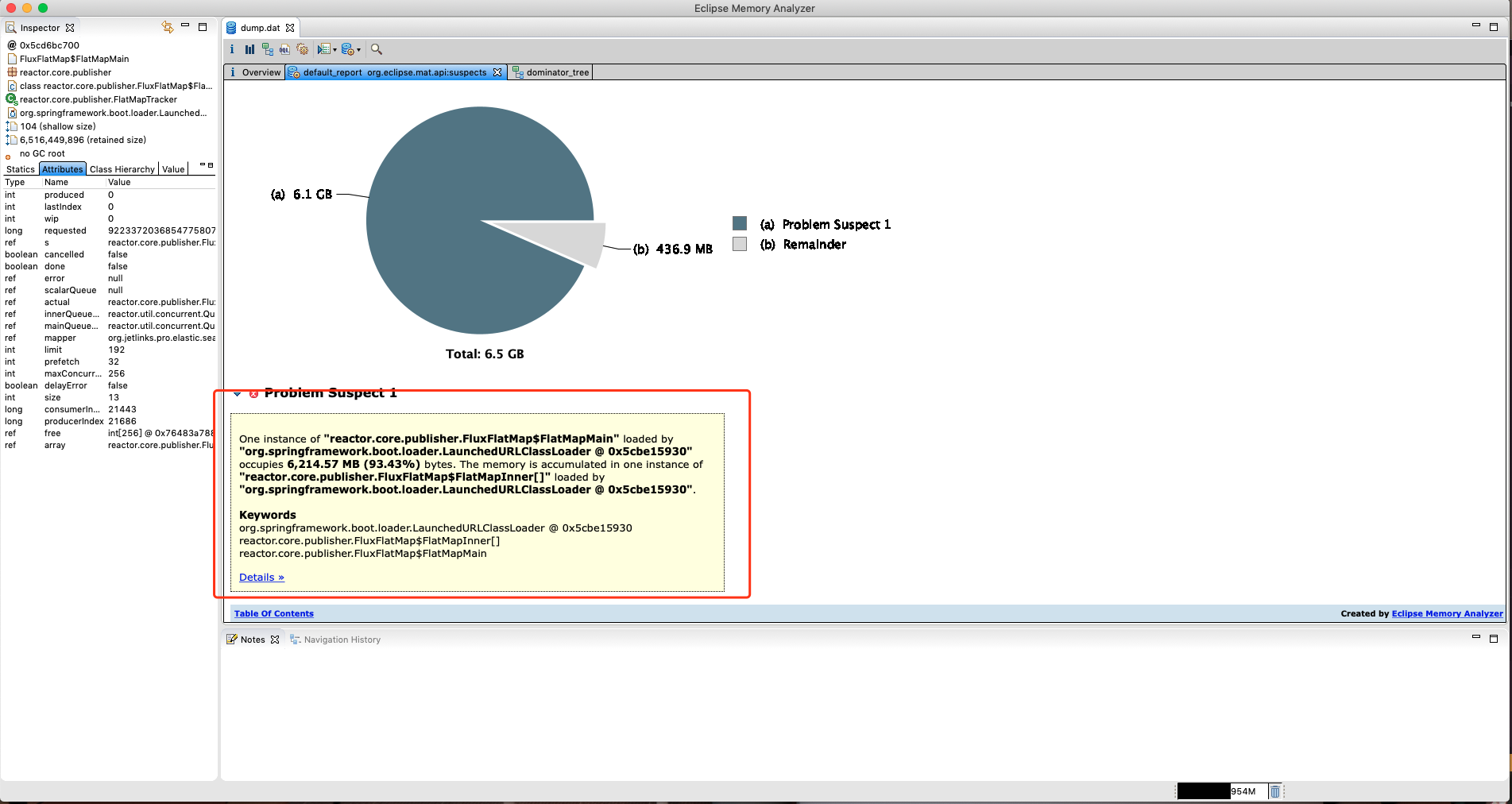
从图中可以看出一个可疑对象消耗了近93.43%的内存。接着往下看,点击Details查看详细情况
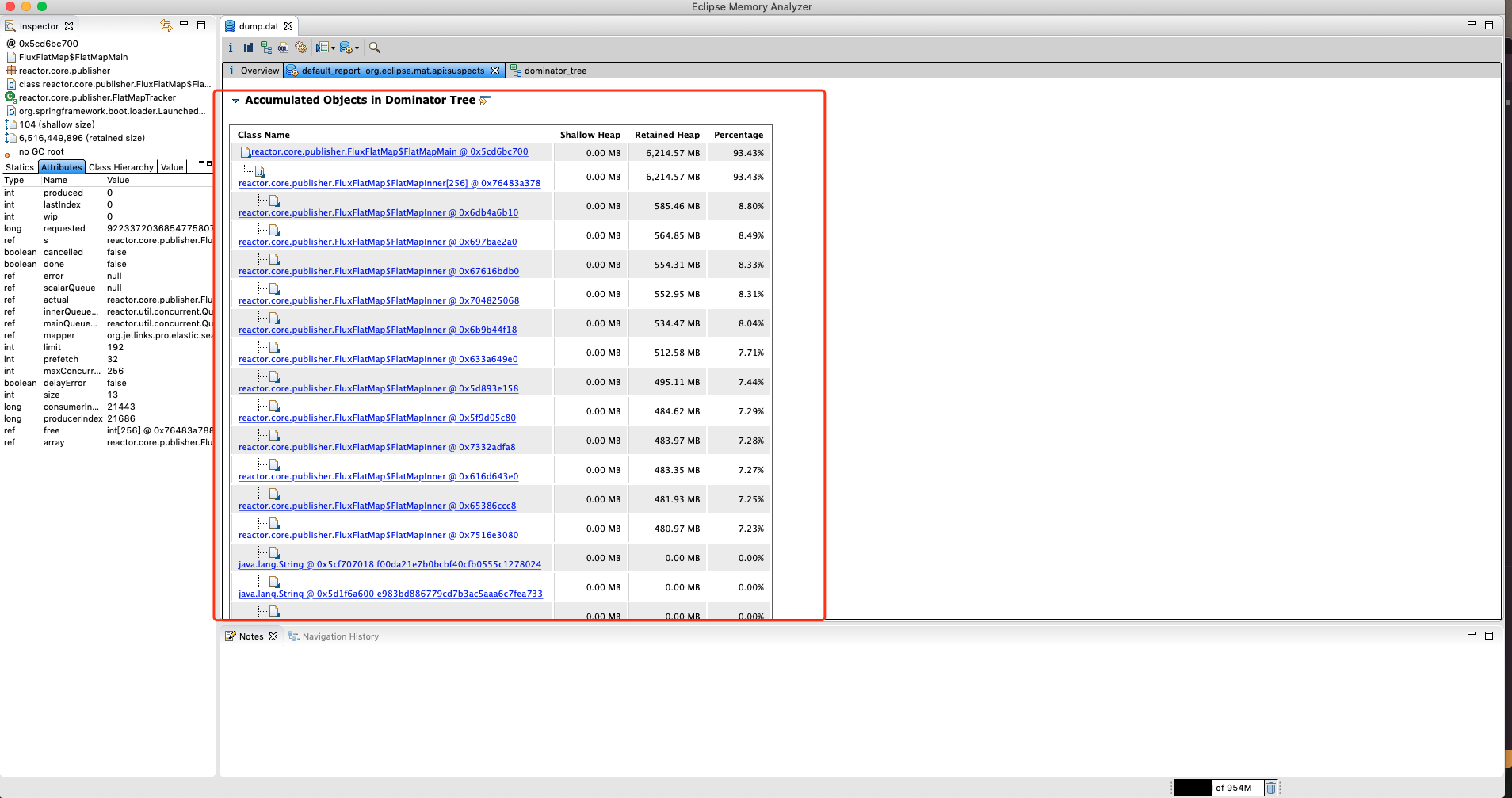
备注:
Shallow Heap 为对象自身占用的内存大小,不包括它引用的对象。
Retained Heap 为当前对象大小 + 当前对象可直接或间接引用到的对象的大小总和
点击dominator_tree查看entries heap对象引用关系tree进行分析
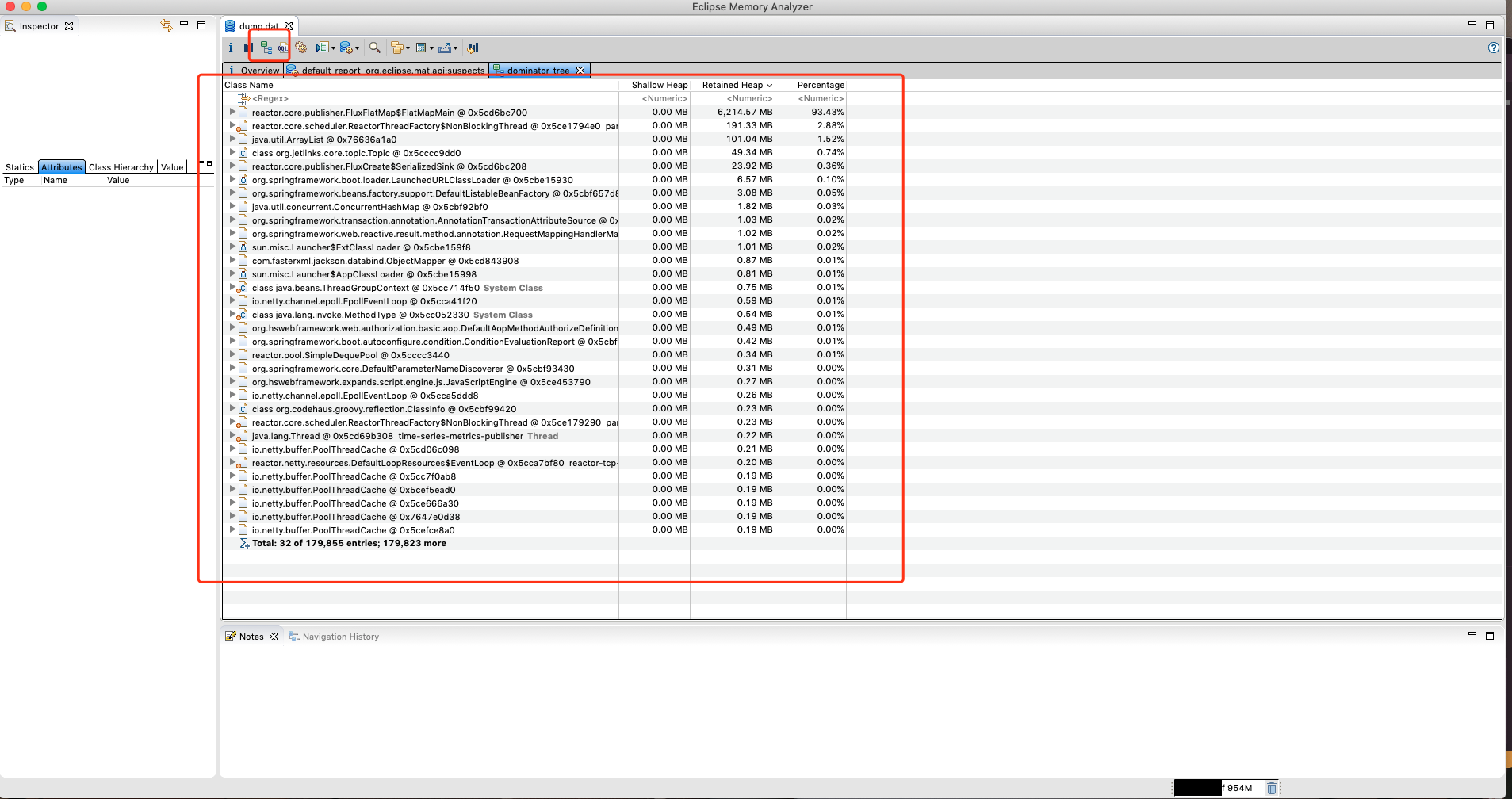
最终通过点击entries引用tree层层查看对象的引用情况,查看熟悉的东西,定位到好像与device_log_mtu_2020-12这个地方有关系
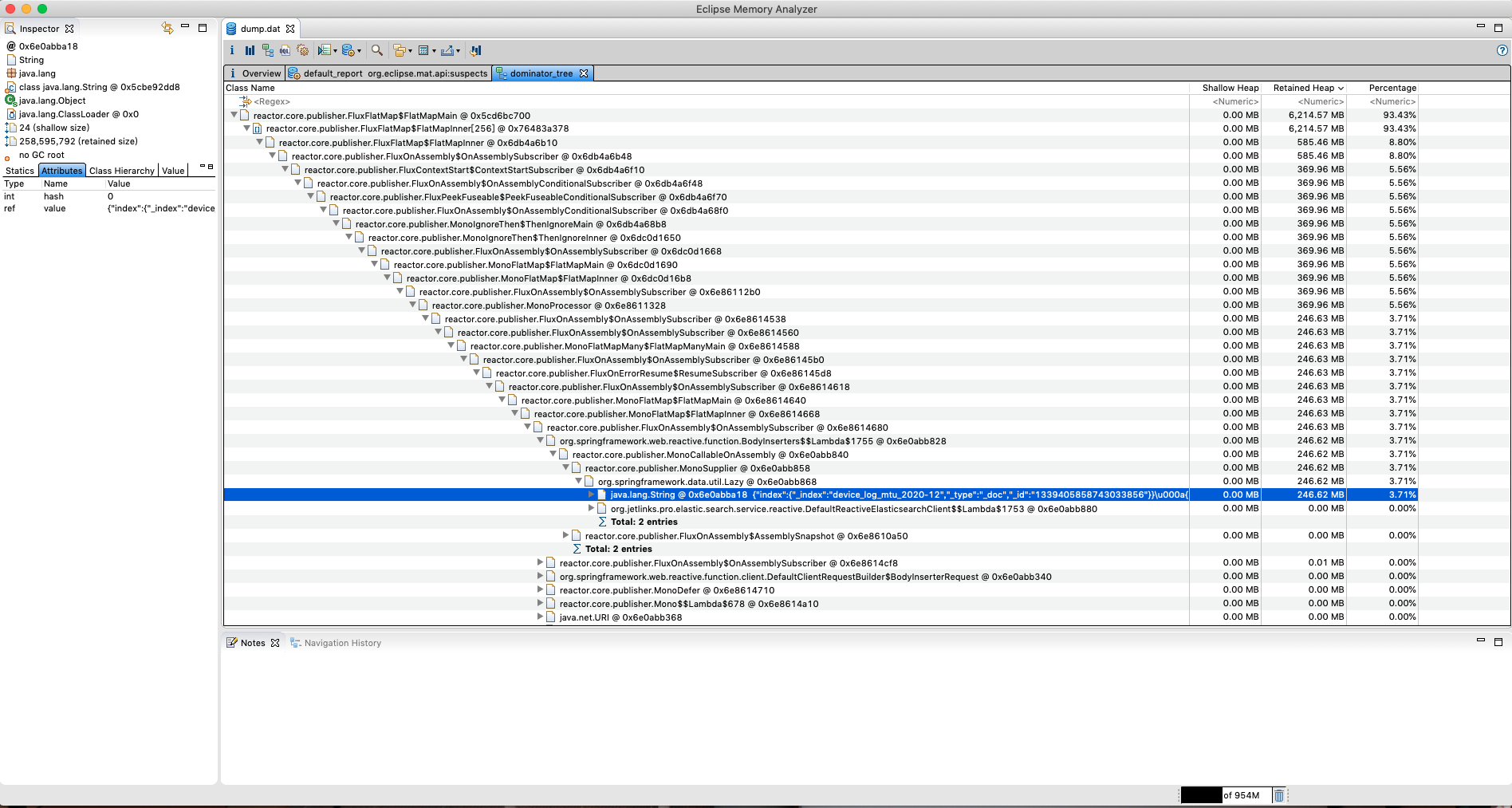
其实我们已经大概定位到问题出现位置了,接下来其实就要结合业务系统情况来追查业务情况与分析系统代码,最终定位到问题的原因:
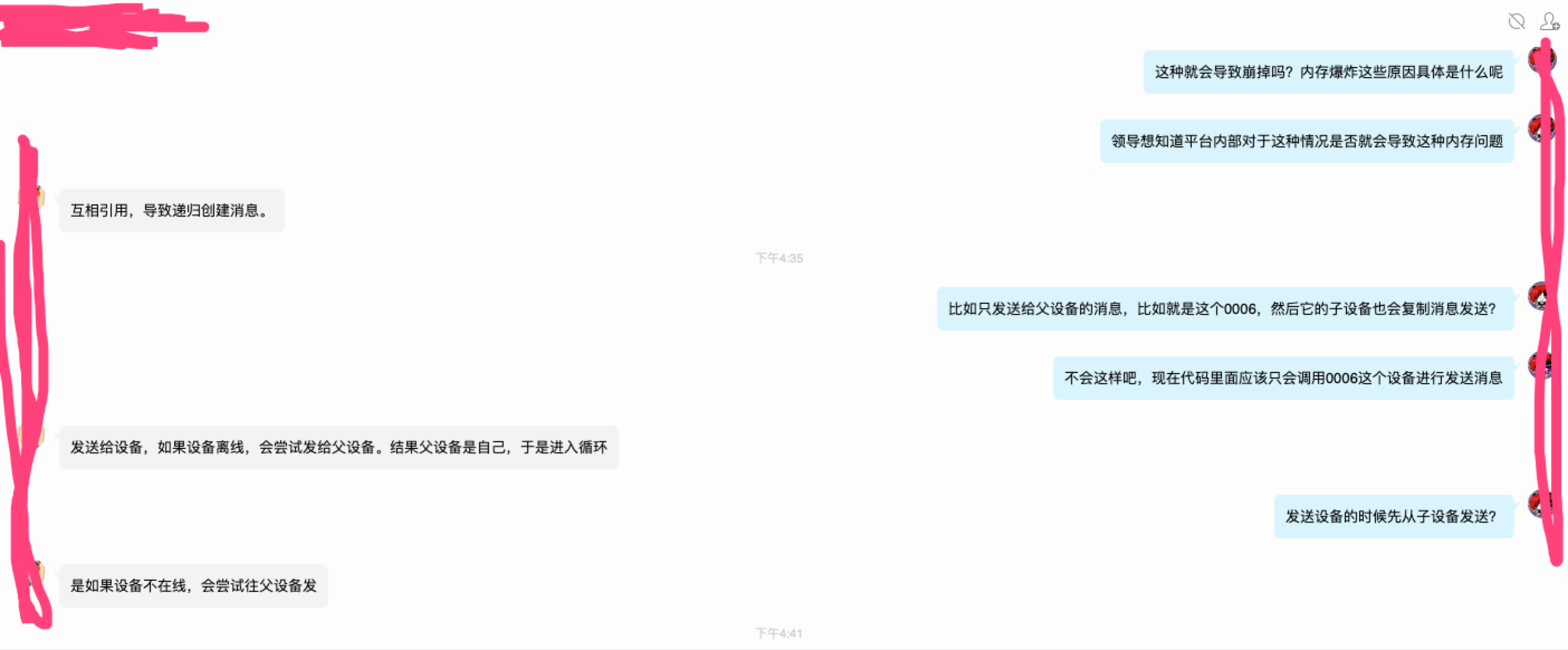
以下截图是我与系统的技术开发人员的交流,最终大概定位到问题的原因:因为代码的逻辑bug导致出现死循环
总结
先通过top命令查看CPU与内存情况,查看是什么进程的CPU和内存飙高,如果是CPU比较高,则可以通过top -Hp 命令查看当前进程的各个线程运行情况,找出CPU过高的线程以后,将其线程id转换为十六进制的形式后,然后通过jstack日志查看改线程的工作状态和调用栈情况,这里有两种情况:
- 如果是正常的用户线程,则通过该线程的堆栈信息查看其具体在哪出代码运行比较消耗CPU;
- 如果该线程是
VM Thread,则通过jstat -gcutil <pid> <period> <times>命令监控当前系统的GC状况,然后通过jmap dump:format=b,file=<filepath> <pid>导出系统当前的内存数据。导出之后将内存情况放到eclipse的mat工具中进行分析即可得出内存中主要是什么对象比较消耗内存,进而可以处理相关代码
如果企业内部本身没有相关监控与运维工具,那我们可以使用JDK本身提供了一些监控分析工具(jps、jstack、jmap、jhat、jstat、hprof等),通过灵活运用这些工具几乎能够定位Java项目80%的性能问题。最后在这里推荐一个Alibaba开源的Java诊断工具Arthas可以帮助你解决:
- 这个类从哪个 jar 包加载的?为什么会报各种类相关的 Exception?
- 我改的代码为什么没有执行到?难道是我没 commit?分支搞错了?
- 遇到问题无法在线上 debug,难道只能通过加日志再重新发布吗?
- 线上遇到某个用户的数据处理有问题,但线上同样无法 debug,线下无法重现!
- 是否有一个全局视角来查看系统的运行状况?
- 有什么办法可以监控到JVM的实时运行状态?
- 怎么快速定位应用的热点,生成火焰图?
