

- 原文地址:Damn Cool Algorithms: Log structured storage
- 原文作者:Nick Johnson
- 译文出自:掘金翻译计划
- 本文永久链接:github.com/xitu/gold-m…
- 译者:jackwener
- 校对者:ousheobin,chzh9311
酷毙了的算法:日志结构存储
通常来说,当你在设计一个文件系统或数据库这样的存储系统时,你会非常关注这个问题:如何在磁盘上存储数据。你必须注意为要存储的对象和索引数据分配空间;你也必须注意当您要扩展现有对象时(譬如追加到文件中)会发生什么,你还必须考虑旧对象被删除,新对象被存入时带来的存储碎片化问题。所有的这些问题都带来了很多复杂性,而且解决方案往往是有缺陷的或者低效的。
日志结构化存储是一种能够解决这些问题的技术。它起源于 1980 年代的“日志结构文件系统”,但最近它被越来越多地用作数据库引擎中的结构化存储。在其原来应用的文件系统应用中,它存在一些明显的缺点导致无法广泛应用,但是正如我们将看到的那样,这些问题对于数据库引擎而言并不那么严重,同时日志结构化存储还能为数据库引擎带来更多除更容易进行存储管理以外的优势。
顾名思义,日志结构化存储系统的基本组织是日志,即仅附加的数据项序列。每当您有新数据要写入时,您只需将其添加到日志的末尾,而不需要在磁盘上找到它的位置。通过相同的方式处理元数据可完成数据索引,即把元数据的更新也追加到日志中。这看起来效率低下,但基于磁盘的索引结构(如 B 树)通常应用十分广泛,因此每次写入时需要更新的索引节点数量通常非常少。让我们看一个简单的例子。我们将从一个仅包含单个数据项和一个引用该数据项的索引节点的日志开始:
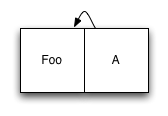
到现在为止还不错。现在,假设我们要添加第二个元素。我们将新元素添加到日志末尾,然后更新索引条目,并将更新后的版本也添加到日志中:
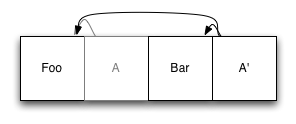
原有的索引项(A)仍在日志文件中,但不再生效:它已被新项 A' 替换,A' 引用 Foo 的原始未修改副本,以及新项 Bar。当有东西想读取文件系统时,它会找到索引的根节点,并像在任何其他使用基于磁盘的索引的系统中一样使用它。
寻找索引的根源值得一提。简单的方法是查看日志中的最后一个块,因为我们最后编写的总是索引的根。但是,这并不理想,因为在您尝试读取索引时,另一个进程可能正在向日志追加数据。我们可以通过在日志文件的开头使用一个包含指向当前根节点的指针的块来避免这种情况。每当更新日志时,我们重写第一个条目以确保它指向新的根节点。为了简洁起见,我们没有在图表中显示这一点。
接下来,让我们检查一下更新元素时会发生什么。假设我们修改 Foo:
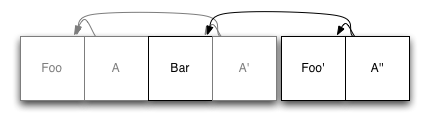
我们开始写一个全新的 Foo 副本到日志的末尾。然后,我们再次更新索引节点(在本例中只有 A'),并将它们写入日志的末尾。同样,Foo 的旧副本仍然保留在日志中;它只是不再被更新的索引引用。
你可能已经意识到这个系统是不可持续的。总有一天,我们的存储空间会用完,所有这些旧数据会占满空间。在文件系统中,这是通过将磁盘视为环形缓冲区并覆盖旧的日志数据来处理的。当这种情况发生时,仍然有效的数据只会再次被追加到日志中,就好像它是新写入的一样,这就释放了旧副本以进行覆盖。
在常规文件系统中,我前面提到的一个缺点就是在这里暴露出来的。随着磁盘越来越满,文件系统需要花费越来越多的时间进行垃圾收集,并将数据写回日志的头部。当您达到 80% 的容量时,文件系统实际上已经停止工作了。
但是,如果您将日志结构存储用于数据库引擎,这不是问题!我们在常规文件系统上实现了这一点,因此我们可以利用它来简化我们的生活。如果我们将数据库分成多个固定长度的块,那么当我们需要回收一些空间时,我们可以选择一个块,重写任何仍然有效(active)的数据,然后删除该块。上一个例子中的第一个片段开始显得有点稀疏,所以让我们这样做:
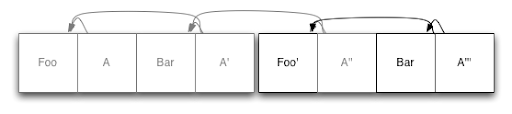
我们在这里所做的只是获取 'Bar' 的现有副本并将其写入日志的末尾,接着是更新的索引节点,如上所述。现在我们已经做完了,第一个日志段已经完全空了,并且可以删除了。
与文件系统方法相比,这种方法有几个优点。首先,我们不局限于首先删除最旧的段:如果中间段几乎为空,我们可以选择对其进行垃圾回收。对于那种一些数据保留时间较长,而另一些数据需要重复读写的数据库,这一点特别有用:我们不想浪费太多时间重写相同的未修改数据。对于何时进行垃圾收集,我们也有一些更大的灵活性:我们通常可以等到一个段基本上是过时的,然后再对其进行垃圾收集,从而进一步减少我们必须做的额外工作。
不过,这种方法对数据库的优势不止于此。为了保持事务的一致性,数据库通常使用“预写日志”(Write Ahead Log)或 WAL。当数据库希望将事务持久化到磁盘时,它首先将所有更改写入 WAL,将这些更改刷新到磁盘,然后更新实际的数据库文件。这使得它可以通过重放WAL中记录的更改来从崩溃中恢复。但是,如果使用日志结构存储,则预写日志就是数据库文件,因此只需要写入一次数据。在恢复情况下,我们只需打开数据库,从最后一个记录的索引头开始,线性地向前搜索,并在执行过程中从数据中重建任何丢失的索引更新。
利用我们上面的恢复方案,我们也可以进一步优化我们的写操作。与每次写入时都写入更新的索引节点不同,我们可以将它们缓存在内存中,并且只定期将它们写入磁盘。只要我们提供某种方法来区分已完成事务和未完成事务,我们的恢复机制将会负责在崩溃时重建内容
使用这种方法,备份也更容易:我们可以通过在数据库完成后将每个新的日志段复制到备份介质来连续、增量地备份数据库。要恢复,我们只需再次运行恢复过程。
这个系统的最后一个主要优点是数据库中的并发和事务语义。为了提供事务一致性,大多数数据库使用复杂的锁系统来控制哪些进程可以在什么时候更新数据。根据所需的一致性级别,这可能涉及到读取者获取锁以确保在读取数据时数据不会被修改,以及写入者需要锁定数据以进行写入,并且如果有大量的并发读取,即使写入速率相对较低,也可能导致性能显著下降。
我们可以用多版本并发控制(Multiversion Concurrency Control,MVCC)来解决这个问题。每当一个节点想从数据库中读取数据时,它都会查找当前的根索引节点,并将该节点用于其事务的其余部分。由于现有数据在基于日志的存储系统中从未修改过,因此该进程现在有了获取句柄时的数据库快照:并发事务所做的任何操作都不会影响其对数据库的视图。就这样,我们实现了无锁读取!
在回写数据时,我们可以利用乐观并发(Optimistic concurrency)。如上所述,在典型的读取-修改-写入周期中,我们首先执行读取操作。然后,为了写入更改,我们对数据库进行了写入锁定,并确认在第一阶段中读取的所有数据均未被修改。我们可以通过查看索引并检查我们关注的数据的地址是否与上次查看的地址相同来快速完成此操作。如果相同,则不会发生写操作,我们可以自己进行修改。如果不同,则发生冲突的事务,我们只需回滚并从读取阶段重新开始。
当我高度赞扬它时,你可能会想知道什么系统已经使用了这个算法。我所知的却很少,但以下是几个值得注意的:
- 尽管最初的 Berkeley DB 使用了相当标准的体系结构,但Java端口 BDB-JE 使用了我们刚才描述的所有组件。
- CouchDB 使用了刚才描述的系统,但是它没有将日志分成段并进行垃圾收集,而是在累积了足够多的过时数据时重写整个数据库。
- PostgreSQL 使用 MVCC,它的 WAL(write ahead logs)是结构化的,以便允许我们描述的增量备份方法。
- App Engine 数据存储基于 Bigtable,Bigtable 采用了不同的磁盘存储方法,但是事务层使用乐观并发。
如果你知道其他数据库系统使用了本文详细描述的想法,请在评论中告诉我们!
如果发现译文存在错误或其他需要改进的地方,欢迎到 掘金翻译计划 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 本文永久链接 即为本文在 GitHub 上的 MarkDown 链接。
掘金翻译计划 是一个翻译优质互联网技术文章的社区,文章来源为 掘金 上的英文分享文章。内容覆盖 Android、iOS、前端、后端、区块链、产品、设计、人工智能等领域,想要查看更多优质译文请持续关注 掘金翻译计划、官方微博、知乎专栏。
