

八、 APM 小结
-
通常来说各个端的监控能力是不太一致的,技术实现细节也不统一。所以在技术方案评审的时候需要将监控能力对齐统一。每个能力在各个端的数据字段必须对齐(字段个数、名称、数据类型和精度),因为 APM 本身是一个闭环,监控了之后需符号化解析、数据整理,进行产品化开发、最后需要监控大盘展示等
-
一些 crash 或者 ANR 等根据等级需要邮件、短信、企业内容通信工具告知干系人,之后快速发布版本、hot fix 等。
-
监控的各个能力需要做成可配置,灵活开启关闭。
-
监控数据需要做内存到文件的写入处理,需要注意策略。监控数据需要存储数据库,数据库大小、设计规则等。存入数据库后如何上报,上报机制等会在另一篇文章讲:打造一个通用、可配置的数据上报 SDK
-
尽量在技术评审后,将各端的技术实现写进文档中,同步给相关人员。比如 ANR 的实现
/* android 端 根据设备分级,一般超过 300ms 视为一次卡顿 hook 系统 loop,在消息处理前后插桩,用以计算每条消息的时长 开启另外线程 dump 堆栈,处理结束后关闭 */ new ExceptionProcessor().init(this, new Runnable() { @Override public void run() { //监测卡顿 try { ProxyPrinter proxyPrinter = new ProxyPrinter(PerformanceMonitor.this); Looper.getMainLooper().setMessageLogging(proxyPrinter); mWeakPrinter = new WeakReference<ProxyPrinter>(proxyPrinter); } catch (FileNotFoundException e) { } } }) /* iOS 端 子线程通过 ping 主线程来确认主线程当前是否卡顿。 卡顿阈值设置为 300ms,超过阈值时认为卡顿。 卡顿时获取主线程的堆栈,并存储上传。 */ - (void) main() { while (self.cancle == NO) { self.isMainThreadBlocked = YES; dispatch_async(dispatch_get_main_queue(), ^{ self.isMainThreadBlocked = YES; [self.semaphore singal]; }); [Thread sleep:300]; if (self.isMainThreadBlocked) { [self handleMainThreadBlock]; } [self.semaphore wait]; } } -
整个 APM 的架构图如下
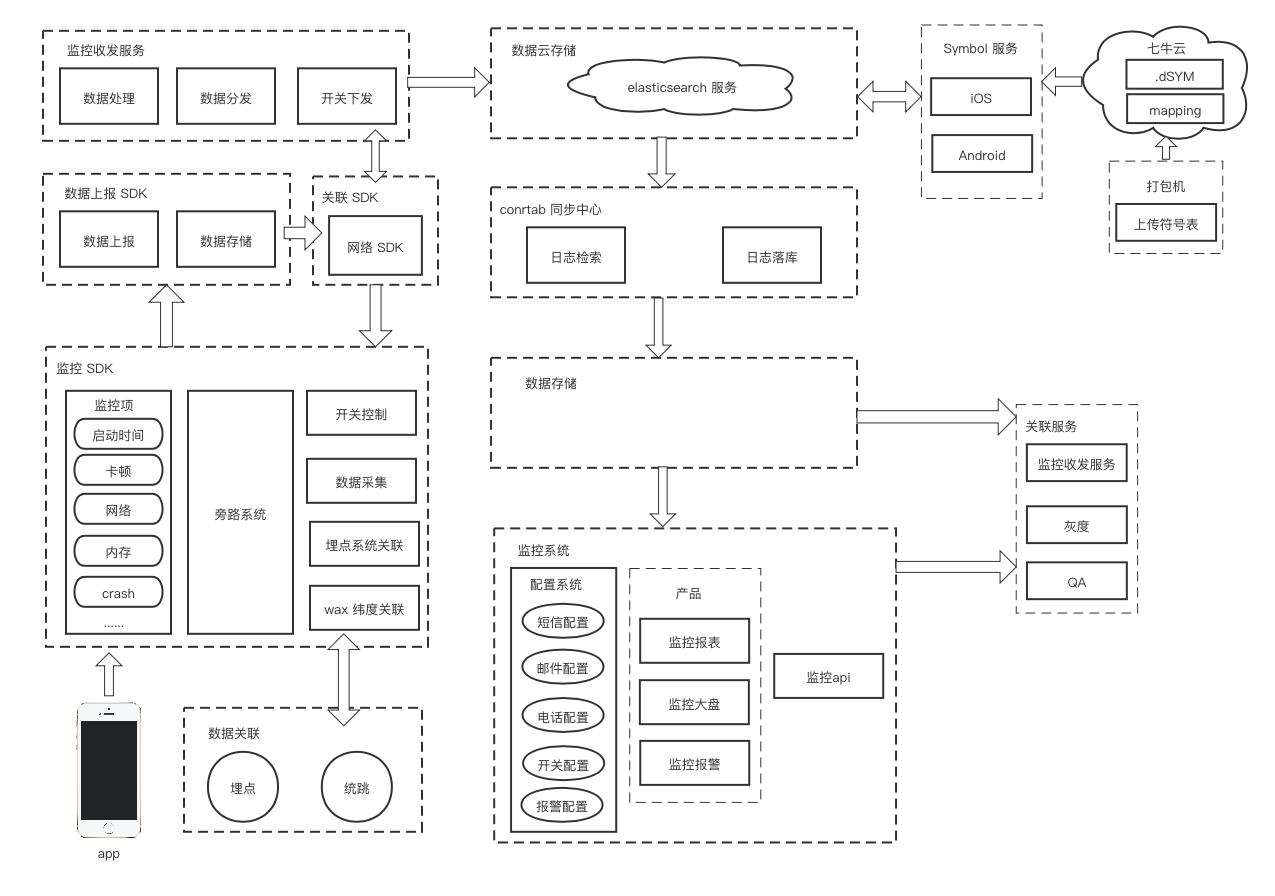
说明:
- 埋点 SDK,通过 sessionId 来关联日志数据
-
APM 技术方案本身是随着技术手段、分析需求不断调整升级的。上图的几个结构示意图是早期几个版本的,目前使用的是在此基础上进行了升级和结构调整,提几个关键词:Hermes、Flink SQL、InfluxDB。
文章内容过长,拆分为多个篇章,请自行点击查看,如果想整体连贯查看,请访问这里
