

1 起因
考拉有很多node工程,其中客户端代码client/和基于egg的服务端server/混合在一起。由于历史遗留问题,大部分client下都会有多套构建脚本。比如我负责的工程就包含:
1. client/pc(webpack2)
2. client/wap(webpack2)
3. client/wap-vue(webpack4)
4. ssrClient(vue-cli)
竟然有四套构建 (キ`゚Д゚´) 再加上对应的npm install,以及服务端的server/也需要install,最终导致构建时间会很长
为了解决这个问题,提升构建效率,我做了@kaola/buildflow,通过多线程并行构建,按需构建(缓存npm install和npm run build的构建结果),大幅提升了构建速度
本文主要介绍了buildflow的解决方案、实现思路,以及一些有趣的技术细节
2 原理和实现
↓流程示意图↓
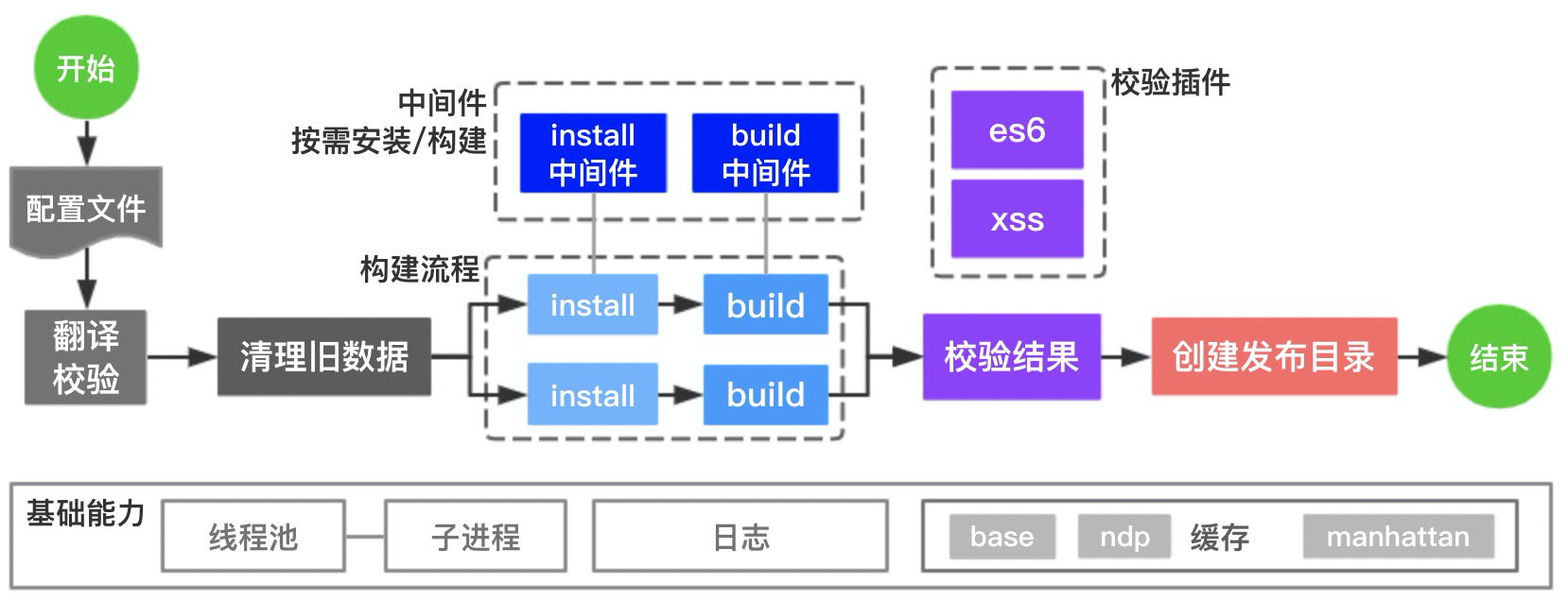
2.1 多线程执行任务
将构建的各种命令合理分配到不同线程中,将总体打包效率最大化
2.1.1 设计易于维护和理解的api
创建一个可执行任务
flow.exec('install wap packages', {
cmd: 'npm i --prefix=./client/wap',
cwd: './'
})
如何串行执行
flow.exec('install wap packages', { cmd: 'npm i --prefix=./client/wap' })
.exec('build wap packages', { cmd: 'npm run build --prefix=./client/wap' })
如何多线程并行执行
flow.fork([
flow.exec(...), // 任务1
flow.exec(...), // 任务2
])
并行任务之间可以进行嵌套
flow.fork([
flow.fork([
flow.exec(...), // 任务1
flow.exec(...), // 任务2
])
.exec(...), // 任务3,
flow.exec(...), // 任务4
.exec(...), // 任务5
])
如上伪代码执行顺序,就是1/2/4同时开始执行,当1/2执行结束后3再开始执行,当4执行结束后5开始执行
2.1.2 最大线程数
在运行时,如果不限制线程数,可能会并发执行大量任务,导致机器卡顿,反而会拖累整体构建速度。一般在构建机上执行还好(几十个cpu内核起步),但在本地执行时容易出这种问题
因此,使用线程池来控制最大线程数,数量由cpu虚拟内核数来决定更加合理
// CPU逻辑内核,决定最大并发任务数量
const cpus = require('os').cpus();
const cpuNumber = cpus.length;
一个例子,部分代码如下
完整版见:

const CpuPool = require("./cpu-pool");
const sleep = require("./sleep");
const pool = new CpuPool();
// 一个任务
async function exec() {
await pool.occupy(); // 占用1个cpu逻辑内核
await sleep(1000 * 10 * Math.random()); // 休眠0-10s,模拟执行效果
await pool.release(); // 释放占用
}
let count = 0,
max = 20;
while (count <= max) {
exec();
count++;
}
/*
假设 cpu 虚拟内核为 12
并行执行20个任务
并行执行12个任务(执行时间0-10s),剩余8个任务队列中等待
先执行完毕的任务会释放cpu,队列的等待的任务进入执行
*/
2.1.3 执行
执行使用node的child_process模块
const spawn = require('child_process').spawn;
function run(first, params, options = {}) {
return new Promise((resolve) => {
const p = spawn(first, params, options);
let stdout = '', stderr = '', output = '';
p.stdout.on('data', (data) => {
const str = data.toString();
stdout += str;
output += str;
});
p.stderr.on('data', (data) => {
const str = data.toString();
stderr += str;
output += str;
});
p.on('close', (code) => {
resolve({ stdout, stderr, output, code });
});
});
}
// 执行
run('npm', ['run', 'build'], { cwd: './client/wap' })
.then({ stdout } => stdout);
2.1.3 日志
使用debug包对日志进行分级,如:error、warn、info、debug
通过设置process.env.DEBUG参数,可以选择输出的日志类型
2.1.4 某次构建耗时太久
在webpack的一次构建中,如果耗时太长,可以考虑拆分构建的页面:
- 除了各种优化措施之外,webpack还推荐使用 parallel-webpack 和 cache-loader 来对单次构建使用多线程能力,以及在不同线程中共享缓存(我还没用过┭┮﹏┭┮)
- 也可以只构建变更的页面,
buildflow的缓存能力可以将构建结果与上一次构建的结果合并
2.2 缓存构建结果
测试环境可能会频繁构建。如果只修改了服务端代码,却仍然要整体构建,显然是比较浪费的
因此,思路就是将前一次构建的结果进行缓存,并在下一次构建时,只对变动的部分执行构建命令,最后将两次的构建结果合并
2.2.1 如何判断哪些变动,并执行对应的日志
将上一次构建的 commitId 与 HEAD 做 git diff 操作。我使用了 simple-git
const { root, joinRoot } = require('../lib/path');
const git = require('simple-git/promise')(rootPath);
async function getChangedFiles(lastCommitId, currCommitId = 'HEAD') { // 获取指定commit id之间变更的文件,默认对比HEAD
assert.ok(typeof lastCommitId === 'string');
const changeFiles = (await git.diffSummary([`${lastCommitId}...${currCommitId}`]))
.files.map(f => f.file)
.filter(p => p)
.map(filepath => joinRoot(filepath));
return changeFiles;
}
确定修改的文件后,将文件路径与npm run build的路径进行比对,如果文件在该路径下,则执行对应的构建操作。
2.2.2 如何缓存
缓存放在什么地方?
最早在网易的时候,跟运维商量之后,决定将缓存文件放在构建机的特定目录,貌似会进行定期清理
而现在因为构建机有很多台,这种方案显然不再适用,改为上传到oss远程存储的方式存放缓存数据。
下载解压+压缩上传一个20M+的一个压缩包,大概总共需要10~15s,这个要算到使用缓存功能的时间成本中
另外需要考虑到:版本管理、定期清理、安全问题。
尤其是安全方面需要特别留意,oss bucket不能让无关的用户访问到,Bucket ACL需要设置为私有(上传,下载均需要AK鉴权)。
每次构建结束,将缓存的内容tar+gzip压缩后,上传到oss私有桶,oss中的路径包含:工程名、分支、时间,便于维护和定期清理,到下一次构建开始时,先尝试将缓存的构建结果拉倒本地进行解压
2.2.3 流
为了更快速的压缩&上传、下载&解压文件,需要用到stream流来辅助操作
比如下载&解压文件,你需要先下载,然后再解压。而如果使用流,就能做到一边下载,一边解压,效率提升了很多
我使用了 compressing 与 pump,再结合 oss node客户端 进行的流操作,文件被压缩为*.tgz格式
2.2.4 中间件
为了应用缓存能力,我使用了中间件的设计思路。上面提到 flow.exec 会生成一个安装或构件任务,那么中间件就会加载到这一任务中,在这个任务开始前和结束后执行。当有多个中间件同时生效时,使用koa洋葱模型嵌套执行
中间件的实现方式很简单,基本原理如下
sandbox:
// 第一个中间件
const mid1 = async (next, props = {}) => {
console.log(`mid1 before, name: ${props.name}`);
await next();
console.log(`mid1 after, name: ${props.name}`);
};
// 另一个中间件
const mid2 = async (next, props = {}) => {
console.log(`mid2 before, name: ${props.name}`);
await next();
console.log(`mid2 after, name: ${props.name}`);
};
// 任务函数
const exec = async (props = {}) => {
console.log(`run exec, name: ${props.name}`);
};
// 添加了中间件的任务函数
const execNew = async (props = {}) => {
const ms = [
mid1, // 将中间件放到数组的前两位,执行时会符合koa洋葱模型
mid2,
async(next, props = {}) => { // 封装后的任务函数
await exec(props);
},
];
const next = async() => {
const m = ms.shift(); // 每次执行next,都会从头部导出数组的一项
await m(next, { name });
};
await next(); // 开始执行
};
/*
执行结果:
> mid1 before, name: tian
> mid2 before, name: tian
> run exec, name: tian
> mid2 after, name: tian
> mid1 after, name: tian
*/
2.2.5 api如何设计
oss相关参数很好处理
flow
.cache({
// oss缓存参数
oss: {...}
})
});
中间件的定义,以及哪些exec任务需要加载中间件
方法一:全局中间件
// 全局应用中间件(具体节点也可以单独设置,会合并)
// - 只针对: flow.exec、flow.check
// - 写在开头,可以应用到全局
flow.use({
'git-change': { // 中间件名称
// 筛选需要应用中间件的节点,名字以 build 开头的任务
test: ({ name }) => /^\s*build\s*$/.test(name),
// 传入中间件的参数
option: ({ cwd = '' }) => {
return { watch: cwd }; // watch 目录的代码修改后,需要重新构建,否则使用缓存
}
}
});
方法二:针对某个任务使用中间件
flow.exec('build wap', {
cmd: 'npm run build --prefix=./client/wap',
use: [ 'git-change?watch=./client/wap' ] //
});
2.2.6 缓存install结果
npm i操作也会消耗一定的时间,使用缓存后也有一定提升空间
具体策略是将package.json与package-lock.json文件 md5 转换为字符串,并与对应的node_modules/一起缓存。
在新一次构建中,如果新计算的md5值未发生修改,则直接使用上一次安装的node_modules/
md5操作使用了crypto
2.3 其他功能
2.3.1 clean
删除文件/目录,一般用于在开始构建前,剔除不参与构建(缓存)的内容
flow.clean([ './compressed', './server/app/public'])
2.3.2 check
对打包结果进行校验,提前避免一部分问题,比如es6语法、xss风险(目前支持了art-template模板)等
flow // 构建结果检查
.check('check bundle file', {
es5check: { // 检查1 - 指定目录不应该包含es6的语法
path: require.resolve('@kaola/buildflow.check.es6'), // 外部导入
pattern: ['./server/app/public/**/*.js'], // 需要检查的列表
notCheckEval: false, // 是否检查eval语法中的代码
},
xss: {/* ... */} // 检查2 - 模板中是否存在xss风险
});
2.3.3 compress
输出构建结果到指定目录,使用 globby
compress
// 将哪些数据输出
.from({
cwd: './',
include: ['@(dist)', 'server/*'],
exclude: []
})
// 输出到的目录
.to('./compressed');
2.4 API解析
如何将易于阅读的api,解析为适合工程运行的数据结构?
假设用户输入的api如下
flow.node('total') // 仅用于打日志,用于分割和标记时间
.clean(['./server/app/public']) // 删除目录
.fork([ // 启用并发
flow.exec('install wap', { cwd: 'npm i --prefix=./client/wap' }) // 任务1
.exec('build wap', { cwd: 'npm run build --prefix=./client/wap' }), // 任务2(依赖任务1)
flow.exec('install server', { cwd: 'npm i --prefix=./server' }), // 任务3,与任务1并发执行
])
.check('check es6 bundle', { // 对构建结果进行校验
checkES6Bundle: {
path: require.resolve('@kaola/buildflow.check.es6'), // 引用外部模块
pattern: ['./server/app/public/**/*.js'], // 需要检查的文件
}
})
为了便于程序运行,api最终会被解析为一个数组如下:
[ { "id": 0, "name": "total", "type": "node", "parent": [] },
{
"id": 1, "name": "clean", "type": "clean", "parent": [0],
"dirs": ["./server/app/public"]
},
{
"id": 2, "name": "install wap", "type": "exec", "parent": [1],
"use": [],
"exec": { "cmd": "npm i", "options": { "cwd": "./client/wap" } }
},
{
"id": 3, "name": "build wap", "type": "exec", "parent": [2],
"use": [],
"exec": { "cmd": "npm run build", "options": { "cwd": "./client/wap" } }
},
{
"id": 4, "name": "install server", "type": "exec", "parent": [1],
"use": [],
"exec": { "cmd": "npm i", "options": { "cwd": "./server" } }
},
{
"id":5, "name":"check es6 bundle", "type":"check", "parent":[3, 4],
"rules":[
{
"path":"./node_modules/@kaola/buildflow.check.es6/src/index.js",
"pattern":["./server/app/public/**/*.js"],
"type":"es5check"
}
]
}
]
除了表示并发的flow之外,其余的API(node,clean,exec,check)都会被解析为数组中的一项,并且每一种类型都会有对应的处理函数(onNode,onClean,onExec,onCheck)负责执行
参数id,parent用来标记各个节点之间的关系,其中parent为数组,因为一个节点可能同时依赖多个节点,比如最后的check节点,它依赖于并行执行的2个任务(任务2、任务3)
真正执行的顺序是这样的,先取数组的第一个节点(id为0),执行第一个节点(onNode函数)完毕后,将执行完毕的节点的id放到一个数组中(如 dealIds 为 [0]),再检查有哪些节点的parent已经执行完毕(包含在dealIds中),此时得到id为1的节点clean,继续执行onClean,执行完毕后将对的id放到dealIds中(此时为[0, 1]),继续检查parent包含[0, 1]的节点,由此依次执行下去,直到全部节点执行完毕为止
3 总结
- 多线程并发构建,适用于一个工程中有多个与构建相关命令的场景
- 缓存功能,主要解决了修改很少一部分代码,却要全量构建的问题。但依赖于构建脚本本身,能够支持针对改动部分的代码单独进行构建
- 上文还分享了开发过程中的一些知识点和设计思路,希望对大家有一定启发意义
