

clickhouse中的表可以分为分布式表和本地表
- 分布式表
逻辑存在的表,自身不存储数据,可以理解为数据库中的视图, 一般建议使用分布式表做查询操作,分布式表引擎会将我们的查询请求路由本地表进行查询, 然后进行汇总最终返回给用户
- 本地表
真正存储数据的表
1.分布式(Distributed)表引擎介绍
原理解析:
分布式(Distributed)表引擎是分布式表的代名词,它⾃身不存储任何数据,⽽是作为数据分⽚的透明代理,能够⾃动的 路由数据⾄集群中的各个节点,即分布式表需要和其他数据表⼀起协同⼯作。分布式表会将接收到的读写任务, 分发到各个本地表,而实际上数据的存储也是保存在各个节点的本地表中。
原理如下图:

2.创建分布式表
分布式表创建规则:
- 使用on cluster语句在集群的某台机器上执行以下代码,即可在每台机器上创建本地表和分布式表, 其中⼀张本地表对应着⼀个数据分⽚,分布式表通常以本地表加“_all”命名。它与本地表形成⼀对多的映 射关系,之后可以通过分布式表代理操作多张本地表。
- 这里有个要注意的点,就是分布式表的表结构尽量和本地表的结构一致。 如果不一致,在建表时不会报错,但在查询或者插入时可能会抛出异常。
先在每个分片上创建本地表:
--使用ReplicatedMergeTree引擎创建本地表test_log
create table test_log on cluster ck_cluster
(
totalDate Date,
unikey String
)
engine = ReplicatedMergeTree('/clickhouse/test/tables/{shard}/test_log', '{replica}')
PARTITION BY totalDate
ORDER BY unikey
SETTINGS index_granularity = 8192;
分布式表引擎的创建模板:
ENGINE = Distributed(cluster, database, table, [sharding_key])
参数描述:
-
cluster:集群名称,在对分布式表执⾏读写的过程中,它会使⽤集群的配置信息来找到相应的host节点。
-
database,table:数据库和本地表名称,用于将分布式表映射到本地表上。
-
sharding_key: 分⽚键,分布式表会按照这个规则,将数据分发到各个本地表中。
--创建分布式表test_log_all,数据在读写时会根据rand()随机函数的取值, --决定数据写⼊哪个分⽚,也可以用hash取值。 create table test_log_all on cluster ck_cluster ( totalDate Date, unikey String ) engine = Distributed('ck_cluster', 'test', 'test_log', rand());
联系上面创建的本地表和分布式表,假设我们clickhouse集群有两个节点,其分布式表与本地表的对应关系则如下图所示:
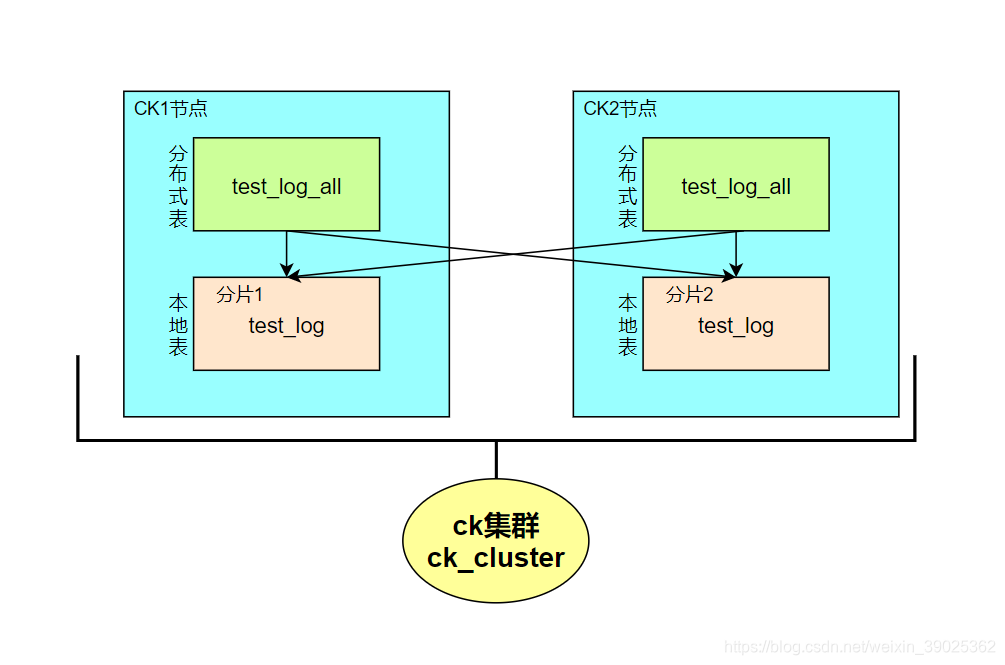
至此,ck_cluster集群的本地表test_log和分布式表test_log_all就创建完成了。
3.使用分布式表
-
我们的插入和查询任务都将使用分布式表,数据是分别保存本地表中的,分布式表是代理或映射关系 并不保存数据。可以理解分布式表是nginx,负责将读写任务分发到本地表。
-
如果要彻底删除分布表,则需要分别删除分布式表和本地表,其语法规则如下:
--删除分布式表 DROP TABLE test_log_all ON CLUSTER ck_cluster --删除本地表 DROP TABLE test_log ON CLUSTER ck_cluster
参考书籍:ClickHouse原理解析与应用实践
