

前言
最近公司在做文件存证的功能:文件存证上传之后得到SHA256值,当区块链or法庭需要用到的时候,比较SHA值,若文件被改动,SHA256值都会产生变化。因此前端需要对文件进行读取并用文件数据计算出SHA256值,需要用到文件读取类
new FileReader(),并用散列算法SHA256进行计算,但是一旦计算大文件就会出现网页假死/崩溃情况,切片也不能解决因为问题出在了计算上面,需要用到new Works()为 JavaScript 创造多线程环境,当然高版本的浏览器有内置计算函数,速度更快但兼容性没有new Works()好。下面就讲解一下问题的出现/解决思路,仅供参考!
这种问题记录文很少写,有什么不对的地方,错误的思维,欢迎大家指出,纠正。感谢大家了
初始阶段的文件读取
Vue演示:
input获取文件的的Blob值,前期为了节省时间是用crypto-js中的SHA256()进行计算。记得npm install crypto-js --save,后面拆解算法就不需要这个包了
<input type="file" @change="inputChange" />
import CryptoJS from 'crypto-js'
//...
methods:{
inputChange(e){
let files = e.target.files[0];
//生成实例
let fileReads = new FileReader();
//开始读取文件
fileReads.readAsArrayBuffer(files);
//读取回调
fileReads.onload=function(){
//将读取结果:文件数据类型:ArrayBuffer 转化 为wordArray格式
var wordArray = CryptoJS.lib.WordArray.create(fileReads.result);
//直接调用SHA256()并转化得到十六进制字符串(也就是我们要的SHA256)
var hash = CryptoJS.SHA256(wordArray).toString();
}
}
小课堂
来源:JavaScript类型化数组(二进制数组)
`ECMAScript 6` 中的 `ArrayBuffer`是类型化数组,也就是读取文件得到的缓冲内存,需要转换一下格式才能被计算 类型化数组的诞生就是为了能够让开发者通过类型化数组来操作内存,大大增强了JavaScript处理二进制数据的能力。
JavaScript类型化数组将实现拆分为缓冲和视图两部分。一个缓冲(ArrayBuffer)描述的是内存中的一段二进制数据,缓冲没有格式可言,并且不提供机制访问其内容。为了访问在缓存对象中包含的内存,你需要使用视图。视图可以将二进制数据转换为实际有类型的数组。一个缓冲可以提供给多个视图进行读取,不同类型的视图读取的内存长度不同,读取出来的数据格式也不同。缓冲和视图的工作方式如下图所示: 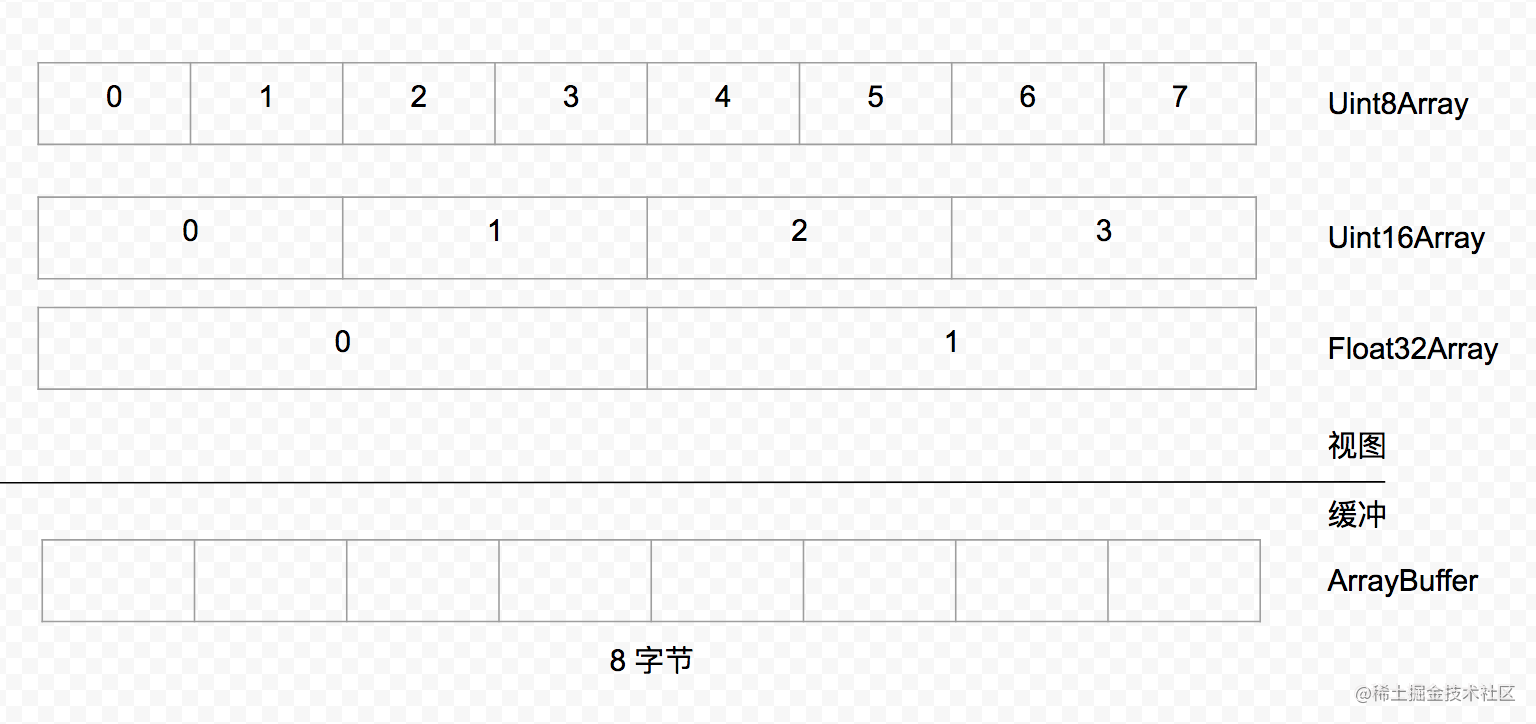
我们常见的各种编码、散列、加密算法,其基础都是位操作。
不管是对哪种数据类型,位操作对象的本质都是一段连续的比特序列。从性能的角度讲,位操作最好是能直接操作连续的内存位。那就是通过二进制位操作符。在含有位操作符的运算中,都得通过 ToInt32() 转换为 32 位有符号整数,然后将其当做 32 位的比特序列进行位运算,运算结果返回也为 32 位有符号整数。因此,通过拼接 32 位有符号整数,就可以实现“对一段连续的比特序列进行位操作”的功能了。
正是基于这样的原理, CryptoJs 实现了名为WordArray的类,作为“一段连续比特序列”的抽象进行各种位操作。 WordArray 是 CryptoJs 中最核心的一个类,所有主要算法的实际操作对象都是WordArray对象。理解WordArray是理解CryptoJs各算法的基础
words 为 32 位有符号整数构成的数组,通过按顺序拼接数组中的数,就组成了比特序列。 JavaScript 中 32 位有符号整数是通过补码转换为二进制的,不过在这里我们不需要关注这点,因为这个整数的值是没有意义的,实际使用中,比特序列更多的是用字节作单位,或用 16 进制数表示,因此我们只需要知道 32 位等价于 4 个字节,等价 于 8个 16 进制数。
问题出现
1、读取的文件大小一旦超过1GB左右就会长时间页面没有反应或者直接读取500MB左右并去计算会直接导致内存溢出页面崩溃,因为初始阶段的计算是用CryptoJS.lib.WordArray.create,这个方法短时间内会不断的开辟新的内存来保存二进制数组得不到释放。原因可以看看浏览器垃圾回收专栏。①切片读取后需要读取出来的ArrayBuffer格式转化成Uint8Array格式,再从Uint8Array转化成CryptoJs所需要的WordArray格式,但大文件的wordArray长度超出了数组的最长长度2的31次幂也就是2GB(有待商榷),超过2GB就会报错并且这个方式效率也会更低,因为数组合并也需要时间。
后面在crypto-js的sha256.js源码中发现了这个最终合并阶段函数算法,才解决了如何保留每一段的文件块的问题:
解决方案
思路:
- 直接采用CrotoJS中的SHA256的方法会内存溢出,所以把源码中的算法拆出来
采取分段读取,每一段的转化,再计算保存到初始哈希值,到最后一段合并,再最终转化。==》解决内存溢出问题。算法内容可以看看:》》一文读懂SHA256《《。 - 文件计算和上传是同时进行的,所以采取JS中的多线程:》》Web Worker《《,让我可以在后台计算文件哈希值,前台文件上传。===》
解决计算的时候线程被占用不能上传的问题。
实现步骤:
1、安装 worker-loader
不然webpack无法打包成功和识别这种方式
npm i -D worker-loader
2、配置:webpack.config.js:
+ const WorkerPlugin = require('worker-plugin');
module.exports = {
<...>
plugins: [
+ new WorkerPlugin()
]
<...>
}
3、业务代码
<input type="file" @change="inputChange" />
inputChange(e){
//获取文件实例
let files = e.target.files;
let i, workers, worker, cryptoFiles, cryptoAlgos;
//上传多文件
for (i = 0; i < files.length; i += 1) {
let currentFile = files[i];
workers = [];
cryptoAlgos = []; // 内置加密 集合
//线程文件(这是我的文件路径哈,别直接粘贴复制)
worker = new Worker('../toolkit/computer.js', { type: 'module' });
worker.addEventListener('message', this.handleWorkerEvent(currentFile));
workers.push(worker);
//开始分段
this.hashFile(currentFile, workers);
//...文件上传操作
}
}
//hashFile() 该方法对传入的文件列表进行分块读取并把读取结果通过 worker.postMessage() 给多线程文件computer.js
hashFile(file, workers){
let i, bufferSize, block, threads, reader, blob, handleHashBlock, handleLoadBlock;
bufferSize = 64 * 16 * 1024; // 块大小默认 1M
block = {
'file_size' : file.size,
'start' : 0
};
block.end = bufferSize > file.size ? file.size : bufferSize; // 源文件大小和块的单位大小对比 取小者
threads = 0; // 线程数
for (i = 0; i < workers.length; i += 1) {
// 监听多线程文件computer.js传过来的信息,每完成一次计算都通信告诉列表继续文件分块
workers[i].addEventListener('message', handleHashBlock);
}
reader = new FileReader();
//读取完后执行的函数:把读取完成的结果通信给线程文件computer.js,
reader.onload = handleLoadBlock;
blob = file.slice(block.start, block.end);
block.end = bufferSize > file.size ? file.size : bufferSize; // 源文件大小和块的单位大小对比 取小者
//开始读取分块
reader.readAsArrayBuffer(blob);
handleLoadBlock = (event)=> {
for( i = 0; i < workers.length; i += 1) {
threads += 1;
workers[i].postMessage({
'message' : event.target.result,
'block' : block
});
}
}
handleHashBlock = (event)=> {
threads -= 1;
if(threads === 0) {
if(block.end !== file.size) {
block.start += bufferSize;
block.end += bufferSize;
if(block.end > file.size) {
block.end = file.size;
}
reader = new FileReader();
reader.onload = handleLoadBlock;
blob = file.slice(block.start, block.end);
reader.readAsArrayBuffer(blob);
}
}
}
}
// worker 计算结果和进度 监听线程文件computer.js传过来的值
handleWorkerEvent() {
return (event)=> {
if (event.data.result) {
this.fileDigestResult = event.data.result;
console.log('计算结果为---------------:'+this.fileDigestResult)
} else {
console.log('当前进度-----:',(event.data.block.end * 100 / event.data.block.file_size).toFixed(2) + '%')
}
};
}
}
小课堂: window.postMessage() 方法可以安全地实现跨源通信。通常,对于两个不同页面的脚本,只有当执行它们的页面位于具有相同的协议(通常为https),端口号(443为https的默认值),以及主机 (两个页面的模数 Document.domain设置为相同的值) 时,这两个脚本才能相互通信。window.postMessage() 方法提供了一种受控机制来规避此限制,只要正确的使用,这种方法就很安全。
文件 computer.js:
//字节转words格式(小课堂有提到该格式)
function bytesToWords(a){
for(var b=[],c=0,d=0;c<a.length;c++,d+=8){
b[d>>>5]|=a[c]<<24-d%32;
}
return b
}
// words转字节
function wordsToBytes(a){
for(var b=[],c=0;c<a.length*32;c+=8){
b.push(a[c>>>5]>>>24-c%32&255)
}
return b
}
// 字节转十六进制字符串
function bytesToHex(a){
for(var b=[],c=0;c<a.length;c++){
b.push((a[c]>>>4).toString(16)),
b.push((a[c]&15).toString(16));
}
return b.join("")
}
self.hash = [ 0x6A09E667, 0xBB67AE85, 0x3C6EF372, 0xA54FF53A, 0x510E527F, 0x9B05688C, 0x1F83D9AB, 0x5BE0CD19 ];
// 在SHA256算法中,用到64个常量,这些常量是对自然数中前64个质数的立方根的小数部分取前32bit而来
var K = [ 0x428A2F98, 0x71374491, 0xB5C0FBCF, 0xE9B5DBA5,
0x3956C25B, 0x59F111F1, 0x923F82A4, 0xAB1C5ED5,
0xD807AA98, 0x12835B01, 0x243185BE, 0x550C7DC3,
0x72BE5D74, 0x80DEB1FE, 0x9BDC06A7, 0xC19BF174,
0xE49B69C1, 0xEFBE4786, 0x0FC19DC6, 0x240CA1CC,
0x2DE92C6F, 0x4A7484AA, 0x5CB0A9DC, 0x76F988DA,
0x983E5152, 0xA831C66D, 0xB00327C8, 0xBF597FC7,
0xC6E00BF3, 0xD5A79147, 0x06CA6351, 0x14292967,
0x27B70A85, 0x2E1B2138, 0x4D2C6DFC, 0x53380D13,
0x650A7354, 0x766A0ABB, 0x81C2C92E, 0x92722C85,
0xA2BFE8A1, 0xA81A664B, 0xC24B8B70, 0xC76C51A3,
0xD192E819, 0xD6990624, 0xF40E3585, 0x106AA070,
0x19A4C116, 0x1E376C08, 0x2748774C, 0x34B0BCB5,
0x391C0CB3, 0x4ED8AA4A, 0x5B9CCA4F, 0x682E6FF3,
0x748F82EE, 0x78A5636F, 0x84C87814, 0x8CC70208,
0x90BEFFFA, 0xA4506CEB, 0xBEF9A3F7, 0xC67178F2 ];
function sha256(m, H) {
var w = [], a, b, c, d, e, f, g, h, i, j, t1, t2;
for (var i = 0; i < m.length; i += 16) {
//初始化工作变量
a = H[0];
b = H[1];
c = H[2];
d = H[3];
e = H[4];
f = H[5];
g = H[6];
h = H[7];
//进行64次循环:算法使用64个32位字的消息列表、8个32位工作变量以及8个32位字的散列值。
for (var j = 0; j < 64; j++) {
if (j < 16) w[j] = m[j + i];
else {
var gamma0x = w[j - 15],
gamma1x = w[j - 2],
gamma0 = ((gamma0x << 25) | (gamma0x >>> 7)) ^
((gamma0x << 14) | (gamma0x >>> 18)) ^
(gamma0x >>> 3),
gamma1 = ((gamma1x << 15) | (gamma1x >>> 17)) ^
((gamma1x << 13) | (gamma1x >>> 19)) ^
(gamma1x >>> 10);
w[j] = gamma0 + (w[j - 7] >>> 0) +
gamma1 + (w[j - 16] >>> 0);
}
//执行散列计算
var ch = e & f ^ ~e & g,
maj = a & b ^ a & c ^ b & c,
sigma0 = ((a << 30) | (a >>> 2)) ^
((a << 19) | (a >>> 13)) ^
((a << 10) | (a >>> 22)),
sigma1 = ((e << 26) | (e >>> 6)) ^
((e << 21) | (e >>> 11)) ^
((e << 7) | (e >>> 25));
t1 = (h >>> 0) + sigma1 + ch + (K[j]) + (w[j] >>> 0);
t2 = sigma0 + maj;
h = g;
g = f;
f = e;
e = (d + t1) >>> 0;
d = c;
c = b;
b = a;
a = (t1 + t2) >>> 0;
}
//计算中间散列值
H[0] = (H[0] + a) | 0;
H[1] = (H[1] + b) | 0;
H[2] = (H[2] + c) | 0;
H[3] = (H[3] + d) | 0;
H[4] = (H[4] + e) | 0;
H[5] = (H[5] + f) | 0;
H[6] = (H[6] + g) | 0;
H[7] = (H[7] + h) | 0;
}
//
return H;
}
//接受前台传过来的值转化后,对每一小段继续计算来影响初始值哈希初值H 并进行最终的计算。
self.addEventListener('message', function (event) {
var uint8_array, message, block, nBitsTotal, output, nBitsLeft, nBitsTotalH, nBitsTotalL;
uint8_array = new Uint8Array(event.data.message);
message = bytesToWords(uint8_array);
block = event.data.block;
//防止短时间内内存溢出
event = null;
uint8_array = null;
output = {
'block' : block
};
// 如果是文件的最后一块则最终计算结果
if (block.end === block.file_size) {
nBitsTotal = block.file_size * 8;
nBitsLeft = (block.end - block.start) * 8;
nBitsTotalH = Math.floor(nBitsTotal / 0x100000000);
nBitsTotalL = nBitsTotal & 0xFFFFFFFF;
message[nBitsLeft >>> 5] |= 0x80 << (24 - nBitsTotal % 32);
message[((nBitsLeft + 64 >>> 9) << 4) + 14] = nBitsTotalH;
message[((nBitsLeft + 64 >>> 9) << 4) + 15] = nBitsTotalL;
self.hash = sha256(message, self.hash);
//最终结果
output.result = bytesToHex(wordsToBytes(self.hash));
} else {
//如果不是最后一块则计算的hash存入H(n)
self.hash = sha256(message, self.hash);
}
message = null;
self.postMessage(output);
}, false)
测试效果
100MB文件是9秒左右,1GB的文件计算时间是40秒左右,4.5GB是155000毫秒(2分钟左右)
再次声明:
这种问题记录文很少写,有什么不对的地方,错误的思维,欢迎大家指出,纠正。感谢大家了
