

python爬虫 -----图书馆抢座
本人也是一位考研学子 奈何图书馆座位总抢不到 就利用学过的技术做了一个图书馆抢座系统。
主要原理是利用提交post表单的形式进行抢座。
验证码识别
整个爬虫最难的可能就是验证码了,小编自然也走过很多歪路,有用过pytesseract识别,这pytesseract是真的垃圾,正确率不可直视 后来采用腾讯的一个接口进行测试 接口测试自然是可行的 奈何也得花个7-8秒 还不如手抢 在一次偶然的机会 通过文献、百度终于找到了大哥muggle_ocr 这个大哥可是拯救我于水火之中啊 0.3秒识别 废话不多说了代码粘上
#file_name是验证码图片路径
with open(file_name, "rb") as f:
captcha_bytes = f.read()
text = sdk.predict(image_bytes=captcha_bytes)
1234
分析登录请求信息
实质还是以post的形式提交表单。通过fiddler抓包得到,提交的信息和请求头如下:
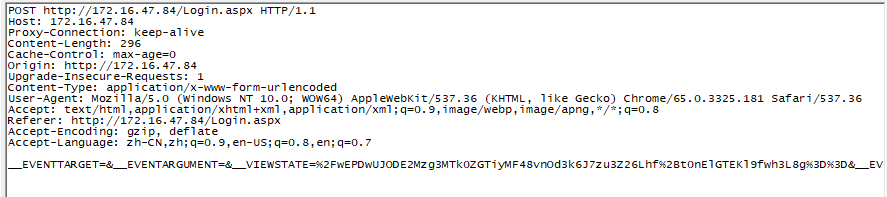

用户登录获取请求信息尤其是cookie
登录有一个重点就是利用session域保存一整个会话,为方便之后的获取验证码,以及抢座做准备。然后进行简单登录吧代码如下:
def login(self,username,password,quyu1,js3,zuoweihao):
ses = requests.session()
url='http://172.16.47.84/Login.aspx'
date={
'__VIEWSTATE': '/wEPDwUJODE2Mzg3MTk0ZGTiyMF48vnOd3k6J7zu3Z26Lhf+t0nElGTEKl9fwh3L8g==',
'__EVENTVALIDATION': '/wEWBAKm8rLABwLs0bLrBgLs0fbZDAKM54rGBkCiS2WHGa6+EL0Kh6yO5Ah09T75GOA5NPCLw47Aiepp',
'TextBox1': username,
'TextBox2': password,
'Button1': '登录',
}
str = ''
ses.post(url,headers=headers01,data=date)
return str
12345678910111213
通过cookie获取验证码
根据登录获取的session域进行获取验证码,保存在相应的路径,代码如下:
def yanzhengmaimage(self,ses):
str1 = ses.get("http://172.16.47.84/VerifyCode.aspx?", headers=headers01)
imagename=ses.__str__()[-19:-1]
with open('code02'+imagename+'.jpg', 'wb') as img:
img.write(str1.content)
12345
分析抢座请求信息

主要以下面代码为主
利用保存的cookie会话发送post 以及get请求
def tomorrow(self,ses,quyu1='3',js3='207',zuoweihao='001'):
#quyu1 代表区域 1东区 2中区 3 西区
#js3 代表教室 正常三位数字
#zhuoweihao 代表座位号 3位数字
str=quyu1+js3+zuoweihao
url = 'http://172.16.47.84/Verify.aspx?seatid='+str
date = {
'__VIEWSTATE': '/wEPDwUKMTcwNzM5ODc3NGRkFTNhg2TJCMmXjk16k+jkM2+o35s9J3SOm+JNsHJEwo4=',
'__EVENTVALIDATION': '/wEWAwL5+IeIAgLs0Yq1BQKM54rGBlbX/7GsfmI6ZGnyG3S+AAk6bsW9xrBTrDecfP4rhl+R',
'TextBox3': '',
'Button1': '提 交',
}
# self.base6434(ses)
hi = ses.get(url, headers=headers01)
date['TextBox3'] = self.base6434(ses)
resp = ses.post(url, headers=headers02, data=date)
soup = BeautifulSoup(resp.text, 'lxml')
Soup = soup.find_all('script')[0]
print(Soup)
print(zuoweihao)
ses.close()
return Soup.text
12345678910111213141516171819202122
抢座成功结果图

先写到这里 再更新 小编累了
利用多线程并发给多个账号进行同步抢座
并发抢座成功截图
PS:如遇到解决不了问题的小伙伴可以加点击下方链接自行获取
