

结构化的数据是最好处理,一般都是类似JSON格式的字符串,直接解析JSON数据,提取JSON的关键字段即可。
JSON
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式;适用于进行数据交互的场景,比如网站前台与后台之间的数据交互
Python 3.x中自带了JSON模块,直接import json就可以使用了。
Json模块提供了四个功能:dumps、dump、loads、load,用于字符串 和 python数据类型间进行转换
Python操作json的标准api库参考docs.python.org/zh-cn/3/lib…
1. json.loads()
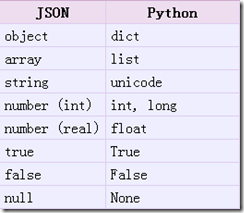
实现:json字符串 转化 python的类型,返回一个python的类型
从json到python的类型转化对照如下:
import json
a="[1,2,3,4]"
b='{"k1":1,"k2":2}'#当字符串为字典时{}外面必须是''单引号{}里面必须是""双引号
print json.loads(a)
[1, 2, 3, 4]
print json.loads(b)
{'k2': 2, 'k1': 1}
案例
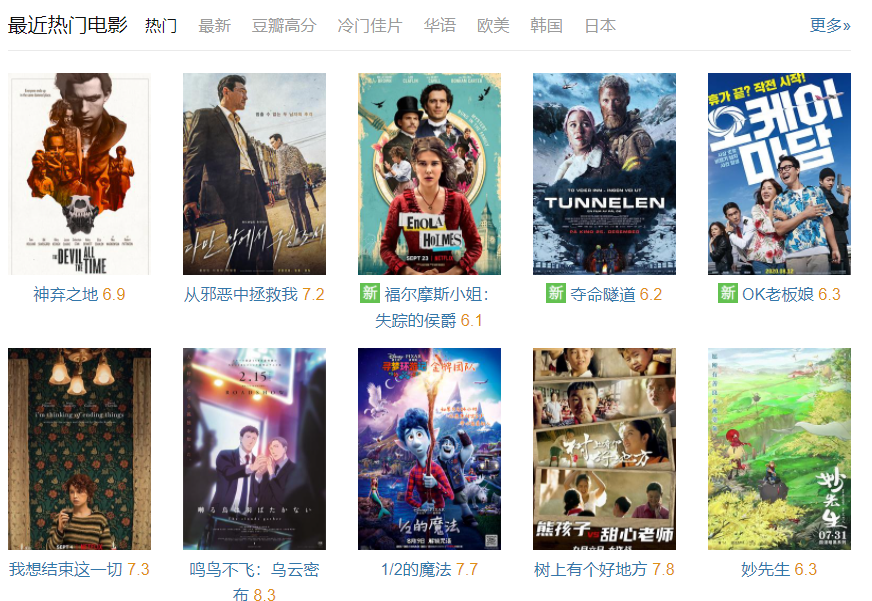
获取豆瓣电影热门
import urllib.parse
import urllib.request
import json
url='https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&page_limit=50&page_start=0'
# 豆瓣最新 热门
herders={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36', 'Referer':'https://movie.douban.com','Connection':'keep-alive'}
# 请求头信息
req = urllib.request.Request(url,headers=herders)
# 设置请求头
response=urllib.request.urlopen(req)
# 发起请求,得到response响应
hjson = json.loads(response.read())
# json转换为字典
# 遍历字典中的电影,item是每条电影信息
for item in hjson["subjects"]:
print(item["rate"],item["title"])
# 打印每条电影的评分与标题
输出
6.9 神弃之地
7.2 从邪恶中拯救我
6.1 福尔摩斯小姐:失踪的侯爵
6.2 夺命隧道
6.3 OK老板娘
7.3 我想结束这一切
8.3 鸣鸟不飞:乌云密布
7.7 1/2的魔法
7.8 树上有个好地方
6.3 妙先生
5.1 釜山行2:半岛
...
2. json.dumps()
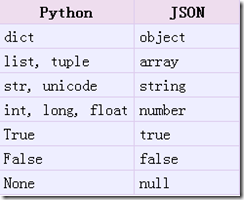
实现python类型转化为json字符串,返回一个str对象
从python原始类型向json类型的转化对照如下:
import json
a = [1,2,3,4]
b ={"k1":1,"k2":2}
c = (1,2,3,4)
json.dumps(a)
'[1, 2, 3, 4]'
json.dumps(b)
'{"k2": 2, "k1": 1}'
json.dumps(c)
'[1, 2, 3, 4]'
json.dumps 中文编码问题
如果Python Dict字典含有中文,json.dumps 序列化时对中文默认使用的ascii编码
import chardet
import json
b = {"name":"中国"}
json.dumps(b)
'{"name": "\\u4e2d\\u56fd"}'
print json.dumps(b)
{"name": "\u4e2d\u56fd"}
chardet.detect(json.dumps(b))
{'confidence': 1.0, 'encoding': 'ascii'}
'中国' 中的ascii 字符码,而不是真正的中文。
想输出真正的中文需要指定ensure_ascii=False
json.dumps(b,ensure_ascii=False)
'{"name": "\xe6\x88\x91"}'
print json.dumps(b,ensure_ascii=False)
{"name": "我"}
chardet.detect(json.dumps(b,ensure_ascii=False))
{'confidence': 0.7525, 'encoding': 'utf-8'}
3. json.dump()
import json
a = [1,2,3,4]
json.dump(a,open("digital.json","w"))
b = {"name":"我"}
json.dump(b,open("name.json","w"),ensure_ascii=False)
json.dump(b,open("name2.json","w"),ensure_ascii=True)
4. json.load()
读取 文件中json形式的字符串元素 转化成python类型
import json
number = json.load(open("digital.json"))
print( number)
b = json.load(open("name.json"))
print( b)
b.keys()
print b['name']
实战项目
获取 lagou 城市表信息
import urllib.parse
import urllib.request
import json
url='http://www.lagou.com/lbs/getAllCitySearchLabels.json?'
# 拉钩城市列表
herders={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36', 'Referer':'http://www.lagou.com','Connection':'keep-alive'}
# 请求头信息
req = urllib.request.Request(url,headers=herders)
# 设置请求头
response=urllib.request.urlopen(req)
# 发起请求,得到response响应
hjson = json.loads(response.read())
# print(hjson)
# json转换为字典
# 遍历字典中A开头的城市列表
for item in hjson["content"]["data"]["allCitySearchLabels"]["A"]:
print(item["name"],item["code"])
# 打印A 开头的城市清除与代码
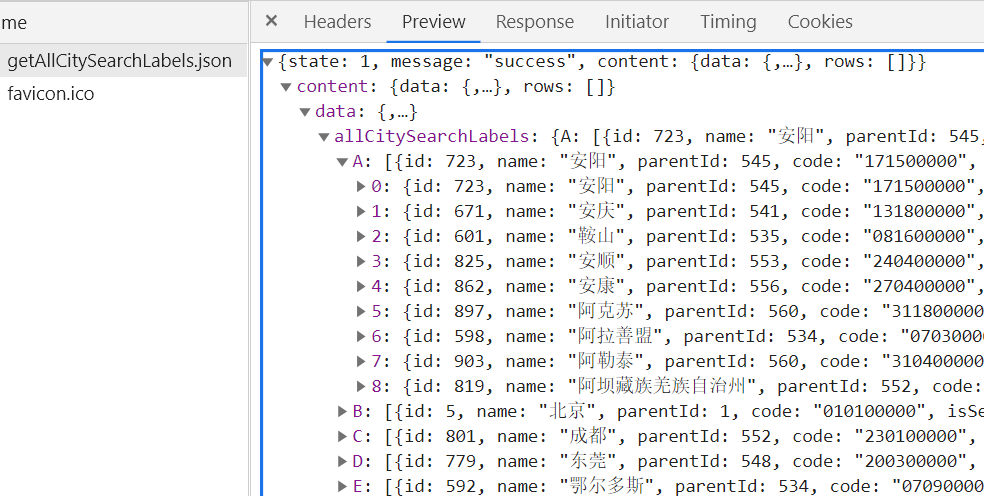
输出:
安阳 171500000
安庆 131800000
鞍山 081600000
安顺 240400000
安康 270400000
阿克苏 311800000
阿拉善盟 070300000
阿勒泰 310400000
阿坝藏族羌族自治州 230700000
JSONPath
JSON 信息抽取类库,从JSON文档中抽取指定信息的工具
JSONPath与Xpath区别
JsonPath 对于 JSON 来说,相当于 XPATH 对于XML。
下载地址:
安装方法:pip install jsonpath
参考文档
| XPath | JSONPath | Result |
|---|---|---|
/store/book/author | $.store.book[*].author* | 获取所有store中的book的author |
//author | $..author | 获取所有 authors |
/store/ | $.store. | all things in store, which are some books and a red bicycle. |
/store//price | $.store..price | 获取store中所有的price |
//book[3] | $..book[2] | 第二个 book |
//book[last()] | $..book[(@.length-1)]``$..book[-1:] | 获取到最后一个book |
//book[position()<3] | $..book[0,1]``$..book[:2] | 获取到前两个 books |
//book[isbn] | $..book[?(@.isbn)] | 获取到有isbn属性的book |
//book[price<10] | $..book[?(@.price<10)] | 获取所有的book ,price小于10 |
// | $..* | 匹配任意元素 |
案例
还是以 www.lagou.com/lbs/getAllC… 为例,获取所有城市
import urllib.request
import json
import jsonpath
url='http://www.lagou.com/lbs/getAllCitySearchLabels.json'
# 拉钩城市列表
herders={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36', 'Referer':'http://www.lagou.com','Connection':'keep-alive'}
# 请求头信息
req = urllib.request.Request(url,headers=herders)
# 设置请求头
response=urllib.request.urlopen(req)
# 发起请求,得到response响应
hjson = json.loads(response.read())
# 将字符加载为json对象
citylist = jsonpath.jsonpath(hjson,'$..name')
# 获取到所有的 城市名称
# print (type(citylist)) # <class 'list'>
content = json.dumps(citylist,ensure_ascii=False)
# 列表转换为json 字符串 ,不使用ascii编码,
fp = open('city.json','w')
# 打开文件
fp.write(content)
# 写入文件
fp.close()
# 关闭文件
输出文件为

XML
xmltodict模块让使用XML感觉跟操作JSON一样
Python操作XML的第三方库参考:
模块安装:
pip install xmltodict
import xmltodict
bookdict = xmltodict.parse("""
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
""")
print (bookdict.keys())
[u'bookstore']
print(json.dumps(bookdict,indent=4))
输出结果:
{
"bookstore": {
"book": [
{
"title": {
"@lang": "eng",
"#text": "Harry Potter"
},
"price": "29.99"
},
{
"title": {
"@lang": "eng",
"#text": "Learning XML"
},
"price": "39.95"
}
]
}
}
单词表
"""
单词表
content 内容
loads 加载
dumps 输出 (倾倒)
citylist 城市列表
JSON(JavaScript Object Notation)
( JS 对象对象表述数据)
path 路径
request 请求
headers 头信息
response 响应
read 读取
content 内容
"""
数据提取总结
- HTML、XML
XPath
CSS选择器
正则表达式
- JSON
JSONPath
转化成Python类型进行操作(json类)
- XML
转化成Python类型(xmltodict)
XPath
CSS选择器
正则表达式
- 其他(js、文本、电话号码、邮箱地址)
正则表达式

