

lxml 是一种使用 Python 编写的库,可以迅速、灵活地处理 XML ,支持 XPath (XML Path Language)
lxml python 官方文档 lxml.de/index.html
学习目的
利用上节课学习的XPath语法,来快速的定位 特定元素以及节点信息,目的是 提取出 HTML、XML 目标数据
如何安装
- Ubuntu :
sudo apt-get install libxml2-dev libxslt1-dev python-dev
sudo apt-get install zlib1g-dev
sudo apt-get install libevent-dev
sudo pip install lxml
利用 pip 安装即可
- Windows:
初步使用
首先我们利用lxml来解析 HTML 代码,先来一个小例子来感受一下它的基本用法。
使用 lxml 的 etree 库,然后利用 etree.HTML 初始化,然后我们将其打印出来。
from lxml import etree
text ='''
<div>
<ul>
<li class="item-0"><a href="link1.html">第一项</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
'''
#把字符串解析为html文档
html = etree.HTML(text)
#将元素序列化为其XML树的字符串表示形式
result = etree.tostring(html)
print (result)
所以输出结果是这样的
<html><body><div>
<ul>
<liclass="item-0"><ahref="link1.html">第一项</a></li>
<liclass="item-1"><ahref="link2.html">second item</a></li>
<liclass="item-inactive"><ahref="link3.html"><spanclass="bold">third item</span></a></li>
<liclass="item-1"><ahref="link4.html">fourth item</a></li>
<liclass="item-0"><ahref="link5.html">fifth item</a>
</li></ul>
</div>
</body></html>
不仅补全了 li 标签,还添加了 body,html 标签。
XPath实例测试
**1. 获取所有的 **<li> 标签
print type(html)
result = html.xpath('//li')
print (result)
print (len(result))
print (type(result))
print (type(result[0]))
运行结果
<type'lxml.etree._ElementTree'>
[<Elementliat 0x1014e0e18>, <Elementliat 0x1014e0ef0>, <Elementliat 0x1014e0f38>, <Elementliat 0x1014e0f80>, <Elementliat 0x1014e0fc8>]
5
<type'list'>
<type'lxml.etree._Element'>
可见,每个元素都是 Element 类型;是一个个的标签元素,类似现在的实例
<Elementliat 0x1014e0e18>
Element类型代表的就是
<li class="item-0"><ahref="link1.html">第一项</a></li>
[注意]
Element类型是一种灵活的容器对象,用于在内存中存储结构化数据。
每个element对象都具有以下属性:
1. tag:string对象,标签,用于标识该元素表示哪种数据(即元素类型)。
2. attrib:dictionary对象,表示附有的属性。
3. text:string对象,表示element的内容。
4. tail:string对象,表示element闭合之后的尾迹。
示例
<tag attrib1=1>text</tag>tail1 2 3 4
result[0].tag #li
2. 获取 <li> 标签的所有 class
html.xpath('//li/@class')
运行结果
['item-0', 'item-1', 'item-inactive', 'item-1', 'item-0']
3.获取 <li> 标签下属性 href 为 link1.html 的 <a> 标签
html.xpath('//li/a[@href="link1.html"]')
运行结果
[<Element a at 0x10ffaae18>]
4.获取 <li> 标签下的所有 <span>** 标签**
注意这么写是不对的
html.xpath('//li/span')
因为 / 是用来获取子元素的,而 <span> 并不是 <li> 的子元素,所以,要用双斜杠
html.xpath('//li//span')
运行结果
[<Element span at 0x10d698e18>]
5. 获取 <li> 标签下的所有 class,不包括 <li>
html.xpath('//li/a//@class')
运行结果
['blod']
**6. 获取最后一个 **<li> 的<a> 的 href
html.xpath('//li[last()]/a/@href')
运行结果
['link5.html']
7. 获取 class 为 bold 的标签名
result = html.xpath('//*[@class="bold"]')print result[0].tag
运行结果
span
通过以上实例的练习,相信大家对 XPath 的基本用法有了基本的了解
实战项目
豆瓣电影排行榜
from lxml import etree
import urllib.parse
import urllib.request
url='https://movie.douban.com/chart'
# 豆瓣排行榜
herders={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36', 'Referer':'https://movie.douban.com/','Connection':'keep-alive'}
# 请求头信息
req = urllib.request.Request(url,headers=herders)
# 设置请求头
response=urllib.request.urlopen(req)
# response 是返回响应的数据
htmlText=response.read()
# 读取响应数据
# 把字符串解析为html文档
html = etree.HTML(htmlText)
result = html.xpath('//div[@class="pl2"]/a')
# 解析到所有的标题
file = open('data.txt','a+',encoding='utf-8')
# 打开一个文本文件
for line in result:
file.write(line.xpath('string(.)').replace('\n','').replace(' ','')+'\n')
# 遍历解析到的结果
# 获取里面的文字.移除换行.替换空格+换行
file.close()
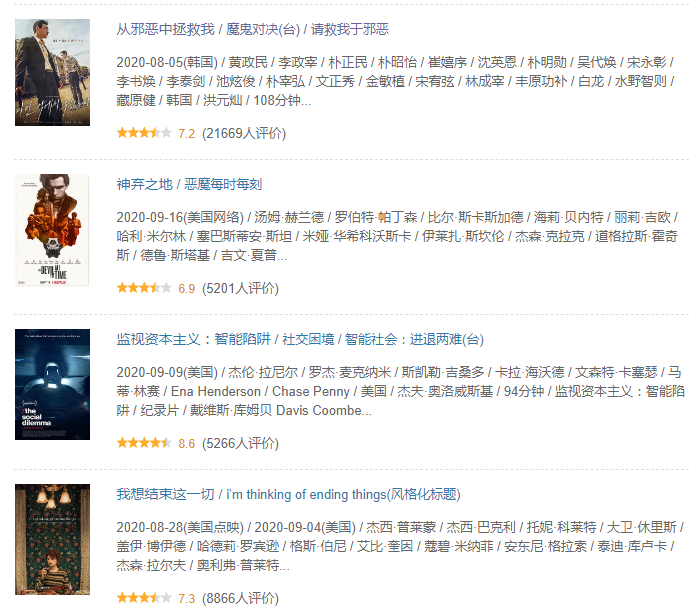
结果
data.txt
从邪恶中拯救我/魔鬼对决(台)/请救我于邪恶
神弃之地/恶魔每时每刻
监视资本主义:智能陷阱/社交困境/智能社会:进退两难(台)
我想结束这一切/i’mthinkingofendingthings(风格化标题)
禁锢之地/Imprisonment/TheTrapped
鸣鸟不飞:乌云密布/SaezuruToriWaHabatakanai:TheCloudsGather
树上有个好地方/TheHomeintheTree
辣手保姆2:女王蜂/撒旦保姆:血腥女王/TheBabysitter2
冻结的希望/雪藏希望:待日重生/HopeFrozen:AQuestToLiveTwice
铁雨2:首脑峰会/铁雨2:首脑会谈/钢铁雨2:核战危机(港)
单词表
"""
单词表
parse 解析
request 请求
headers 请求头
result 结果
file 文件
encoding 编码
write 写
open 打开
string 文本
replace 替换
"""
作业
(1)练习一下lxml、etree、xpath的整个的操作
(2)试试上节课XPath的语法以及Html,自己动手实践

