本系列是台湾大学资讯工程系林軒田(Hsuan-Tien Lin)教授开设的《机器学习基石》课程的梳理。重在梳理,而非详细的笔记,因此可能会略去一些细节。
该课程共16讲,分为4个部分:
- 机器什么时候能够学习?(When Can Machines Learn?)
- 机器为什么能够学习?(Why Can Machines Learn?)
- 机器怎样学习?(How Can Machines Learn?)
- 机器怎样可以学得更好?(How Can Machines Learn Better?)
本文是第4部分,对应原课程中的13-16讲。
本部分的主要内容:
- 过拟合问题,过拟合与噪声、目标函数复杂度的关系;
- 正则化,正则化与VC理论的联系;
- 验证,留一交叉验证和V-折交叉验证;
- 三个学习原则,即奥卡姆剃刀、抽样偏差和数据窥探。
1 过拟合问题
1.1 过拟合的发生
假设现在用带很小噪声的2次多项式生成了5个样本,对于这5个样本,其实用4次多项式就可以完美拟合它:
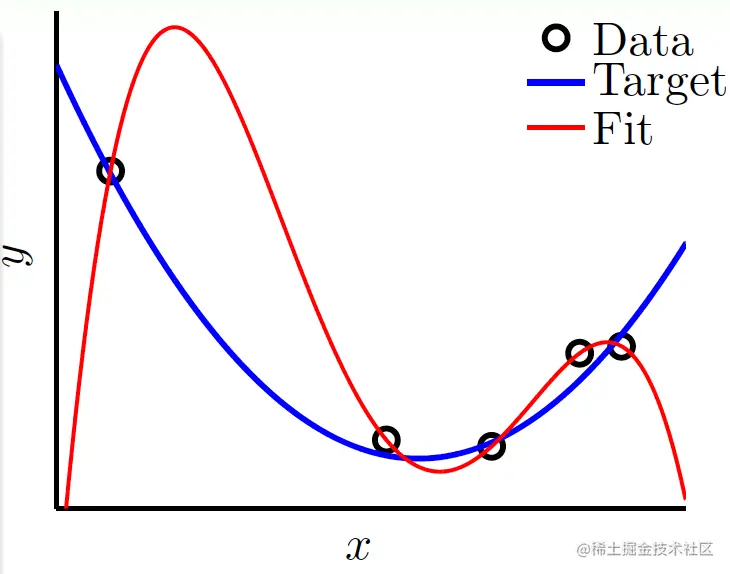
这样做可使Ein=0,但Eout却会非常大。
如果出现Ein很小,Eout很大的情况,就是出现了不好的泛化(bad generalization)。如果在训练的过程中,Ein越来越小,Eout越来越大,就称为过拟合(overfitting)。
噪声和数据规模都会影响过拟合。先来看以下两个数据集:
- 数据由10次多项式生成,有一些噪声;
- 数据由50次多项式生成,无噪声。
数据集图像如下:
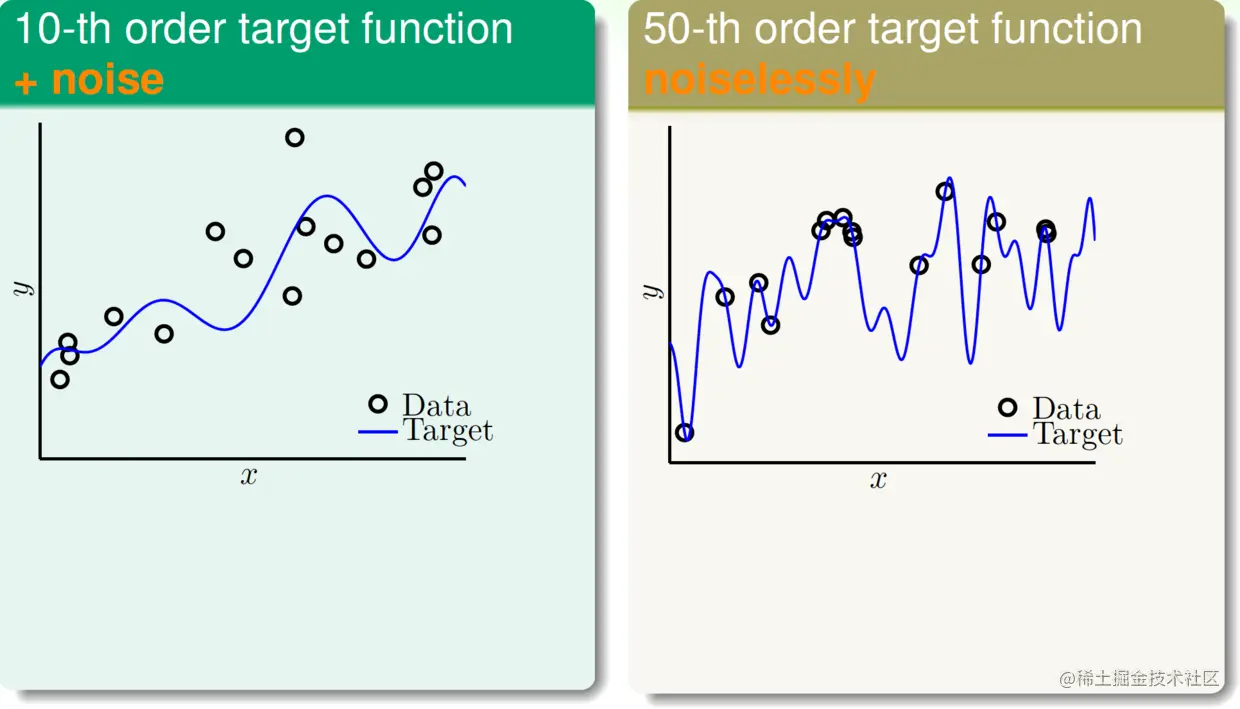
如果我们用2次和10次多项式分别拟合以上两个数据集,那么在从g2∈H2到g10∈H10的过程中,会发生过拟合吗?
拟合结果如下:
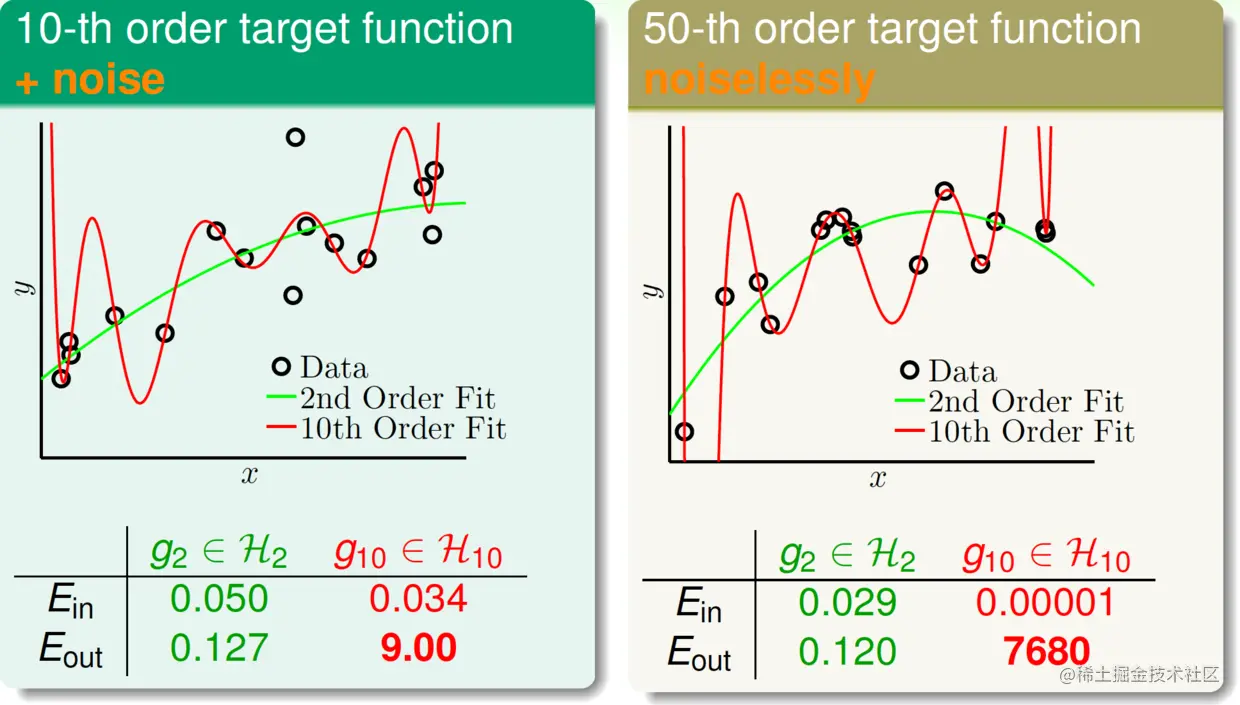
比较后发现,在两个数据集中,都发生了过拟合!
来看学习曲线,当N→∞时显然H10会有更小的Eout,但N较小时它会有很大的泛化误差。灰色区域就是过拟合发生的区域。
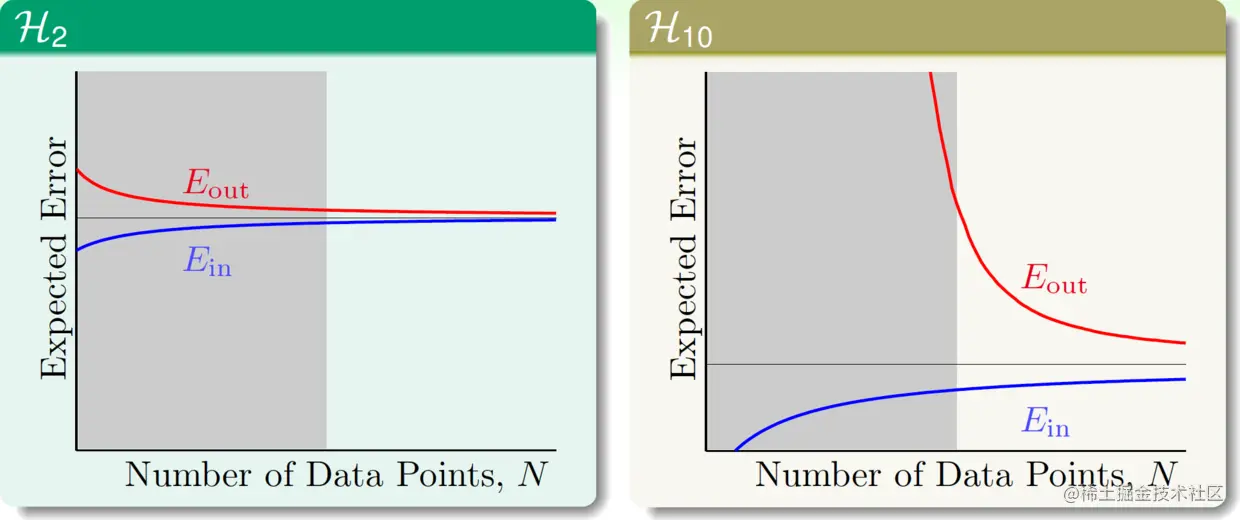
其实对于由无噪声的50次多项式生成的数据,“目标函数的复杂度”本身就可以看作类似的噪声。
接下来做个更细节的实验。用
y=f(x)+ϵ∼Gaussian⎝⎛q=0∑Qfαqxq,σ2⎠⎞
生成N个数据,其中ϵ是独立同分布的高斯噪声,噪声水平为σ2,f(x)关于复杂度水平Qf是均匀分布的。也就是说,目标函数有Qf和σ2两个变量。
然后,分别固定Qf=20和σ2=0.1,还是分别用2次和10次多项式拟合数据,并用Eout(g10)−Eout(g2)度量过拟合水平。结果如下:
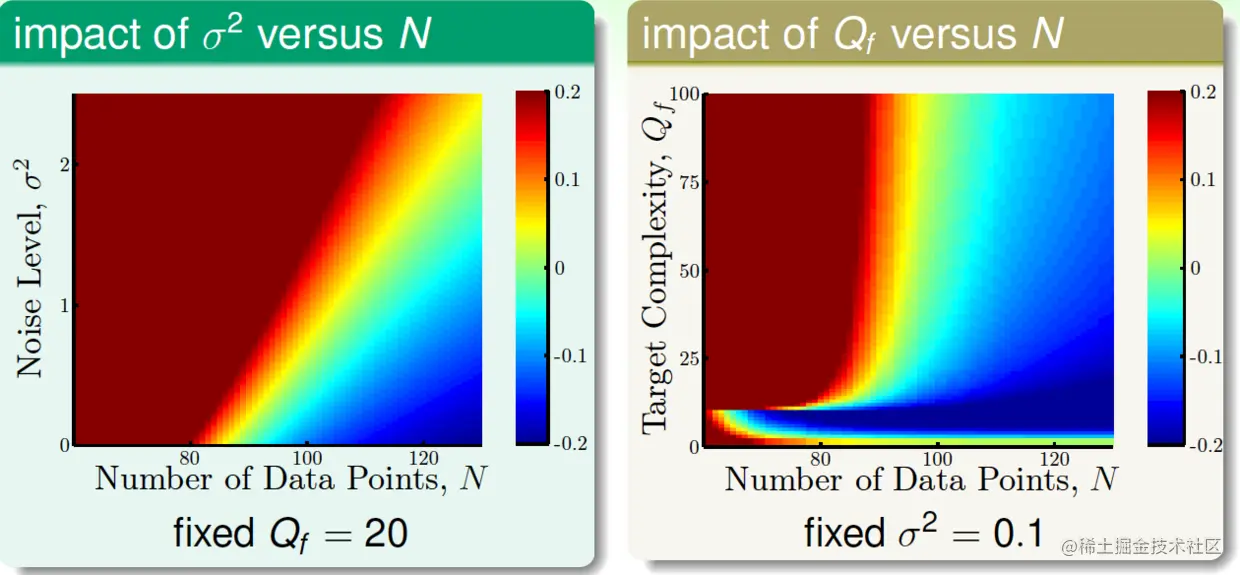
颜色偏红的区域,就是发生了过拟合。
加上去的σ2高斯噪声可称为stochastic noise,而目标函数的次数Qf也有类似噪声的影响,因此可叫deterministic noise。
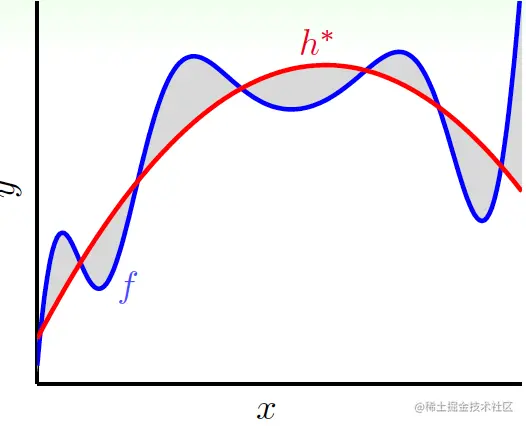
如果f∈/H,那么f一定有某些部分就无法被H所捕捉到,最好的h∗∈H与f的差就是deterministic noise,它的表现与随机噪声没什么不一样(与伪随机数生成器类似)。它与stochastic noise的不同之处在于,它与H有关,且对于每个x,它的值是确定的:
1.2 过拟合的处理
一般来说,处理过拟合的思路有以下几种:
- 从简单的模型开始;
- 数据清洗(data cleaning),将错误的数据修正(如更正它的标签类别);
- 数据剪枝(data pruning),删去离群点(outlier);
- data hinting,当样本量不够时,可以对现有样本做些简单的处理,增加样本量,如在数字分类中,可以将数据微微旋转或平移而不改变它们的标签,这样就可增大样本量;
- 正则化(regularization),见下节;
- 验证(validation),见后文。
2 正则化(regularization)
2.1 正则化
正则化的思想是好比从H10“逐步回退”到H2。这个名字的由来是在早期做函数逼近(function approximation)时,有很多问题是ill-posed problems,即有很多函数都是满足问题的解,所以要加入一些限制条件。从某种意义上说,机器学习中的过拟合也是“正确的解太多”的问题。
H10中假设的一般形式为
w0+w1x+w2x2+w3x3+⋯+w10x10
而H2中假设的一般形式为
w0+w1x+w2x2
其实只要限制w3=w4=⋯=w10=0,就会有H10=H2。如果在用H10时加上这个限制,其实就是在用H2做机器学习。
H2的灵活性有限,但H10又很危险,那有没有折中一些的假设集呢?不妨把这个条件放松一些,变成q=0∑101[w1=0]≤3,记在该限制下的假设集为H2′,有H2⊂H2′⊂H10,即它比H2更灵活,但又没有H10那么危险。
在H2′下,求解的问题转化成了
w∈R10+1minEin(w)s.t. q=0∑101[w1=0]≤3
这是个NP-hard问题,复杂度很高。不如再将它变为
w∈R10+1minEin(w)s.t. q=0∑10wq2≤C
记该假设集为H(C),它与H2′是有部分重叠的,并且对于C有软的、光滑的结构:
H0⊂H1⊂⋯⊂H∞=H10
记在H(C)下找到的最优解为wREG。
在没有正则化时,用梯度下降更新参数的方向是−∇Ein(w)。而在加入了正则化wTw≤C的限制时,必须在该限制下更新,如下图:
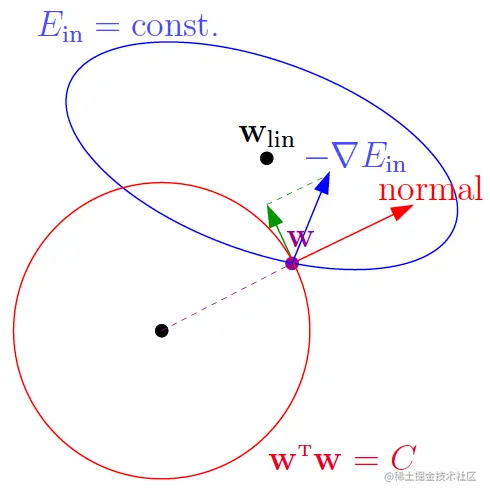
wTw=C的法向量(normal vector)就是w,从图中可知,只要−∇Ein(w)和w不平行,就可继续在该限制下降低Ein(w),因此,达到最优解时,一定有
−∇Ein(w)∝wREG
由此,问题可以转化为求解
∇Ein(wREG)+N2λwREG=0
其中λ是引入的拉格朗日乘子(Lagrange multiplier)。假设已知λ>0,只需要把梯度的式子写出来,即有:
N2(XTXwREG−XTy)+N2λwREG=0
直接求解即可得
wREG←(XTX+λI)−1XTy
只要λ>0,XTX+λI就是正定矩阵,它一定可逆。
在统计学中,这通常叫岭回归(ridge regression)。
换一种视角来看,求解
∇Ein(wREG)+N2λwREG=0
就等价于求解(相当于对上式两边取积分)
wminEin(w)+NλwTw
wTw可叫regularizer,整个Ein(w)+NλwTw可叫作augmented error Eaug(w)。
这样,原本是给定C后解一个条件最值问题,现在转化成了一个给定λ的无条件最值问题。
可将+NλwTw称为weight-decay regulariztion,因为更大的λ,就相当于让w更短一些,也相当于C更小一点。
一个小细节:在做特征变换时,如果用Φ(x)=(1,x,x2,…,xQ),假设xn∈[−1,+1],那么xnq会非常小,这一项本来就需要很大的wq才能起到作用,如果此时再用正则化,就对高维的系数有些“过度惩罚”了,因为它本来就要比较大才行。因此,可在多项式的空间中找出一些正交的基函数(orthonormal basis function),这是一些比较特别的多项式,叫勒让德多项式(Legendre Polynomials),再用这些多项式这样做特征变换(1,L1(x),L2(x),…,LQ(x))即可。前5个勒让德多项式如下图:

2.2 正则化与VC理论
在最小化augmented error的时候,尽管它与带约束最值问题是等价的,但在计算时,其实并没有真正的将w限制在H(C)中。那么正则化究竟是怎么发生的?
可以从另一个角度看augmented error:
Eaug(w)=Ein(w)+NλwTw
若记wTw为Ω(w),它度量的是某个假设w的复杂度。而在VC Bound中
Eout(w)≤Ein(w)+Ω(H)
Ω(H)度量的是整个H的复杂度。如果NλΩ(w)与Ω(H)有某种关联,Eaug就可以直接作为Eout的代理,不需要再通过做好Ein来做好Eout,而同时,又可以享受整个H的高度灵活性。
再换个角度,原本对于整个H有dVC(H)=d~+1,而现在相当于只考虑H(C)中的假设,也就是说VC维变成了dVC(H(C))。可以定义一个“有效VC维”dEFF(H,A),只要A中做了正则化,有效VC维就会比较小。
2.3 更一般的正则项
有没有更一般的正则项Ω(w)?该如何选择呢?有以下建议:
- 与目标有关(target-dependent),如果知道目标函数的一些性质,就可以写出来,比如我们预先知道目标函数是接近于偶函数的,那就可以选取∑1[q is odd]wq2;
- 合理的(plausible),可以选平滑的或简单的,如为了稀疏性而选L1正则项∑∣wq∣,下文会说明;
- 友好的(friendly),即容易优化,如L2正则项∑wq2;
- 就算选的正则项不好,也没有关系,因为可以靠λ来调节,最差也就是相当于没有加入正则项。
L1正则项如下图:
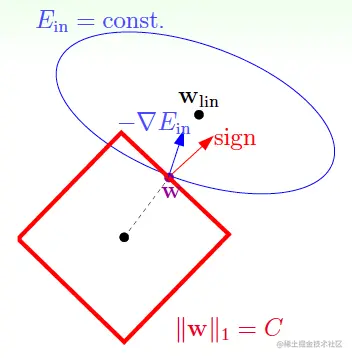
它是凸的,但不是处处可微,加入它之后,解具有稀疏性。如果在实际中需要有稀疏解,L1就会很有用。
λ要怎么选呢?可根据Eout的情况选出的最优λ,示例如下(加粗点为最优λ):
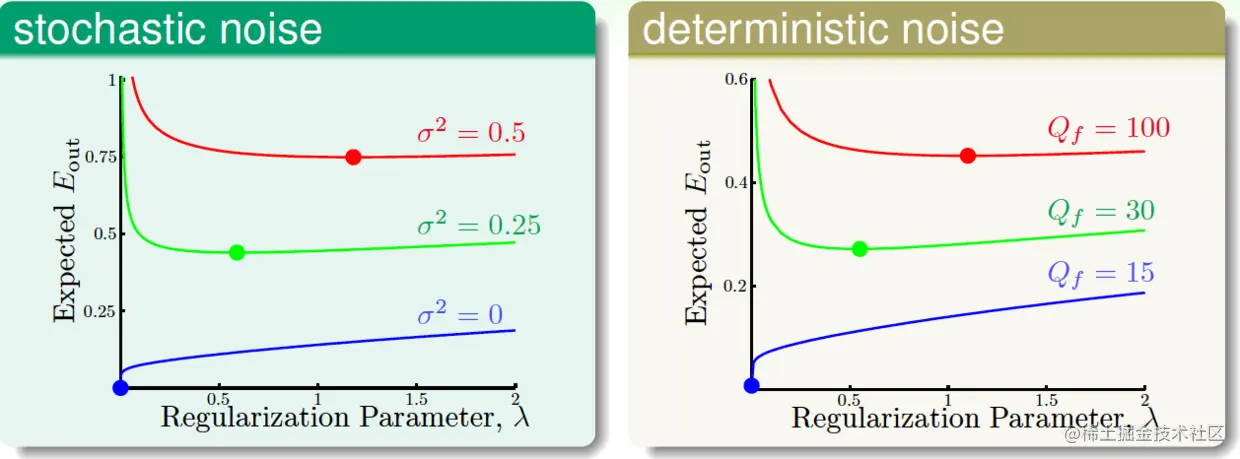
从图中可以看到,噪声越大,越需要增加regularization。
但一般情况下,噪声是未知的,该如何选择合适的λ?
3 验证(Validation)
3.1 验证集
λ该如何选择?我们完全不知道Eout,并且也不能直接通过Ein做选择。如果有一个从来没被使用过的测试集就好了,这样就可以根据测试集进行选择:
m∗=1≤m≤Margmin(Em=Etest(Am(D)))
并且,这样做是有泛化保证的(Hoeffding):
Eout(gm∗)≤Etest(gm∗)+O(NtestlogM)
但哪里有真正测试集?只能折中地从D划分出一部分数据作为验证集Dval⊂D了,当然,也要求它是在过去从未被Am使用过的。
划分验证集Dval的过程如下:
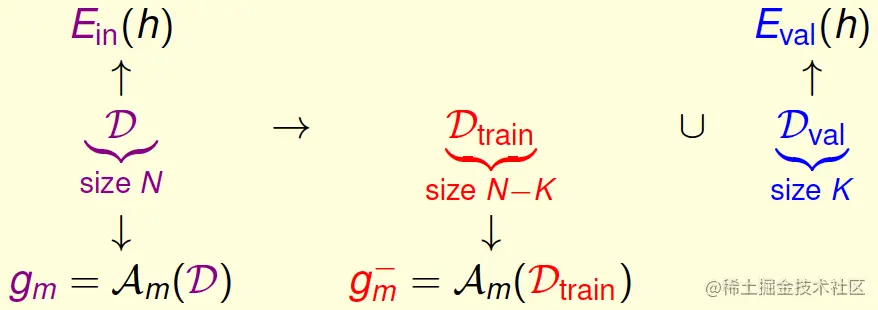
用训练集得到的gm−,也可以有泛化保证:
Eout(gm−)≤Eval(gm−)+O(KlogM)
做验证时的一般流程如下:

可以看到,在用验证集选出最好的模型gm∗−后,还是要用所有的数据再训练一个最好的模型gm∗出来,一般来说这次训练得到的gm∗会由于训练数据量的更大而有更低的Eout,见下图:
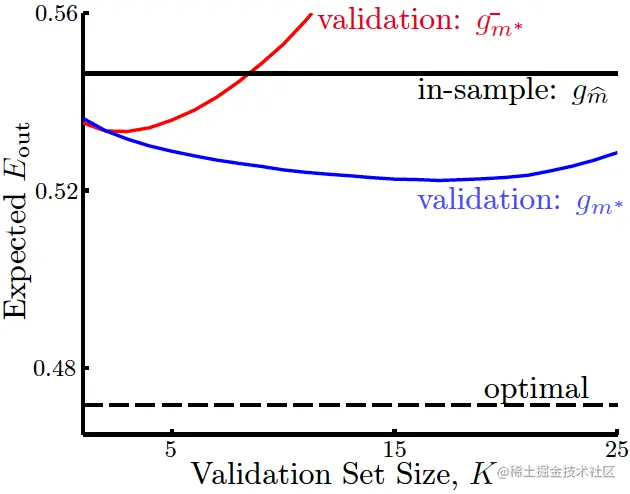
图中最下面的虚线为Eout。可以看到,K不能过大或过小,如果K过小,虽然gm−≈gm,但Eval和Eout会差别很大,而如果K过大,尽管Eval≈Eout,但会使gm−比gm差很多。
我们真正想要做到的是
Eout(g)≈Eout(g−)≈Eval(g−)
第一个约等号要求K较小,第二个约等号要求K较大,因此必须选一个合适的K,按经验法则可选K=5N。
3.2 留一交叉验证(LOOCV)
如果让K=1,即只留一个样本n作为验证集,记
Eval(n)(gn−)=err(gn−(xn),yn)=en
但单个en无法告诉我们准确的信息,要想办法对所有可能的Eval(n)(gn−)取平均。可以用留一交叉验证(Leave-One-Out Cross Validation):
Eloocv(H,A)=N1n=1∑Nen=N1n=1∑Nerr(gn−(xn),yn)
我们希望的是有Eloocv(H,A)≈Eout(g)。可作证明:
======DEEloovc(H,A)DEN1n=1∑NenN1n=1∑NDEenN1n=1∑NDnE(xn,yn)Eerr(gn−(xn),yn)N1n=1∑NDnEEout(gn−)N1n=1∑NEout(N−1)Eout(N−1)
由于Eloovc(H,A)的期望会告诉我们一些关于Eout(g−)的期望的信息,因此也叫作Eout(g)的“几乎无偏估计”(almost unbiased estimate)。
用手写数字识别——对数字是否为1进行分类——看看效果,两个基础特征为对称性和平均强度(average intensity),对它们进行特征变换(增加特征数量),再分别用Ein和Eloocv进行参数选择(参数是变换后的特征个数),结果如下:
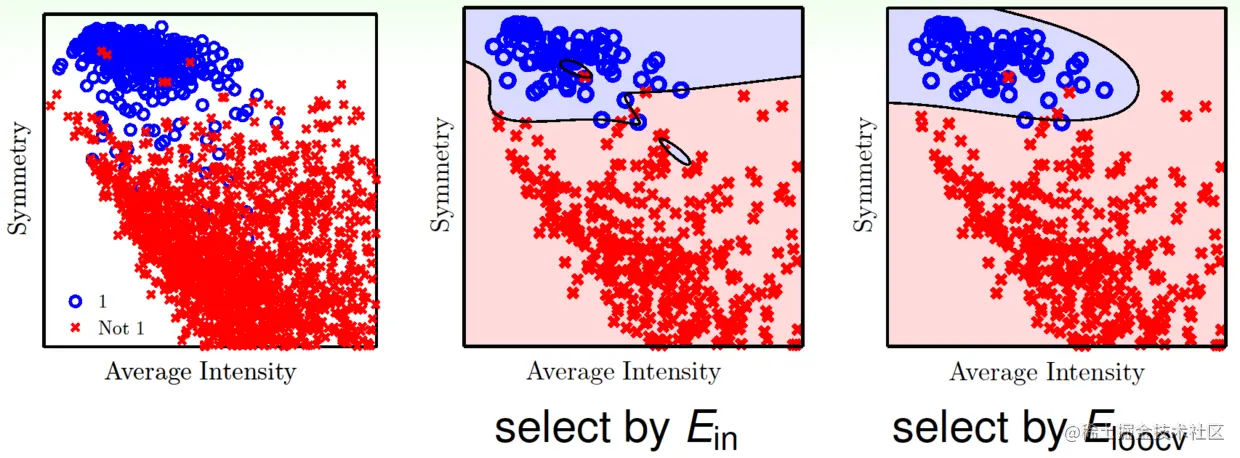
如果将Eout、Ein、Eloocv分别随特征数变化而变化的情况画出来,如图:
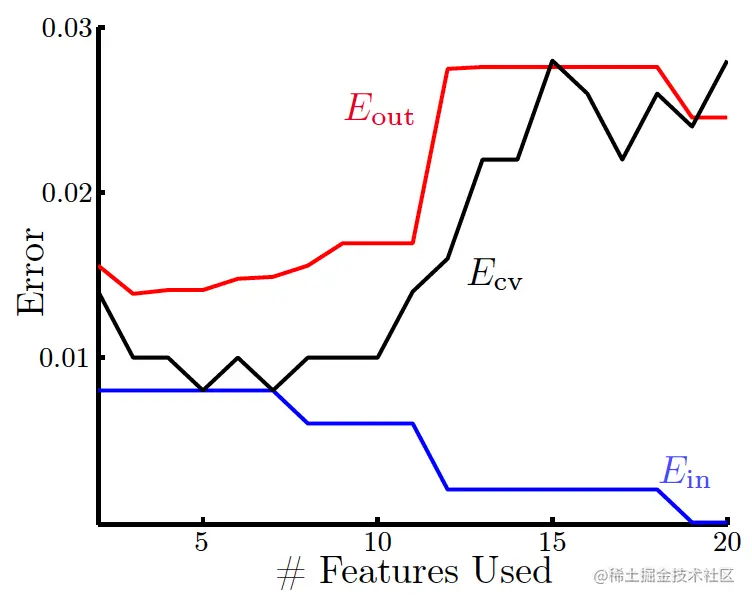
3.3 V-折交叉验证
如果有1000个点,做留一交叉验证就要计算1000次en,每次计算还要用999个样本做训练,除了少数算法(如线性回归,它有解析解),在大多数情况下会非常耗时间。另一方面,由上一节最后可看到,由于Eloocv是在单个点上做平均,结果会有跳动,不够稳定。因此,在实际中,loocv并不是很常用。
在实际中,更常用的是V折交叉验证(V-Fold Cross Validation),即将D随机分为V等分,轮流用每一份做验证,用剩下的V−1份做训练,在实际中一般常取V=10,如下图:

这样能计算出
Ecv(H,A)=V1v=1∑VEval(v)(gv−)
再用它对参数做选择:
m∗=1≤m≤Margmin(Em=Ecv(Hm,Am))
值得注意的是,由于验证过程也是在做选择,它的结果依旧会比最后的测试结果乐观一些。因此,最后重要的是测试的结果,而非找出来的最好的验证的结果。
4 三个学习的原则
这里介绍三个学习的原则。
4.1 奥卡姆剃刀
首先是奥卡姆剃刀(Occam's Razor)。
An explanation of the data should be made as simple as possible, but no simpler.
--Albert Einsterin (?)
这句话传说是爱因斯坦所说,但没有证据。最早可追溯到奥卡姆的话:
entia non sunt multiplicanda praeter necessitatem (entities must not be multiplied beyond necessity)
--William of Occam (1287-1347)
在机器学习中,这是说能拟合数据的最简单的模型往往是最合理的。
什么叫简单的模型呢?对于单个假设h来说,要求Ω(h)较小即参数较少,对于一个模型(假设集)H来说,要求Ω(H)较小即它没包含太多可能的假设。这两者是相关的,比如∣H∣规模是2ℓ,那么其实只需要ℓ个参数就可以描述所有的h,因此小的Ω(H)也就意味着小的Ω(h)。
从哲学意义上说,越简单的模型,“拟合”发生的概率越小,如果真的发生了,那就说明数据中可能真的有一些比较重要的规律。
4.2 抽样偏差
第二个是要注意抽样偏差(Sampling Bias)。
如果数据的抽样过程存在偏差,那么机器学习也会产生一个有偏差的结果。
在讲解VC维时,提到过一个前提条件,就是训练数据和测试数据需要来自同一个分布。当无法满足时,经验法则是,尽可能让测试环境和训练环境尽可能匹配。
4.3 数据窥探
第三是要注意数据窥探(Data Snooping)。
如果你通过观察,发现数据比较符合某个模型,进而选用该模型,这是比较危险的,因为相当于加入了你大脑中的模型的复杂度。
在任何使用数据的过程中,其实都是间接窥探到了数据。在窥探了数据的表现后,做任何决策,都会引入“大脑”复杂度。
比如在做scaling时,不能把训练集和测试集放在一起做scaling,而只能对训练集做。
其实在机器学习的前沿研究中,也存在类似的情况。比如第一篇论文发现了H1会在D上表现较好,而第二篇论文提出了H2,它在D上比H1表现得更好(否则就不会发表),第三篇也如此……如果将所有论文看作一篇最终版的论文,那么真正的VC维其实是dvc(∪mHm),它会非常大,泛化会非常差。这是因为其实在每一步过程中,作者都通过阅读前人的文献而窥探了数据。
因此在做机器学习时,要审慎地处理数据。要避免用数据来做一些决策,即最好事先就将领域知识加入到模型中,而不是在观察了数据后再把一些特性加入模型中。另外,无论是在实际操作中,还是在看论文过程中,或者是在对待自己的结果时,都要时刻保持怀疑。

