

Livy简介
我们平时提交的spark任务,通常是使用Apache Spark本身提供的spark-submit、spark-shell和Thrift Server外,Apache Livy提供了另外一种与Spark集群交互的方式,通过REST接口
此外,Apache Livy支持同时维护多个会话,可以通过REST接口、Java/Scala库和Apache Zeppelin访问Apache Livy
Livy基本架构
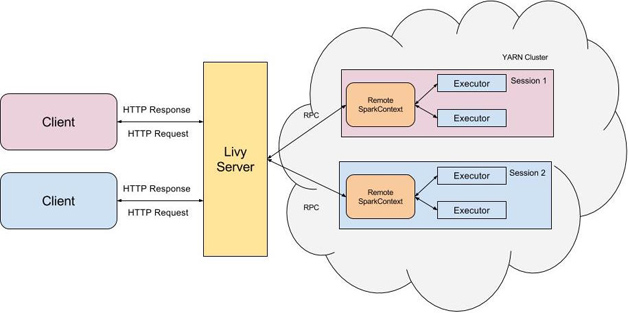
Livy是一个典型的REST服务架构,一方面接收并解析用户的REST请求,转换成相应的操作;另一方面管理着用户所启动的所有Spark集群
用户可以以REST请求方式通过Livy启动一个会话(session),一个会话是由一个spark集群所构成的,并且通过RPC协议在Spark集群和Livy服务端之间进行通信。根据处理交互方式不同,Livy将会话分为两种类型:
1.交互式会话(interactive session):跟spark的交互处理相同,在启动会话后可以接收用户所提交的代码片段,提交至远程的spark集群编译并执行
2.批处理会话(batch session):用户可以通过livy以批处理的方式启动spark应用,这样的一个方式在Livy中称之为批处理会话,与spark中的批处理是相同的
Livy部署
进入livy.apache.org/download/下载Apache Livy(注意Github有Cloudera Livy),这是两个不同的Livy,注意区分,下载成功后执行unzip解压缩即可
1.下载压缩包并解压缩
wget https://www.apache.org/dyn/closer.lua/incubator/livy/0.6.0-incubating/apache-livy-0.6.0-incubating-bin.zip
unzip apache-livy-0.6.0-incubating-bin.zip
mv apache-livy-0.6.0-incubating-bin /usr/local/livy
2.配置
cd /usr/local/livy/conf
cp livy-env.sh.template livy-env.sh
vi livy-env.sh
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop/conf
export SPARK_HOME=$SPARK_HOME
cp livy.conf.template livy.conf
vi livy.conf
livy.spark.master=yarn-client #使用yarn模式
livy.spark.deploy-mode = client
livy.repl.enable-hive-context = true
livy.server.session.kind=yarn
livy.server.recovery.mode = recovery #恢复机制
livy.server.recovery.state-store = zookeeper / filesystem #有两种保存机制,一种是文件,一种是zookeeper
livy.server.recovery.state-store.url = zookeeper_host:port
livy.file.upload.max.size=107059609600 # livy上传文件限制,默认上限是100M,当Jar包大于100M时候,会抛出异常Too large request or file
其他可选的配置有:
livy.server.host #主机地址,默认为 0.0.0.0;
livy.server.port #端口号,默认为 8998;
livy.server.session.timeout-check # 是否检测会话超时,默认为 true;
livy.server.session.timeout # 会话超时时间,默认为 1h;
livy.server.session.state-retain.sec # 已完成会话保留时间,默认为 600s;
livy.rsc.jars # RSC JAR 包位置,缓存在 HDFS 上,可以加速会话的启动速度;
livy.repl.jars # REPL JAR 包位置,缓存在 HDFS 上,可以加速会话的启动速度
livy.server.yarn.poll-interval # YARN 状态刷新频率,默认为 5s;
livy.ui.enabled # 是否启动 UI 界面,默认为 true;
3.服务启动与停止
cd /usr/local/livy/bin
./livy-server start # 启动服务
./livy-server stop # 停止服务
4.访问界面
访问页面http://bigdatatest-1:8999 # 注意:默认端口是8998,使用Ambari部署集群时的livy服务端口是8999
使用Postman测试工具了解Livy接口
Livy官文档:livy.apache.org/docs/latest…
1.新建session
post http://bigdatatest-1:8999/sessions
2.查看session状态
GET http://bigdatatest-1:8999/sessions
3.提交代码片段
POST http://bigdatatest-1:8999/sessions/130/statements
注意:如果在同一个session,提交的代码片段是共享的,相当于在同一个spark shell里面进行操作的
sesssions/130 :130这个数字是开始新建session(即第一步的结果)时得到的id值
4.查看代码运行结果
GET http://bigdatatest-1:8999/sessions/0/statements/0
注意:statements/0 :后面的0是第3步提交代码片段返回的id值
5.杀掉session
delete http://bigdatatest-1:8999/sessions/130
6.提交spark批处理任务
POST http://bigdatatest-1:8999/batches
注意:示例中使用的SparkPi例子,该jar包路径在$SPARK_HOME/examples/jars/下
7.查看Spark任务结果
GET http://bigdatatest-1:8999/batches
Livy Java API
使用Java API只需要以下几个步骤即可:
1.添加maven依赖
2.实现
org.apache.livy.Job接口3.基于URL地址构建LivyClient
4.上传依赖jar包 ---->注意如果jar包文件过大会抛出异常
5.提交Livy任务并获取结果
6.关闭客户端
1.添加mavan依赖
<dependency>
<groupId>org.apache.livy</groupId>
<artifactId>livy-client-http</artifactId>
<version>0.5.0-incubating</version>
</dependency>
2.实现Job接口
package com.ud.livy;
import org.apache.livy.Job;
import org.apache.livy.JobContext;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.*;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import scala.Tuple2;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
/**
*
* CreateTime:2019/5/31 10:50
* Descriptor:
*/
public class TestJob implements Job {
private static Logger logger = LoggerFactory.getLogger(TestJob.class);
@Override
public List<String> call(JobContext jobContext) throws Exception {
JavaRDD<String> stringJavaRDD = jobContext.sc().parallelize(Arrays.asList("hello", "are", "you", "spark", "java", "java", "spark", "hadoop"));
logger.info("样本数据:" + stringJavaRDD.first());
JavaPairRDD<String, Integer> stringIntegerJavaPairRDD = stringJavaRDD.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2<>(s, 1);
}
}).reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer integer, Integer integer2) throws Exception {
return integer + integer2;
}
});
List<Tuple2<String, Integer>> collect = stringIntegerJavaPairRDD.collect();
List<String> list = new ArrayList<>();
for (Tuple2<String,Integer> result:collect){
list.add("key:"+ result._1+" value:"+result._2);
}
return list;
}
}
3.构建Client,上传Jar包,提交作业获取结果
package com.ud.livy;
import org.apache.livy.LivyClient;
import org.apache.livy.LivyClientBuilder;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.File;
import java.net.URI;
import java.util.List;
/**
*
* CreateTime:2019/5/31 10:57
* Descriptor:
*/
public class LivyMain {
private static Logger logger = LoggerFactory.getLogger(LivyMain.class);
public static void main(String[] args) {
LivyClient client = null;
try {
client = new LivyClientBuilder()
.setURI(new URI("http://bigdatatest-1:8999"))
.setConf("spark.debug.maxToStringFields", "10000000")
.setConf("spark.sql.parquet.binaryAsString", "true")
.setConf("spark.sql.parquet.writeLegacyForma", "true")
.setConf("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.setConf("spark.kryoserializer.buffer", "256")
.setConf("spark.yarn.queue", "llap")
.setConf("spark.app.name", "sparkTestSpark")
.setConf("spark.driver.memory", "2g")
.setConf("spark.executor.memory", "5g")
.setConf("spark.executor.instances", "3")
.setConf("spark.executor.cores", "4")
.setConf("spark.default.parallelism", "500")
.build();
//注意:使用uploadJar()方法将会在每次运行程序的时候上传jar,使用addJar可加快运行速度,一般需要先把jar包上传至hdfs
client.addJar(new URI("hdfs://bigdatatest-1:8020/bigdata-backtrack-final-0.0.1-SNAPSHOT.jar"));
// client.uploadJar(new File("D:\\GitCode\\livyTest\\target\\bigdata-backtrack-final-0.0.1-SNAPSHOT.jar")).get();
List<String> results = ( List<String>) client.submit(new TestJob()).get();
System.out.println(results);
} catch (Exception e) {
logger.error("抛出异常:",e);
} finally {
if(client!=null){
client.stop(true);
}
}
}
}
4.结果展示
