需求
通过Flume日志采集收集工具对其他服务器上产生的日志进行采集,并按照时间天数对日志进行切割,然后下发到HDFS中
A服务器需做的事情
- 1、通过脚本产生日志
[root@node01 home]
while true
do
echo 'timetime'>>/home/flume.log
sleep 5
done
- 2、给脚本加执行权限
[root@node01 home]# chmod 755 makeLog.sh
- 3、在后台启动脚本
[root@node01 home]# sh makeLog.sh &
- 4、监控末尾10行日志文件
[root@node01 home]# tail -10f flume.log
- 5、进入flume的conf目录下编写配置文件
[root@node02 conf]
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = exec
a1.sources.r1.command =tail -F /home/flume.log
a1.sources.r1.shell = /bin/sh -c
a1.sinks.k1.type = avro
a1.sinks.k1.hostname=192.168.52.100
a1.sinks.k1.port = 44444
a1.channels.c1.type = memory
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
B服务器需做的事情
- 1、进入flume的conf目录下编写配置文件
[root@node01 conf]
b1.sources = r2
b1.sinks = k2
b1.channels = c2
b1.sources.r2.type = avro
b1.sources.r2.bind=192.168.52.100
b1.sources.r2.port = 44444
b1.sinks.k2.type = hdfs
b1.sinks.k2.channel = c2
b1.sinks.k2.hdfs.path = /flume/%Y-%m/%m-%d/
b1.sinks.k2.hdfs.filePrefix = %Y-%m-%d
b1.sinks.k2.hdfs.fileType = DataStream
b1.sinks.k2.hdfs.useLocalTimeStamp = true
b1.channels.c2.type = memory
b1.channels.c2.capacity = 1000
b1.channels.c2.transactionCapacity = 100
b1.sources.r2.channels = c2
b1.sinks.k2.channel = c2
flume-ng agent -c conf -f b-hdfs.properties -n b1 -Dflume.root.logger=INFO,console
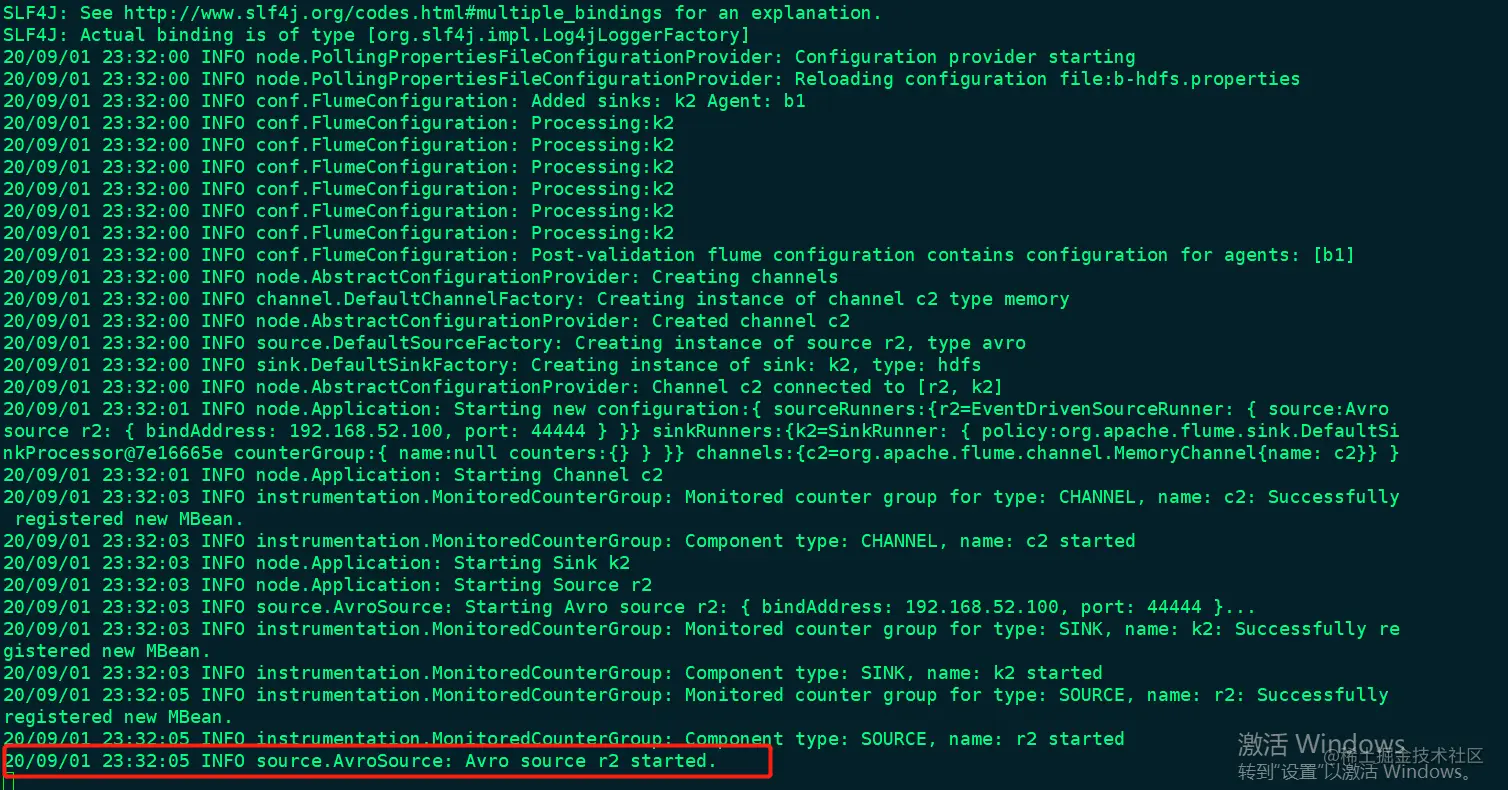
此图中的红框标志B服务器启动flume成功
flume-ng agent -c conf -f a-b.properties -n a1 -Dflume.root.logger=INFO,console
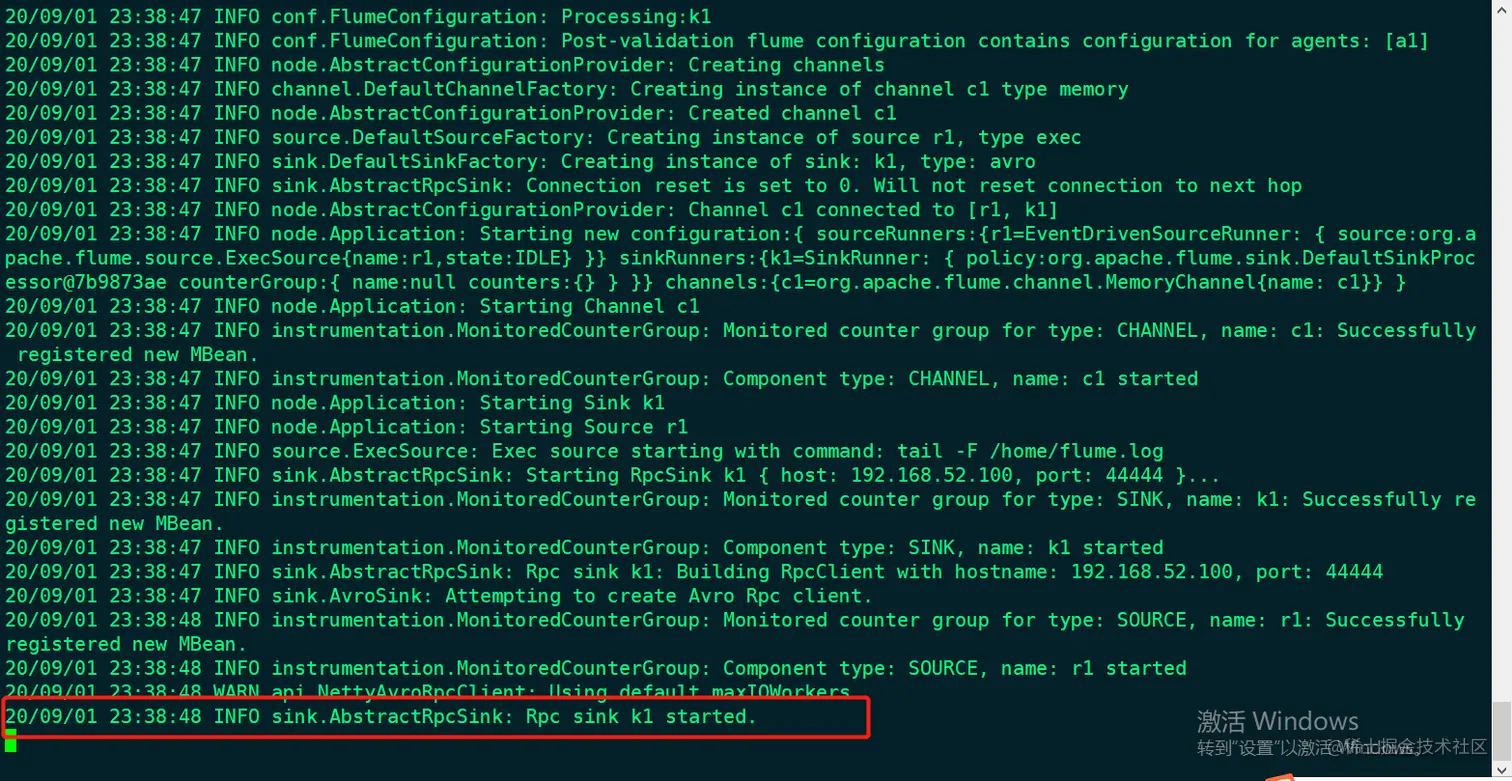
此图中的红框标志A服务器启动flume成功
查看HDFS目录
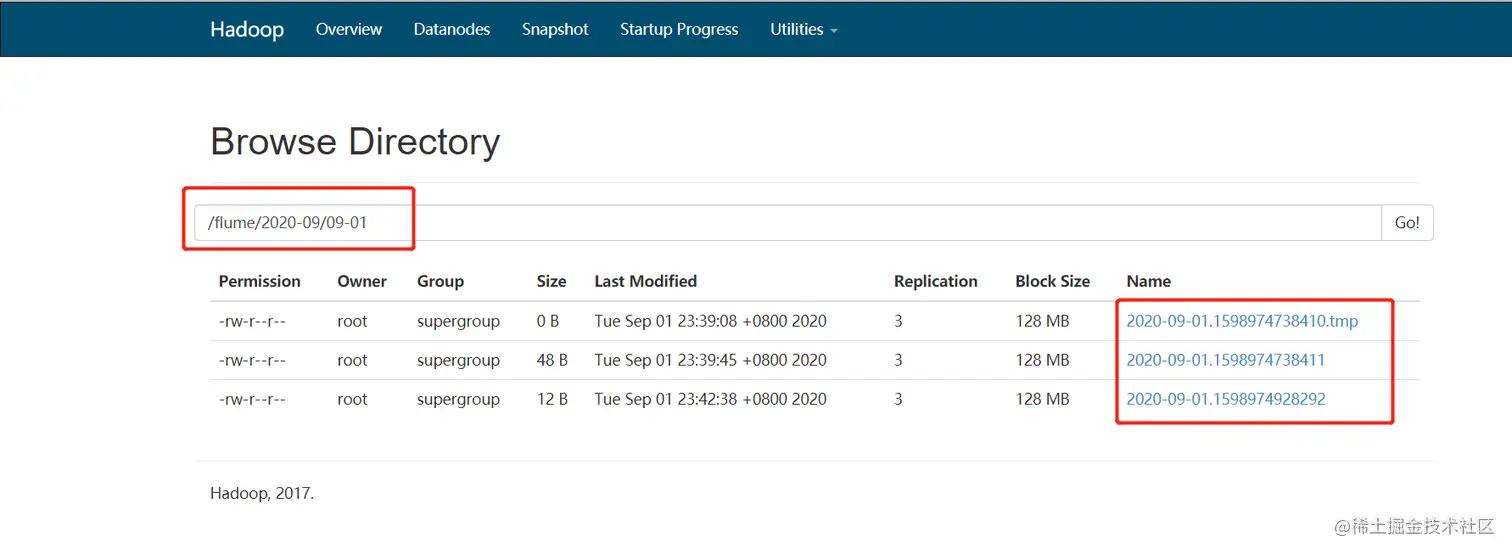
发现成功采集数据,并且按照时间天数进行分区


