

一、缓存穿透
1. 什么是缓存穿透?
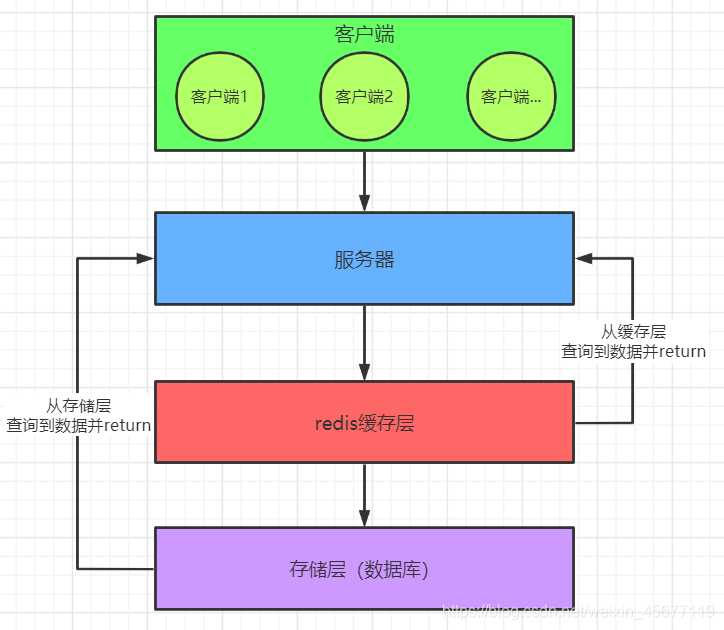
为了缓解持久层数据库的压力,在服务器和存储层之间添加了一层缓存;
一个简单的正常请求:当客户端发起请求时,服务器响应处理,会先从redis缓存层查询客户端需要的请求数据,如果缓存层有缓存的数据,会将数据返回给服务器,服务器在返回给客户端;如果缓存层中没有客户端需要的数据,则会去底层存储层查找,再返回给服务器;
缓存穿透就是:当客户端想要查询一个数据,发现redis缓存层中没有(即缓存没有命中),于是向持久层数据库查询,发现也没有,于是本次查询失败;当用户很多的时候,缓存都没有命中,于是都去请求了持久层数据库,此时会给持久层数据库造成很大的压力,这时候就相当于出现了缓存穿透。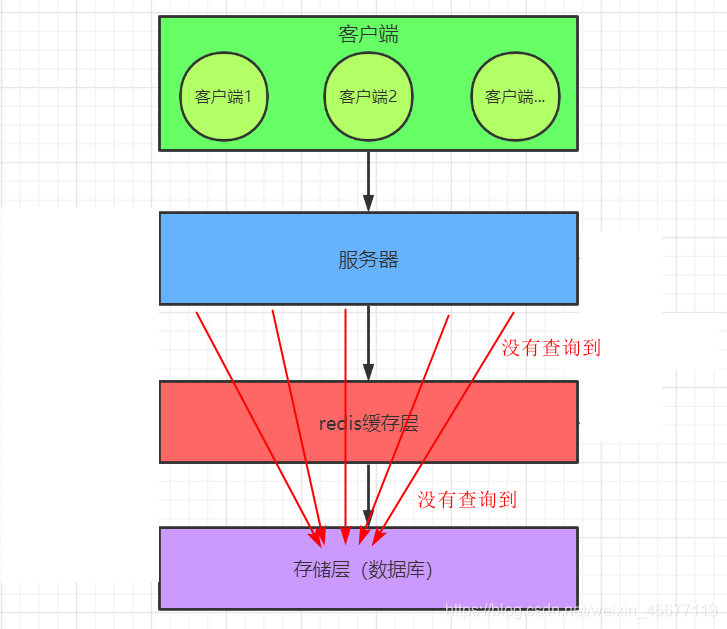
2. 解决办法
- 在缓存层加布隆过滤器,通俗简述一下其作用:将数据库中的 id ,通过某方式映射到布隆过滤器,当处理不存在的 id 时,布隆过滤器会将该请求过直接过滤出去,不会到数据库做操作。
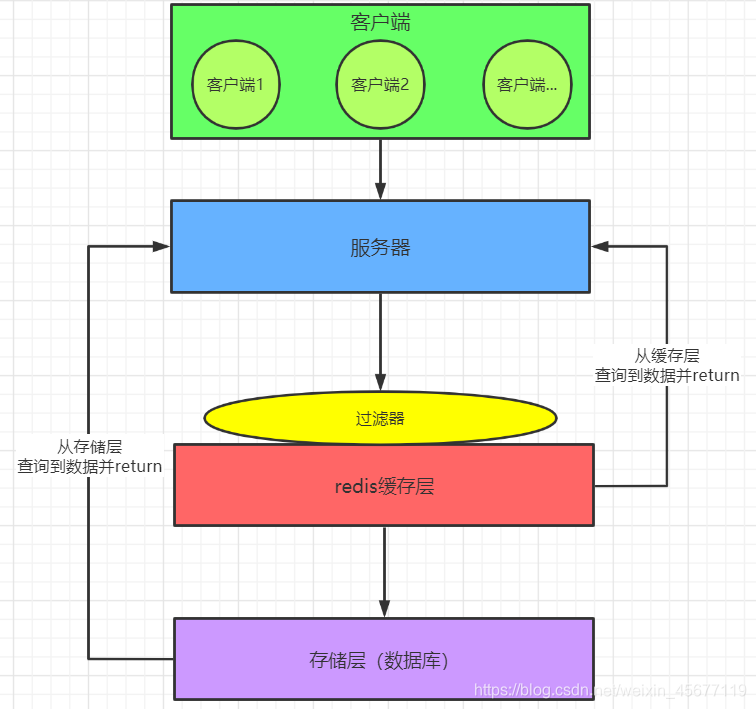
3. 布隆过滤器
1)概述:布隆过滤器是一种数据结构,比较巧妙的概率型数据结构,实际上是一个很长的二进制向量和一系列随机映射函数,特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”,相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
2)返回结果的不确切性:
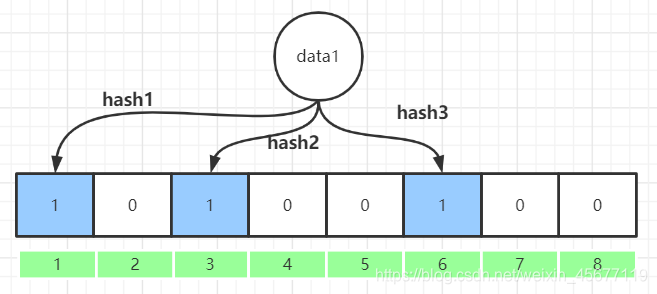
布隆过滤器是一个 bit 向量或者说 bit 数组:假设有8位
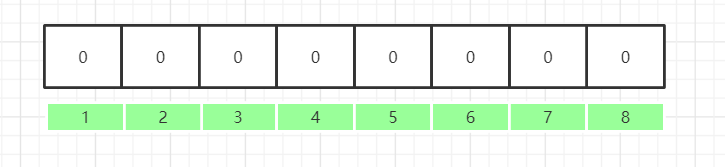
映射数据1:使用多个不同的哈希函数生成多个哈希值,并对每个生成的哈希值指向的 bit 位置为 1,比如三次hash完后,data1 将1、3、6位,置为1;
映射数据2:data2 将2、3、6位,置为1,此时由于hash为随机性,所以6位和 data1 有重复的,便会覆盖 data1 的第6位的1;
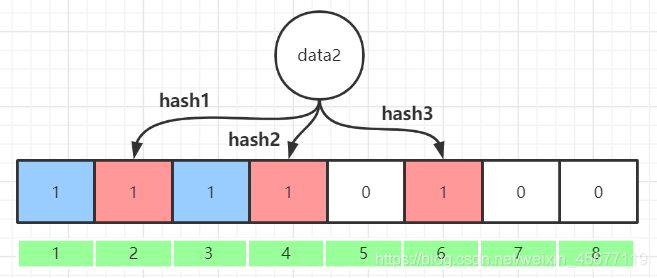
问题来了!!
6 这个 bit 位由于两个值的哈希函数都返回了这个 bit 位,因此它被覆盖了,当我们如果想查询 data3这个值是否存在,假设哈希函数返回了 1、5、6三个值,结果我们发现 5 这个 bit 位上的值为 0,说明没有任何一个值映射到这个 bit 位上,因此我们可以很确定地说 data3 这个值不存在。而当我们需要查询 data1 这个值是否存在的话,那么哈希函数必然会返回 1、3、6,然后我们检查发现这三个 bit 位上的值均为 1,那么我们是否可以说 data1 存在了么?答案是不可以,只能是 data1 这个值可能存在!因为随着增加的值越来越多,被置为 1 的 bit 位也会越来越多,这样某个值 data4 即使没有被存储过,但是万一哈希函数返回的三个 bit 位都被其他值置位了 1 ,那么程序还是会判断 data4 这个值存在。
- 所以:布隆过滤器的长度会直接影响误报率,布隆过滤器越长其误报率越小。
3)简单剖析布隆过滤器源码
导入guava的包:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>23.0</version>
</dependency>
源码:
BloomFilter一共四个create方法,最终都是走向第四个方法;
public static <T> BloomFilter<T> create(Funnel<? super T> funnel, int expectedInsertions) {
return create(funnel, (long) expectedInsertions);
}
public static <T> BloomFilter<T> create(Funnel<? super T> funnel, long expectedInsertions) {
return create(funnel, expectedInsertions, 0.03); // FYI, for 3%, we always get 5 hash functions
}
public static <T> BloomFilter<T> create(
Funnel<? super T> funnel, long expectedInsertions, double fpp) {
return create(funnel, expectedInsertions, fpp, BloomFilterStrategies.MURMUR128_MITZ_64);
}
static <T> BloomFilter<T> create(
Funnel<? super T> funnel, long expectedInsertions, double fpp, Strategy strategy) {
......
}
参数类型:funnel:数据类型;expectedInsertions:期望插入的值的个数;fpp:错误率(默认值为0.03);strategy:哈希算法。
总结:错误率越大,所需空间和时间越小;反之错误率越小,所需空间和时间越大!
二、缓存击穿
1. 什么是缓存击穿?
缓存击穿,是指一个 key 非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,造成击穿,就像在一堵墙上凿开了一个洞;比如微博热搜…
2. 解决办法
1)设置热点数据缓存没有过期时间,但当热点平稳一阵后,会造成一些空间浪费;
2)加互斥锁:使用分布式锁,保证每一个key只有一条线程访问,其他线程等待,但对分布锁考验很大。
三、缓存雪崩
1. 什么是缓存雪崩?
缓存雪崩是指:某一时间段,缓存集中过期失效,即缓存层出现了错误,不能正常工作了;于是所有的请求都会达到存储层,存储层的调用量会暴增,造成 “雪崩”;
比如:双十二临近12点,抢购商品,此时会设置商品在缓存区,设置过期时间为1小时,当到了1点时,缓存过期,所有的请求会落到存储层,此时数据库可能扛不住压力,自然 “挂掉”。
2. 解决办法
- redis高可用
这个思想的含义是,既然redis有可能挂掉,那我多增设几台redis,这样一台挂掉之后其他的还可以继续工作,其实就是搭建的集群。 - 限流降级
这个解决方案的思想是,在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。 - 数据预热
数据预热的含义就是在正式部署之前,我先把可能的数据先预先访问一遍,这样部分可能大量访问的数据就会加载到缓存中,在即将发生大并发访问前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。
