

前言
第一次接触跳表就是在 16 年的时候,那时候看《Redis 设计与实现》了解到了跳表,当时还参考了其他的代码用 php 实现了一份。
这次巧了,又一次是看 redis 相关的东西又一次看到了跳表,于是我就找以前的代码,可是找不到了,那么干脆就在实现一次好了
目标
由于之前是参考代码,我觉得理解的并不是很深,尤其是为什么要用那些属性,为什么没有就不行呢?所以这次我参考了比较偏理论的文章 跳表──没听过但很犀利的数据结构,没有任何代码,事后全部靠自己思考来实现出来。
Let's Go
先来个图
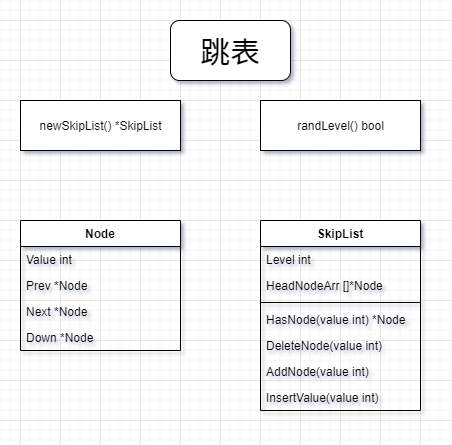
如果是自己摸索就比参照代码来的麻烦的多,我让自己完全忘记全部的东西,当作一个小白来从头思考跳表。
那么跳表是由什么组成的呢? 一个多层的跳表。 那么层数是怎么决定的?通过抛硬币来提升层数,层数只能比当前层数高一层,但是不能超过预设的最高值。 好了,那么跳表的接口出来了,有一个层高,有一个存储各层头节点的数组。目前来看够了。
那么节点都有什么呢? 存储值,前置节点,后置节点,下层节点,够了,因为我们只有向下查找,并没有向上,所以也够了
好了,再说跳表存储头节点的数组,头节点的我这边存了一个空Node,其实也可以不用空Node,在我看来怎么都可以的。
直接上代码
package main
import (
"fmt"
"math/rand"
"strconv"
"time"
)
const MaxLevel = 7
type Node struct {
Value int // 存储值
Prev *Node // 同层前节点
Next *Node // 同层后节点
Down *Node // 下层同节点
}
type SkipList struct {
Level int
HeadNodeArr []*Node
}
// 是否包含节点
func (list SkipList) HasNode(value int) *Node {
if list.Level >= 0 {
// 只有层级在大于等于 0 的时候在进行循环判断,如果层级小于 0 说明是没有任何数据
level := list.Level
node := list.HeadNodeArr[level].Next
for node != nil {
if node.Value == value {
// 如果节点的值 等于 传入的值 就说明包含这个节点 返回 true
return node
} else if node.Value > value {
// 如果节点的值大于传入的值,就应该返回上个节点并进入下一层
if node.Prev.Down == nil {
if level - 1 >= 0 {
node = list.HeadNodeArr[level - 1].Next
} else {
node = nil
}
} else {
node = node.Prev.Down
}
level -= 1
} else if node.Value < value {
// 如果节点的值小于传入的值就进入下一个节点,如果下一个节点是 nil,说明本层已经查完了,进入下一层,且从下一层的头部开始
node = node.Next
if node == nil {
level -= 1
if level >= 0 {
// 如果不是最底层继续进入到下一层
node = list.HeadNodeArr[level].Next
}
}
}
}
}
return nil
}
// 删除节点
func (list *SkipList) DeleteNode(value int) {
// 如果没有节点就删除
node := list.HasNode(value)
if node == nil {
return
}
// 如果有节点就删除
for node != nil {
prevNode := node.Prev
nextNode := node.Next
prevNode.Next = nextNode
if nextNode != nil {
nextNode.Prev = prevNode
}
node = node.Down
}
}
// 添加数据到跳表中
func (list *SkipList) AddNode(value int) {
if list.HasNode(value) != nil {
// 如果包含相同的数据,就返回,不用添加了
return
}
headNodeInsertPositionArr := make([]*Node, MaxLevel)
// 如果不包含数据,就查找每一层的插入位置
if list.Level >= 0 {
// 只有层级在大于等于 0 的时候在进行循环判断,如果层级小于 0 说明是没有任何数据
level := list.Level
node := list.HeadNodeArr[level].Next
for node != nil && level >= 0 {
if node.Value > value {
// 如果节点的值大于传入的值,就应该返回上个节点并进入下一层
headNodeInsertPositionArr[level] = node.Prev
if node.Prev.Down == nil {
if level - 1 >= 0 {
node = list.HeadNodeArr[level - 1].Next
} else {
node = nil
}
}else {
node = node.Prev.Down
}
level -= 1
} else if node.Value < value {
// 如果节点的值小于传入的值就进入下一个节点,如果下一个节点是 nil,说明本层已经查完了,进入下一层,且从下一层的头部开始
if node.Next == nil {
headNodeInsertPositionArr[level] = node
level -= 1
if level >= 0 {
// 如果不是最底层继续进入到下一层
node = list.HeadNodeArr[level].Next
}
} else {
node = node.Next
}
}
}
}
list.InsertValue(value, headNodeInsertPositionArr)
}
func (list *SkipList) InsertValue(value int, headNodeInsertPositionArr []*Node) {
// 插入最底层
node := new(Node)
node.Value = value
if list.Level < 0 {
// 如果是空的就插入最底层数据
list.Level = 0
list.HeadNodeArr[0] = new(Node)
list.HeadNodeArr[0].Next = node
node.Prev = list.HeadNodeArr[0]
} else {
// 如果不是空的,就插入每一层
// 插入最底层,
rootNode := headNodeInsertPositionArr[0]
nextNode := rootNode.Next
rootNode.Next = node
node.Prev = rootNode
node.Next = nextNode
if nextNode != nil {
nextNode.Prev = node
}
currentLevel := 1
for randLevel() && currentLevel <= list.Level+1 && currentLevel < MaxLevel {
// 通过摇点 和 顶层判断是否创建新层,顶层判断有两种判断,一、不能超过预定的最高层,二、不能比当前层多出过多层,也就是说最多只能增加1层
if headNodeInsertPositionArr[currentLevel] == nil {
rootNode = new(Node)
list.HeadNodeArr[currentLevel] = rootNode
} else {
rootNode = headNodeInsertPositionArr[currentLevel]
}
nextNode = rootNode.Next
upNode := new(Node)
upNode.Value = value
upNode.Down = node
upNode.Prev = rootNode
upNode.Next = nextNode
rootNode.Next = upNode
if nextNode != nil {
nextNode.Prev = node
}
node = upNode
// 增加层数
currentLevel++
}
list.Level = currentLevel - 1
}
}
// 通过抛硬币决定是否加入下一层
func randLevel() bool {
randNum := rand.Intn(2)
if randNum == 0 {
return true
}
return false
}
// 初始化跳表
func newSkipList() *SkipList {
list := new(SkipList)
list.Level = -1 // 设置层级别
list.HeadNodeArr = make([]*Node, MaxLevel) // 初始化头节点数组
rand.Seed(time.Now().UnixNano())
return list
}
func printSkipList(list *SkipList) {
fmt.Println("====================start===============" + strconv.Itoa(list.Level))
for i := list.Level; i >= 0; i-- {
node := list.HeadNodeArr[i].Next
for node != nil {
fmt.Print(strconv.Itoa(node.Value) + " -> ")
node = node.Next
}
fmt.Println()
}
fmt.Println("====================end===============")
}
func main() {
list := newSkipList()
list.AddNode(5)
list.AddNode(1)
list.AddNode(7)
list.AddNode(2)
list.AddNode(-2)
list.AddNode(-0)
list.AddNode(-10)
printSkipList(list)
fmt.Println(list.HasNode(0))
fmt.Println(list.HasNode(100))
list.DeleteNode(1)
printSkipList(list)
}
简单说一说
其实整体来说就是跳表的操作,难点就是切换层,如何走向下层需要仔细考虑一下
剩下的看注释吧,我觉得很细致了
总结
还是菜啊,如果不是自己这次用了很久的时间才想明白如何写代码,我以前一直以为自己很了解跳表了呢,不过这次写的很爽。 这是个自己实现的,我也不知道自己实现的如何,等过一阵去极客时间看看数据结构课程的跳表是如何实现的,在加深一次
不如来这关注我一波

