


本文来自飞猪前端美少女@清锁同学,最近使用 Puppeteer 进行前端页面检测的探索,梳理成文分享给大伙!
Puppeteer 是一个 Node 库,它提供了一个高级 API 来通过 DevTools 协议控制 Chromium 或 Chrome。在H5页面检测中可以通过Puppeteer的提供的api直接控制Chrome模拟用户操作来进行UI Test或者作为爬虫访问页面来收集数据加以使用。针对任意页面检测,我们的检测内容如下图所示:
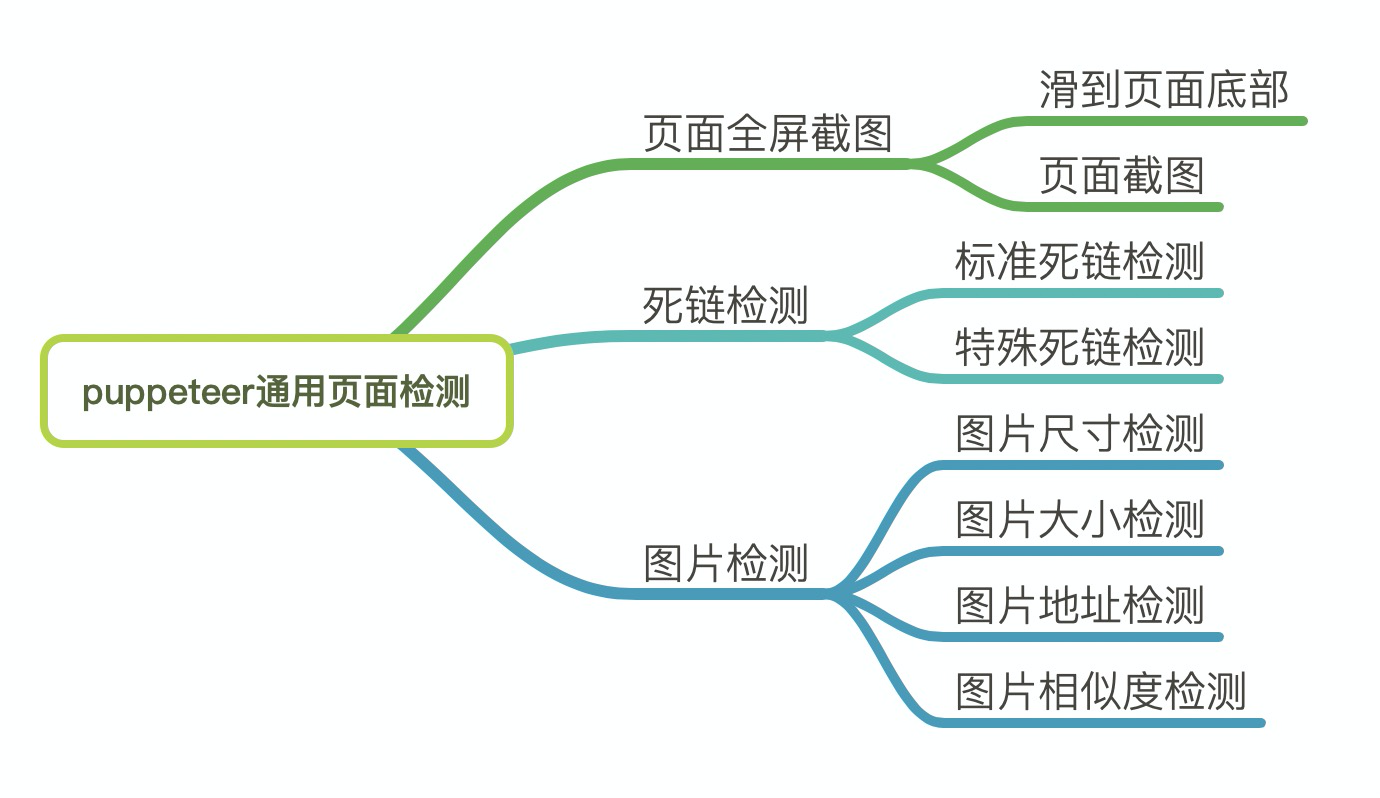
页面全屏截图
在页面检测中,需要使用puppeteer获取页面全屏截图,即包含页面滚动部分。根据官网提供的官网的demo 以及API pagescreenshot API,本以为简单几行代码就可以搞定,于是写了第一版demo。
const puppeteer = require('puppeteer');
const iPhone = puppeteer.devices['iPhone 6'];
const url = 'https://h5.m.taobao.com/trip/home/index.html';
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.emulate(iPhone); // 生成 iPhone 6 模拟器
await page.goto(url, { waitUntil: ['networkidle0'] }); // networkidle2 会一直等待,直到页面加载后同时没有存在 2 个以上的资源请求,这个种状态持续至少 500 ms
await page.screenshot({path: 'pics/demo1.png', fullPage: true});
await browser.close();
})();
结果截图如下所示:

问:为何没有截全屏
试了几个页面都只截首屏的图片,然后看下这几个页面的页面结构,发现这些页面的body高度或者为0,或者等于视口高度。
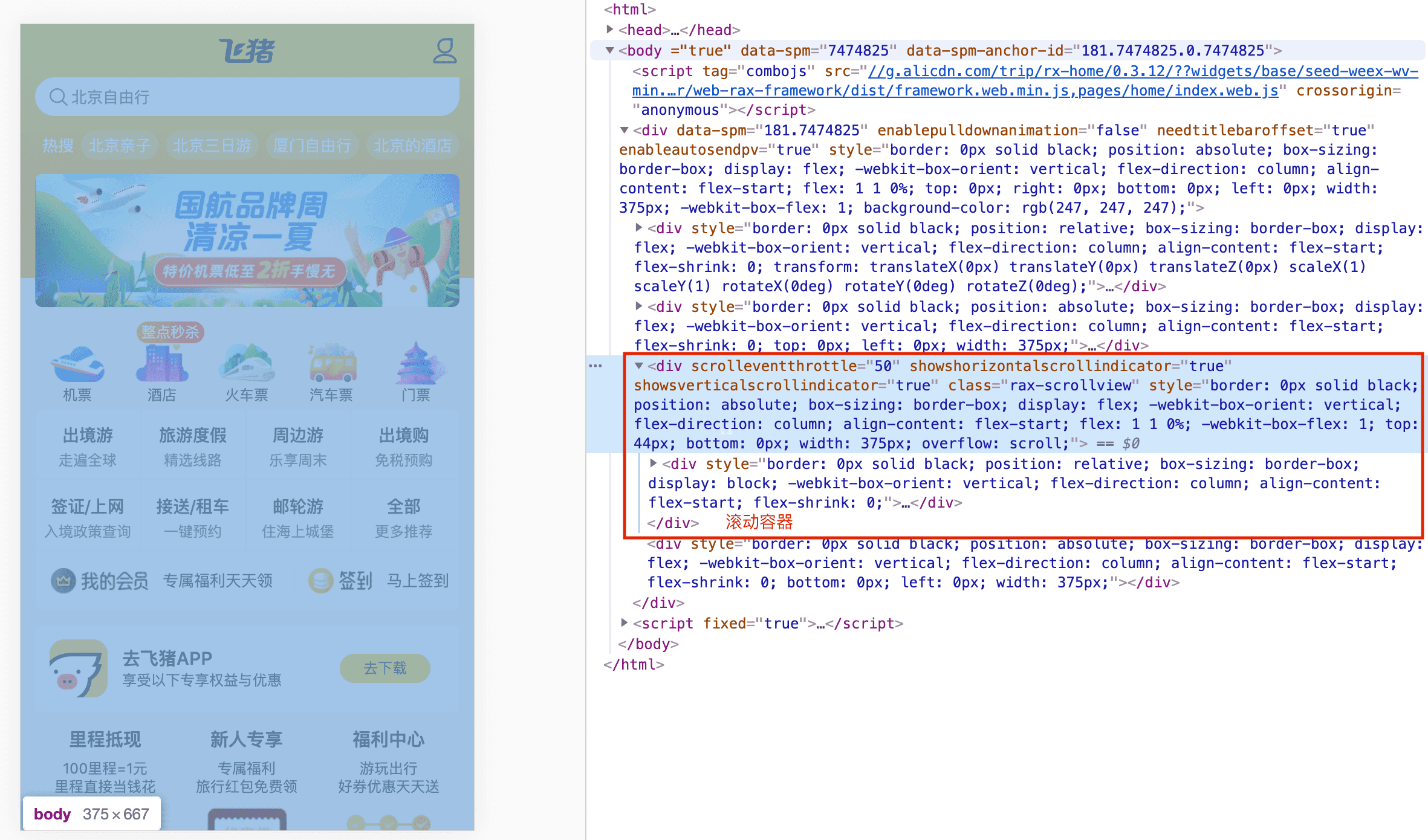
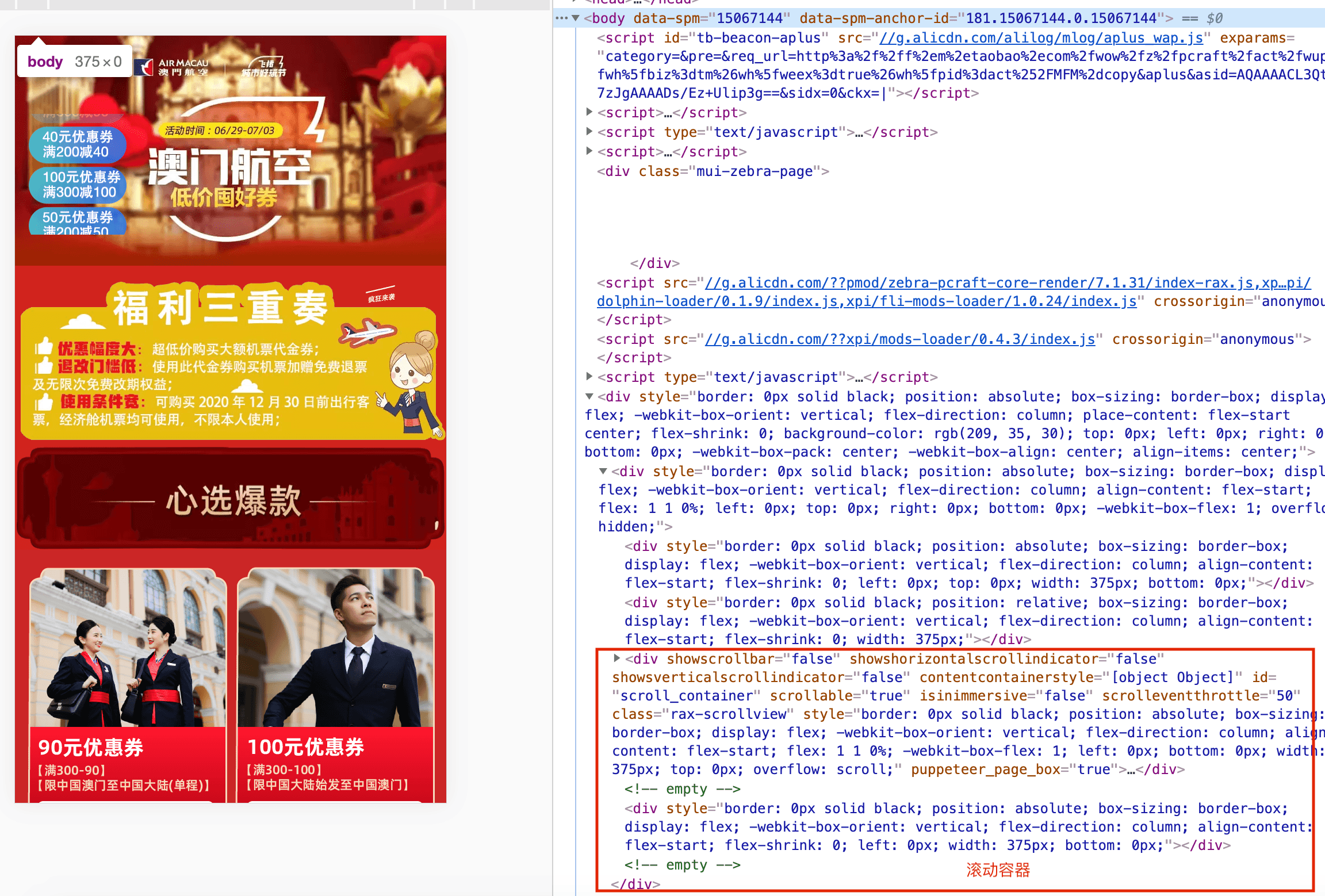
fullPage参数为true是对完整的页面viewport截图,针对页面需要滚动的部分也会截图。但若页面高度等于视口高度或者页面高度为0,则只会截取首屏图片。
看下fullPage为true针对页面超出视口高度的场景及其对应的截图:


滚动元素截屏
查看了各个页面的特点,发现了共同点:即滚动容器元素的scrollHeight一定大于视口高度。通过page.evaluate方法遍历所有div节点,找到一个scrollHeight大于视口高度的节点,将其标记为滚动节点。如果所有元素节点的scrollHeight都不大于视口高度,则body为滚动节点。
await page.evaluate(() => {
const clientHeight = document.documentElement.clientHeight;
const divs = [...document.querySelectorAll('div')];
const len = divs.length;
let boxEl = null;
let i = 0;
for(; i < len; i++) {
const div = divs[i];
if(div.scrollHeight > clientHeight) {
boxEl = div;
break;
}
}
if(!boxEl && i === len) {
boxEl = document.querySelector('body');
}
boxEl.setAttribute('id', 'Puppeteer_Page_Box');
});
const scrollableSectionEl = await page.$('#Puppeteer_Page_Box');
// 针对元素截屏
await scrollableSectionEl.screenshot({
path: 'pics/demo2.png',
fullPage: true,
});
此时报错  screenshot的参数fullPage和clip只能用一个,元素使用fullPage时,会同时给clip设置默认值
screenshot的参数fullPage和clip只能用一个,元素使用fullPage时,会同时给clip设置默认值clip = { x: 0, y: 0, width, height, scale: 1 }; ,导致报错。因此针对元素截图不能使用fullPage:true,需要设置指定裁剪区域。
const bounding_box = await scrollableSectionEl.boundingBox();
await scrollableSectionEl.screenshot({
path: 'pics/demo22.png',
clip: bounding_box,
});
滑到页面底部
此时截图仍然不是全部页面。大多页面都是懒加载渲染,需要一直滚动页面直到到达页面底部,然后再截图。需要注意的点:页面加载中需要获取接口,根据接口返回渲染页面。此时定时器时间应该大于接口返回时间,否则最后截图仍是未完全加载页面
await page.evaluate(async (scrollableSectionEl, deviceHeight = 667) => {
await new Promise((resolve, reject) => {
let totalHeight = 0;
let times = 0;
const timer = setInterval(() => {
times++;
const scrollHeight = scrollableSectionEl.scrollHeight;
scrollableSectionEl.scrollBy(0, deviceHeight);
totalHeight = totalHeight + deviceHeight;
// 设定最多加载10屏,
if(times > 10 || totalHeight >= scrollHeight){
clearInterval(timer);
resolve();
}
}, 2000); // 设定页面加载接口在2s内返回
});
}, scrollableSectionEl, deviceHeight);
// 获取滚动容器的scrollHeight值
const scrollHeight = await page.$eval('#Puppeteer_Page_Box', el => el.scrollHeight);
const bounding_box = await scrollableSectionEl.boundingBox();
await scrollableSectionEl.screenshot({
path: 'pics/demo3.png',
clip: {
x: bounding_box.x,
y: bounding_box.y,
height: scrollHeight, // 滚动元素截图高度为scrollHeight值
width: deviceWidth,
},
});
此时页面截图:

只截取了最后一屏页面截图,整个scrollHeight剩下部分全部为空白。。。
虽然是调用元素截图,但是截图针对视口的。我们在设置元素截图的高度之前需要设置页面视口高度,保证页面视口大小等于元素截图高度。
await page.setViewport({
height: scrollHeight,
width: deviceWidth,
deviceScaleFactor: 2,
isMobile: true,
hasTouch: true,
isLandscape: false,
});
const bounding_box = await scrollableSectionEl.boundingBox();
await scrollableSectionEl.screenshot({
path: 'pics/demo4.png',
clip: {
x: bounding_box.x,
y: bounding_box.y,
height: scrollHeight,
width: deviceWidth,
},
});
此时页面截图:

死链检测
在页面检测中,检验页面里是否存在“死链”是非常重要的。死链包括协议死链和内容死链两种形式。协议死链:页面的TCP协议状态/HTTP协议状态明确表示的死链,常见的如404、403、503状态等。内容死链:服务器返回状态是正常的,但内容已经变更为不存在、已删除或需要权限等与原内容无关的信息页面。针对我们的场景,只要用户不可正常访问的链接都认为是“死链”。由于前面截图时已经将页面滑到底部,就确保我们能够获取到页面所有内容。
标准死链检测
const standardLinks = await page.evaluate(() => {
const els = [...document.querySelectorAll("a[href*='//']")];
return els.map(el => {
return el.href.trim();
})
});
const badLinks = []; // 死链集合
for(const link of standardLinks) {
const res = await page.goto(link);
const status = res.status();
if(status >= 400) { // 针对用户不可正常访问的链接认为是死链
badLinks.push(link);
}
}
特殊死链检测
针对大多数页面,通用死链检测已经能覆盖了。由于页面的多样性,历史原因等,很多链接不是直接写在链接元素上的,而是点击后调用js跳转。针对这种情况,需要识别这部分元素模拟点击操作,获取跳转链接。依据指定规则拿到所有的可跳转元素后,需要挨个执行点击操作,调用page.waitForNavigation方法等待新地址加载后再返回到检测页面。针对符合点击跳转规则的元素,但触发点击事件无需跳转时,调用page.waitForNavigation方法会导致打开新页面的超时错误,此时应忽略该错误继续往下触发点击跳转。
const tapLinks = []; // 所有点击跳转的链接
const visitLink = async (index = 0) => {
try {
const links = await page.$$("[data-click]:not([href*='//'])"); // 获取所有符合点击跳转规则的元素,根据页面实际情况定义选择器
if (links[index]) {
await links[index].tap(); // 模拟点击
await page.waitForNavigation({ // 等待加载新页面地址
timeout: 5000, // 新地址超时时间
waitUntil: 'load'
});
const currentPage = await page.url();
tapLinks.push(currentPage);
await page.goBack({ waitUntil: "networkidle0" }); // 返回到原先的检测页面
return visitLink(index + 1); // 继续检测下一个可点击元素
}
} catch(err) {
await visitLink(index + 1); // 对于不含页面跳转的点击元素,会导致超时报错,此时可直接进入下一个模拟点击
}
};
await visitLink();
通过上述操作,可以获得所有点击跳转的链接地址,如下图所示
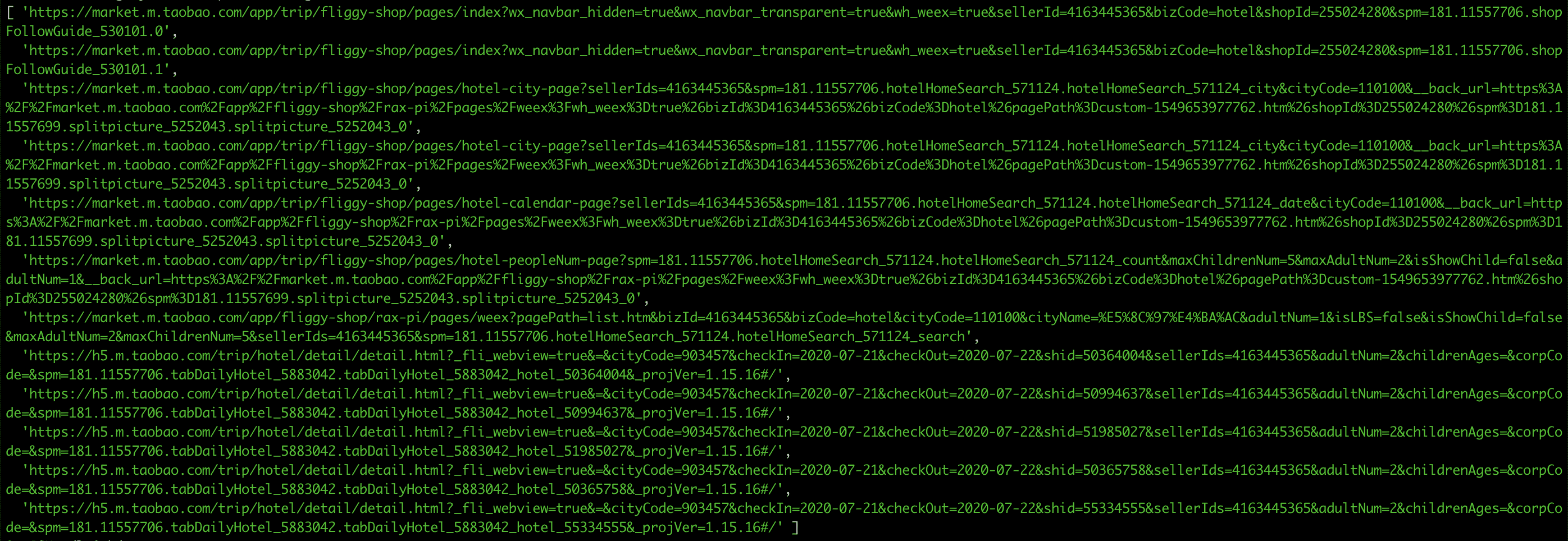
通用死链检测
通过标准死链检测获取到所有a标签跳转的链接地址,通过特殊死链检测获取到所有点击元素js打开的链接地址,我们可以拿到页面上所有的链接地址。循环遍历打开链接地址,根据响应状态判断是否为用户不可正常访问的链接。
const badLinks = []; // 死链集合
const totalLinks = tapLinks.concat(standardLinks);
for(const link of totalLinks) {
const res = await page.goto(link);
const status = res.status();
if(status >= 400) {
badLinks.push(link);
}
}
图片检测
页面检测中图片检测是非常重要的一环,我们默认通用图片检测为:图片大小检测、图片压缩检测、图片尺寸检测、图片相似度检测。
获取img图片大小&尺寸
const imgInfoList = await page.evaluate(async () => {
const imgs = [...document.querySelectorAll('img')]; // 获取所有图片
const promises = imgs.map(async img => {
const size = '...'; // 获取图片字节大小,参见下文
return {
src: img.src, // 图片地址
width: img.width, // 图片渲染宽度
height: img.height, // 图片渲染高度
naturalWidth: img.naturalWidth, // 图片固有宽度
naturalHeight: img.naturalHeight, // 图片固有高度
size, // 图片字节大小
};
});
const list = await Promise.all(promises);
return list;
});
获取背景图
页面使用图片的渲染方式不同,除了常规img标签引入图片外,很多图片以背景图的方式展示。如图所示

const bgImgInfoList = await page.evaluate(async () => {
let bgImgs = [...document.querySelectorAll('div[placeholder]')]; // 依赖页面规则获取所有可能背景图的元素,根据页面实际情况定义选择器
async function getBackgroundSize(elem) {
var computedStyle = getComputedStyle(elem),
image = new Image(),
src = computedStyle.backgroundImage.replace(/url\((['"])?(.*?)\1\)/gi, '$2'), // 背景图片地址
cssSize = computedStyle.backgroundSize,
elemW = parseInt(computedStyle.width.replace('px', ''), 10),
elemH = parseInt(computedStyle.height.replace('px', ''), 10),
elemDim = [elemW, elemH],
computedDim = [],
ratio;
image.src = src;
ratio = image.width > image.height ? image.width / image.height : image.height / image.width;
cssSize = cssSize.split(' ');
computedDim[0] = cssSize[0];
computedDim[1] = cssSize.length > 1 ? cssSize[1] : 'auto';
const size = '...'; // 获取图片字节大小,参见下文
// 获取图片渲染尺寸大小
if(cssSize[0] === 'cover') {
if(elemDim[0] > elemDim[1]) {
if(elemDim[0] / elemDim[1] >= ratio) {
computedDim[0] = elemDim[0];
computedDim[1] = 'auto';
} else {
computedDim[0] = 'auto';
computedDim[1] = elemDim[1];
}
} else {
computedDim[0] = 'auto';
computedDim[1] = elemDim[1];
}
} else if(cssSize[0] === 'contain') {
if(elemDim[0] < elemDim[1]) {
computedDim[0] = elemDim[0];
computedDim[1] = 'auto';
} else {
if(elemDim[0] / elemDim[1] >= ratio) {
computedDim[0] = 'auto';
computedDim[1] = elemDim[1];
} else {
computedDim[1] = 'auto';
computedDim[0] = elemDim[0];
}
}
} else {
for(var i = cssSize.length; i--;) {
if (cssSize[i].indexOf('px') > -1) {
computedDim[i] = cssSize[i].replace('px', '');
} else if (cssSize[i].indexOf('%') > -1) {
computedDim[i] = elemDim[i] * (cssSize[i].replace('%', '') / 100);
}
}
}
return {
src, // 图片地址
size, // 图片字节大小
width: computedDim[0], // 图片渲染宽度
height: computedDim[1], // 图片渲染高度
naturalWidth: image.naturalWidth, // 图片固有宽度
naturalHeight: image.naturalHeight, // 图片固有高度
};
}
const promises = bgImgs.map(async el => {
return await getBackgroundSize(el);
});
const list = await Promise.all(promises);
return list;
});
});
获取图片字节大小
获取base64图片大小
上述获取图片字节大小的方式无法获取base64图片的字节大小,针对base64图片需要单独处理。我们先来了解下base64图片的编码原理。 Base64编码要求把3个8位字节(38=24)转化为4个6位的字节(46=24),之后在6位的前面补两个0,形成8位一个字节的形式。 如果剩下的字符不足3个字节,则用0填充,输出字符使用’=’,因此编码后输出的文本末尾可能会出现1或2个’=’。通过base64编码原理我们知道,base64的图片字符流中的每8个字符就有两个是用0补充,而且字符流的末尾还可能存在‘=’号。
// 需要计算文件流大小,首先把头部的'data:image/png;base64,'去掉
let str = src.replace(/^\s*data:image\/(png|gif|jpg|jpeg);base64,/, '');
const equalIndex = str.indexOf('=');
if (str.indexOf('=') > 0) {
str = str.substring(0, equalIndex); // 获取=前的内容
}
const strLength = str.length;
size = parseInt(strLength - (strLength / 8) * 2); // base64图片字节大小
获取普通图片大小
const res = await fetch(src, {
method: 'HEAD'
});
size = res.headers.get('content-length');
最终代码
const base64Reg = /^\s*data:([a-z]+\/[a-z0-9-+.]+(;[a-z-]+=[a-z0-9-]+)?)?(;base64)?,([a-z0-9!$&',()*+;=\-._~:@\/?%\s]*?)\s*$/i;
const isBase64 = base64Reg.test(src);
let size = 0;
if(isBase64){
let str = src.replace(/^\s*data:image\/(png|gif|jpg);base64,/, '');
const equalIndex = str.indexOf('=');
if (str.indexOf('=') > 0) {
str = str.substring(0, equalIndex);
}
const strLength = str.length;
size = parseInt(strLength - (strLength / 8) * 2);
} else {
const res = await fetch(src, {
method: 'HEAD'
});
size = res.headers.get('content-length');
}
图片大小 & 尺寸检测
图片大小检测标准
- 图片过大会导致网络请求耗时增加,使用户等待交互的时间过长,针对普通图片检测标准为:单个图片大小要小于50KB。
- base64图片过大会导致css体积过大,css过大直接影响页面渲染,因此针对base64图片检测标准为:单个图片大小要小于5KB
图片尺寸检测标准
图片太大而有效显示区域较小时会增加内存的消耗,应根据显示区域大小合理控制图片大小。针对所有类型图片的检测标准为:图片固有尺寸应小于图片渲染尺寸的3倍
上文已经获取到全部图片的大小,只要做简单的判断即可。
图片地址检测
检测标准
集团CDN图片提供的对小图片压缩,裁剪,质量压缩,提供图片webp格式等功能。除了icon等小图片,针对宽高大于100px的图片,应使用剪裁后的图片地址。 非集团CDN图片,可检测图片地址是否为webp图片,webp图片具有更优的图像数据压缩算法,能带来更小的图片体积,而且拥有肉眼识别无差异的图像质量;同时具备了无损和有损的压缩模式、Alpha 透明以及动画的特性,在 JPEG 和 PNG 上的转化效果都相当优秀、稳定和统一。
集团CDN图片剪裁前后大小对比
如下图所示的普通商品图片

剪裁前原图地址:gw.alicdn.com/bao/uploade…
剪裁后图片地址:gw.alicdn.com/bao/uploade…
图片大小对比:商品原图大小是354KB,而剪裁后的图片只有10.2KB。剪裁后的图片能够极大地减少图片大小。
webp格式支持
针对支持webp的环境,需要检测图片地址是否为webp图片有效地址
图片相似度检测
检测标准
同一个页面,除了下拉箭头等小icon外,针对图片尺寸大于50px的图片,会做相似度检测。相似度大于95%的图片会标记出来,避免活动页或者商品页出现重复商品图片。
图片相似度检测算法
常见的图片相似度检测算法有:平均哈希算法、感知哈希算法、颜色分布法、内容特征法。我们检测使用的是平均哈希算法。使用该算法的原因是:计算速度快。
平均哈希算法步骤
- 缩小尺寸。最快速的去除高频和细节,只保留结构明暗的方法就是缩小尺寸。将图片缩小到8x8的尺寸,总共64个像素。摒弃不同尺寸、比例带来的图片差异。
- 简化色彩。将缩小后的图片,转为64级灰度。也就是说,所有像素点总共只有64种颜色。
- 计算所有64个像素的灰度平均值。
- 比较像素的灰度。将每个像素的灰度,与平均值进行比较。大于或等于平均值,记为1;小于平均值,记为0。
- 计算哈希值。将上一步的比较结果,组合在一起,就构成了一个64位的整数,这就是这张图片的指纹。如果图片放大或缩小,或改变纵横比,结果值也不会改变。增加或减少亮度或对比度,或改变颜色,对hash值都不会太大的影响。
- 计算哈希值的差异,得出相似度。
平均哈希算法实现
// 缩小尺寸
async function compressImg(src, imgWidth = 8){
return new Promise(function(resolve){
const canvas = document.createElement('canvas');
const ctx = canvas.getContext('2d');
const image = new Image();
image.crossOrigin = 'Anonymous'; // 允许浏览器在下载图像数据时允许跨域访问请求
image.onload = function(){
canvas.width = imgWidth;
canvas.height = imgWidth;
ctx.drawImage(image, 0, 0, imgWidth, imgWidth);
const data = ctx.getImageData(0, 0, imgWidth, imgWidth);
resolve(data);
}
image.onerror = function(){
resolve("");
}
image.src = src;
});
}
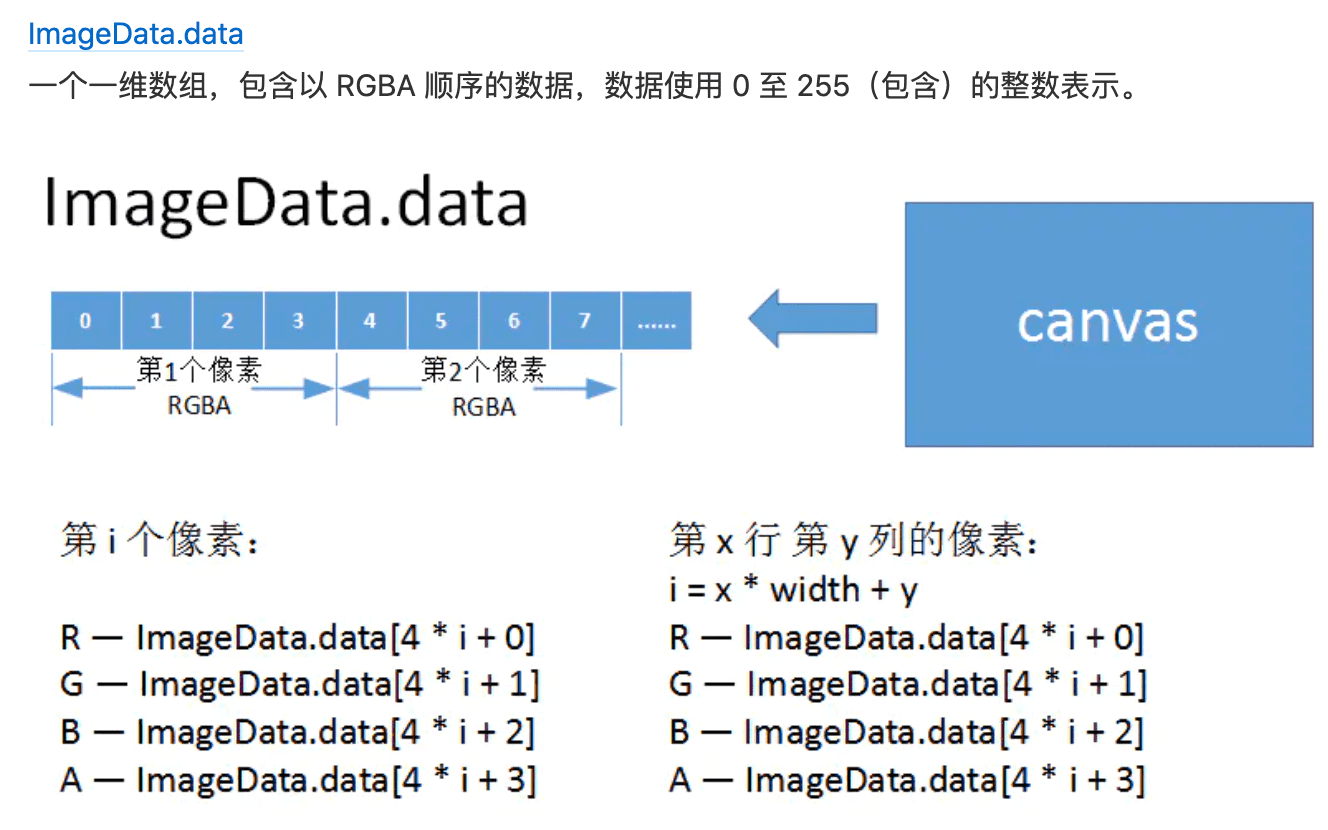
// 简化色彩,转换成灰图
function createGrayscale(imgData) {
const newData = Array(imgData.data.length);
newData.fill(0);
imgData.data.forEach((_data, index) => {
if ((index + 1) % 4 === 0) {
const R = imgData.data[index - 3];
const G = imgData.data[index - 2];
const B = imgData.data[index - 1];
const gray = ~~((R + G + B) / 3);
newData[index - 3] = gray;
newData[index - 2] = gray;
newData[index - 1] = gray;
newData[index] = 255;
}
});
return createImgData(newData);
}
// 计算hash值
function getAHashFingerprint(imgData) {
const grayList = imgData.data.reduce((pre, cur, index) => {
if ((index + 1) % 4 === 0) {
pre.push(imgData.data[index - 1]);
}
return pre;
}, []);
const length = grayList.length;
const grayAverage = grayList.reduce((pre, next) => (pre + next), 0) / length;
return grayList.map(gray => (gray >= grayAverage ? 1 : 0)).join('');
}
拿到所有图片的的hash值后,根据hash间的汉明距离判断相似度。
// 获取汉明距离
function getHammingDistance(str1, str2) {
let distance = 0;
const str1Arr = str1.split('');
const str2Arr = str2.split('');
distance = Math.abs(str1Arr.length - str2Arr.length);
str1Arr.forEach((letter, index) => {
if (letter !== str2Arr[index]) {
distance++;
}
});
return distance;
}
const repeatImgs = []; // 存储相似图片
const len = imgList.length; // 所有图片
for(let i = 0; i < len - 1; i++) {
for(let j = i + 1; j < len; j++) {
const hash1 = newImgList[i].hash || '';
const hash2 = newImgList[j].hash || '';
const hammingDistance = getHammingDistance(hash1, hash2);
const hammingSimilarity = ((hash1.length - hammingDistance) / hash1.length).toFixed(2);
if(hammingSimilarity >= 0.95) { // 保存相似度大于95%的图片
repeatImgs.push({
src1: newImgList[i].src,
src2: newImgList[j].src,
hammingSimilarity,
});
}
}
}
图片相似度检测结果
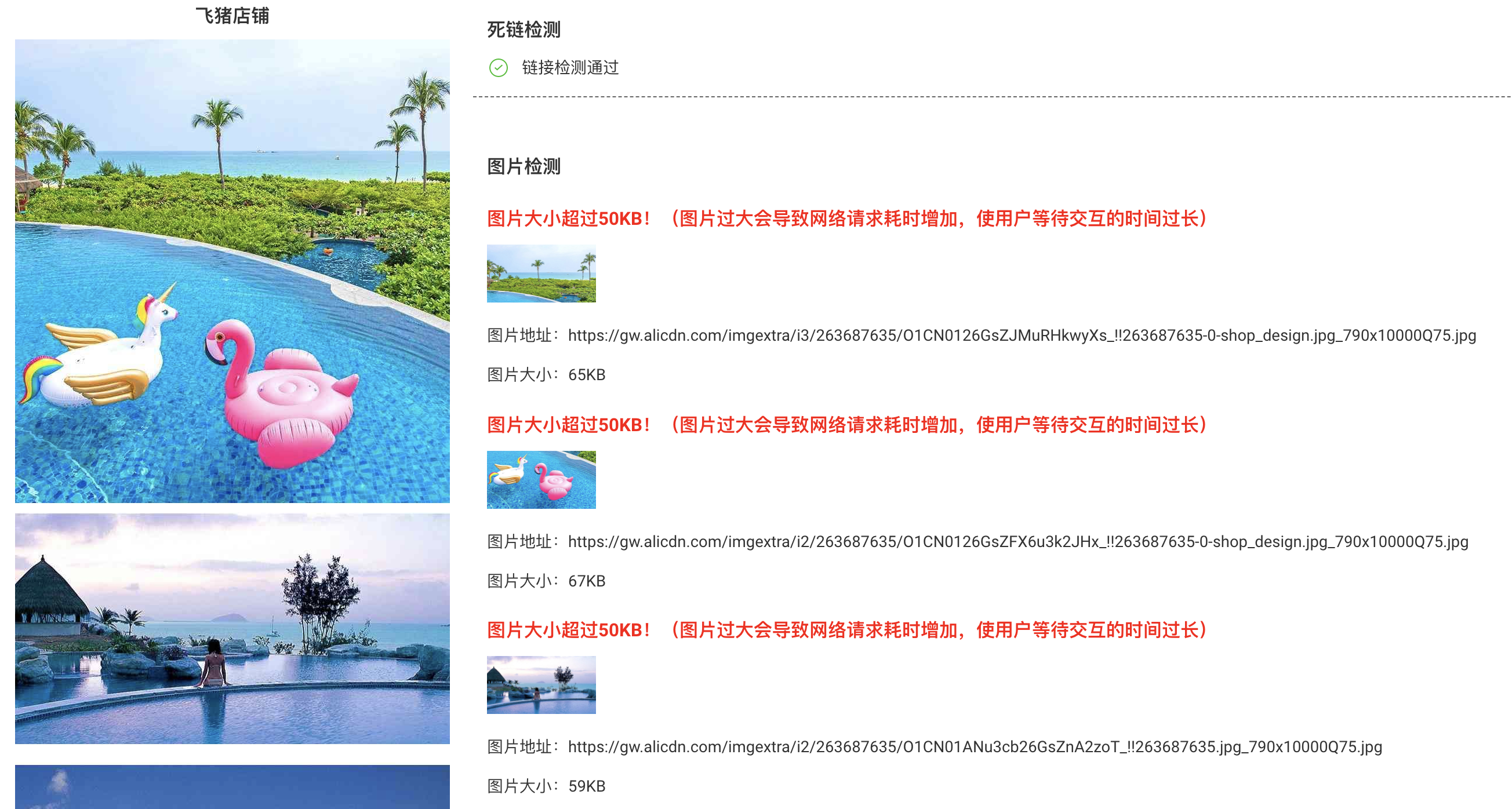

总结
基于puppeteer的前端检测不仅能够发现页面死链,也可以针对指定的链接规则做检测,最大限度的保障页面链接的有效性。针对图片的检测能够最大限度的减小图片大小,减少网络请求耗时。针对商品促销页面等,可以通过图片相似度检测来避免出现重复商品。后续还会添加白屏检测、异常页面检测等功能,丰富前端检测功能更好地保障页面质量。
Last but not lease
阿里巴巴飞猪部门正在招聘前端,目前我们在 Serverless 、微前端运营工作台、端渲染、互动营销、招选投搭、智能化、体验技术、数据度量有不少建设,欢迎有能力同学进来落地技术产生业务价值,想带人同学过来直接带一个方向也是可以的,欢迎关注飞猪前端团队公众号【Fliggy F2E】直接聊天联系即可!
