

此次操作,主要目的还是为了了解 ES 的新数据结构,为了 2.x 迁移到 7.x 做准备。
为了方便能用 Docker 我都会用 Docker
准备环境
首先创建 docker 网络,保证通信,这里不采用 host 模式
docker network create elastic
拉取 es7.4 以及 kibana 镜像并启动
docker pull elasticsearch:7.4.2
docker run -d --name elasticsearch --network=elastic -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:7.4.2
由于不能再使用 es 内置的 elasticSearch-head 插件了(当然你也可以使用第三方插件或 chome 插件),直接安装 kibana ,一定要注意,版本一定要对应。
docker pull kibana:7.4.2
docker run -d --name kibana --network=elastic -e ELASTICSEARCH_URL=http://192.168.123.107:9200 -p 5601:5601 kibana:7.4.2

这样我们看官网的文档 Demo 的时候也会非常方便,因为官网直接可以一键把构造数据转移到 Kibana console 上面,省去了复制粘贴的麻烦。
Index some documents | Elasticsearch Reference [7.4] | Elastic

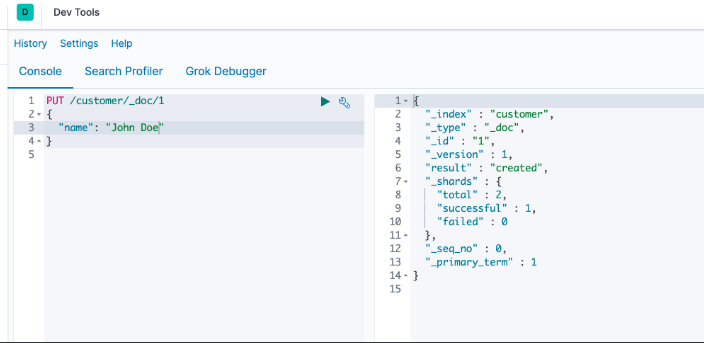
创建了一个索引名字为 customer ,type 是 _doc ,那么我心中疑虑,不是说好了为了防止索引数据不均匀影响 Lucene 的性能 7.x 砍掉 type 吗,怎么还是存在 _type 这个 filed 呢?

我尝试继续创建一个 _doc2 ,果然被拒绝了,我猜测可能是兼容老数据?钻牛角尖的人都很惨,先往下看再说。
批量索引
Indexing documents in bulk
If you have a lot of documents to index, you can submit them in batches with the bulk API. Using bulk to batch document operations is significantly faster than submitting requests individually as it minimizes network roundtrips.
如果要一次索引很多文档,可以使用 bulk API 批量提交,因为会减少网络往返次数,所以很快
The optimal batch size depends a number of factors: the document size and complexity, the indexing and search load, and the resources available to your cluster. A good place to start is with batches of 1,000 to 5,000 documents and a total payload between 5MB and 15MB. From there, you can experiment to find the sweet spot.
一次搞 1000 - 5000,数据 5m - 15m 食用最佳。
官方给了一堆垃圾数据,然后给了 curl 的食用方法秀了一下效率。
结合之前的博客:
综合考虑一下 string、 bool、type 新的调整,对以后的迁移又多了一些了解。
github 归档 : github.com/pkwenda/Blo…
