

同学们好,今天我们就开始讲Redis系列的知识了,先带大家对缓存和Redis有一个简单的了解
缓存简介
缓存的主要目的就是为了提升系统性能:
比如 CPU Cache 缓存的是内存数据用于解决 CPU 处理速度和内存不匹配的问题,内存缓存的是硬盘数据用于解决硬盘访问速度过慢的问题。 再比如操作系统在 页表方案 基础之上引入了 快表 来加速虚拟地址到物理地址的转换。我们可以把块表理解为一种特殊的高速缓冲存储器(Cache)。
“老师,本地也可以建立缓存,为什么非要用Redis呢”
“很好,既然提出了本地缓存,我就简单介绍一下本地缓存,再谈谈为什么用Redis”
本地缓存
目前本地缓存使用的方案有以下几种:
1. HashMap和ConcurrentHashMap
concurrentHashMap主要提供的是线程安全的map,这个后面我们会单独建立一个章节去详细讲,他们的主要缺点就是功能太单一了,至少要有:过期时间、淘汰机制(内存达到阈值,触发淘汰机制)、命中率统计(判缓存失效机制设计是否合理)
2. 一些本地缓存框架:Ehcache 、 Guava Cache 、 Spring Cache、Caffeine
这些框架大家课后可以看看其使用和原理,他们主要缺陷在于多个服务之间数据无法共享,甚至是数据存量也不够大,其实这也是本地缓存的通病
3. 总结一下本地缓存的局限性 :
- 对分布式架构支持不友好,如数据无法贡献
- 缓存容量受机器影响,使用的就是机器内存
- 高并发支持不佳,一般Mysql的QPS是1w左右,而redis可以达到10-30w,集群应该更高
QPS(Query Per Second):服务器每秒可以执行的查询次数;
而采用分布式缓存可以有效解决这些问题

为什么是Redis
目前分布式存储使用比较多的memcached和redis,而且使用redis越来越广泛了
两者的共同点:
都是基于内存存储的
都有过期策略
性能其实差不多
两者的区别:
redis支持的数据类型更丰富,memcached只支持简单的k/v,而redis还支持list、set、zset、hash等
redis支持持久化,也就是支持将内存数据保存到磁盘中,保证了数据的安全,memcached就不可以
redis因为有持久化就可以实现灾难恢复
redis在遇到内存使用完成之后利用淘汰机制,将数据放到磁盘中,memcached则直接就抛异常了
redis是支持cluster模式的,memcached需要自己实现
Memcached 是多线程,非阻塞 IO 复用的网络模型;Redis 使用单线程的多路 IO 复用模型(Redis 6.0 引入了多线程 IO )
redis提供更丰富的附加功能:发布订阅模型、Lua脚本、事务等
redis过期数据的删除策略有惰性删除和定期删除,而Memcached 只有惰性删除
“老师,惰性删除和定期删除还有刚才提到的淘汰机制,都不是很懂哎”
“既然两次都谈到这个了,我就给大家简单介绍一下”
Redis的过期清理机制
缓存的数据不可能一直存在,这样内存就会撑爆了,一方面是通过设置过期时间的,如果没有设置那么只能通过内存淘汰机制
如果Redis设置过期时间,内部删除过期key使用的是「定期删除」+「惰性删除」两者配合的过期策略
定期删除
比如每隔100ms随意抽一些设置了过期的key,判断是否过期并删除,之所以随机是因为key太多,全局扫描太浪费性能了,但是也有个问题,删不完啊,越留越多怎么办,那么还会结合惰性删除策略
惰性删除
这种就是客户端在访问key的时候,会判断是否过期,如果过期了那么就直接删除同时不会将结果返回给客户端。但是也有问题,加入有些key即过期也没有客户端访问,还是会导致内存耗尽,这时候就要使用内存淘汰机制了
内存淘汰机制
当内存耗尽,则自动触发该机制选取key删除
注意内存淘汰机制策略或者内存限制的阈值都是可以在Redis配置的,具体命令可以自行查看
内存淘汰机制策略选取的方式有一下几种:
noeviction:如果已满则新写入的会报错。默认策略
allkeys-lru:最近最少使用的key移除
allkeys-random:随机移除key
volatile-lru:在设置了过期时间的key中,移除最近最少使用的key
volatile-random:在设置了过期时间的key中,随机移除key
volatile-ttl:在设置了过期时间的key中,将最早过期的key移除
「一般比较推荐使用lru策略」
注意哦,lru策略其实使用在很多淘汰策略里面,比如操作系统的内存中等很多地方, 给大家布置个小作业,是否能手写LRU算法
class LRUCache<K, V> extends LinkedHashMap<K, V> {
private final int CACHE_SIZE;
/**
* 传递进来最多能缓存多少数据
*
* @param cacheSize 缓存大小
*/
public LRUCache(int cacheSize) {
// true 表示让 linkedHashMap 按照访问顺序来进行排序,最近访问的放在头部,最老访问的放在尾部。
super((int) Math.ceil(cacheSize / 0.75) + 1, 0.75f, true);
CACHE_SIZE = cacheSize;
}
/**
* 钩子方法,通过put新增键值对的时候,若该方法返回true
* 便移除该map中最老的键和值
*/
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
// 当 map中的数据量大于指定的缓存个数的时候,就自动删除最老的数据。
return size() > CACHE_SIZE;
}
}
当然在持久化的过程中其实也会去检查是否过期,如果过期了那么是不会进入到持久化的文件中的,当然,在数据恢复的时候也会检查,其中AOF会对过期的数据增加del的命令的,这部分持久化知识,我们会单独建立一章做讲解。
回到正题,我们讨论了redis使用的好处,那现在我们就来真正的看看redis的面纱了。
Redis 简介
redis是C语言开发的数据库,其实Memcached也是用C开发的,下图是官网的简介
Redis 采用单线程模型,具体通信过程建议大家阅读《Redis 设计与实现——黄健宏》进行系统学习,这里面涉及到比较复杂计算机体系知识,不做过多讲解。
首先说明一下单线程不是指Redis单实例就是一个线程,而是核心模块由单线程完成,当然还有一些辅助线程从旁协助,比如LRU的淘汰机制
「之所以不使用多线程有几点考虑:」
普通的kv操作其实瓶颈不在cpu,而在于内存及I/O
redis中有多种数据类型的操作,甚至包括事务,采用多线程会因为切换问题而困扰,甚至加锁解锁等都会增加复杂度
其实目前6.0版本已经引入了多线程,我们都知道redis主要瓶颈在于内存及IO,内存就是加当然也要注意NUMA陷阱,还有一个就是IO了,多线程主要就是解决了IO问题,下图是Redis6版本的多线程模型
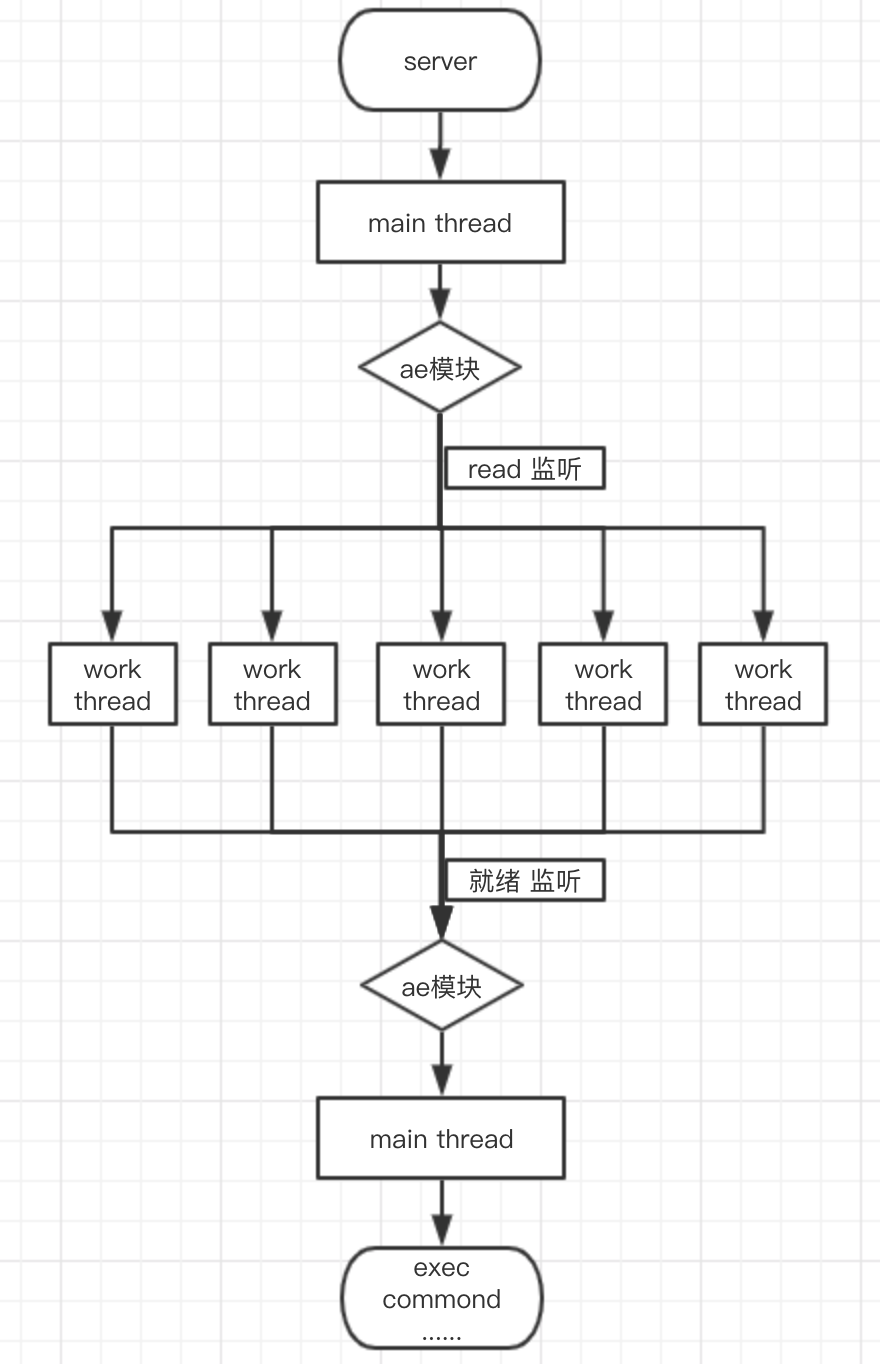
根据上方结构简图可以看到,Redis 6 中的多线程 主要在处理 网络 I/O 方面,对网络事件进行监听,分发给 work thread 进行处理,处理完以后将主动权交还给 主线程,进行 执行操作,当然后续还会有,执行后依然交由 work thread 进行响应数据的 socket write 操作,注意Memcached其实也是多线程, 相同点就是都采用了master-worker 这一经典思路,不同点就是Memcached中的执行主逻辑也放在了线程中,当然这主要是因为有简单的数据类型。
“老师,单线程的话,那redis效率应该不高吧”
“好吧,那我还是简单说一下”
其实效率还是很高的,原因主要有:
纯内存操作
核心是基于非阻塞的IO多路复用机制
大家都知道多线程的弊端主要在上下文的切换中会影响性能,采用单线程如何实现多个客户端的请求相应,利用的就是非阻塞的IO多路复用机制(epoll),IO多路复用主要有三种分别是select、poll、epoll,性能最好的是epoll,具体原理后面可以单独开一章来详细讲解该机制的原理。
- C语言编写,更接近底层
Redis 选择使用单线程模型处理客户端的请求主要还是因为 CPU 不是 Redis 服务器的瓶颈,所以使用多线程模型带来的性能提升并不能抵消它带来的开发成本和维护成本,系统的性能瓶颈也主要在网络 I/O 操作上;而 Redis 引入多线程操作也是出于性能上的考虑,对于一些大键值对的删除操作,通过多线程非阻塞地释放内存空间也能减少对 Redis 主线程阻塞的时间,提高执行的效率。
总结
主要看到了Redis比本地缓存及Memcached的好处,主要表现在:数据共享、完善的数据过期机制以及更丰富的辅助功能,我们也简单的了解了Redis作为单线程实现的系统,但是性能却可以达到最优。下节课我们会带领大家学习Redis的不同数据结构及实现方式。下课!
