

1、定义
给定一个语言(表达式),定义它的文法的一种表示,并定义一个解释器,使用该解释器来解释语言中的句子(表达式)。
2、模式结构
解释器模式由四部分组成:
- AbstractExpression(抽象表达式):声明一个所有的具体表达式角色都需要实现的抽象接口。这个接口主要是一个interpret()方法,称做解释操作。
- TerminalExpression(终结符表示式):实现了抽象表达式所要求的接口,主要是一个interpret()方法;文法中的每个终结符都有一个具体终结表达式与之相对应。比如有一个简单的公式R=R1+R2,在里面R1和R2就是终结符,对应的解析R1和R2的解释器就是终结符表达式。
- NonTerminalExpression(非终结符表达式):文法中的每一调规则都需要一个具体的非终结符表达式,非终结符表达式一般式文法中的运算符或者其他关键字,比如公式R=R1+R2中,“+”就是非终结符,解析“+”的解释器就是一个非终结符表达式。
- Context(环境):环境类又称为上下文,一般是用来存放文法中各个终结符所对应的具体值,比如R=R1+R2,我们给R1赋值100,给R2赋值200.这些信息需要存放到环境中,很多情况下我们使用Map来充当环境就足够了。
3、实例
3.1 Expression(AbstractExpression)
public abstract class Expression {
public abstract int interpreter(HashMap<String, Integer> map);
}
3.2 VarExpression(TerminalExpression)
public class VarExpression extends Expression {
private String key;
public VarExpression(String key) {
this.key = key;
}
@Override
public int interpreter(HashMap<String, Integer> map) {
return map.get(key);
}
}
3.3 SymbolExpression(NonTerminalExpression)
public class SymbolExpression extends Expression {
protected Expression left;
protected Expression right;
public SymbolExpression(Expression left, Expression right) {
this.left = left;
this.right = right;
}
@Override
public int interpreter(HashMap<String, Integer> map) {
return 0;
}
}
3.4 加减解释器
public class AddExpression extends SymbolExpression {
public AddExpression(Expression left, Expression right) {
super(left, right);
}
@Override
public int interpreter(HashMap<String, Integer> map) {
return super.left.interpreter(map) + super.right.interpreter(map);
}
}
public class SubExpression extends SymbolExpression {
public SubExpression(Expression left, Expression right) {
super(left, right);
}
@Override
public int interpreter(HashMap<String, Integer> map) {
return super.left.interpreter(map) - super.right.interpreter(map);
}
}
3.5 Calculator(Context)
public class Calculator {
private Expression expression;
public Calculator(String expStr) {
// 使得运算先后顺序
Stack<Expression> stack = new Stack<>();
char[] charArray = expStr.toCharArray();
Expression left = null;
Expression right = null;
for (int i = 0; i < charArray.length; i++) {
switch (charArray[i]) {
case '+':
left = stack.pop();
right = new VarExpression(String.valueOf(charArray[++i]));
stack.push(new AddExpression(left, right));
break;
case '-':
left = stack.pop();
right = new VarExpression(String.valueOf(charArray[++i]));
stack.push(new SubExpression(left, right));
break;
default:
stack.push(new VarExpression(String.valueOf(charArray[i)));
break;
}
}
this.expression = stack.pop();
}
public int run(HashMap<String, Integer> map) {
return this.expression.interpreter(map);
}
}
3.6 客户端调用
public class Client {
public static void main(String[] args) throws IOException {
String expStr = getExpStr();
HashMap<String, Integer> map = getValue(expStr);
Calculator calculator = new Calculator(expStr);
System.out.println("运算结果:" + expStr + "=" + calculator.run(map));
}
public static String getExpStr() throws IOException {
System.out.print("请输入表达式:");
return (new BufferedReader(new InputStreamReader(System.in))).readLine();
}
public static HashMap<String, Integer> getValue(String expStr) throws IOException {
java.util.HashMap<String, Integer> map = new HashMap<>();
for (char ch : expStr.toCharArray()) {
if (ch != '+' && ch != '-') {
System.out.print("请输入" + ch + "的值:");
String in = (new BufferedReader(new InputStreamReader(System.in))).readLine();
map.put(String.valueOf(ch), Integer.valueOf(in));
}
}
return map;
}
}
4、适用场景
- 可以将一个需要解释执行的语言中的句子表示一个抽象语法树。
- 一些重复出现的问题可以用一种简单的语言来进行表达。
- 一个语言的文法较为简单。
- 执行效率不是关键问题。(注:高效的解释器通常不是通过直接解释抽象语法树来实现的,而是需要将它们转换为其他形式,使用解释器模式的执行效率并不高。)
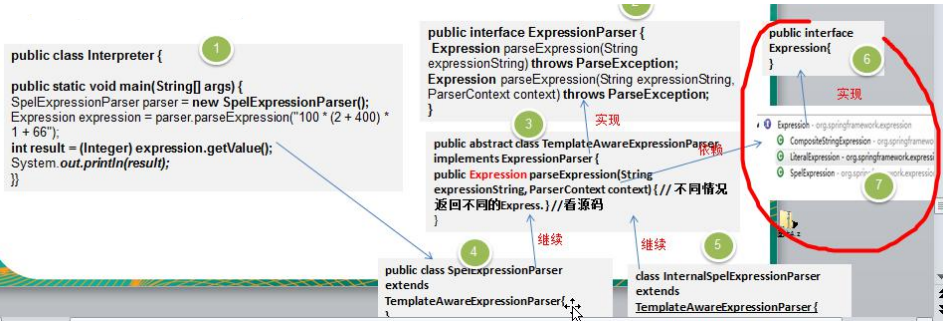
5、在Spring中的应用
6、优缺点
6.1 优点
- 易于实现文法。在解释器模式中,一条语法规则用一个解释器对象来解释执行。对于解释器的实现来讲,功能就变得比较简单,只需要考虑这一条语法规则的实现就可以了,其他的都不用管。
- 易于扩展新的语法。由于解释器采用类来描述语法规则,因此可以通过继承等机制创建相应的解释器对象,在创建抽象语法树的时候使用这个新的解释器对象就可以了。
6.2 缺点
- 执行效率低。由于在解释器模式中使用了大量的循环和递归调用,因此在解释较为复杂的句子时其速度很慢,而且代码的调试过程也比较麻烦。
- 对于复杂的文法难以维护。在解释器模式中,每一条规则至少需要定义一个类,因此如果一个语言包含太多文法规则,类的个数将会急剧增加,导致系统难以管理和维护,此时可以考虑使用语法分析程序等方式来取代解释器模式。
