

本文始发于个人公众号:TechFlow,原创不易,求个关注
今天是算法数据结构专题的第29篇文章,我们来聊一个新的字符串匹配算法——KMP。
KMP这个名字不是视频播放器,更不是看毛片,它其实是由Knuth、Morris、Pratt这三个大牛名字的合称。老外很喜欢用人名来命名算法或者是定理,数学里就有一堆,什么高斯定理、欧拉函数什么的。但是中国人更倾向于从表意上来给一个概念命名,比如勾股定理、同余定理等等。之前觉得用人名命名很洋气,作者可以青史留名,后来想想这也是英文表意能力不足,很难用表意的方式起名的体现。
扯远了,我们回到正题。
应用场景
在计算机领域当中字符串匹配其实是一个非常常见的问题,我们使用它的场景也多到不可计数。比如在一个已经打开的页面当中搜索关键词,再比如说git里面的代码变动的记录,以及论文的查重等等。在这些问题当中有些情况可能还好,比如说我们搜索一个关键词,因为关键词并不长,我们暴力枚举也不会特别耗时。但是在有些问题当中明显暴力匹配是无法胜任的,比如论文查重。一篇论文动辄上千词,要和库中的上万篇文章进行查重扫描,这当中的工作量可想而知。如果是暴力枚举算法那查重显然会查到天荒地老。
所以早期的时候字符串匹配是一个难题,既然是难题那么显然就会有很多人来研究,也因此出了很多成果,很多大牛发表了字符串匹配的算法,其中KMP算法由于效率很高、实现复杂度低被应用得最广。到这里,我们就知道KMP算法是用来字符串匹配的。
比方说我们有两个字符串,A串是:I hate learning English. B串是hate learning,很明显B串是A串的字符串。如果我们暴力枚举来判断的话,我们需要遍历A串当中的每一个起始位置是否能够完成匹配,那么复杂度显然是。通过KMP算法,我们可以在
的时间内做到这点。
著名的大佬matrix67在KMP算法的介绍博客当中有一句著名的骚话,当你有一个喜欢的MM,你可以委婉地问她:“假如你要向你喜欢的人表白的话,我的名字是你的告白语中的子串吗?”
Next数组
KMP算法的核心精髓只有一个就是Next数组,但是这个概念并不太容易理解,很多人学KMP放弃就是折戟在了Next这个数组上。
我们先把Next数组是怎么来的放在一边,先来看下Next数组是用来干嘛的,它起作用的原理是什么,最后再来讨论Next数组怎么来的问题。根据我的理解,Next数组其实就是一个中途开始的机会,也就是当我们在枚举匹配的时候,发现了不匹配的情况,我们不是从头开始,而是从一个最大可能的中间结果开始。
我们来看个例子:
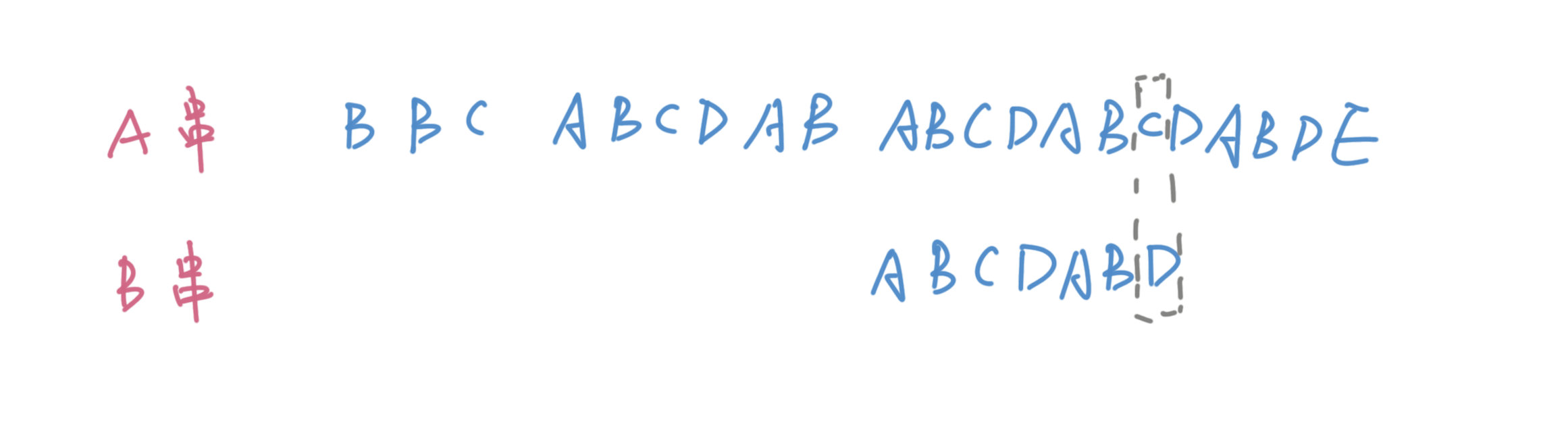
上图中上面的是A串,下面的是B串,我们在匹配的过程当中发现B串的前面几位都匹配上了,而在最后一位匹配失败。按照常规的做法,我们应该是移动到下一个位置从头开始匹配。但是这是非常浪费的,因为我们观察下可以发现失败位置的ABC和B串开头的ABC是可以构成匹配的。
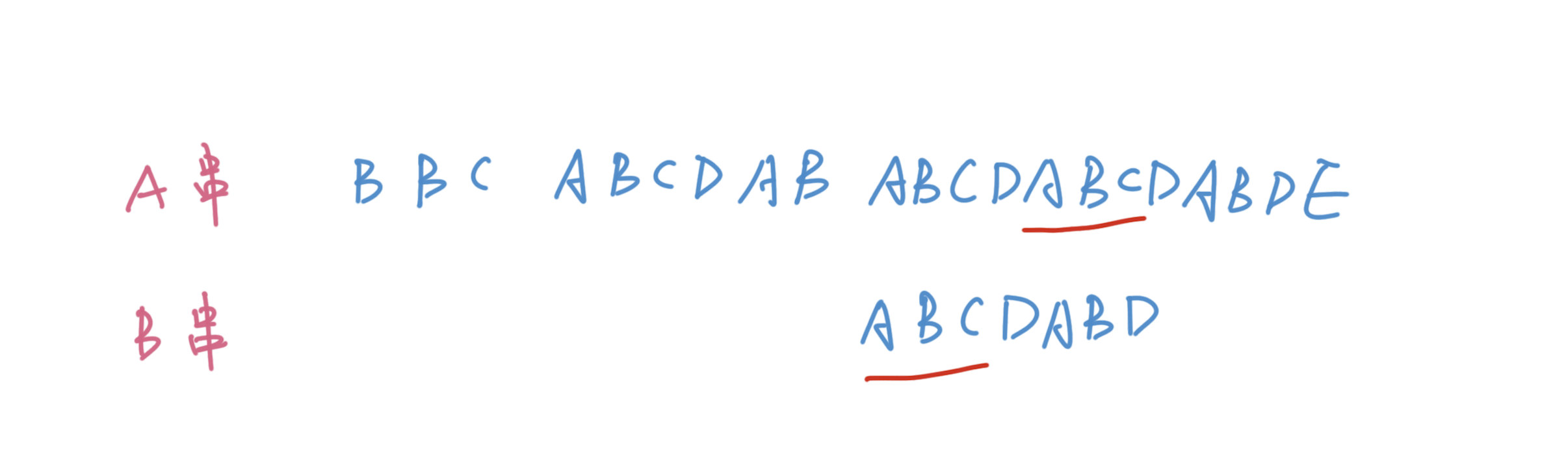
我们之前失败的时候判断的是以C结尾的ABCDABC和B串的匹配,在这一次匹配失败之后,我们可以继续尝试匹配其他以C结尾的前缀串,比如ABC。这样我们就可以从中间状态开始,而节省了许多次不必要的枚举。但问题就来了,这个中间结果是怎么来的呢,我们怎么知道当下失败了上一个可行的中间结果是哪一个?
对,没有错,前面说到的Next数组就是用来存储中间结果的。所以Next可以理解成下一次机会的意思,这样就好理解了。由于我们是在A串当中寻找B串,所以这个Next数组应该是针对B的,记录B中每一个位置如果匹配失败,它的前面一个可行的中间状态是哪一个。
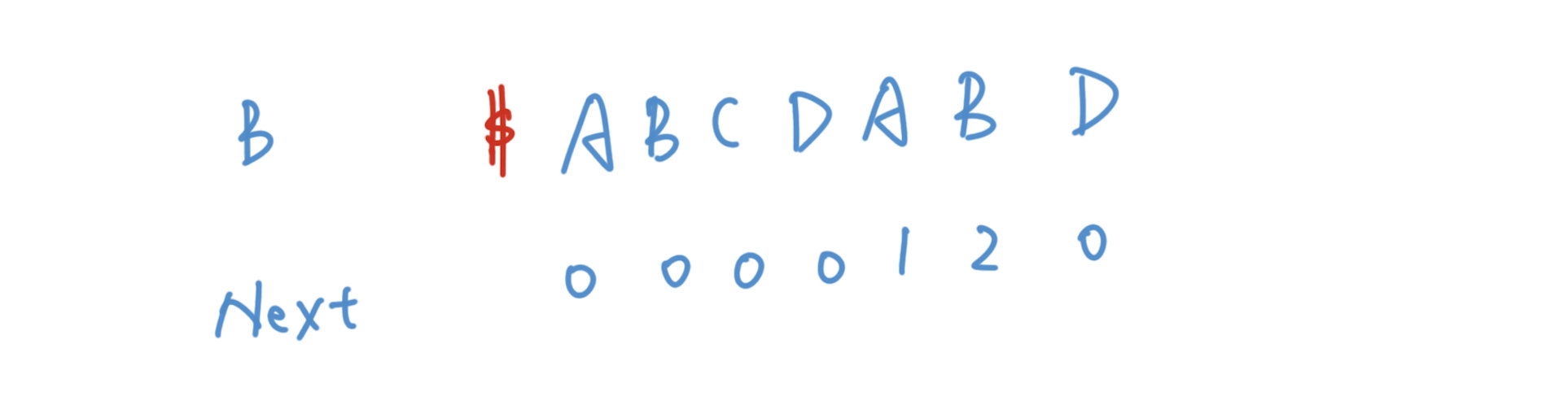
我们先写出来B的Next数组,等会再去研究它是怎么得到的。为了简化编码,我们假设字符串是从1位置开始的,所以我们在0的位置添加一个$符号作为占位符。对于大部分情况都是没有重来的机会的,失败了直接归零。而其中的A和B两个位置是有重来机会的,因为B的前缀当中出现了A和AB。所以如果在匹配ABD的时候失败了,我们还可以从AB处再次开始尝试匹配ABC。
算法原理
我们想象一根指针指向了B数组当中接下来要匹配的位置,如果匹配失败了,它就会跳转到Next数组当中记录的位置去,匹配成功了我们就向后移动一位。在有了Next数组之后,我们写出代码来真的很容易了:
def kmp(var_str, template_str):
# var_str即A串
# template_str模式串即B串
# 我们在两个字符串前加上了占位符
var_str = '$' + var_str
template_str = '$' + template_str
next = generate_next(template_str)
n, m = len(var_str), len(template_str)
# head指向要匹配的位置的前一位
head = 0
for i in range(1, n):
# 由于next数组很长,可能失败多次
# 直到head+1的位置能匹配上或者head等于0
while head > 0 and template_str[head+1] != var_str[i]:
head = next[head]
# 匹配上了则head变长一位
if template_str[head+1] == var_str[i]:
head += 1
# 如果head长度等于B串了,则表示匹配成功
if head == m - 1:
return True
return False
对于A串中的每一个位置来说,我们都在B串当中遍历了每一个有可能构成匹配的前缀。所以说这个算法是可行的,一定可以获得解。另外一个问题是复杂度的问题,为什么我们用了两重循环,但仍然是的算法呢?
其实很简单,因为while循环只会让head减小,而不会让head增加。head增加是在for循环里执行的,也就是说head最多增加n次。那么对应的while循环也就最多执行n次,因为head是非负的。所以while循环在整个for循环执行的过程当中最多执行了n次,整体执行的次数仍然是级别的而不是
级,当然是线性的算法。
求解Next
到这里,问题只剩下了一个,就是这个Next怎么来呢?
其实我们在之前讲Next数组的使用的时候已经泄露天机了,我们再来看下上图,不知道大家能感觉到什么。
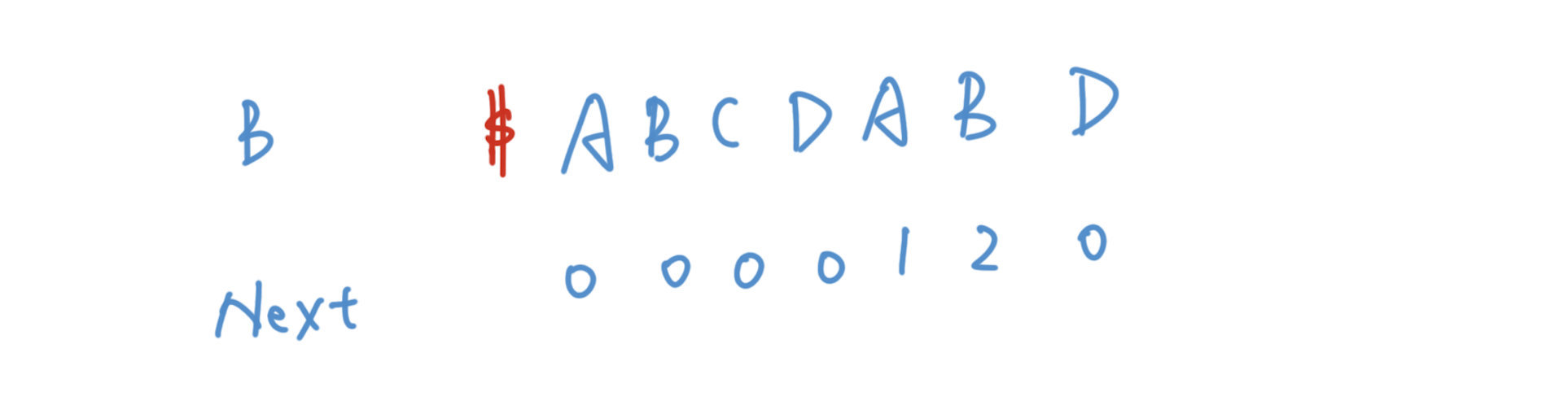
后面一个A的Next值是1,也就是第一个A的下标,后面一个B的Next值是2,也就是第一个B的下标。换句话说第二个A能够和位置1的A匹配,后面的AB能和前缀的AB匹配。也就是说Next数组其实就是B数组自己和自己匹配的结果,我们在一开始的时候将整个Next数组全部置为0,然后依次递推迭代出所有的Next的值。
我们在求解Next[i]的时候我们可以利用上Next[i-1]的值,因为Next[i-1]存储的是能够与B[i-1]匹配的前缀的结尾位置。如果B[Next[i-1]+1]等于B[i],那么说明Next[i] = Next[i-1] + 1。如果不等的话,我们可以用while循环来寻找能够匹配上的前缀。也就是说这是一个递推的过程,不过要注意一点我们计算Next数组要从2开始,因为对于1来说,Next[1]一定等于0。
def generate_next(var_str):
n = len(var_str)
next = [0 for _ in range(n)]
for i in range(2, n):
# 用next[i-1]作为开始寻找能够匹配上的最长next[i]
head = next[i-1]
while head > 0 and var_str[head+1] != var_str[i]:
head = next[head]
# 如果匹配上了,head+1
if var_str[head+1] == var_str[i]:
head = head + 1
# 记录下来
next[i] = head
return next
总结
到这里,我们关于KMP算法的介绍就结束了,不知道大家看完之后感受如何,是不是有点蒙圈呢?
其实蒙圈是正常的,我第一次学的时候足足看了好几遍才算是看明白。这毕竟是一个比较巧妙的算法,想要通过阅读一篇文章就完全学会还是比较困难的,最好的还是亲自动手实现一下试试。KMP算法我最大的感受就是如果你把整个算法的逻辑都串起来了,那么即是自己从头到尾推导一遍难度也不是很大(我就在面试当中推导过一次)。如果你没能把逻辑串起来,那么觉得难理解看不懂是正常的,你可能需要再读一遍或者是寻找一些其他的资料查漏补缺。
今天的文章到这里就结束了,如果喜欢本文的话,请来一波素质三连,给我一点支持吧(关注、转发、点赞)。

