

一、Paxoskv的研发背景
在BIGO内部,存储系统主要包含表格类存储系统MyShard,分布式key/value类存储系统ssdb [1]和pika [2],以及其它用于对象存储的分布式系统。key/value的存储内部大量采用ssdb和pika,虽然ssdb和pika都是很优秀的存储系统,但在BIGO业务场景的具体实践中,BIGO技术遭遇到了不少的问题和挑战。例如,ssdb和pika都是采用基于binlog的primary/backup [3]复制模型,primary/backup模型很好地解决了读扩展问题的同时,也带来了如下图所示的一些问题:
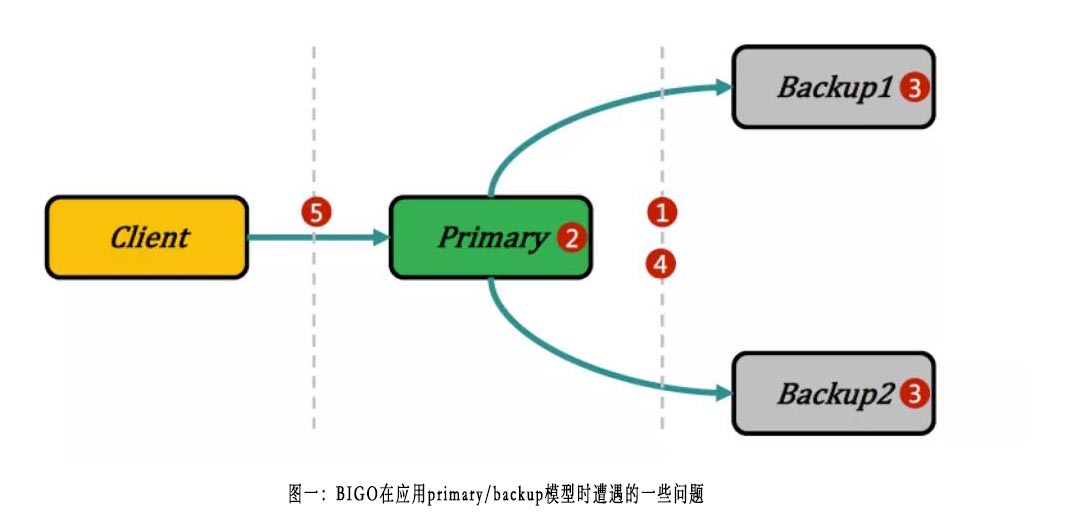
1) primary/backup之间的数据同步,不仅涉及到数据是否会丢失的问题,还涉及到整个存储集群对外可以提供什么样的一致性模型的问题。而单一的同步方式,无论是采用异步、半同步还是强同步的方式,都无法满足不同业务差异化的需求。
2) primary上data操作和binlog操作的原子性,既和复制的进度管理有关,又和多副本系统中的一致性有关。比如在MySQL内部,innodb和binlog之间采用内部XA事务来解决这个问题,但在现有系统上如何解决好这个问题就比较有挑战。
3) primary/backup模型,比较难处理多region写入的问题。简单的多点写入不仅无法提供正确的一致性边界,而且可能导致更新静默丢失等问题,从而给故障定位和运维带来较大的负担。
4) primary/backup模型在多区部署的情况下,存在primary节点fanout放大、跨region流量冗余传输、backup节点资源利用受限等潜在问题。
5) pika也提供类似NRW [25]的复制模型,但即使采用R+W > N的quorum配置,如果不采用read repair等手段,也无法提供线性一致性,具体示例参考“2.3.6”章节。
总之,相对于BIGO多元化的业务种类和快速增长的数据规模,现有存储系统在数据一致性、系统可用性、性能和跨region部署能力等方面,已经无法满足BIGO内部业务系统的诉求。具体而言,BIGO业务对存储系统的核心诉求包含:
● 具备从线性一致性到最终一致性的多种一致性模型,不同业务场景可以根据自身的SLA,在RTO和RPO之间权衡;
● 具备多点写入的能力,即宏观上是一个multi-master的系统,在容错设计内的节点故障,不对系统可用性产生影响;
● 具备深度的掌控/定制能力,可以下沉部分高频业务场景到存储层;简化开发的同时,有利于提升业务的核心竞争力;
● 具备友好的水平扩展能力,可以快速地扩/缩容;在交付效率和资源利用方面更进一步;
基于上面这些背景,我们开发了paxoskv。其设计目标是:具备线性一致性/因果一致性/最终一致性可选的能力,具备多点写入的能力,具备水平扩展能力,读写性能和ssdb、pika相当。
二、Paxoskv的技术实现
2.1 系统架构
Paxoskv的系统架构示意如下,每一个set对应一个逻辑数据分区,每一个set在服务端有多个replica(图中以3副本为例:replica1/replica2/replica3)。每一个set内的key,按照一致性hash划分为多个key space,每一个key space对应到具体replica。这样做的目的是为了让每一个replica都具备处理请求的能力,与之对应的是raft [23]这类强leader协议,所有的写请求必须路由到leader节点,由leader节点发起。这样对follower节点的资源利用不是十分充分,一定程度上降低了整个集群的处理能力。
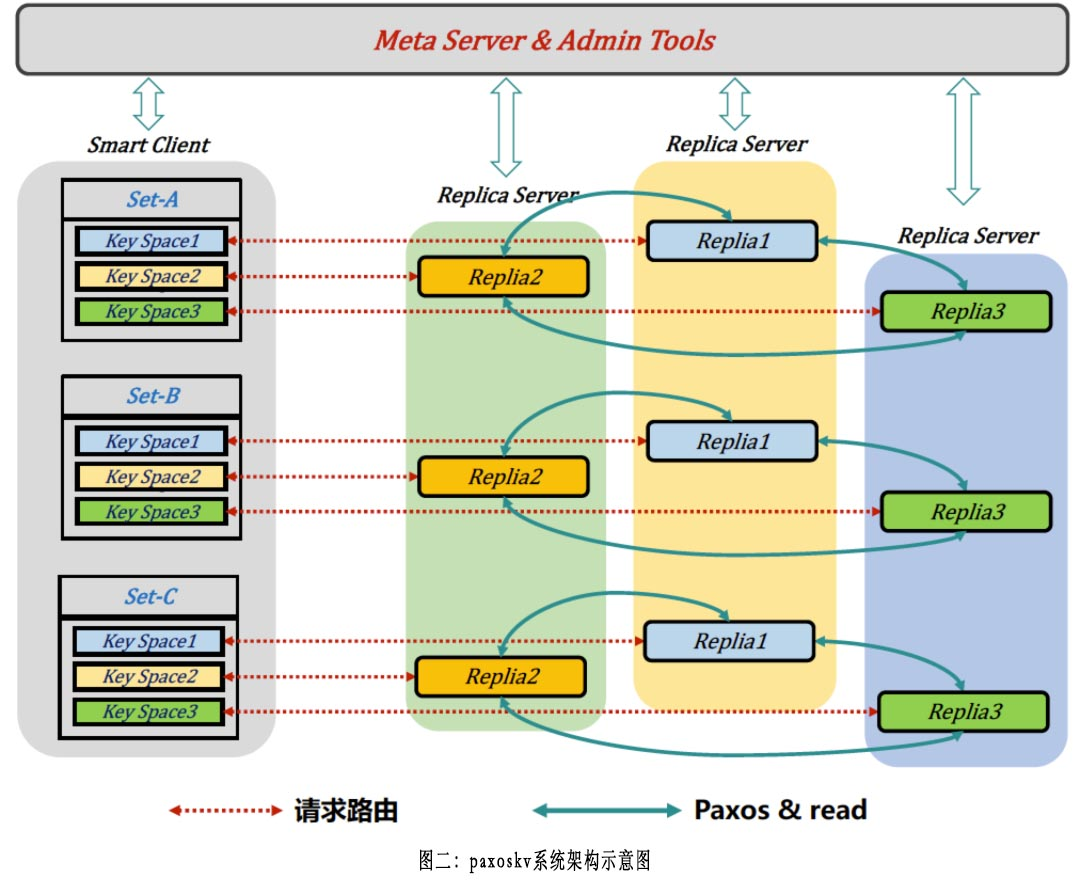
每一个replica server可以包含多个set的replica,同时对多个set进行服务。一个replica server所服务的replica数量,可以随着迁移、物理机器扩容等因素而不时变化。整个集群的元数据存储在etcd [16]中,smart client通过watch的方式及时感知整个集群拓扑情况的变化。
2.2 设计选型
在paxoskv的设计选型上,我们主要结合了“Paxoskv的研发背景”部分描述的现状、BIGO内部业务的诉求、以及较为前沿的分布式存储系统技术,来进行综合的判断和取舍。设计中,BIGO技术借鉴了WPaxos [24]中的很多想法,最终选择paxoskv的理论支撑和工程实践设计如下:
● 在复制模型方面,RW节点间paxoskv采用leaderless的multi-paxos架构,既允许多点写入、又借助于multi-paxos来保证多个副本间状态的一致性;
● 为避免data操作和binlog操作原子性的问题,RW到RO节点、RO节点到RO节点间paxoskv通过复制存储引擎的WAL来回避这个问题,同时也带来了成本和复制实时性方面的一些收益;
● 为应对多region部署的需求,和cloud spanner [5]类似,paxoskv内部节点分为RW(read-write)和RO(read-only)两种角色,在region内部RW间采用multi-paxos做强同步复制,跨region通过RO做异步复制,多个region间采用chain-replication,避免产生冗余的跨region流量;
● 另外,paxoskv是一个key一个独立的multi-paxos log序列,不同的multi-paxos log之间完全隔离,比较好地可以让大量的paxos实例并行运行,从而提升集群层面的并发响应能力;
2.3 深度优化
2.3.1 Leaderless
目前主流基于multi-paxos的多副本存储系统中,都是采用set划分的方式,一个set管理一个数据分片,一个set对应一个multi-paxos log。Paxoskv的实现中,为了满足系统水平扩展性的需求,也是采用set化的思想,不过一个set中包含多个multi-paxos log。具体而言是每一个key都有自己独立的multi-paxos log。在同一个set内,在smart client发起请求时,会根据一致性hash,将同一个set中的不同key均匀地分布到多个副本之间。所以paxoskv是具备多点写入能力的leaderless架构,在微观层面,对于同一个key,如果集群拓扑稳定,则走fast accept路径,反之则走slow accept路径,即原生的paxos算法两阶段流程。
Leaderless设计的一个好处是可以提供集群层面更好的可用性保证,在基于raft [23]或primary/backup [3]的设计中,通常采用租约的方式来保证系统中同一时刻只有一个Raft leader或primary节点,以避免在网络分区等情况下产生“多主”问题。租约方式的不足是,租约期设置太小容易导致误判,网络抖动被认为是节点不可用;租约期设置太大,又会导致真正故障发生时,上一任租约过期到选出新租约持有节点的间隔较长,这个过度窗口期整个集群是不可用的,会影响系统的SLA。
如下图所示(图片来源[7]),Paxos算法天然具备leaderless属性,无论是否有稳定的proposer leader节点存在,都可以保证算法的safety,最多牺牲一些liveness。工程实践中,可以通过随机避让和重试等手段来提升paxos实例的liveness。这也是我们选择paxos作为共识算法的原因之一:
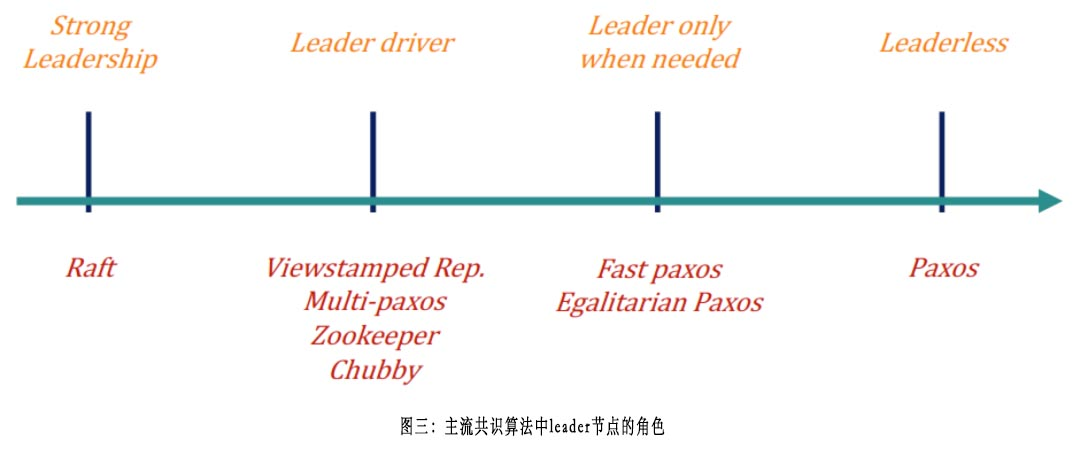
BIGO实际的业务场景中,同一个key从不同的client并发请求,且部分client和其对应的paxoskv节点遭遇网络分区(进而认为节点不可用,转而切换到其它节点重试)发生的概率非常低。所以在向一个节点请求超时后,可以快速换节点发起重试请求,这样系统的不可用时间窗口就大幅降低了。
2.3.2 Log is data
Log is data最早较为正式的起源是新国大2012年VLDB的论文《LogBase: A Scalable Log-structured Database System in the Cloud》[8],目前已经成为云原生数据库架构的重要设计理念之一,主要是为了解决传统WAL + data page数据库架构中写入IO容易成为瓶颈的不足。如下图所示:
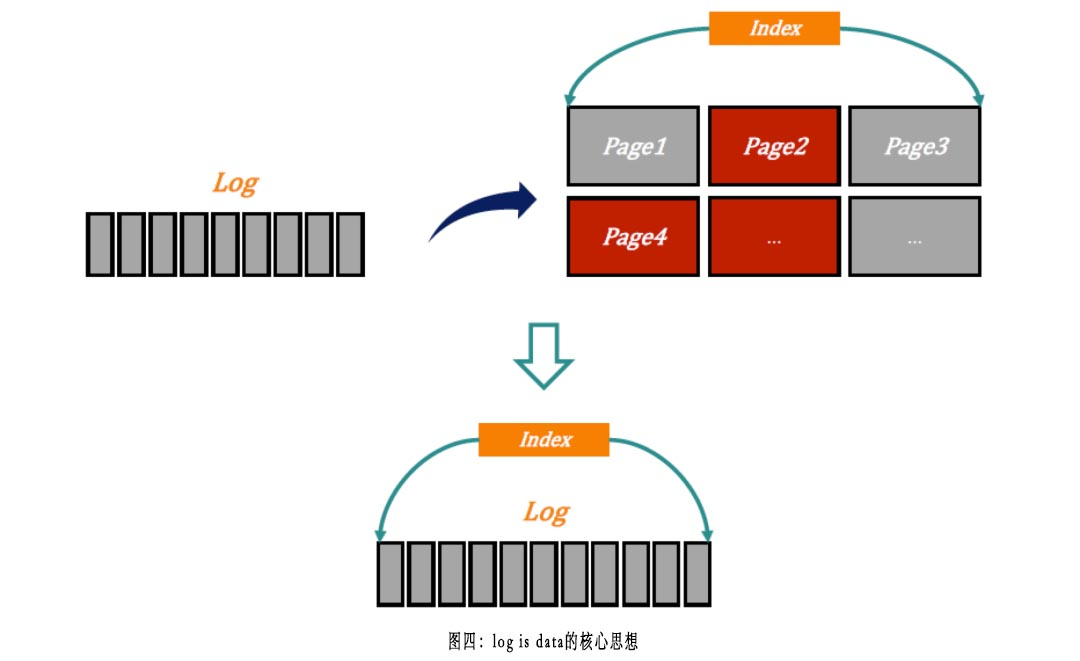
在paxoskv的实现中,value本身是paxos log的一部分,是比较合适采用log is data思想的场景。即BIGO技术把运行paxos达成共识的paxos log和最终对业务提供读/写的value融为一体,无需先写paxos log,再replay paxos log到存储引擎。但paxoskv目前的实现中,还是会带来一定程度的读/写放大,尤其是value较大的场景体现较为明显,采用多版本机制是更合理的方法,这是后续需要优化的方向之一。
2.3.3 Fast accept
如下图所示(图片来源[9]),原生的paxos算法分为两个阶段:第一阶段包含phase-1a propose和phase-1b promise;第二阶段包含phase-2a accept和phase-2b accepted;每一个阶段消耗1个RTT。Paxoskv虽然采用leaderless的架构,但实现中借鉴了主流multi-paxos工程实现中具备stable leader的优化。对于同一个key,如果最新的chosen log其发起者正好是当前节点(Proposer ID会被记录在paxos log的meta信息中),那么就不需要执行原生paxos算法的第一个阶段(phase-1a propose/phase-1b promise),直接发起phase-2a accept请求,我们称paxoskv中的这种流程为fast accept(在具体的工程实现中,为了保证协议的正确性,fast accept的提案会以1:Proposer ID作为提案编号发起,而非fast accept的提案会以2: Proposer ID作为提案编号发起)。因此,大多数集群拓扑稳定的情况下,paxoskv都可以走fast accept路径。
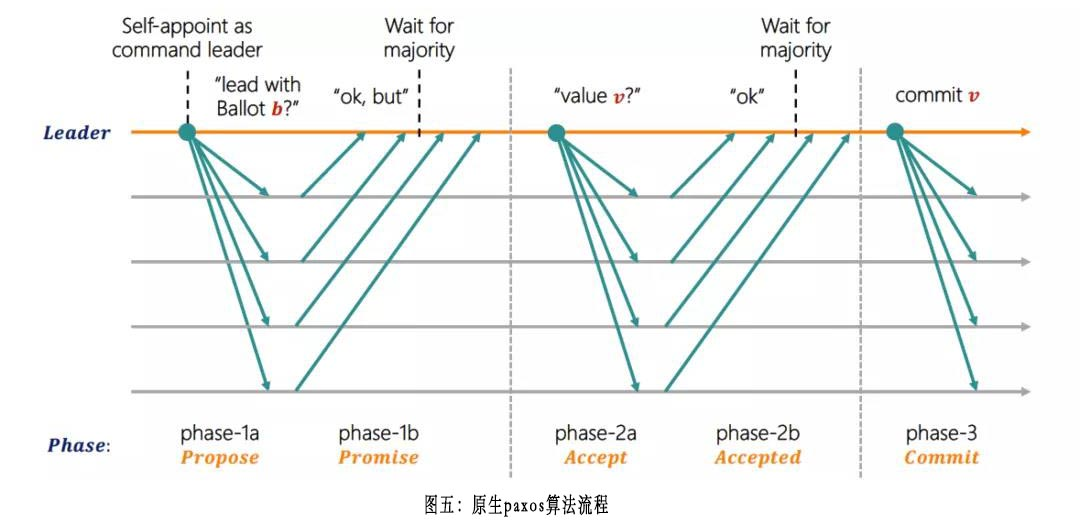
2.3.4 Fast chosen
如下图所示(图片来源[9]),原生的paxos算法中,有Proposer/Acceptor/Learner三个角色,一个典型的paxos算法执行流程如下图所示:
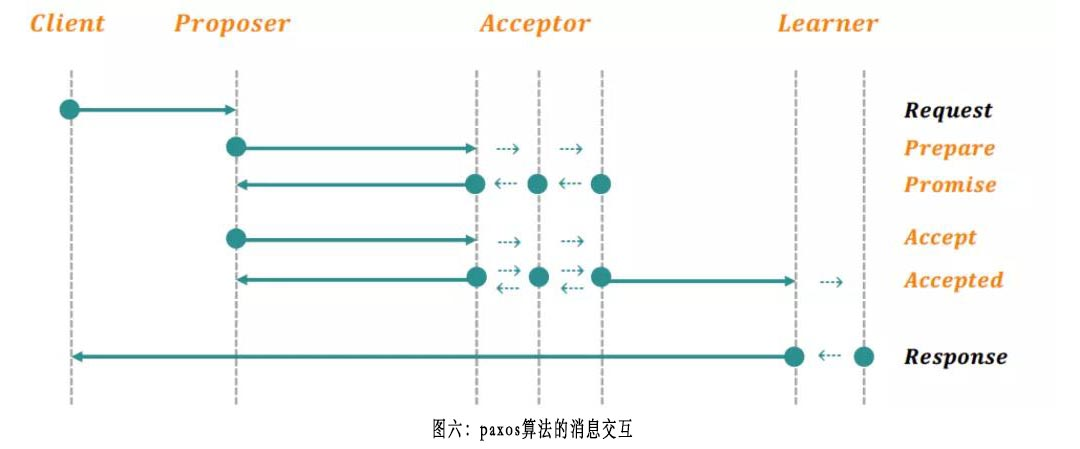
我们可以看到,即便是走fast accept的路径,从发起accept请求到确定一个提案已经chosen,需要1.5个RTT(Proposer → Acceptor → Distinguished Proposer/Learner → Acceptor),在更新频繁的场景,可以在下一个请求之上piggyback上一个提案的chosen通知。注意,如果每一个acceptor在accepted一个提案后,可以广播给所有的Acceptor,以快速确定是否已经满足多数派计数从而达成chosen状态,但工程实现中一般不会这样做,因为消息复杂度太高。
paxoskv的实现中,在3副本的情况下,Proposer会先本地accepted,然后再发送accept请求给acceptors,这样一来,任何一个acceptor只要本地判断满足accepted的条件,加上Proposer的一个accepted计数,就可以确定满足majority accepted的条件,从而快速进入chosen状态。和前面提到的下一个请求之上piggyback上一个提案的chosen通知方式相比,写入的延时没有明显的改善,但这里可以和log is data的思想结合,对于acceptor来说,确定chosen后一次磁盘写入就完成了本次paxos的流程,节省了一次写Rocksdb [10]的IO操作。当然,fast chosen只有在3副本的配置下才能生效(BIGO的实际部署中,目前都是3副本的配置)。
2.3.5 WAL replication
在采用binlog进行复制的系统中,在产生binlog的节点上要面临更新data和binlog原子性的问题。binlog通常又分为基于statement和基于ROW的两种格式,涉及到的问题包含如何保证在其它副本上replay binlog后产生相同的数据页、同时还要考虑同步的binlog的大小、binlog是否可以被并行replay等问题。
在paxoskv的实现中,因为最终存储数据的引擎是Rocksdb [10],所以BIGO技术采用基于Rocksdb WAL log的复制。如下图所示:
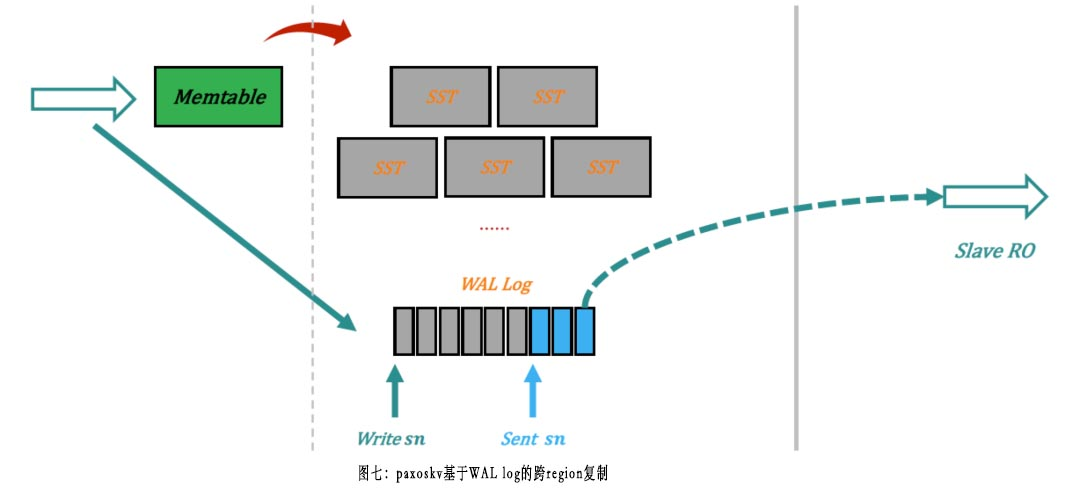
paxoskv WAL replication的实现主要依赖Rocksdb [10]的GetLatestSequenceNumber()和GetUpdatesSince()这两个API。在初始化或者复制中断恢复时,采用pull/push结合的模式来对齐同步位点,具体的实现和MySQL 5.7基于GTID的binlog复制比较类似[11]。
2.3.6 Linearizable quorum read
在强一致的存储系统中,实现线性一致性读写,一般是通过在paxos proposer leader上实现master lease来完成,亦或者从集群中实施多数派读来实现。上述主流实现方式中,leader节点容易成为集群的瓶颈,follower节点的资源则比较难以充分利用。paxoskv针对这个问题,借鉴《Linearizable Quorum Reads in Paxos》[12]中的算法,优化了paxoskv的线性一致性读的流程,实际验证表明性能有80+%以上的提升。
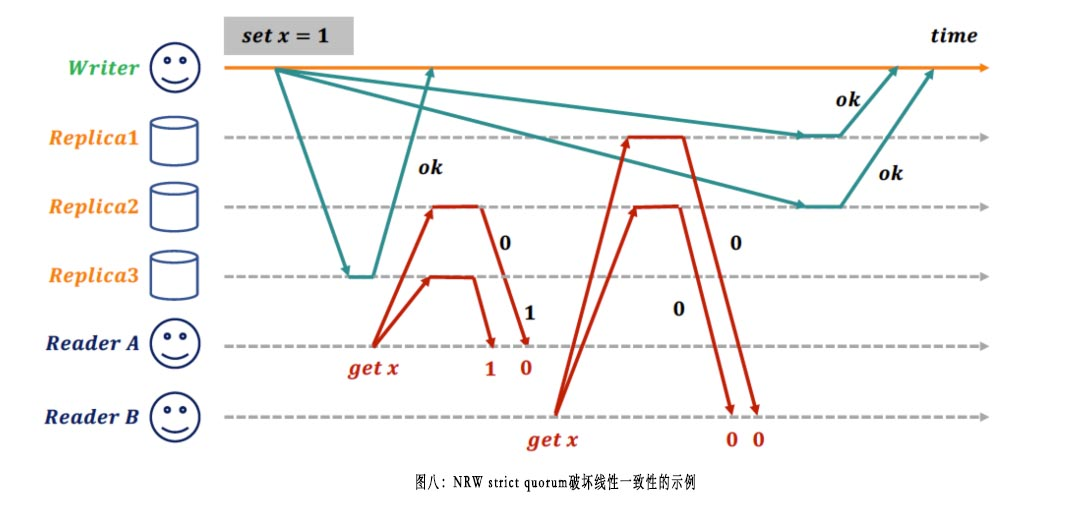
简单的quorum读并不能保证线性一致性,例如传统的NRW模型,即便在选择R + W > N的strict quorum配置下,也会破坏线性一致性。如下图所示,Reader A先发起读请求,返回了新版本的值x=1;此后某个时间点Reader B后发起读请求,却返回了旧版本的值x=0,破坏了线性一致性的约束。图片来源于《Designing Data-Intensive Applications》:
具体的实现算法为Paxos Quorum Reads(简称为PQR),图片来源于《Linearizable Quorum Reads in Paxos》[12]论文:
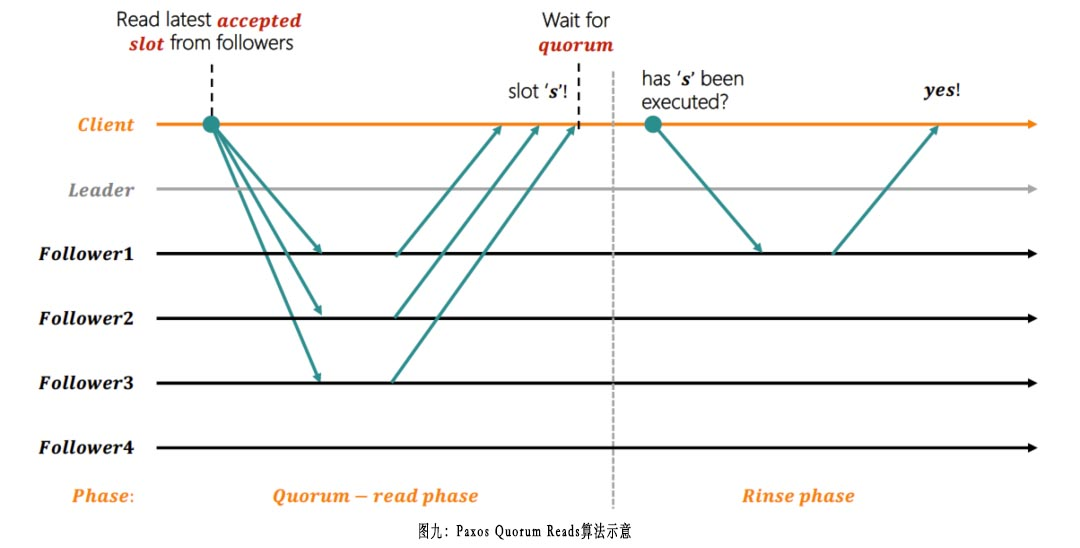
算法分为quorum-read和rinse两个阶段。quorum-read阶段,smart client从除leader之外的多数派中读取最新被accepted的slot。每一个replica不管accepted slot是否存在gap,直接返回自己所见的最大accepted slot,例如某一个replica本地accepted的slot是[1,4]和6,那么返回6给smart client。smart client收集所有回复中最大的accepted slot,作为发起rinse阶段的accepted slot,这个slot的value会作为最终返回给调用的value;但这个accepted的slot可能还没有完成commit,所以smart client必须等待以确保这个slot已经完成持久化的commit,通过这种方式来完成client视角的强一致性。
在rinse阶段中,smart client向quorum-read阶段的replica集合中任意一个replica发送请求,检查对应的accepted slot是否已经被commit。如果被选中的replica回复已经commit,smart client以这个commit的value返回给调用者。
这种方式还是需要2个RTT才能完成强一致性的读,paxoskv在实现的时候,在quorum-read阶段,返回最新的accepted slot和最新的committed slot。如果多数派的replica返回了相同的accepted slot和committed slot,实际上这就是集群中最新的数据;换句话说,保证了线性一致性的约束。因此,paxoskv中大多数场景下,线性一致性都只需要一个RTT就可以完成。
三、总结与展望
自从Paxos算法1989年[9]问世以后,工业界很多重量级产品都基于Paxos算法或其变种来构建高可用能力和提升数据的一致性,例如大家熟悉的Google Chubby [14]、Apache Zookeeper [15],以及比较新的etcd [16]和consul [17]等。但这些实现都强依赖一个中心化的leader节点,所以这类系统基本都只能部署在IDC内,或者同城的IDC之间,我们称这类协议为leader-based的协议。
Paxos [9]算法也一直是学术界的热点,比较新的研究成果包含Mencius [18]协议和EPaxos [19]协议,这两者都属于Leaderless的协议,Mencius [18]协议通过对paxos实例进行静态的预分配,虽然达到了多点写入的目的,但其提交的延时还是依赖于集群中最慢的节点。而EPaxos协议应用于实际工程中,主要的缺陷是通常需要3/4(大于常规的多数派 [n/2]+f)的节点通讯正常,其次是协议工程化复杂度较高。所以虽然Mencius [18]和EPaxos [19]比较好的解决了多点写入的问题,但是由于上述限制,还是无法部署于副本之间延时比较高的场景,比如异地多IDC之间。
应对leader-based协议只能单点写入的另外一个途径是sharding,比如Google Spanner [20]、ZooNet [21]和Bizur [22]等,但这些解决方案美中不足是对数据进行了静态分区,而且以分区为粒度生成multi-paxos log一定程度上降低了并发能力。实际的业务负载中,通常数据的局部性会不时动态变化,因此比较理想的情况是存储系统具备根据业务access patterns和服务器的负载等维度,应用相关的策略来动态调整数据对象的读/写访问接入点。在下一阶段的迭代中,paxoskv将重点打造下面两个主要功能:
3.1 Access patterns/Load aware
前面提到,在同一个set内paxoskv采用一致性hash来将不同的key打散到不同的节点上,但如果业务的key分布相对稳定,即某一部分key都稳定在一个固定的IDC内进行读写,那么一个比较自然的调整就是将这部分key的读写请求发往离client最近的节点,这样达到比较优化的端到端延时。和work stealing [13]设计类似,更通用的抽象是根据不同的access patterns,以不同的key分布策略来动态调整每一个key的就近接入点。与此类似,我们也可以根据节点间的负载,来动态迁移一部分key的接入点,来达到整个集群层面资源利用更合理的效果。
3.2 Lightweight Multi-Key Transaction
paxoskv在BIGO内部上线后,收到了很多反馈和需求,其中大部分是产品化能力加强的需求,其中技术侧比较迫切的需求是实现多个key操作的原子性,比如在赠送相关的业务场景,实质是一个A减B加的过程。paxoskv在下一个迭代中,将提供跨多个set的轻量级multi-key事务。
四、收获与感谢
从paxoskv设计研发到上线落地的过程中,BIGO技术深刻地体会到开发一个健壮的分布式存储系统所面临的挑战和取舍。比如如何测试并验证系统的正确性,如何验证系统在遭遇异常后的自愈能力。再比如我们选择了key粒度的multi-paxos log,虽然带来了多点写入和并发能力提升方面的收益,但是也给集群的成员变更、全局快照备份等方面带来了很大的复杂度。这些问题我们将在后续的介绍中陆续展开,也借这个机会感谢所有给我们提出宝贵建议和反馈的同学们!
参考资料
[1]:http://ssdb.io/zh_cn/
[2]:https://github.com/pika/pika
[3]:https://en.wikipedia.org/wiki/Replication_(computing)#Primary-backup_and_multi-primary_replication
[4]:https://www.cs.cornell.edu/courses/cs6410/2017fa/slides/22-p2p-storage.pdf
[5]:https://cloud.google.com/spanner/docs/replication
[6]:http://muratbuffalo.blogspot.com/2018/11/sdpaxos-building-efficient-semi.html
[7]:https://www.slideshare.net/InfoQ/consensus-why-cant-we-all-just-agree
[8]:http://vldb.org/pvldb/vol5/p1004_hoangtamvo_vldb2012.pdf
[9]:https://en.wikipedia.org/wiki/Paxos_(computer_science)
[10]:https://github.com/facebook/rocksdb
[11]:https://dev.mysql.com/doc/refman/5.7/en/replication-gtids-howto.html
[12]:https://www.usenix.org/system/files/hotstorage19-paper-charapko.pdf
[13]:https://en.wikipedia.org/wiki/Work_stealing
[14]:Chubby,https://static.googleusercontent.com/media/research.google.com/zh-CN//archive/chubby-osdi06.pdf
[15]:Zookeeper,https://github.com/apache/zookeeper
[16]:etcd,https://github.com/etcd-io/etcd
[17]:consul,https://github.com/hashicorp/consul
[18]:Mencius,https://www.usenix.org/legacy/events/osdi08/tech/full_papers/mao/mao.pdf
[19]:EPaxos,https://www.cs.cmu.edu/~dga/papers/epaxos-sosp2013.pdf
[20]:Spanner,https://www.usenix.org/system/files/conference/osdi12/osdi12-final-16.pdf
[21]:Zoonet,https://www.usenix.org/system/files/conference/atc16/atc16_paper-lev-ari.pdf
[22]:Bizur,https://arxiv.org/abs/1702.04242
[23]:Raft,https://www.usenix.org/conference/atc14/technical-sessions/presentation/ongaro
[24]:WPaxos,https://cse.buffalo.edu/tech-reports/2017-01.pdf
[25]:http://courses.cse.tamu.edu/caverlee/csce438/readings/dynamo-paper.pdf
(稿件来源BIGO技术自媒体)
