

前言
序列化,简单来说,就是将对象数据,按照一定的规则,转成一串有迹可循的二进制流,然后将此二进制流在双方中传输。其中,输出方按照约定的规则转译对象,接收方按照约定的规则进行翻译,从而获得有效数据。
应对Android的日常开发中,出镜率最高的序列化手段无非Serializable、以及Parcelable。也常将二者进行比较,以其各自的优劣势来应对不同的场景。
Serializable有进行过分析 (我是传送门),对于Serializable的整体实现也算有个认识,简单做个回顾:
- Serializable 将对象当成一颗树,遍历并反射各个节点获取信息。期间产生很多中间变量来保存信息
- 提供来一些可实现的对象方法,可以在序列化、反序列化过程中做一些处理,比如替换对象、比如加解密,比如默认值(包括以对象为粒度的默认值)
- 可以实现 ObjectOutputStream.writeObjectOverride() 和 ObjectInputStream.readObjectOverride()来完全控制序列化、反序列化过程
本篇文章的目的,将分析Parcelable实现原理,一者可以明白其实现;二者可以更好地与Serializable进行比较;三者对于序列化所要到达的目的考量也会有较清晰的认识。
本文将会回答以下问题,如果你不知道答案,或许有些帮助:
- Parcelable 如何实现
- 为什么序列化与反序列化要保持相同的顺序
- 能否自行实现Parcel
- 子类是否需要实现Parcelable
- Parcelable 真的比 Serializable 快吗
Parcel存储
实际上,Parcelable的实现可以用一句话概括:按照顺序,将从标记处获取的信息,加以辅助信息逐个写入存储区域(看完后文会理解这段话)。因此对于Parcelable来说,存储就显得尤为重要。而对于存储,主要实现均由Parcel.cpp来完成。
Parcel.cpp的出现,是为了应对IPC过程中的数据传输问题而出现的,这一点从Parcel.cpp位于Binder包下可窥探一二。以及为了intercode communication,这一点从Java侧能享用,以及Parcel.cpp的存储方式能看出。进程间通信需要序列化参与,而Serializable以Java实现,天然就无法解决此问题。得益于Parcel.cpp,Parcelable借势来处理一些对性能要求较高的场景了,比如面对Intent。
Parcel.cpp位于
platform/frameworks/native/libs/bilder/Parcel.cpp
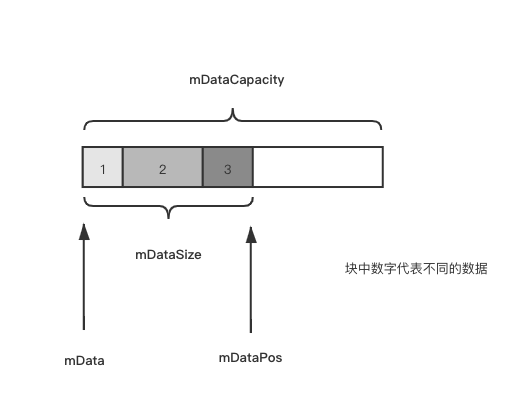
对于理解Parcel.cpp,以下成员变量需要了解
uint8_t* mData; //缓存数据的首地址
size_t mDataSize; //当前数据大小
size_t mDataCapacity; //数据总容量
mutable size_t mDataPos; //下一个数据的首地址
用图理解是这样的
template<class T>
status_t Parcel::writeAligned(T val) {
COMPILE_TIME_ASSERT_FUNCTION_SCOPE(PAD_SIZE_UNSAFE(sizeof(T)) == sizeof(T));
if ((mDataPos+sizeof(val)) <= mDataCapacity) {
//计算当前容量是否还能容得下新数据
restart_write:
// mData+mDataPos地址为指针T*,值为val
*reinterpret_cast<T*>(mData+mDataPos) = val;
// 修改偏移地址,也就是mDataPos
return finishWrite(sizeof(val));
}
// 当前容量不够,增加容量
status_t err = growData(sizeof(val));
// 增加容量成功,跳转到restart_write执行
if (err == NO_ERROR) goto restart_write;
// NO_ERROR 代表函数按预期执行
return err;
}
结合上图,Parcel.cpp存储的,实际上,是连续的各种类型的对象。也因此存在一条规则,即使用Parcel.cpp来存储,必须要清楚,在哪个位置,存储的是什么类型的数据,这是后话了。当然Parcel.cpp也提供了诸如write()等方法,来将一数据,通过memcpy()写入mDataPos后的存储区域。
有写入,就有读出,对应的函数为readAligned()
template<class T>
status_t Parcel::readAligned(T *pArg) const {
COMPILE_TIME_ASSERT_FUNCTION_SCOPE(PAD_SIZE_UNSAFE(sizeof(T)) == sizeof(T));
if ((mDataPos+sizeof(T)) <= mDataSize) {
//检查要读取的数据是否越界
if (mObjectsSize > 0) {
// 检查数据能否被正确读取
status_t err = validateReadData(mDataPos + sizeof(T));
if(err != NO_ERROR) {
// 这段区域的数据无法正常读取,但是偏移值还是要修改 mDataPos += sizeof(T);
return err;
}
}
// 要读取的数据的物理地址
const void* data = mData+mDataPos;
// 更新偏移地址
mDataPos += sizeof(T);
// data的数据类型为T,pArg指向它
*pArg = *reinterpret_cast<const T*>(data);
return NO_ERROR;
} else {
return NOT_ENOUGH_DATA;
}
}
Parcel.cpp对于存储区域的内容,没有做过多的限制,这也是足够灵活的原因。如果你愿意你大可以借助Parcel.cpp来实现自己的序列化方式,并能享受到Parcelable所能享受的优势。
在Java侧,当然不会让开发者直接操作Parcel.cpp,与之对应的也就是Parcel。为了便于区分,在之后的内容Parcel指的是Java侧的Parcel,Parcel.cpp如其名为C++的。
Parcel定义了足够多的Native方法,通过JNI,与Parcel.cpp建立连接并进行对应的操作,文件位于:
frameworks/base/core/jni/android_os_Parcel.cpp
Parcel在实例化时,通过Native方法nativeCreate()能拿到Parcel.cpp实例的句柄值,Parcel在做各种操作的时候,需要此句柄来操作Parcel.cpp。句柄存于Parcel成员变量mNativePtr。
一般来说,我们极少接触到Parcel,能利用到Parcel.cpp所带来的优势,均是通过Parcelable得以体验。Parcelable可以理解为系统实现的一套以Parcel为基础实现的序列化方案,除了必要之处,屏蔽了要对Parcel的了解。
实际上,对于Parcel的使用相当自由。如果你愿意以Parcel为基础实现一套序列化机制,解决序列化过程中的一些中间问题,如数据的读写规则、如何找到对应对象的数据等问题。也就可将Parcel用于你的其他场景。
Parcelable如何实现
使用Parcel要求实现Parcelable,其中:
- 实现writeToParcel(),指明序列化时要写出的数据
- 实现参数为Parcel的实例化方法,指明反序列化时,要读入的数据
- 实现static final成员变量Creator,以提供创建对象实例的入口
不妨从Activity的跳转过程看看Parcel的使用。
数据写入
首先,可以通过Bundle.putParcelable()向Intent传入额外参数。
public void putParcelable(@Nullable String key, @Nullable Parcelable value) {
// 解析Parcel,将Parcel中的数据,放入mMap
unparcel();
// 将Parcelable进行K,V存储
mMap.put(key, value);
mFlags &= ~FLAG_HAS_FDS_KNOWN;
}
在Bundle中,mMap用来存储额外的数据。unparcel()是为了将数据统一放入mMap中,后续统一序列化。
在Activity启动过程中,由AMS完成进程通信,期间,将调用Intent.writeToParcel()将所有必要数据进行序列化,并完成传输。
public void writeToParcel(Parcel out, int flags) {
..... // 除了Bundle外,还会向out中写入其他各种信息,入mAction、mIdentifier、mPackage、mComponent等,此处忽略这些代码
out.writeBundle(mExtras);
}
-> Parcel.writeBundle()
-> Bundle.writeToParcel()
-> BaseBundle.writeToParcelInner()
void writeToParcelInner(Parcel parcel, int flags) {
if (parcel.hasReadWriteHelper()) {
// 有ReadWriteHelper,默认为ReadWriteHelper.DEFAULT,
// 将数据压入mMap
unparcel();
}
final ArrayMap<String, Object> map;
synchronized (this) {
// 上面的unparcel()实际上,会将mParcelladData取出
// 如果走到这里,说明数据经过辗转,又存到了mParcelladData
// 也就是说这里和上面的if判断实际上应该是互斥的
if (mParcelledData != null) {
if (mParcelledData == NoImagePreloadHolder.EMPTY_PARCEL) {
// 无数据,写入Int的0作为标志
parcel.writeInt(0);
} else {
int length = mParcelledData.dataSize();
parcel.writeInt(length);
parcel.writeInt(mParcelledByNative ? BUNDLE_MAGIC_NATIVE : BUNDLE_MAGIC);
// 最终通过Parcel.cpp.appendFrom() 将mParcelledData的数据内容拷贝到parcel中
parcel.appendFrom(mParcelledData, 0, length);
}
return;
}
map = mMap;
}
// 无数据,写入Int的0作为标志
if (map == null || map.size() <= 0) {
parcel.writeInt(0);
return;
}
// 实际上是 Parcel.cpp.mDataPos
int lengthPos = parcel.dataPosition();
// 写入临时占用位
parcel.writeInt(-1);
// 写入魔数
parcel.writeInt(BUNDLE_MAGIC);
// 也是Parcel.cpp.mDataPos,但这个时候多了 占用位 + 魔数 长路的偏移量
int startPos = parcel.dataPosition();
// 写入map
parcel.writeArrayMapInternal(map);
// 最终Parcel.cpp.mDataPos的位置
int endPos = parcel.dataPosition();
// 回到lengthPos位置
parcel.setDataPosition(lengthPos);
int length = endPos - startPos;
// 在前面占用的位置上,写入长度信息
parcel.writeInt(length);
// 恢复Parcel.cpp.mDataPos到正确的位置
parcel.setDataPosition(endPos);
}
以上需要注意的是:
- mMap和mParcelladData是竞争关系,数据只会从其中一个位置存入
- 数据最终被写入Parcel.cpp中,其中,写入的数据,第一个数据为 魔数 + 真正数据的长度
void writeArrayMapInternal(@Nullable ArrayMap<String, Object> val) {
//
final int N = val.size();
// 写入有多少数据
writeInt(N);
int startPos;
for (int i=0; i<N; i++) {
if (DEBUG_ARRAY_MAP) startPos = dataPosition();
// 写入 key
writeString(val.keyAt(i));
// 写入 Object
writeValue(val.valueAt(i));
//
}
}
public final void writeValue(@Nullable Object v) {
//此方法将会按照v类型的不同,执行不同的写入,省略其他
......
else if (v instanceof Parcelable) {
// VAL_PARCELABLE 用来标记为Pacelable类型
writeInt(VAL_PARCELABLE);
writeParcelable((Parcelable) v, 0);
}
......
}
public final void writeParcelable(@Nullable Parcelable p, int parcelableFlags) {
if (p == null) {
writeString(null);
return;
}
// 这里是写入类名
writeParcelableCreator(p);
// 调用对象类实现的writeToParcel()方法
p.writeToParcel(this, parcelableFlags);
}
序列化完后,Intent中的Parcel的存储情况是这样的:

左右部分为Activity启动过程写入的其他信息,length为Bundle数据长度,magic为标示,N为数据量,然后,是连续的K/V,K/V中包含一个Int,用来标志对象类型。
value的写入,就完全交给对象的实现类实现writeToParcel()来写入。value还可以继续往下细分格式,因为在Parcelable.writeToParcel()中写入数据时,最终还是会来到Parcel.writeValue()
数据读出
获取数据,则是通过Bundle.getParcelable()
public <T extends Parcelable> T getParcelable(@Nullable String key) {
unparcel();
Object o = mMap.get(key);
if (o == null) {
return null;
}
try {
return (T) o;
}
.....
}
-> BaseBundle.unparcel()
-> BaseBundle.initializeFromParcelLocked()
-> Parcel.readArrayMapInternal()
void readArrayMapInternal(@NonNull ArrayMap outVal, int N,
@Nullable ClassLoader loader) {
// N 是在前一步initializeFromParcelLocked()通过Parcel.readInt()读出
......
// 数据起始位置
int startPos;
while (N > 0) {
if (DEBUG_ARRAY_MAP) startPos = dataPosition();
// key
String key = readString();
// 读出value,value包含int(标志对象类型)和数据信息
Object value = readValue(loader);
......
// 存入mMap中
outVal.append(key, value);
N--;
}
outVal.validate();
}
在将数据从Parcel.cpp解压到Bundle.mMap中后,就可以使用K/V获取到具体的对象。在序列化时,有Parcel.writeValue()将对象按类型写入,在反序列化时,就有Parcel.readValue()按照对象类型读出,只看Parcelable相关部分
-> Parcel.readValue()
-> Parcel.readParcelable()
public final <T extends Parcelable> T readParcelable(@Nullable ClassLoader loader) {
// 获取到对象声明的public static final Creator<Phone> CREATOR
Parcelable.Creator<?> creator = readParcelableCreator(loader);
if (creator == null) {
return null;
}
if (creator instanceof Parcelable.ClassLoaderCreator<?>) {
Parcelable.ClassLoaderCreator<?> classLoaderCreator =
(Parcelable.ClassLoaderCreator<?>) creator;
// 执行createFromParcel()创建对象,并对象的数据填充
return (T) classLoaderCreator.createFromParcel(this, loader);
}
return (T) creator.createFromParcel(this);
}
readParcelableCreator()代码不贴出,内容是使用反射获取到对象类的以下声明
public static final Creator <xxx> CREATOR
这段代码就解决了为什么要声明CREATOR,也解释了Parcelable如何反序列化。 结合之前的内容,在序列化时,对象有执行时机,执行writeToParcel()来决定自身的数据如何写入;在反序列化时,通过CREATOR调用到带Parcel参数的实例化方来,来决定反序列化的出数据如何填充。
这也不难看出,为什么对象类在实现序列化与反序列化时,读入和写出的数据,要保持一致。但,这也不是绝对的。
之前说过,对于Parcel的使用可以非常灵活。对于读入和写出的数据要保持一致,也就意味着对象对内容有足够的控制权。借助系统Activity的启动过程看Parcel的内容变动,不难看出,需要解决的事写入的内容如何分布,而对有效用的内容不会做任何的拆解。因此大可以在序列化时写入一些特殊的信息,在反序列化前取出即可。在使用Parcel进行序列化时,所有的信息存于一块连续的内存区域,包含助记信息、数据信息。反序列化就变成了如何借助助记信息,查找到数据信息了。如果跳出Activity的启动来看,想借助Parcel并实现一套序列化以应对其他的场景时,自然就要考虑信息如何分布,数据信息如何查找等问题了。
如果你想的话,你完全可以不实现Parcelable,使用Parcel提供的其他函数,也可以实现Parcel为核心的序列化,只不过比较麻烦罢了。
小结
Parcel序列化的原理总结为:
- 实际存储由Parcel.cpp负责,在一块连续的内存区域的中,写入各类信息。Parcel在实例化时,拿到Parcel.cpp的实例的句柄
- Parcel在序列化写入数据时,遵循I-V的形式,其中I指数据类型,V指实际数据
- 要序列化的对象实现Parcelable,其中writeToParcel()在序列化过程中获得执行时机,对象负责写入数据。CREATOR在反序列化时被调用,调用对象构造函数,将Parcel传入以让对象填充数据
Parcelable VS Serializable
Parcelable常会用来与Serializable进行比较,但Parcelable要比Serializable速度差异,需要进行测试对比。
准备以下序列化对象:
public class Phone implements Parcelable, Serializable {
private String brand;
private int price;
public Phone(String brand, int price) {
this.brand = brand;
this.price = price;
}
protected Phone(Parcel in) {
// 测试需要,这个是类名
in.readString();
brand = in.readString();
price = in.readInt();
}
public static final Creator<Phone> CREATOR = new Creator<Phone>() {
@Override
public Phone createFromParcel(Parcel in) {
return new Phone(in);
}
@Override
public Phone[] newArray(int size) {
return new Phone[size];
}
};
@Override
public int describeContents() {
return 0;
}
@Override
public void writeToParcel(Parcel dest, int flags) {
dest.writeString(brand);
dest.writeInt(price);
}
接着是测试例子,计算两种方式的单次序列化和反序列化时间
private void doParcalable() {
long writeStart;
long writeEnd;
long readStart;
long readEnd;
Parcel parcel;
int dataStartPos;
Phone curPhone;
parcel = Parcel.obtain();
curPhone = createPhone();
writeStart = System.nanoTime();
dataStartPos = parcel.dataPosition();
parcel.writeParcelable(curPhone, 0);
writeEnd = System.nanoTime();
int length = parcel.marshall().length;
parcel.setDataPosition(dataStartPos);
readStart = System.nanoTime();
Phone.CREATOR.createFromParcel(parcel);
readEnd = System.nanoTime();
Log.d(TAG, "parcel: " +
(writeEnd - writeStart) / 1_000 + "微秒; unparcel: " +
(readEnd - readStart) / 1_000 +
"微秒; Size: " + length);
}
private void doSerializable() {
long writeStart;
long writeEnd;
long readStart;
long readEnd;
ByteArrayOutputStream dataOut;
ByteArrayInputStream dataIn;
try {
ObjectOutputStream out;
ObjectInputStream in;
dataOut = new ByteArrayOutputStream();
out = new ObjectOutputStream(dataOut);
Phone phone = createPhone();
writeStart = System.nanoTime();
out.writeObject(phone);
writeEnd = System.nanoTime();
out.flush();
byte[] data = dataOut.toByteArray();
int lenght = data.length;
dataIn = new ByteArrayInputStream(data);
readStart = System.nanoTime();
in = new ObjectInputStream(dataIn);
in.readObject();
readEnd = System.nanoTime();
Log.d(TAG, "Serialiazable: " + (writeEnd - writeStart) / 1_000
+ "微秒; unparcel: " + (readEnd - readStart) / 1_000
+ " 微秒; Size: " + lenght);
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
执行结果为
parcel: 67微秒; unparcel: 17微秒; Size: 68 Serialiazable: 4065微秒; unSerialiazable: 661 微秒; Size: 91
从执行结果上看Parcelable比Serializable快。其中,影响时间的因素有:
- 中间过程。根据Serializable的原理,序列化与反序列化过程要创建大量的中间变量来获取、存储数据。而Parcelable则不用,直接将各种需要的数据写入Parcel.cpp中
- 反射。Serializable使用了大量反射,而反射操作耗时。Parcelable使用了非常少的反射操作,来获取入口,而数据,由对象来读入写出,因此省略了Serializable中必要的通过反射才能获取数据的多数时间
- 存储方式。即数据的存储位置,以及数据本身和助记信息
原则上,比较是要让二者所面对的其他变量相同或者趋于相近才有益,但是因为其他成本,实验条件达不到。因为例子仅供参考,并不精确。
考虑到Serializable可以通过实现writeObject()和readObject()来定义自身对象的写入过程,对例子中添加以下内容
//Phone
private void writeObject(java.io.ObjectOutputStream out) throws IOException {
out.writeUTF(brand);
out.writeInt(price);
}
private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException {
brand = in.readUTF();
price = in.readInt();
}
再执行程序,得到结果如下
parcel: 64微秒; unparcel: 18微秒; Size: 68 Serialiazable: 3264微秒; unSerialiazable: 577 微秒; Size: 93
Serialiazable确实更快了,以为Serialiazable原理来看,规划如何写入写出后,就减少部分了需要反射获取信息的过程,并且当属性越多时,效果越明显。但是还没有达到能与Parcelable媲美的程度。
本以为到这里比较就结束了,直到我看到了这个提问 stackoverflow
Usual Java serialization on an average Android device (if done right *) is about 3.6 times faster than Parcelable for writes and about 1.6 times faster for reads. Also it proves that Java Serialization (if done right) is fast storage mechanism that gives acceptable results even with relatively large object graphs of 11000 objects with 10 fields each. The sidenote is that usually everybody who blindly states that "Parcelable is mush faster" compares it to default automatic serialization, which uses much reflection inside. This is unfair comparison, because Parcelable uses manual (and very complicated) procedure of writing data to the stream. What is usually not mentioned is that standard Java Serializable according to the docs can also be done in a manual way, using writeObject() and readObject() methods. For more info see JavaDocs. This is how it should be done for the best performance.
翻译过来就是,当序列化一个超级大的对象图表(表示通过一个对象,拥有通过某路径能访问到其他很多的对象),并且每个对象有10个以上属性时,并且Serializable实现了writeObject()以及readObject(),在平均每台安卓设备上,Serializable序列化速度大于Parcelable 3.6倍,反序列化速度大于1.6倍.
例子是这样的,构建一种对象类型,此类型能能构成大对象图表
public class TreeNode implements Serializable, Parcelable {
private static final long serialVersionUID = 1L;
public List<TreeNode> children;
public String string0;
public String string1;
public String string2;
public int int0;
public int int1;
public int int2;
public boolean boolean0;
public boolean boolean1;
public boolean boolean2;
public TreeNode() {
}
......
// 这里就省略序列化代码
}
这个对象表示一个树结点。然后,构造一颗深度为5,除了叶节点外,每节点有10个字节点的树
private TreeNode createNode(int level) {
if (level < 4) {
return createRootNode(level + 1);
} else {
return createSimpleNode();
}
}
private TreeNode createRootNode(int level) {
TreeNode root = createSimpleNode();
root.children = new ArrayList<TreeNode>(10);
for (int i = 0; i < 10; i++) {
root.children.add(createNode(level));
}
return root;
}
private TreeNode createSimpleNode() {
TreeNode root = new TreeNode();
root.string0 = "aaaaaaaaaa";
root.string1 = "bbbbbbbbbb";
root.string2 = "cccccccccc";
root.int0 = 111111111;
root.int1 = 222222222;
root.int2 = 333333333;
root.boolean0 = true;
root.boolean1 = false;
root.boolean2 = true;
return root;
}
然后,运行程序序列化这个对象,结果如下:
serialize: 23ms; deserialize: 29ms; size: 614279 parcel: 134ms; unparcel: 40ms; size: 1871036
结果惊喜,序列化结果超过3.6倍,反序列化结果虽然没有达到1.6倍,但是也是Serializable更快。
为什么会这样呢?我在那个提问的回答中,没有找到确切的答案。我想尝试分析。
从上面的输出内容来看,parcel的方式比serialize的方式序列化后,生成了更多的byte信息,多出部分的信息,甚至比serialize方式的产生的所有byte信息多很多。byte的写入读出,必然影响时间,更多的数据要用更多的时间去处理,这一点不难理解。那么,多出的数据从何而来?
Serilazable的实现方式中,是有缓存的概念的,当一个对象被解析过后,将会缓存在HandleTable中,当下一次解析到同一种类型的对象后,便可以向二进制流中,写入对应的缓存索引即可。但是对于Parcel来说,没有这种概念,每一次的序列化都是独立的,每一个对象,都当作一种新的对象以及新的类型的方式来处理。
因此上面结果的差异,就在与助记信息的差异。除去了有效值必须占用的存储空间。
当一个TreeNode对象已经被序列化过,下一个TreeNode再被序列化时,会发生什么。
- 对Serilazable来说,需要 1字节的数据类型标示 + 2字节的对象类型缓存索引位置 + 1字节的新对象标记
- 对Parcel来说:每次进入无差异,为 2字节 * 类名长度 + 4字节类型标记 * 属性数量
虽然针对一种类型初次序列化时,Serilazable需要更多的助记信息,但再次序列化类型已被序列化过的对象时,Serilazable要的信息将少得多。
上面没有提到有效值的占用空间,如果有效值的字面量出现过的话,Serilazable需要的空间更说,只需要2字节的字面量缓存索引。因此,当序列化一个很大的对象图表时,并且大多数对象的类型相同时,Parcel需要更多的助记信息,也就产生了更多的byte数据要写入读出。
也因此,如果上面的对象图表例子中,对象的类型几乎不同时,Parcel将再次占上风。当然这只是我的猜想,我也没法写这个程序来证明。
针对于Parcel比Serilazable更快的例子的原因分析,有不对之处或有更好的见解,烦请指出。
上面的例子能说明一定的问题,Serilazable要受累于他所面对的I/O,毕竟,内存中的数据交换与其他设备中的I/O交换,性能上不是一个量级。而序列化过程,产生的信息量也将直观地影响效率。例子中,尽可能把二者面对的其他因素拉到相似的水平进行比较,如此更公平。
总结
小结处已经对Parcel做过小结,这里以二者序列化的比较作为结束。
Parcel:
- 有出入口方法,让对象自行写入读出数据
- 需要使用方自行补充助记信息
- 在连续的内存空间中存储信息
- 一般来说,在Java侧,以I-V方式存储信息
- 子类不一定需要实现
Serializable:
- 以反射方式获取全量信息,要解析出对象描述,属性描述
- 产生大量中间变量,当有描述缓存时,则可以复用
- 有入口方法,实现后能像Parcel一样,让对象决定读入写出的数据
- 存储方式依赖IO
- 子类需要实现
回答
Parcelable 如何实现
有出入口方法,让对象自行写入读出数据。一般来说,需要实现writeToParcel()、带Parcel参数的实例化函数、以及声明类型为Parcelable.Creator 的静态成员变量CREATOR。数据的存储由Parcel.cpp 在内存中获取一片连续的内存区域来写入。通过Parcel,可向此内存区域写入需要的信息。对象存储的数据,一般以 I(标记的对象类型)-V(实际数据)方式来存储。在反序列化时,可通过CREATOR来访问对象初始化函数,来填充数据。
为什么序列化与反序列化要保持相同的顺序
对象的数据的写入读出由完全由对象自己决定,因此存在一个规则——“这个对象知道它面对的"Parcel里”有什么。保持顺序是需要的,但不是绝对的,因为对象知道它的数据在哪,所以他可以决定用不用或怎样用。
能否自行实现Parcel
能。完全可以以Parcel为基础,实现一套序列化,如果不用提供的出入口方法,实现起来叫麻烦而已。
子类是否需要实现Parcelable
看情况,因为对象决定自身数据的读入写出,当不需要子类的信息时,不需要调用到与子类有关的代码。
Parcelable 真的比 Serializable 快吗
看面对的场景。参考上面的例子,当要序列化的对象,所产生的信息前者远大于后者时,Parcelable自然更慢。
这里不妨反问一句:Serializable的开销真的更大吗?
