

LinkedHashMap
LinkedHashMap 很像一个HashMap 加 一个双向链表,其实HashMap 用于存放数据,而双向链表维护访问顺序,这样的组合功能。在一般的情况下,HashMap的迭代访问是没没有顺序的,但是有些情况下既需要使用HashMap 的高性能,也需要使用到顺序访问的功能,因此就将两者结合起来。
- 首先LinkedHashMap 的put 和HashMap 的put 是一模一样的。但是!!!,LinkedHashMap 覆写了put 中会使用到的newNode方法和afterNodeInsertion方法。
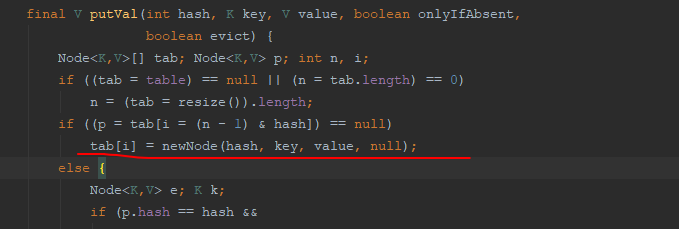
HashMap的newNode
Node<K,V> newNode(int hash, K key, V value, Node<K,V> next) {
return new Node<>(hash, key, value, next);
}
LinkedHashMap的newNode
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
//从这里可以看出,对于新加入的节点,LinkedHashMap 会维护到双向链表的尾部。同时在HashMap 中也维护。
return p;
}
//这是LinkedHashMap 的节点类,和HashMap的Node 不太一样。多了两个节点,用于构建双向链表。
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
//插入到尾部并同时维护双向链表的操作过程
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}
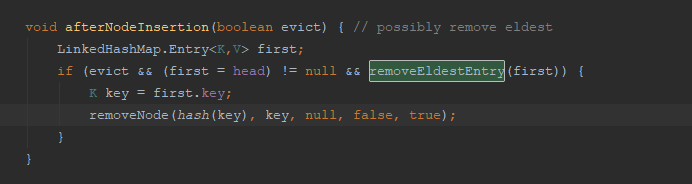
对于后面的afterNodeInsertion()
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
这个方法里面提供了一个插入一个新节点之后,头节点的改变情况,其中,removeEldestEntry(first)可以覆写,
用于实现一些常见的操作。例如我们经常面试中被问及到的LRU算法就可以在这里实现逻辑。
表示的是什么时候需要对头结点进行删除。LinkedHashMap是尾插法,
但是删除的时候这里提供了头部删除逻辑,因此非常适合进行LRU 的实现。
对于accessOrder,主要就是加了一个afterNodeAccess来讲上次访问的元素移到双向链表的后面。这样就可以实现最近浏览的功能。
欣赏一下LinkHashMap的get
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
同时还有迭代器,可以看到到,此时的迭代是在一个新的LinkedEntrySet上执行的。而HashMap 是在EntrySet上执行。
public Set<Map.Entry<K,V>> entrySet() {
Set<Map.Entry<K,V>> es;
return (es = entrySet) == null ? (entrySet = new LinkedEntrySet()) : es;
}
final class LinkedEntrySet extends AbstractSet<Map.Entry<K,V>> {
public final int size() { return size; }
public final void clear() { LinkedHashMap.this.clear(); }
public final Iterator<Map.Entry<K,V>> iterator() {
return new LinkedEntryIterator();
}
//Set迭代的实现流程
public final void forEach(Consumer<? super Map.Entry<K,V>> action) {
if (action == null)
throw new NullPointerException();
int mc = modCount;
for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after)
action.accept(e);
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
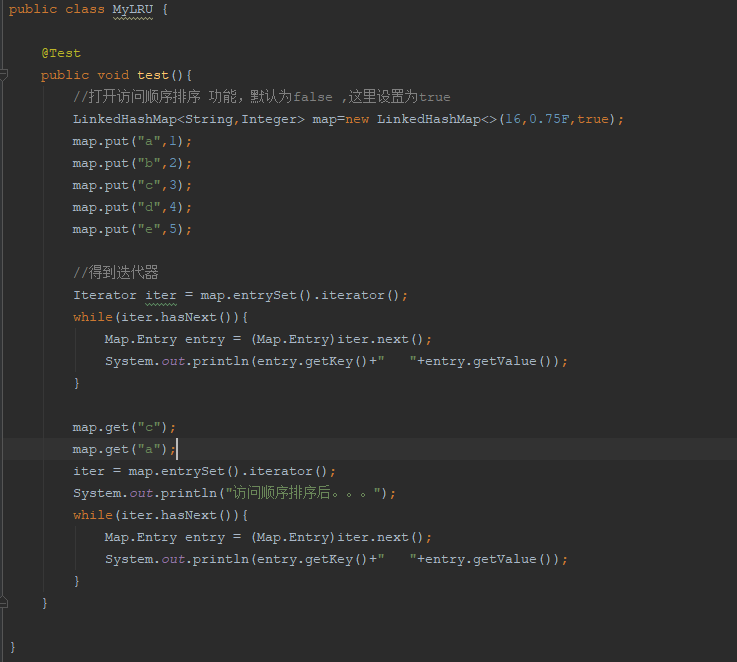
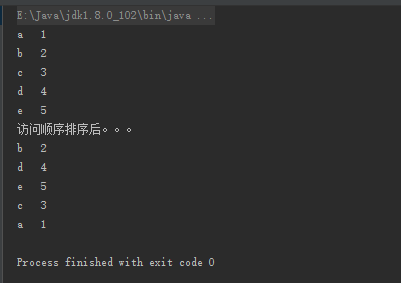
最后附上实现LRU的代码
class LRUCache extends LinkedHashMap{
private int cahceSize = 0;
public LRUCache(int maxSize){
super(maxSize, 0.75F, true);
this.cahceSize = maxSize;
}
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
return size()>cahceSize;
}
}
一波总结
其实和HashMap是基本没有什么区别的,只是我们在操作元素的时候,额外的维护了一个双向链表来保证我们能按顺序地获取和插入元素,而且在迭代的时候实现了自己基于双向链表的跌代器。此外常考的就是实现LRU 算法,这里就是覆写removeEldestEntry()方法的判断逻辑即可。
List 之ArrayList, LinkedList 和 vector
- 首先这三个都是实现了List 接口,但是他们的不同主要表现在线程安全,扩容等方面。
- ArrayList 和vector 底层都是基于数组来实现的,而LinkedList底层是基于双向链表来做的。
- ArrayList是线程不安全的,LinkedList也是线程不安全的,vector 是线程安全的,线程安全的操作是在方法前面加入了synchronized 关键字。
- ArrayList是1.5倍扩容,LinkedList是双向链表,vector是2倍扩容。
- LinkedList提供了index的功能,但是需要额外的开销
- vector 提供了更多的元素遍历方法。
Map 之HashMap , ConcurrentHashMap, HashTable
首先,HashMap是线程不安全的,其他的chm和ht是线程安全的。其中,ht的线程安全是基于方法前面直接加synchronized的,也就是会直接将整个map 锁住,所以在数据访问大的情况下,性能会下降。为此,出现了chm,chm提供了cas加synchronized的方式来实现线程安全,在并发访问的时候只会锁住一个桶而已,不同的桶之间的并发完全可以同步进行。
1.7 和 1.8 的HashMap的改变
- 1.7的HashMap 在发生hash冲突的时候,采用的是单向链表的形式来插入数据的,当碰撞很严重的时候,查询的效率就变成了单向链表的效率。1.8中采用了链表加红黑树的形式来解决hash碰撞,当链表的长度大于8的时候,直接将链表树化成红黑树,这样搜索效率会提高。同时,当红黑树较小的时候,6,会反树化成链表。这是最明显的和1.7的区别
- 1.7是在插入前进行扩容,而1.8是插入后判断再进行扩容的。
- 1.7 是采用的头插法,因为JDK1.7是用单链表进行的纵向延伸,但是头插法时会容易出现逆序且环形链表死循环问题;1.8采用的是尾插法,来避免之前提到的各种问题。
- 扩容后新的位置的计算方式不同 rehash方式详解
1.7 和 1.8 的ConcurrentHashMap
- 将分段锁替换为cas+synchronized.提高并发粒度
- 引入了红黑树和链表组合的方式来避免索索性能的退化
