

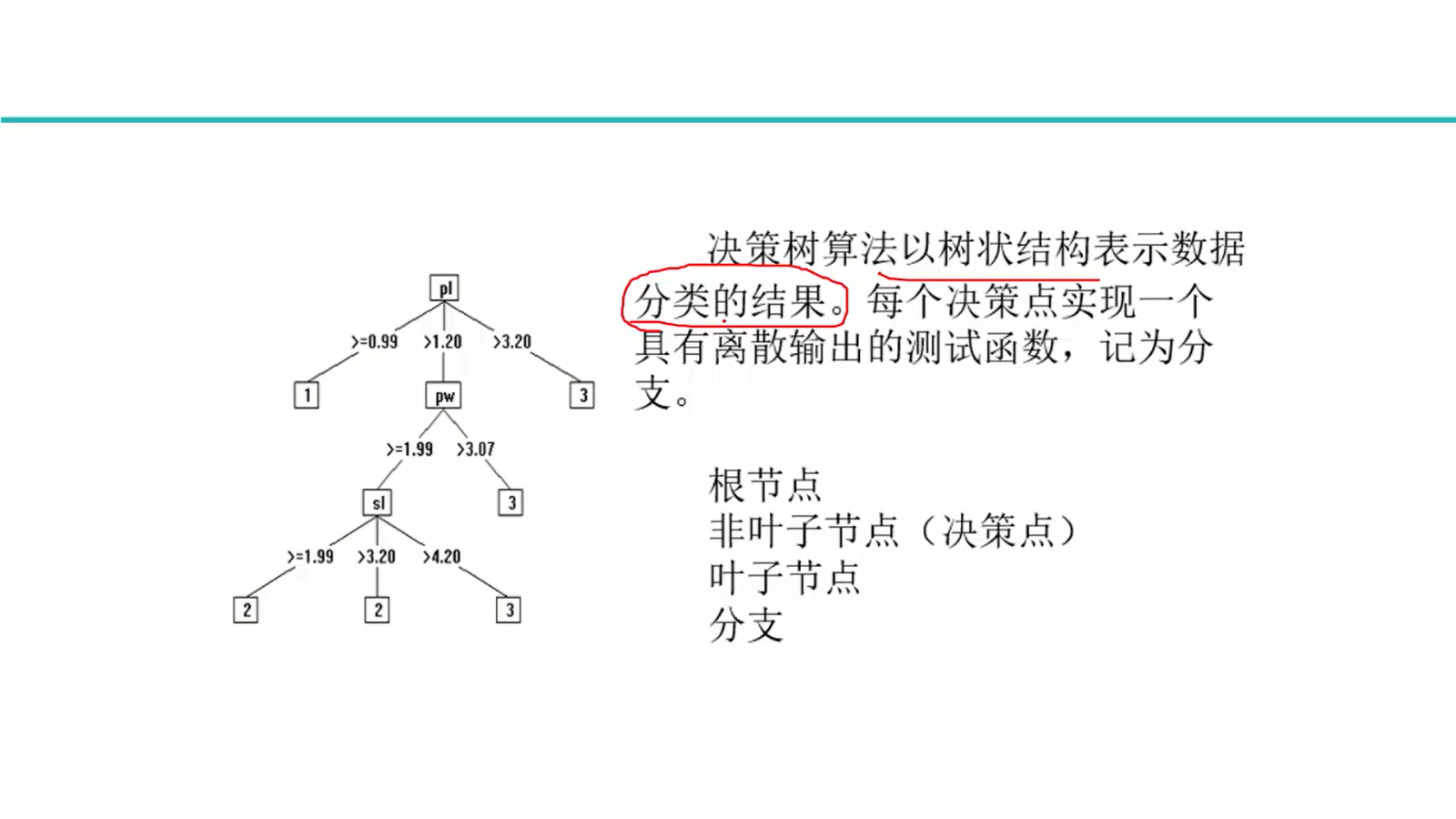
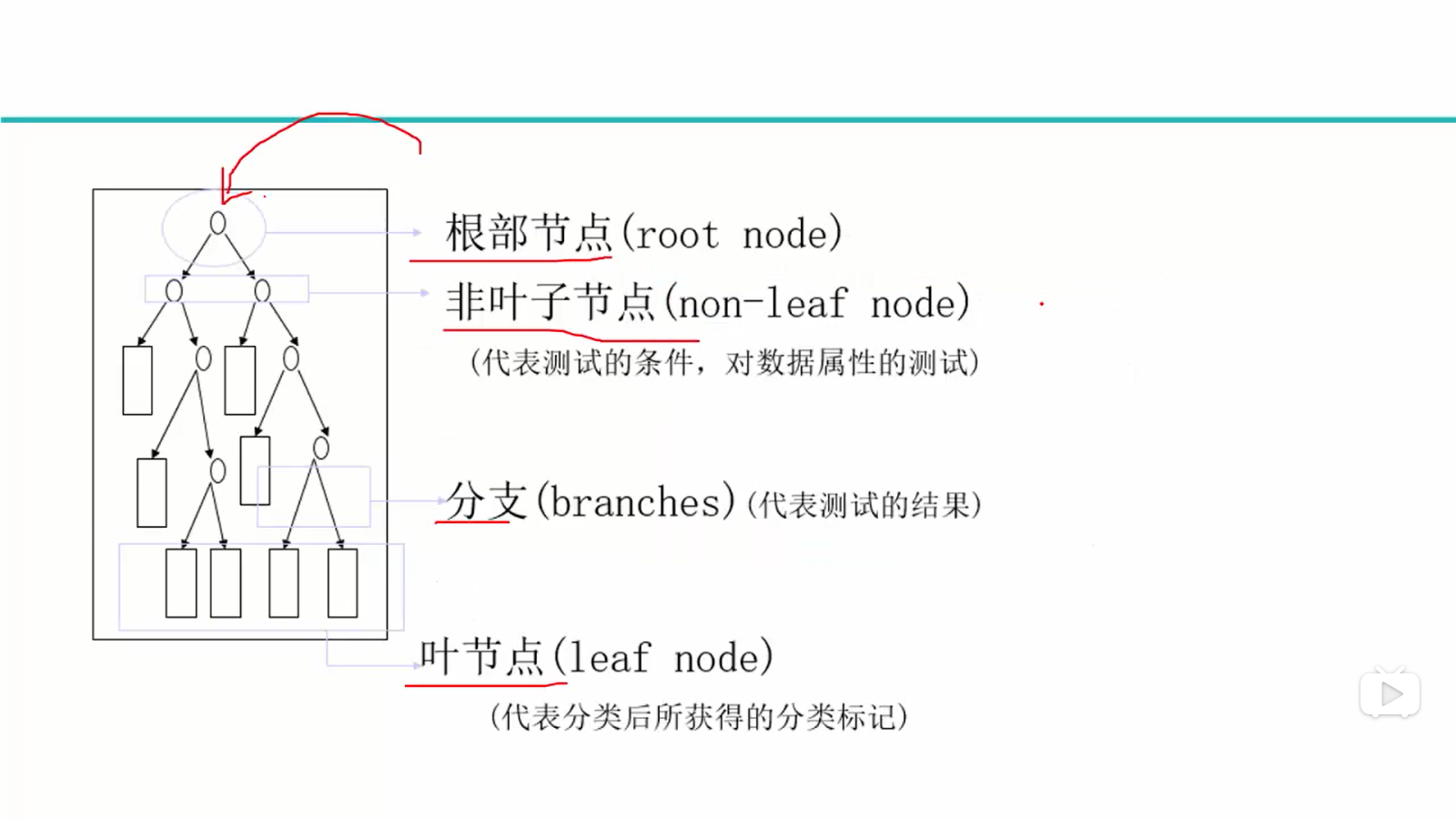
决策树
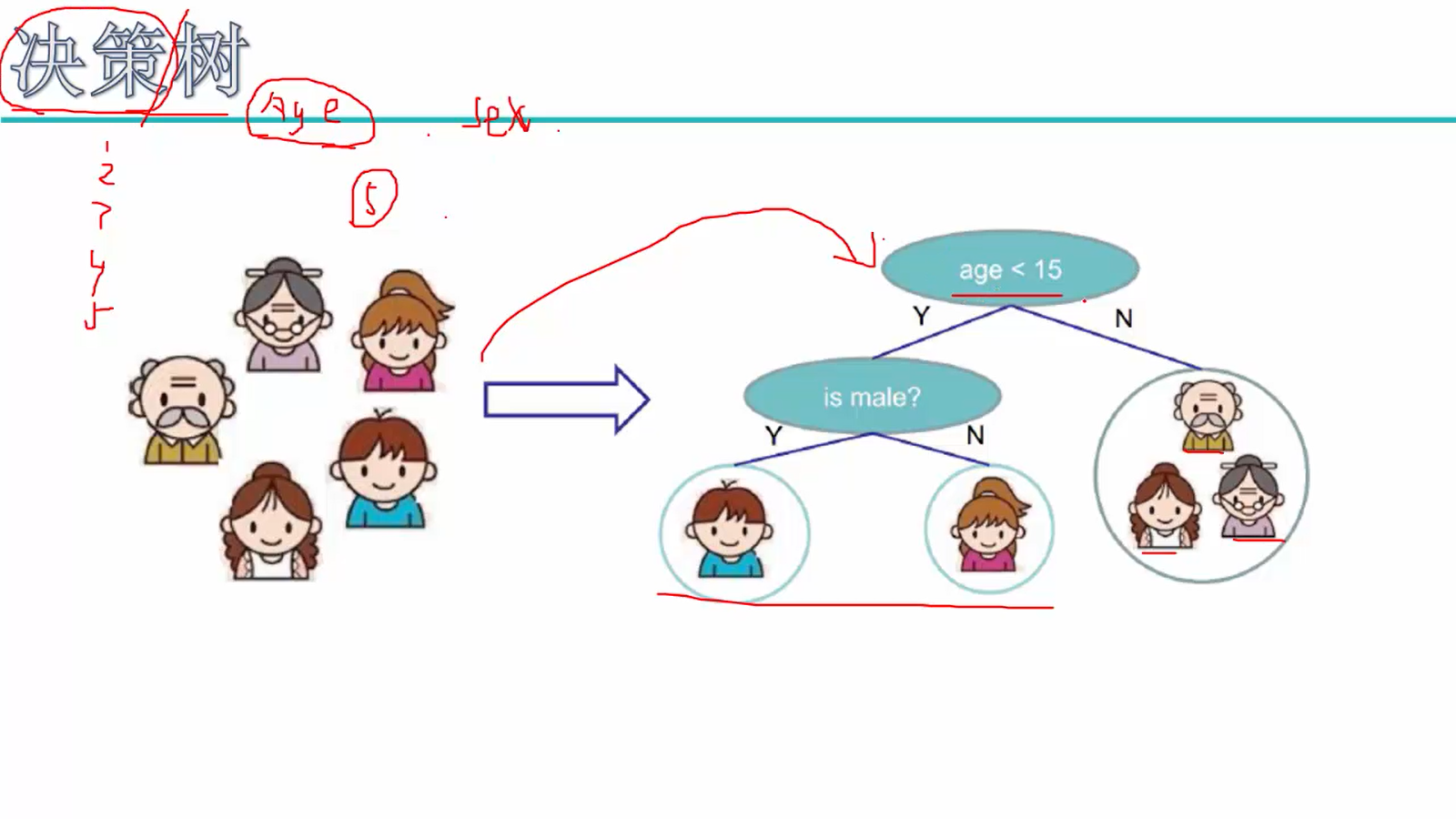
数据从上往下在树中游走,叶子节点就是最终的预测值or回归值
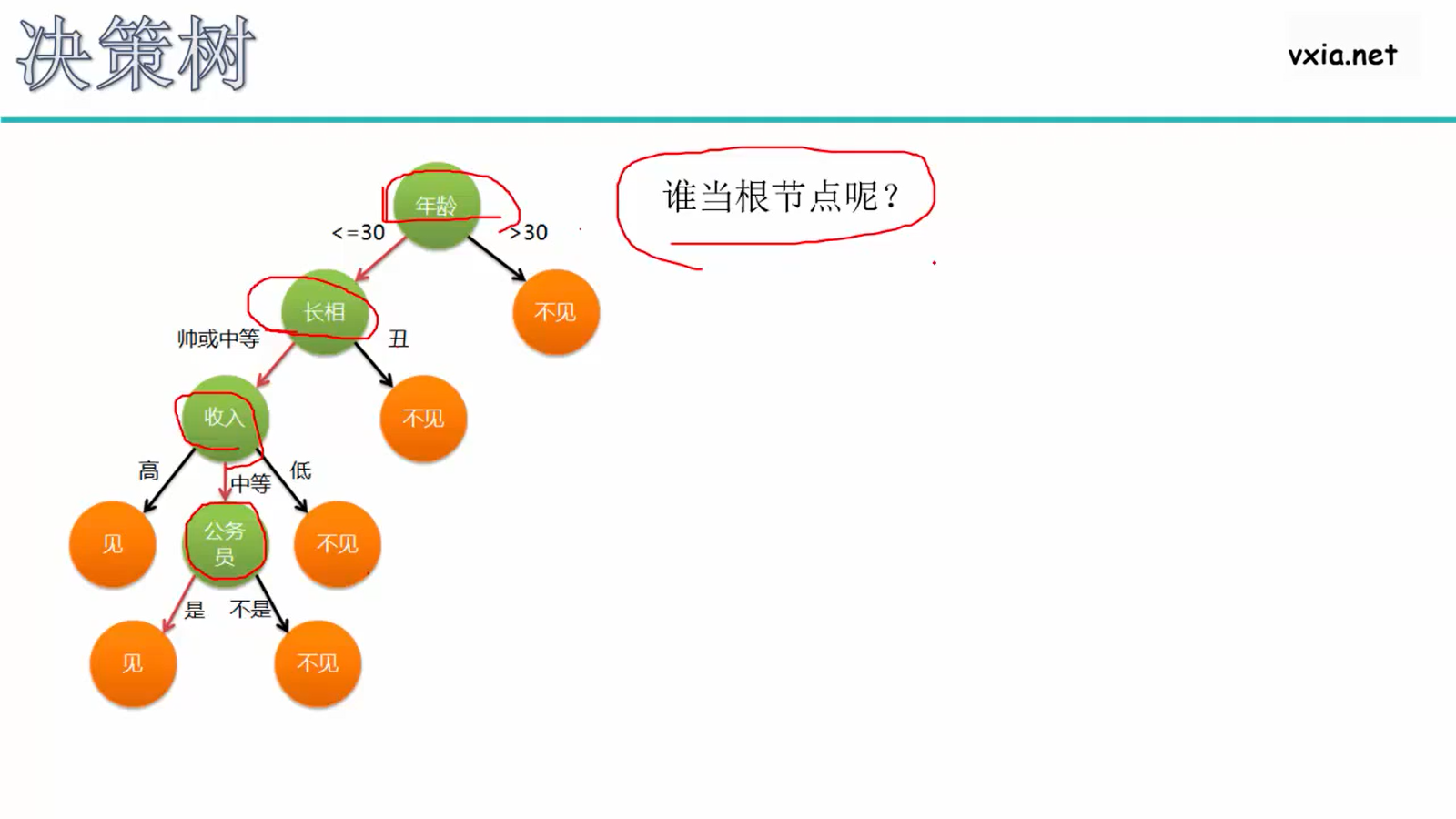
Q:指标age、male是谁定下来的?

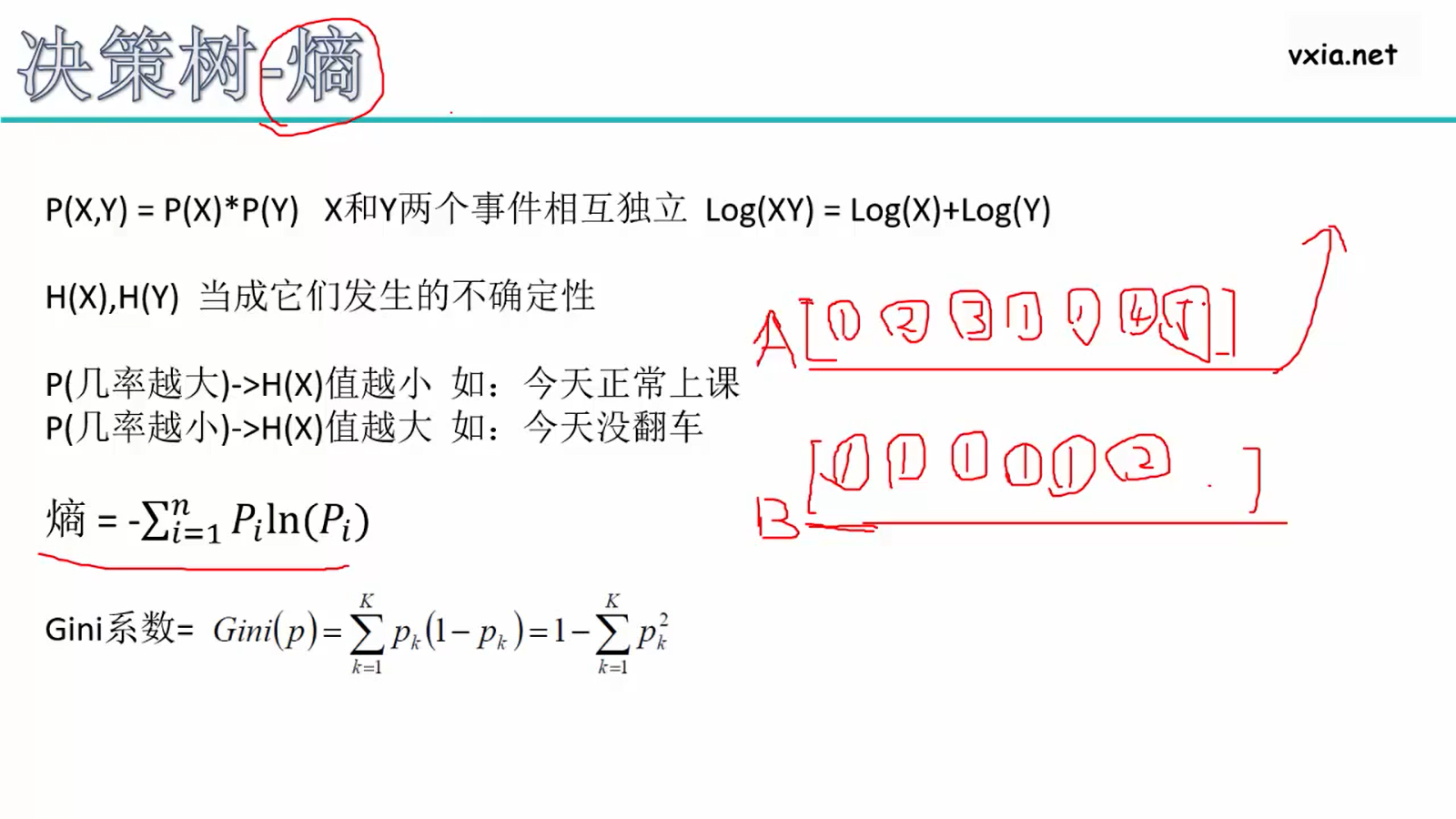
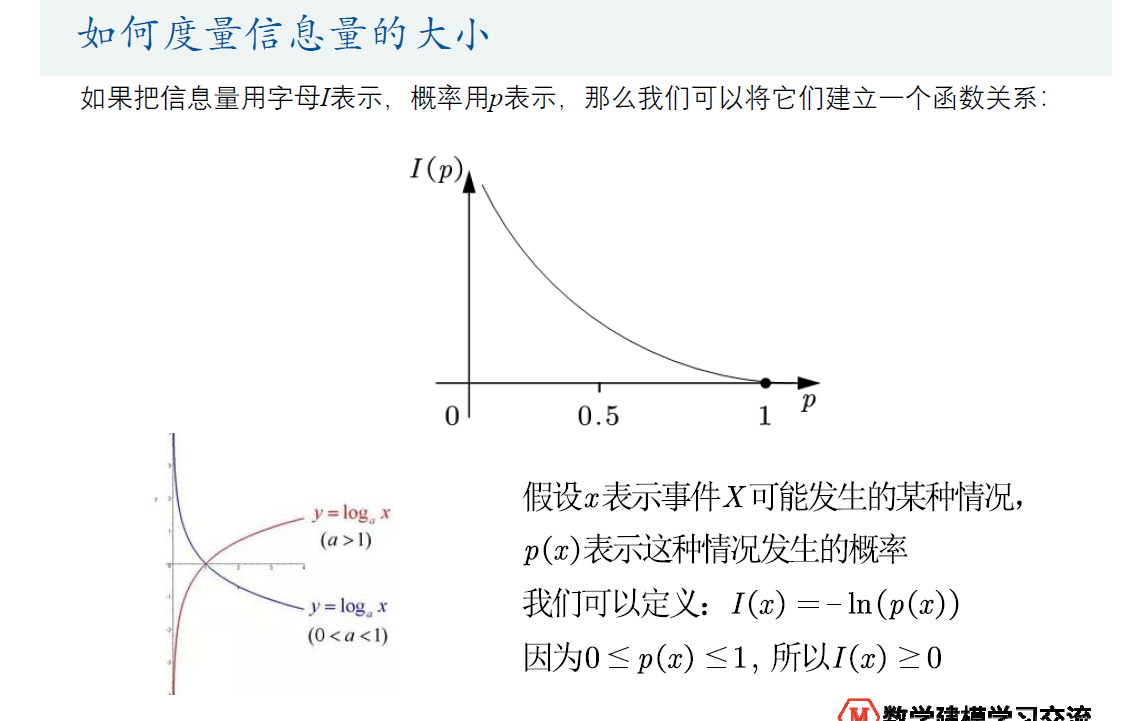

A的熵比较大,对每个类别出现的概率低,ln取负比较大,总和更大
B的熵比较小,1的概率大,ln取负比较小,总和更小
基尼系数,和熵的意义差不多,p越小,Gini越大

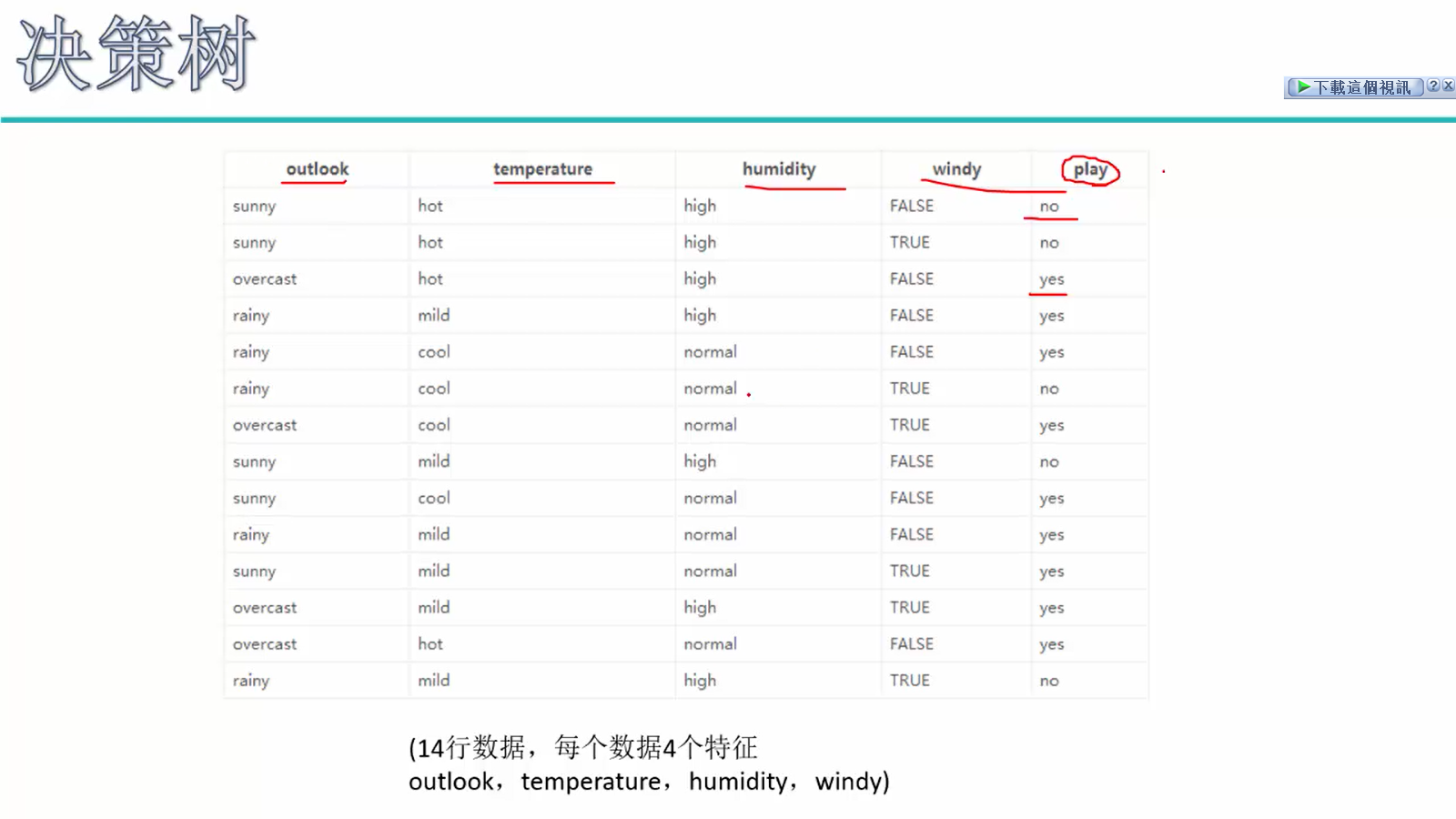

根据labei计算初始熵值=0.940
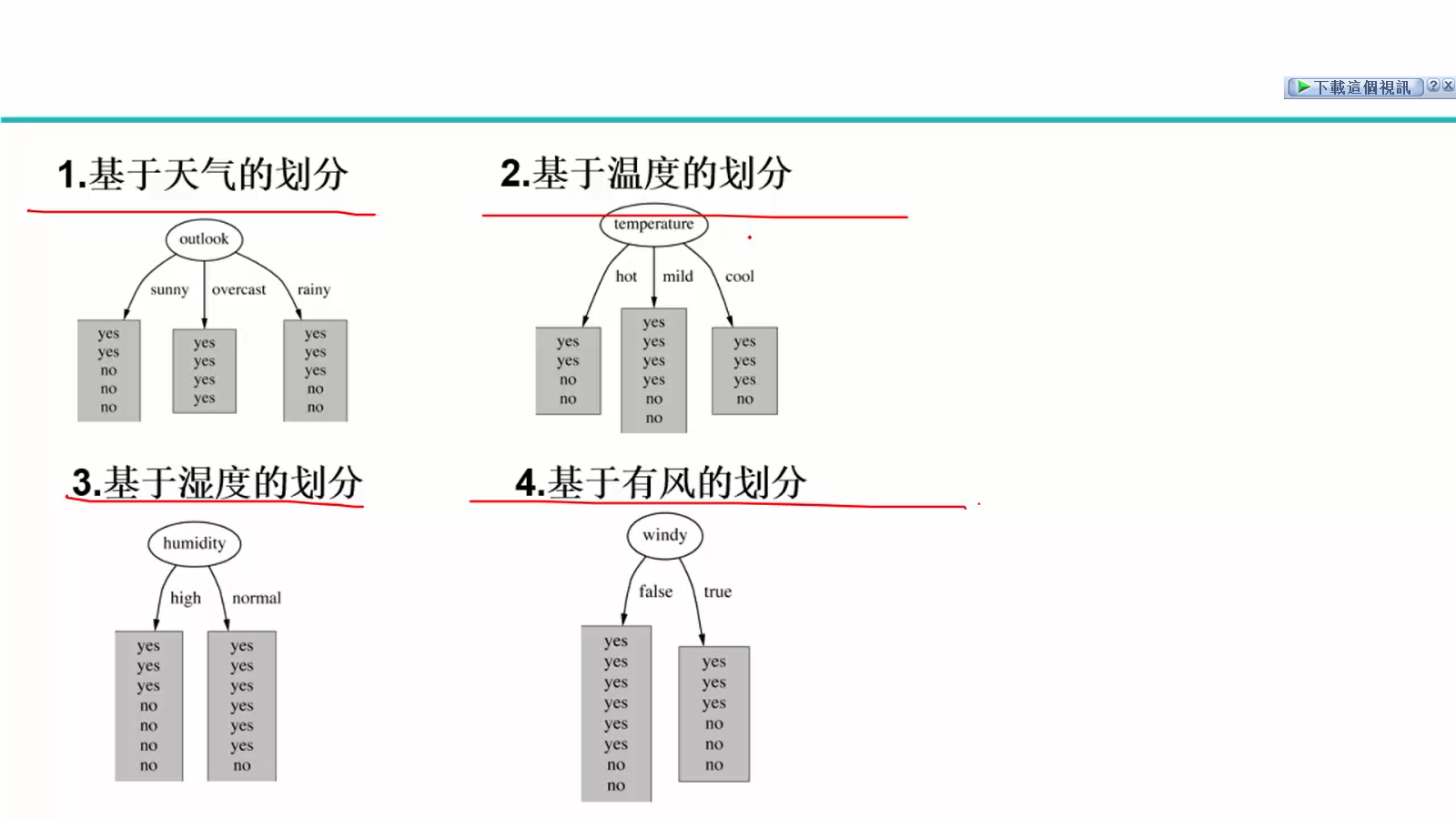



故使用信息增益率

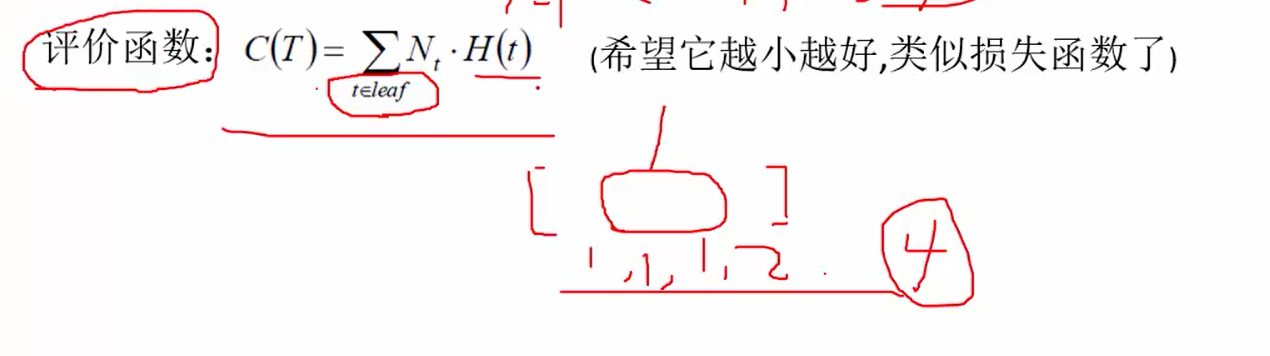
- 信息增益率构建决策树
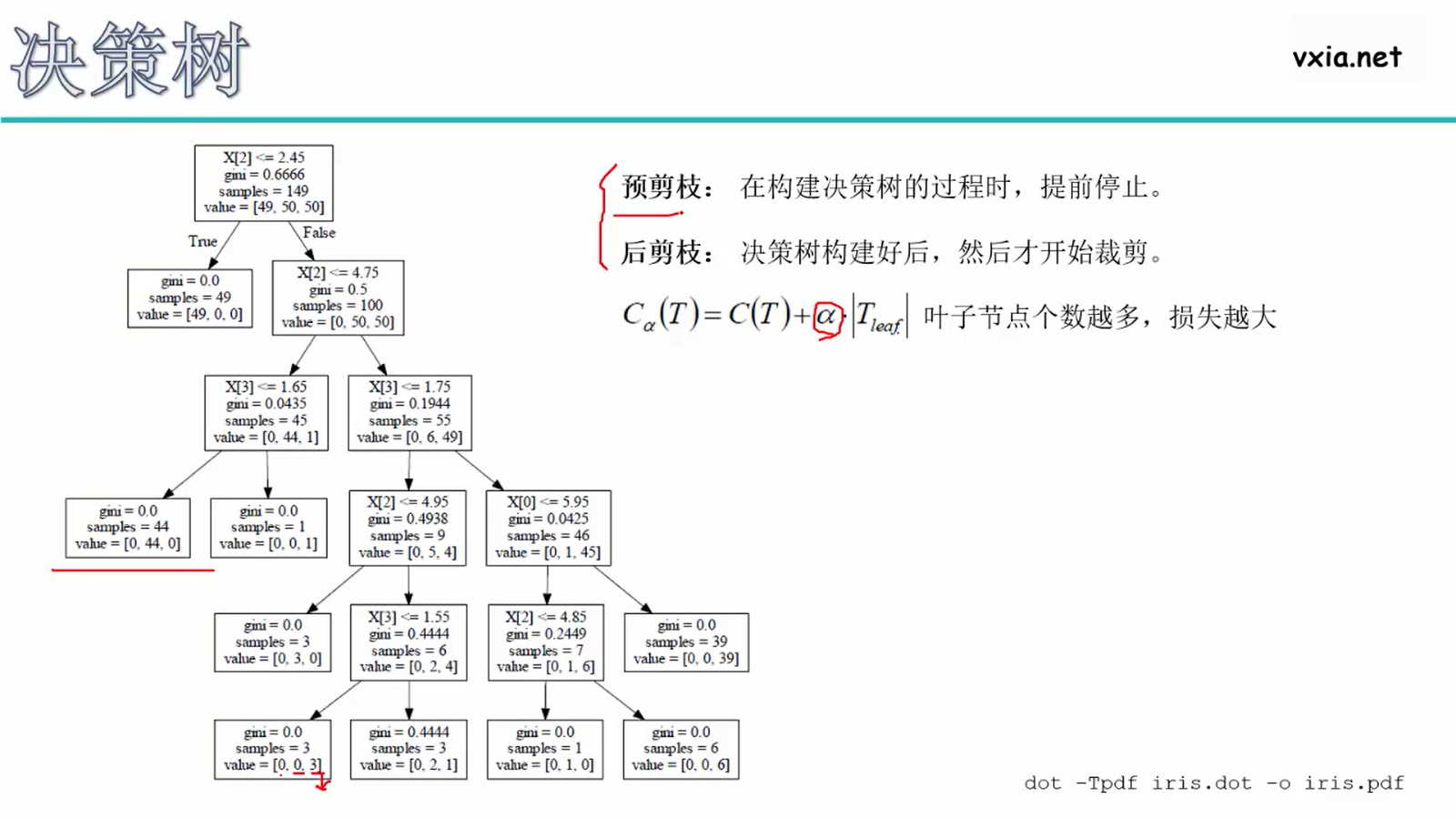
- 评价函数(损失函数)评价决策树

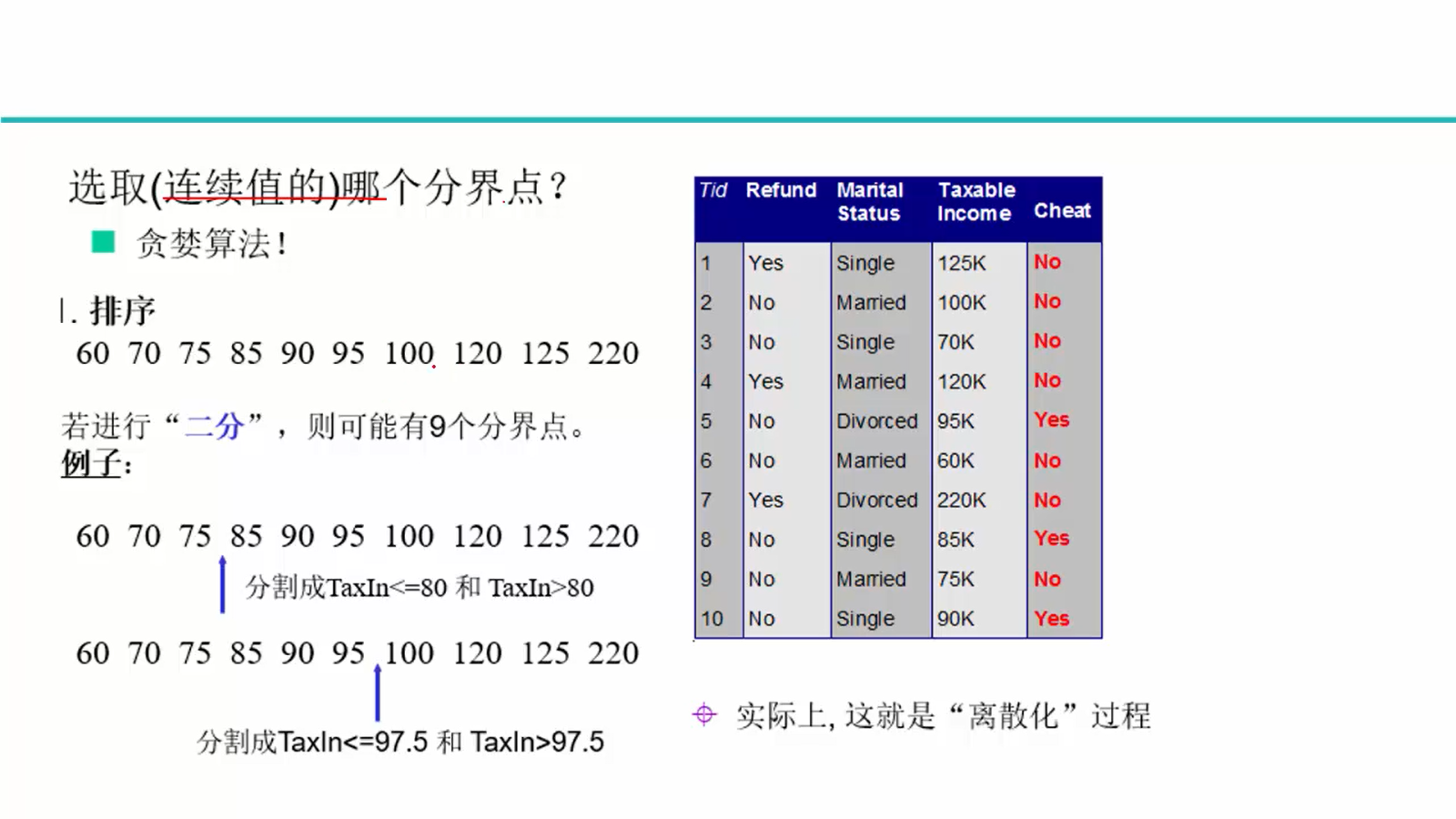
高度高,分支多,效果好,会过拟合,故希望找高度最矮的树;剪枝:
随机森林
随机:
- ①样本:对样本随机采样部分(有放回的采样)来建立决策树---使得某些不好的数(异常值)选不到
- ②特征::对特征随机采样部分(不放回的采样)来建立决策树---使得某些不好的特征(异常特征)选不到
森林:多颗决策树,共同做决策
- 分类,取众数
- 回归,取平均数
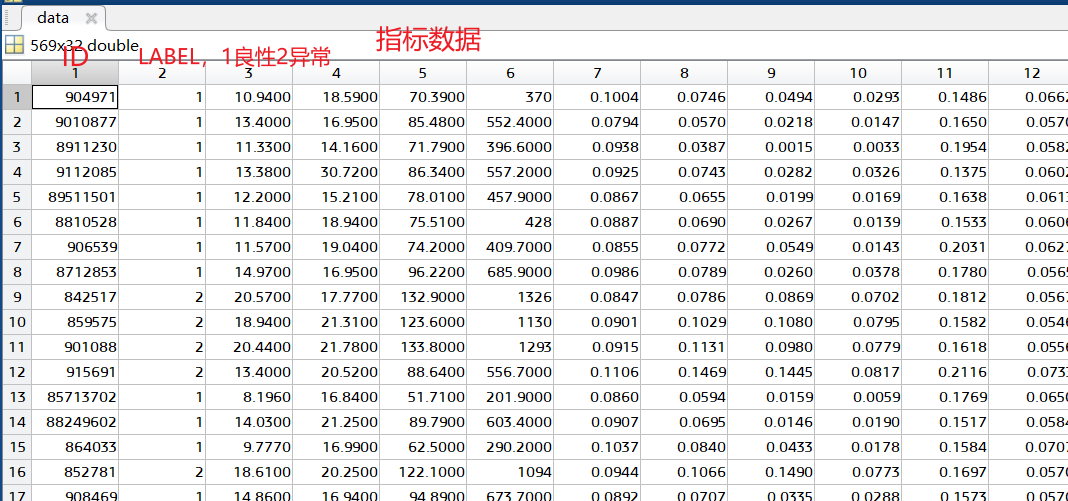
代码实操
代码来源:机器学习及其MATLAB实现-从基础到实践_炼数成金
决策树可直接运行
随机森林需要先将工具包(下图文件夹)扔到matlab/toolbox文件夹里,然后设置路径,便可运行

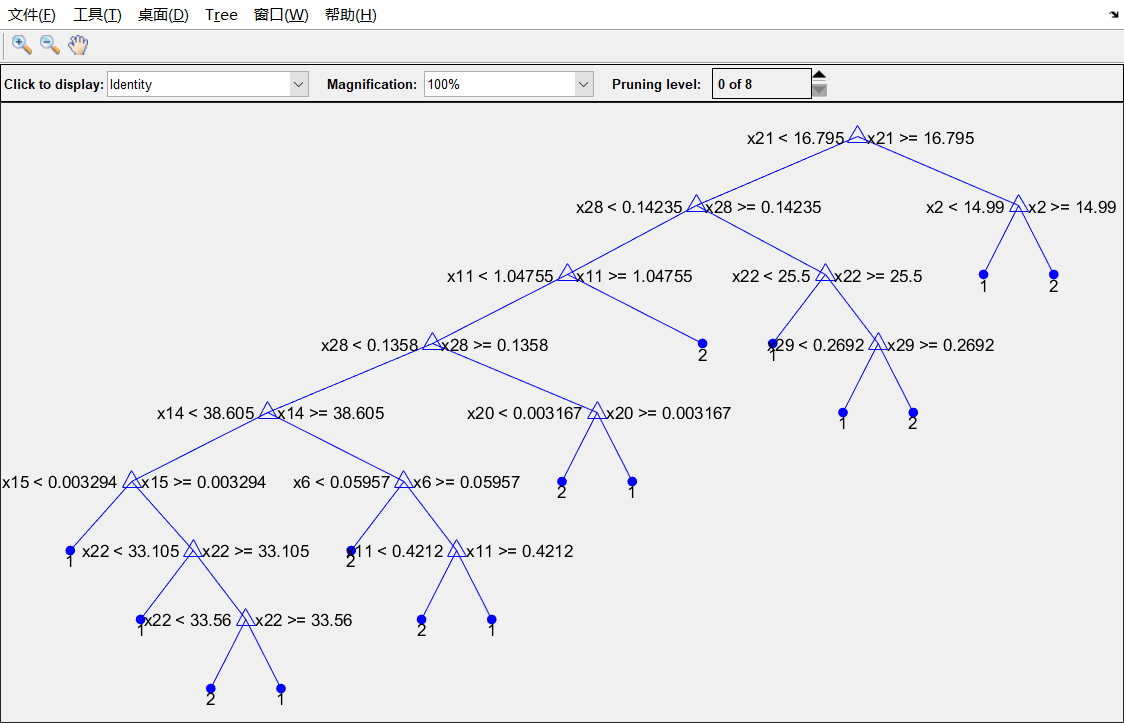
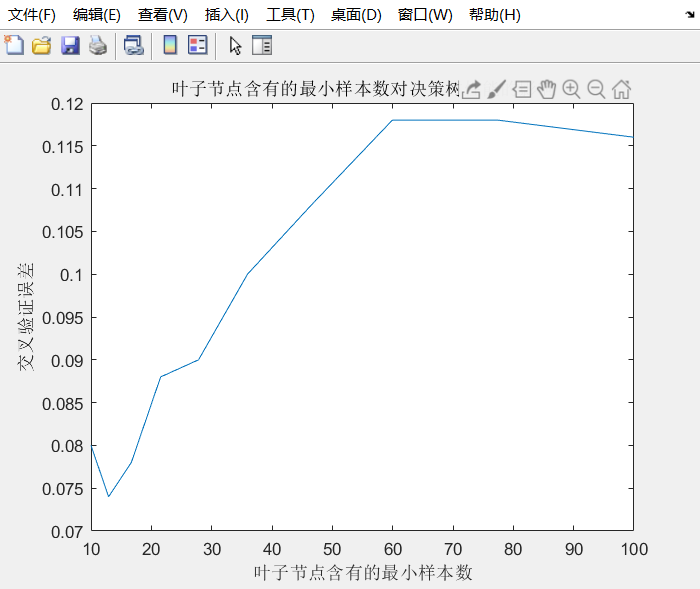
优化决策树①:(设置叶子节点含有的最小样本数)
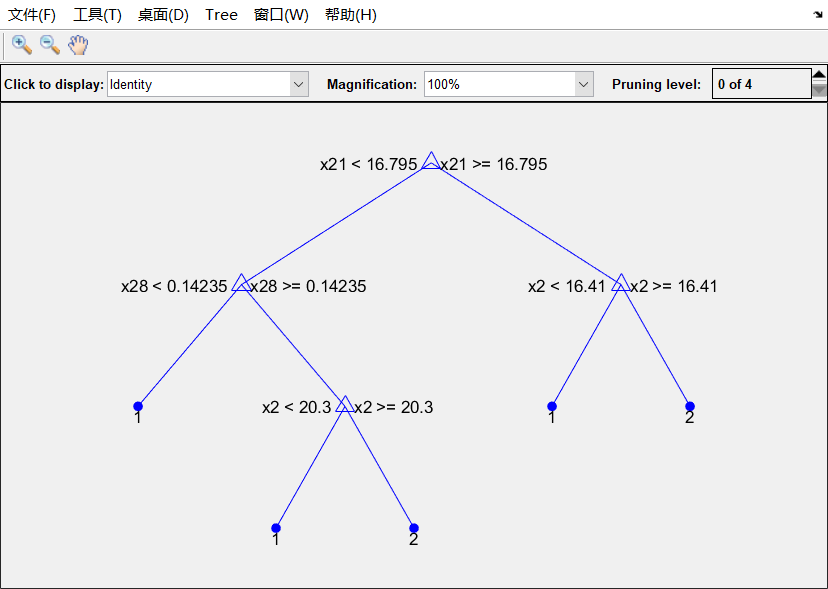
优化决策树②:(剪枝)
