

1 基础知识介绍
1.1 ORM框架介绍
ORM(Object Ralational Mapping,对象关系映射),用来把对象模型表示的对象映射到基于S Q L 的关系模型数据库结构中去。我们在具体的操作实体对象的时候,就不需要再去和复杂的 SQ L 语句打交道,只需简单的操作实体对象的属性和方法。
常见的ORM框架
SQLAlchemy:SQLAlchemy 采用了数据映射模式,其工作单元主要使得有必要限制所有的数据库操作代码到一个特定的数据库session,在该session中控制每个对象的生命周期 。
SQLObject:是一种流行的对象关系管理器,用于为数据库提供对象接口,其中表为类,行为实例,列为属性。SQLObject包含一个基于Python对象的查询语言,使SQL更抽象,并为应用程序提供了大量的数据库独立性。
Storm :是一个介于 单个或多个数据库与Python之间 映射对象的 Python ORM 。为了支持动态存储和取回对象信息,它允许开发者构建跨数据表的复杂查询。Stom中 table class 不需要是框架特定基类 的子类 。每个table class是 的sqlobject.SQLObject 的子类。
Django's ORM :因为Django的ORM 是紧嵌到web框架的,所以就算可以也不推荐,在一个独立的非Django的Python项目中使用它的ORM。Django,一个最流行的Python web框架, 有它独有的 ORM。 相比 SQLAlchemy, Django 的 ORM 更吻合于直接操作SQL对象,操作暴露了简单直接映射数据表和Python类的SQL对象 。
1.2 SQLAlchemy介绍
sqlalchemy是Python ORM的开源框架,使用它可以快速方便的构建数据库模型
SQLAlchemy框架
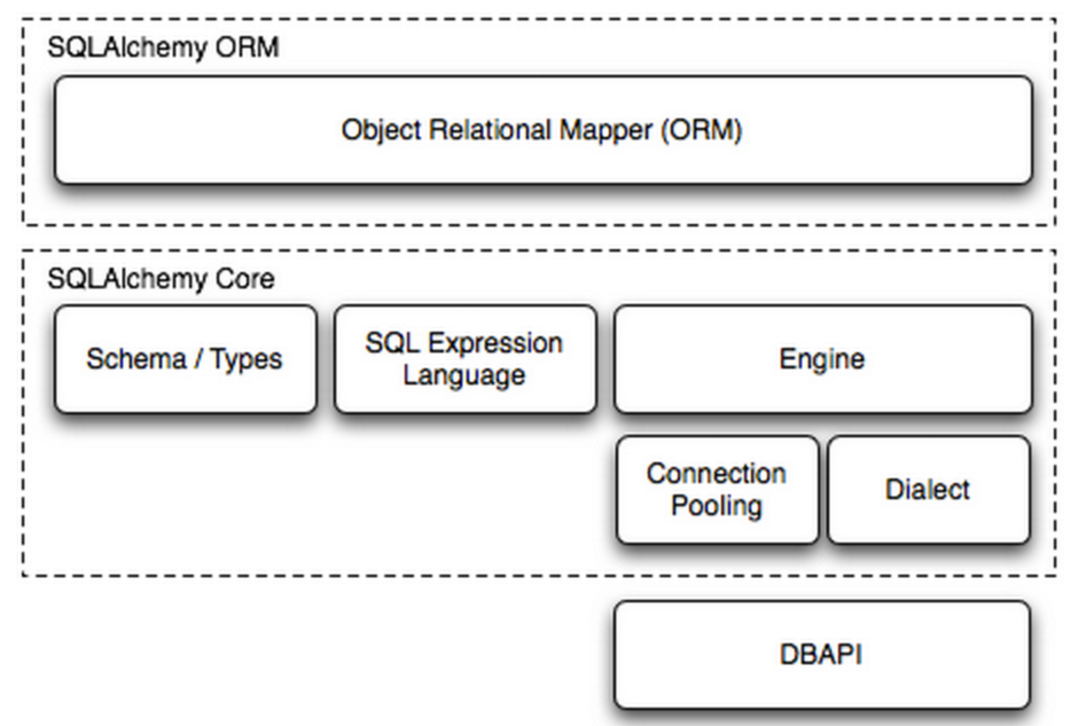
- Engine: 框架的引擎
- Connection Pooling : 数据库连接池
- Dialect : 选择连接数据库的DB API类型
- Schema / Type : 架构和类型
- SQL Expression Language: SQL表达式语言
SQLALchemy本身无法操作数据库,需要依赖pymysql第三方模块,Dialect用于和数据API进行交流,根据配置文件的不同调用不同的数据库API,从而实现对数据库的操作
使用pymysql连接数据库格式:
mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>]2 使用SQLAlchemy
2.1安装SQLAlchemy与检查是否安装成功
#安装
pip install SQLAlchemy
#检查是否安装成功
C:\Users\lsl\Desktop>python
Python 3.7.0rc1 (v3.7.0rc1:dfad352267, Jun 12 2018, 07:05:25) [MSC v.1914 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import sqlalchemy
>>> sqlalchemy.__version__
'1.3.18'2.2使用SQLAlchemy对数据库的表进行操作
2.2.1创建连接对象也就是为了连接到本地的数据库
create_engine中的字段的意义介绍:
engine = create_engine('dialect+driver://username:password@host:port/database')
dialect -- 数据库类型
driver -- 数据库驱动选择(我的数据库驱动选择是pymysql,默认会调用MySQLdb,如果运行的时候提示ImportError: No module named 'MySQLdb'/ImportError: No module named 'pymysql',则意味着没有安装你想使用的数据驱动,安装命令:pip install pymysql)
username -- 数据库用户名
password -- 用户密码
host 服务器地址
port 端口
database 数据库
创建连接:
from sqlalchemy import create_engine
# 连接本地test数据库
engine = create_engine('mysql+pymysql://root:root@localhost:3306/testdab',#数据库类型是mysql,采用pymysql数据库驱动来连接,用户名是root,密码也是root,连接本地数据库testdab(连接的数据库要是已存在的,就是你本地已有的数据库)
encoding='utf-8', # 编码格式
echo=True, # 是否开启sql执行语句的日志输出
pool_recycle=-1, # 多久之后对线程池中的线程进行一次连接的回收(重置) (默认为-1),其实session并不会被close
poolclass=NullPool # 无限制连接数
)2.2.2 简单查询——使用SQL语句
result = engine.execute("select * from students")//在execute()里的参数是查询的sql语句
print(result.fetchall()) //打印出查询的结果2.2.3 创建映射
创建映射后我们就可以减少sql语句对数据库的操作,而是通过操作我们建立的与数据库中的数据表的class来对数据库中的数据进行操作。
创建一个py文件来做数据表的映射text2.py
#引入要使用的declarative_base
from sqlalchemy.ext.declarative import declarative_base
#在要映射的数据表students中有id,name两个字段,所以要引入Integer对应id,String对应name
from sqlalchemy import Column, Integer, String
#声名Base
Base = declarative_base()
#User类就是对应于 __tablename__ 指向的表,也就是数据表students的映射
class User(Base):
#students表是我本地数据库testdab中已存在的
__tablename__ = 'students'
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(64),nullable=False)
__table_args__ = {
"mysql_charset": "utf8"
}在要进行操作之前还要创建一下会话,Session的主要目的是建立与数据库的会话,它维护你加载和关联的所有数据库对象。它是数据库查询(Query)的一个入口。在Sqlalchemy中,数据库的查询操作是通过Query对象来实现的。而Session提供了创建Query对象的接口。
# 创建会话
session = sessionmaker(engine)
mySession = session()接下来,我们就可以通过操作User类来操作数据表students
2.2.4 查询
查询students表中所有的数据
result = mySession.query(News).all()
print(result[0])查询students表中第一条数据
result = mySession.query(User).first()
print(result.name) #打印对象属性通过id查询数据(id=2)
result = mySession.query(User).filter_by(id=2).first()
print(result.name)自定义过滤条件
result = mySession.query(User).filter(text("id>:id")).params(id=2).all()根据主键查询
result = mySession.query(User).get(2)其他查询操作介绍
all()返回查询到的所有的结果。这个方法比较危险的地方是,如果数据量大且没有使用limit子句限制的话,所有的结果都会加载到内存中。它返回的是一个列表,如果查询不到任何结果,返回的是空列表。first()返回查询到的第一个结果,如果没有查询到结果,返回None。.scalar()这个方法与.one_or_none()的效果一样。 如果查询到很多结果,抛出sqlalchemy.orm.exc.MultipleResultsFound异常。如果只有一个结果,返回它,没有结果返回None。one()如果只能查询到一个结果,返回它,否则抛出异常。没有结果时抛sqlalchemy.orm.exc.NoResultFound,有超过一个结果时抛sqlalchemy.orm.exc.MultipleResultsFound。one_or_none()比起one()来,区别只是查询不到任何结果时不再抛出异常而是返回None。get()这是个比较特殊的方法。它用于根据主键来返回查询结果,因此它有个参数就是要查询的对象的主键。如果没有该主键的结果返回None,否则返回这个结果。
2.2.5 增加数据(添加一条数据 name=”小红“),注意要commit
user = User(name="小红")
mySession.add(user)
mySession.commit()
2.2.6删除数据(根据id进行修改)
mySession.query(User).filter(User.id == 1).delete()
mySession.commit()2.2.7修改数据(修改一条数据,把小红的名字修改成小白)
mySession.query(User).filter(User.name=="小红").update({"name":"小白"})
mySession.commit()3 常用条件查询代码
表名:User
1.条件查询
session.query(User).filter(User.name=='张三'){
.all() 查询所有
.one() 查询单个(如果存在多个会异常)
.first() 查询符合条件的第一个
.limit(1).one() limit限制查询,limit(1).one()升级第一个
.count() 查询符合条件的总个数
}
2.主键查询
session.query(User).get(0) 查询主键ID=0
3.offset(n) 限制前面n个,显示后面n+1个
#查询出第三个后面的所有
session.query(User).offset(3).all()
4.slice()切片
#slice(1,3) 与python的slice一致,从0开始 左闭右开,显示1,2两个元素
session.query(User).slice(1,,3).all()
5.order_by() 默认升序
session.query(User).order_by(User.id).all()
6.desc() 降序
session.query(User).order_by(desc(User.id)).all()
7.like 模糊匹配,与sql一样
session.query(User).filter(User.neme.like('%吴')).add()
8.notlike 与7相反
form operator import *
9.in_() 包含
#查询是否包含唐人、吴新喜这个用户的信息
session.query(User).filter(User.name.in_(['唐人','吴新喜'])).all()
10.notin_() 不包含
11.is_ 两种表达方式 None
#查询所有手机号为null的信息
session.query(User).filter(User.phone==None).all()
session.query(User).filter(User.phone.is_(None)).all()
12. isnot()
13. or_ 条件或者关系
#查询name==吴新喜或者唐人的用户信息
session.query(User).filter(or_(User.name=='唐人',User.name=='吴新喜'))
聚合函数
1.count group_by
#查询所有的密码并且计算其相同的个数
from sqlalchemy import func
ssession.query(db_user.psw,func.count(db_user.psw)).group_by(db_user.psw).all()
2.having
having字句可以让我们筛选成组后的各种数据,where字句在聚合前先筛选记录,也就是说作用在group by和having字句前。
而having子句在聚合后对组记录进行筛选。真实表中没有此数据,这些数据是通过一些函数生存。
即先成组在筛选
#查询所有的密码并且计算其相同的个数,having条件相同密码总数大于1的数据
ssession.query(db_user.psw,func.count(db_user.psw)).group_by(db_user.psw).having(func.count(db_user.psw)>1).all()
3.sum
#计算所有id的总和
ssession.query(func.sum(db_user.id)).all()
4.max
#最大的ID
ssession.query(func.max(db_user.id)).all()
5.min
#最小的id
ssession.query(func.min(db_user.id)).all()
6.lable 别名
lable别名不能用在having中
7.extract 提取时间元素
from sqlalchemy import extract4 总的代码
#import
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String
from sqlalchemy.orm import sessionmaker
from sqlalchemy.pool import NullPool
#创建连接对象也就是为了连接到本地的数据库
engine = create_engine('mysql+pymysql://root:root@localhost:3306/testdab',
encoding='utf-8', # 编码格式
echo=True, # 是否开启sql执行语句的日志输出
pool_recycle=-1, # 多久之后对线程池中的线程进行一次连接的回收(重置) (默认为-1),其实session并不会被close
poolclass=NullPool # 无限制连接数
)
#声名Base
Base = declarative_base()
# 创建会话
session = sessionmaker(engine)
mySession = session()
# 创建类,继承基类,用基本类型描述数据库结构
class User(Base):
__tablename__ = 'students'
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(64),nullable=False)
__table_args__ = {
"mysql_charset": "utf8"
}
#sql语句查询
result = engine.execute("select * from students")
print(result.fetchall())
# 查询第一条
result = mySession.query(User).first()
print(result.name) #打印对象属性
# 查询所有
result = mySession.query(User).all()
print(result[0])
# 查询id为2的
result = mySession.query(User).filter_by(id=2).first()
print(result.name)
# 分页查询 0,2
result = mySession.query(User).filter(User.id>1).limit(2).offset(0).all()
print(result)
#插入新数据
user = User(name="小红")
mySession.add(user)
mySession.commit()
result = mySession.query(User).filter_by(name="小红").first()
print(result.name)
#修改已有数据
mySession.query(User).filter(User.name=="小红").update({"name":"小白"})
mySession.commit()
result = mySession.query(User).filter_by(name="小白").first()
print(result.name)
#删除数据
mySession.query(User).filter(User.id == 1).delete()
mySession.commit()
result = mySession.query(User).first()
print(result.name) #打印对象属性