

前言
如上一篇文章所述,Java内存模型规范了Java虚拟机与计算机内存是如何协同工作的。Java虚拟机是一个完整计算机的模型,因此,这个模型自然会包含一个内存模型—又称为Java内存模型。
如果你想设计表现良好的并发程序,理解Java内存模型是非常重要的。Java内存模型规定了如何和何时可以看到由其他线程修改过后的共享变量的值,以及在必须时如何同步的访问共享变量。
1 Java内存模型
我们先来看看Java 线程运行内存示意图,如下图所示:
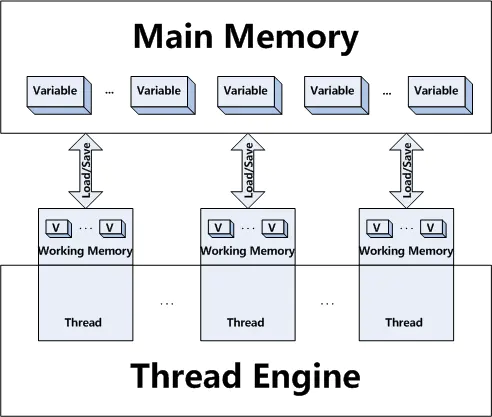
这张图告诉我们在线程运行的时候有一个内存专用的一小块内存,当Java程序会将变量同步到线程所在的内存,这时候会操作工作内存中的变量,而线程中变量的值何时同步回主内存是不可预期的。
因此,依据上面图的线程运行内存示意图,Java内存模型在JVM内部抽象划分为线程栈和堆。如下图所示
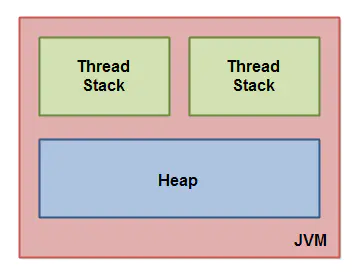
1.1 线程栈与堆
每一个运行在Java虚拟机里的线程都拥有自己的线程栈。这个线程栈包含了 线程调用的方法当前执行点相关的信息,同时线程栈具有如下特性:

即使两个线程执行同样的代码,这两个线程任然在在自己的线程栈中的代码来创建本地变量。因此,每个线程拥有每个本地变量的独有版本。
所有原始类型的本地变量都存放在线程栈上,因此对其它线程不可见。一个线程可能向另一个线程传递一个原始类型变量的拷贝,但是它不能共享这个原始类型变量自身。
堆上包含在Java程序中创建的所有对象,无论是哪一个对象创建的。这包括原始类型的对象版本。如果一个对象被创建然后赋值给一个局部变量,或者用来作为另一个对象的成员变量,这个对象任然是存放在堆上。
所以,调用栈和本地变量存放在线程栈上,对象存放在堆上,如下图所示:
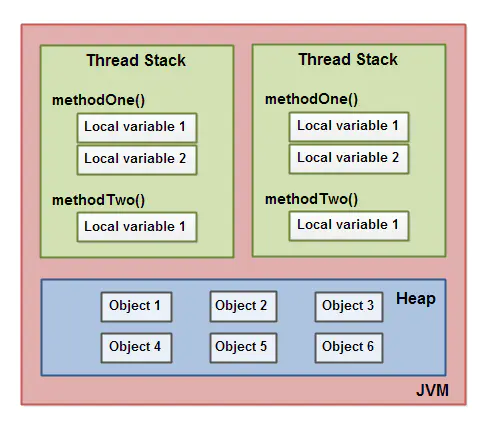

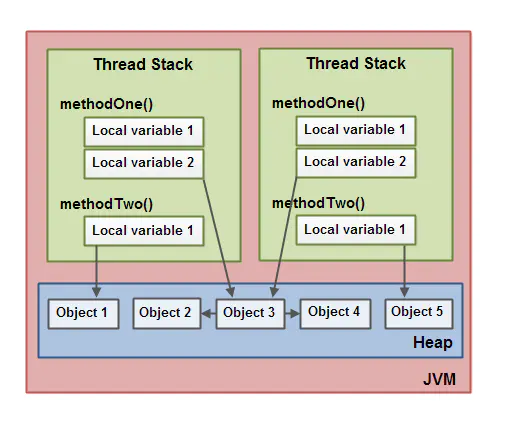
存放在堆上的对象可以被所有持有对这个对象引用的线程访问。当一个线程可以访问一个对象时,它也可以访问这个对象的成员变量。如果两个线程同时调用同一个对象上的同一个方法,它们将会都访问这个对象的成员变量,但是每一个线程都拥有这个本地变量的私有拷贝。
上面说到的几点,如下图所示:
1.2 CPU与内存
众所周知,CPU是计算机的大脑,它负责执行程序的指令。内存负责存数据,包括程序自身数据。同样大家都知道,内存比CPU慢很多,现在获取内存中的一条数据大概需要200多个CPU周期(CPU cycles),而CPU寄存器一般情况下1个CPU周期就够了。下面是CPU Cache的简单示意图:
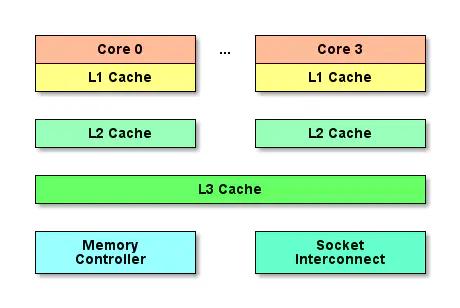
随着多核的发展,CPU Cache分成了三个级别:L1,L2,L3。级别越小越接近CPU,所以速度也更快,同时也代表着容量越小。

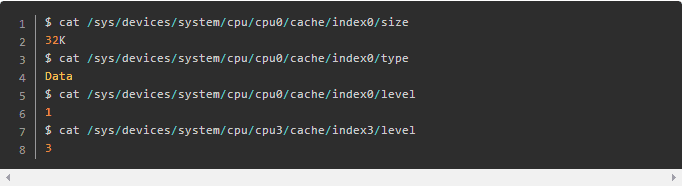
在Linux下面用 cat /proc/cpuinfo,或Ubuntu下 lscpu 看看自己机器的缓存情况,更细的可以通过以下命令看看:
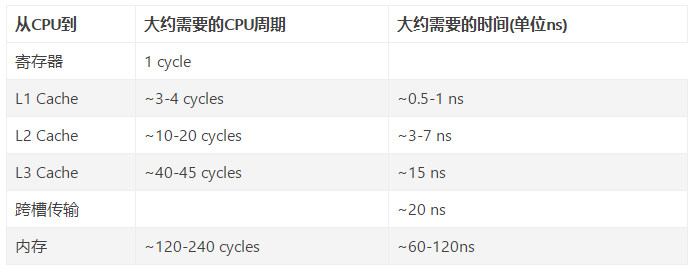
就像数据库cache一样,获取数据时首先会在最快的cache中找数据,如果没有命中(Cache miss) 则往下一级找,直到三层Cache都找不到,那只要向内存要数据了。一次次地未命中,代表获取数据消耗的时间越长。
同时,为了高效地存取缓存,不是简单随意地将单条数据写入缓存的。缓存是由缓存行组成的,典型的一行是64字节。可以通过下面的shell命令,查看cherency_line_size就知道知道机器的缓存行是多大:

CPU存取缓存都是以“行”为最小单位操作的。比如:一个Java long型占8字节,所以从一条缓存行上你可以获取到8个long型变量。所以如果你访问一个long型数组,当有一个long被加载到cache中, 你将无消耗地加载了另外7个。所以你可以非常快地遍历数组。
2 缓存一致性
由于CPU和主存的处理速度上存在一定差别,为了匹配这种差距,提升计算机能力,人们在CPU和主存之间增加了多层高速缓存。每个CPU会有L1、L2甚至L3缓存,在多核计算机中会有多个CPU,那么就会存在多套缓存,在这多套缓存之间的数据就可能出现不一致的现象。为了解决这个问题,有了内存模型。内存模型定义了共享内存系统中多线程程序读写操作行为的规范。通过这些规则来规范对内存的读写操作,从而保证指令执行的正确性。
其实Java内存模型告诉我们通过使用关键词“synchronized”或“volatile”可以让Java保证某些约束:

通过以上描述我们就可以写出线程安全的Java程序,JDK也同时帮我们屏蔽了很多底层的东西。
所以,在编译器各种优化及多种类型的微架构平台上,Java语言规范制定者试图创建一个虚拟的概念并传递到Java程序员,让他们能够在这个虚拟的概念上写出线程安全的程序来,而编译器实现者会根据Java语言规范中的各种约束在不同的平台上达到Java程序员所需要的线程安全这个目的。
那么,在多种类型微架构平台上,又是如何解决缓存不一致性问题的呢?这是众多CPU厂商必须解决的问题。为了解决前面提到的缓存数据不一致的问题,人们提出过很多方案,通常来说有以下2种方案:

2.1 总线的概念
首先,上面的两种方案,其实都涉及到了总线的概念,那到底什么是总线呢?总线是处理器与主存以及处理器与处理器之间进行通信的媒介,有两种基本的互联结构:SMP(symmetric multiprocessing 对称多处理)和NUMA(nonuniform memory access 非一致内存访问)。
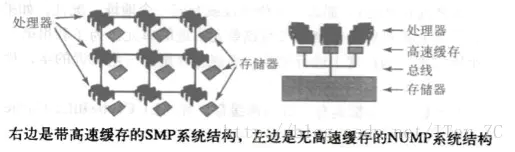
SMP系统结构非常普通,因为它们最容易构建,很多小型服务器采用这种结构。处理器和存储器之间采用总线互联,处理器和存储器都有负责发送和监听总线广播的信息的总线控制单元。但是同一时刻只能有一个处理器(或存储控制器)在总线上广播,所有的处理器都可以监听。很容易看出,对总线的使用是SMP结构的瓶颈。
NUMP系统结构中,一系列节点通过点对点网络互联,像一个小型互联网,每个节点包含一个或多个处理器和一个本地存储器。一个节点的本地存储对于其他节点是可见的,所有节点的本地存储一起形成了一个可以被所有处理器共享的全局存储器。可以看出,NUMP的本地存储是共享的,而不是私有的,这点和SMP是不同的。NUMP的问题是网络比总线复制,需要更加复杂的协议,处理器访问自己节点的存储器速度快于访问其他节点的存储器。NUMP的扩展性很好,所以目前很多大中型的服务器在采用NUMP结构。
对于上层程序员来说,最需要理解的是总线线是一种重要的资源,使用的好坏会直接影响程序的执行性能。
2.2 总线加Lock
在早期的CPU当中,是可以通过在总线上加LOCK#锁的形式来解决缓存不一致的问题。因为CPU和其他部件进行通信都是通过总线来进行的,如果对总线加LOCK#锁的话,也就是说阻塞了其他CPU对其他部件访问(如内存),从而使得只能有一个CPU能使用这个变量的内存。在总线上发出了LCOK#锁的信号,那么只有等待这段代码完全执行完毕之后,其他CPU才能从其内存读取变量,然后进行相应的操作。这样就解决了缓存不一致的问题。
但是由于在锁住总线期间,其他CPU无法访问内存,会导致效率低下。因此出现了第二种解决方案,通过缓存一致性协议来解决缓存一致性问题。
2.3 缓存一致性协议
一致性要求是指,若cache中某个字段被修改,那么在主存(以及更高层次)上,该字段的副本必须立即或最后加以修改,并确保它者引用主存上该字内容的正确性。
当代多处理器系统中,每个处理器大都有自己的cache。同一主存块的拷贝能同时存于不同cache中,若允许处理器各自独立地修改自己的cache,就会出现不一致问题。解决此问题有软件办法和硬件办法。硬件办法能动态地识别出不一致产生的条件并予以及时处理,从而使cache的使用有很高的效率。并且此办法对程序员和系统软件开发人员是透明的,减轻了软件研制负担,从而普遍被采用。
软件办法最出名的就是Intel 的MESI协议,MESI协议保证了每个缓存中使用的共享变量的副本是一致的。MESI协议是一种采用写--无效方式的监听协议。它要求每个cache行有两个状态位,用于描述该行当前是处于修改态(M)、专有态(E)、共享态(S)或者无效态(I)中的哪种状态,从而决定它的读/写操作行为。这四种状态的定义是:

MESI协议适合以总线为互连机构的多处理器系统。各cache控制器除负责响应自己CPU的内存读写操作(包括读/写命中与未命中)外,还要负责监听总线上的其它CPU的内存读写活动(包括读监听命中与写监听命中)并对自己的cache予以相应处理。所有这些处理过程要维护cache一致性,必须符合MESI协议状态转换规则。
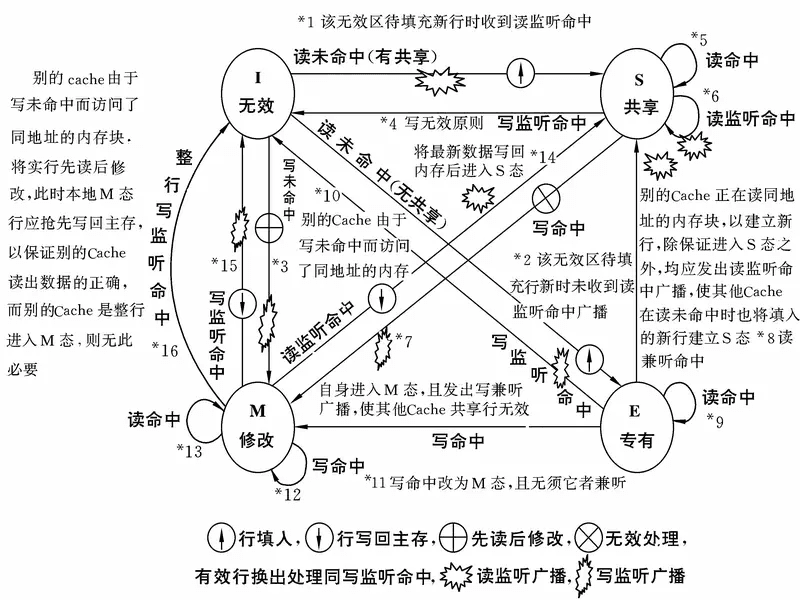
下面由图的四个顶点出发,介绍总线监听与状态转换规则:

上述分析可以看出,虽然各cache控制器随时都在监听系统总线,但能监听到的只有读未命中、写未命中以及共享行写命中三种情况。总线监控逻辑并不复杂,增添的系统总线传输开销也不大,MESI协议却有力地保证了主存块脏拷贝在多cache中的唯一性,并能及时写回,保证cache主存存取的正确性。
但是,值得注意的是,传统的MESI协议中有两个行为的执行成本比较大。一个是将某个Cache Line标记为Invalid状态,另一个是当某Cache Line当前状态为Invalid时写入新的数据。所以CPU通过Store Buffer和Invalidate Queue组件来降低这类操作的延时。如下图所示:
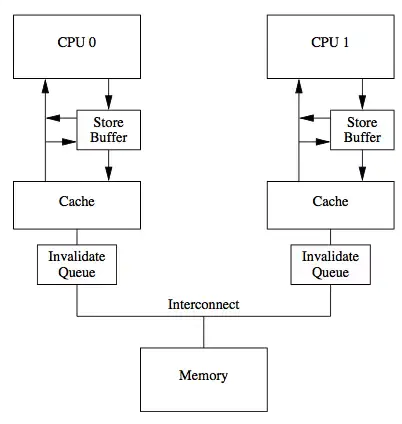

所以,MESI协议,可以保证缓存的一致性,但是无法保证实时性,可能会有极短时间的脏读问题。
其实,并非所有情况都会使用缓存一致性的,如:被操作的数据不能被缓存在CPU内部或操作数据跨越多个缓存行(状态无法标识),则处理器会调用总线锁定;另外当CPU不支持缓存锁定时,自然也只能用总线锁定了,比如说奔腾486以及更老的CPU。
