

前言
谁说程序猿不会压测!基于JMH进行基准测试,给你看看我怎么用代码压测代码(套娃警告⚠) 对性能测试不太了解的朋友可先看看:程序猿也需要知道的性能测试知识总结
什么是基准测试
基准测试是指通过设计科学的测试方法、测试工具和测试系统,实现对一类测试对象的某项性能指标进行定量的和可对比的测试。
为什么要使用基准测试?
基准测试的特质有如下几种:
①、可重复性:可进行重复性的测试,这样做有利于比较每次的测试结果,得到性能结果的长期变化趋势,为系统调优和上线前的容量规划做参考。
②、可观测性:通过全方位的监控(包括测试开始到结束,执行机、服务器、数据库),及时了解和分析测试过程发生了什么。
③、可展示性:相关人员可以直观明了的了解测试结果(web界面、仪表盘、折线图树状图等形式)。
④、真实性:测试的结果反映了客户体验到的真实的情况(真实准确的业务场景+与生产一致的配置+合理正确的测试方法)。
⑤、可执行性:相关人员可以快速的进行测试验证修改调优(可定位可分析)。可见要做一次符合特质的基准测试,是很繁琐也很困难的。外界因素很容易影响到最终的测试结果。特别对于 JAVA的基准测试。
什么时候需要做基准测试
- 想准确的知道某个方法需要执行多长时间,以及执行时间和输入之间的相关性;
- 对比接口/方法不同实现在给定条件下的吞吐量;
- 查看多少百分比的请求在多长时间内完成;
如何测试java代码性能?
测试代码准备
在做性能测试之前,我们先准备测试代码。
在java8横空出世的时候,大家都在鼓励使用lambda表达式,说lambda表达式如何如何地优雅,说lambda表达式如何地提高效率,大家别落后!赶紧用!
当时肯定有一些程序猿表示:

所谓口说无凭, 我们接下来通过对List进行循环查找最大值的代码,验证使用lambda表达式是不是比普通的循环性能要高。
测试代码:
package com.demo.jmh;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.Optional;
/**
* @author lps
* @title: com.demo.jmh.LoopHelper
* @projectName testdemo
* @description: 循环工具类 实现基于java8的多种方式循环List
* 通过 5 种不同的方式遍历List所有的值来查找最大值
* @date 2020/7/1215:43
*/
public class LoopHelper {
/**
* 使用迭代器循环
*
* @param list
* @return
*/
public static int iteratorMaxInteger(List<Integer> list) {
int max = Integer.MIN_VALUE;
for (Iterator it = list.iterator(); it.hasNext(); ) {
max = Integer.max(max, (Integer) it.next());
}
return max;
}
/**
* 使用foreach循环
*
* @param list
* @return
*/
public static int forEachLoopMaxInteger(List<Integer> list) {
int max = Integer.MIN_VALUE;
for (Integer n : list) {
max = Integer.max(max, n);
}
return max;
}
/**
* 使用for循环
*
* @return
*/
public static int forMaxInteger(List<Integer> list) {
int max = Integer.MIN_VALUE;
for (int i = 0; i < list.size(); i++) {
max = Integer.max(max, list.get(i));
}
return max;
}
/**
* 使用java8并行流
*
* @return
*/
public static int parallelStreamMaxInteger(List<Integer> list) {
Optional max = list.parallelStream().reduce(Integer::max);
return (int) max.get();
}
/**
* 使用 lambda 表达式及流
*
* @return
*/
public static int lambdaMaxInteger(List<Integer> list) {
return list.stream().reduce(Integer.MIN_VALUE, (a, b) -> Integer.max(a, b));
}
}
寻常手段代码测试性能
一般来说,我们去评估对比代码的性能,我们可通过耗时指标去评估,哪种方式实现的方法耗时短为优。
所以我们一般这样写:
public static void main(String[] args) {
List<Integer>list = new ArrayList<Integer>();
for (int i = 0; i < 100; i++) {
list.add(i);
}
long start=System.currentTimeMillis();
System.out.println(LoopHelper.iteratorMaxInteger(list));
long end=System.currentTimeMillis();
System.out.println("当前程序1耗时:"+(end-start)+"ms");
}
这样一看没什么不妥,但是中间的误差假如在数据量大的情况下,测试结果是不标准的。
基于JMH的不寻常基准测试
JMH是什么?
JMH,即Java Microbenchmark Harness,是专门用于代码微基准测试的工具套件。何谓Micro Benchmark呢?简单的来说就是基于方法层面的基准测试,精度可以达到微秒级。当你定位到热点方法,希望进一步优化方法性能的时候,就可以使用JMH对优化的结果进行量化的分析。和其他竞品相比——如果有的话,JMH最有特色的地方就是,它是由Oracle内部实现JIT的那拨人开发的,对于JIT以及JVM所谓的“profile guided optimization”对基准测试准确性的影响可谓心知肚明(smile)
使用JMH进行测试
工程环境说明
| 依赖/软件 | 版本 |
|---|---|
| java | 1.8 |
| maven-compiler-plugin | 3.8.1 |
| jmh | 1.23 |
依赖加载
在pom.xml中添加以下依赖
<dependencies>
<!-- https://mvnrepository.com/artifact/org.openjdk.jmh/jmh-core -->
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-core</artifactId>
<version>1.23</version>
</dependency>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId>
<version>1.23</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-math3</artifactId>
<version>3.6.1</version>
</dependency>
</dependencies>
编写测试类
package com.demo.jmh;
import com.demo.jmh.LoopHelper;
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.TimeUnit;
/**
* @author lps
* @title: LoopHelperTest
* @projectName testdemo
* @description: 测试类
* @date 2020/7/1216:11
*/
@BenchmarkMode(Mode.Throughput) // 吞吐量
@OutputTimeUnit(TimeUnit.MILLISECONDS) // 结果所使用的时间单位
@State(Scope.Thread) // 每个测试线程分配一个实例
@Fork(2) // Fork进行的数目
@Warmup(iterations = 4) // 先预热4轮
@Measurement(iterations = 10) // 进行10轮测试
public class LoopHelperTest {
// 定义2个list大小 分别对不同大小list进行测试
@Param({"1000", "100000", })
private int n;
private List<Integer> list;
/**
* 初始化方法,在全部Benchmark运行之前进行
*/
@Setup(Level.Trial)
public void init() {
list = new ArrayList<Integer>();
for (int i = 0; i < n; i++) {
list.add(i);
}
}
@Benchmark
public void testIteratorMaxInteger() {
LoopHelper.iteratorMaxInteger(list);
}
@Benchmark
public void testForEachLoopMaxInteger() {
LoopHelper.forEachLoopMaxInteger(list);
}
@Benchmark
public void testForMaxInteger() {
LoopHelper.forMaxInteger(list);
}
@Benchmark
public void testParallelStreamMaxInteger() {
LoopHelper.parallelStreamMaxInteger(list);
}
@Benchmark
public void testLambdaMaxInteger() {
LoopHelper.lambdaMaxInteger(list);
}
/**
* 结束方法,在全部Benchmark运行之后进行
*/
@TearDown(Level.Trial)
public void arrayRemove() {
for (int i = 0; i < n; i++) {
list.remove(0);
}
}
public static void main(String[] args) throws RunnerException {
Options options = new OptionsBuilder().include(LoopHelperTest.class.getSimpleName()).build();
new Runner(options).run();
}
}
测试结果
运行完成后,控制台输出测试结果如下:
| Benchmark:基准测试执行的方法 | (n):参数n | Mode 测试模式,这里是吞吐量 | cnt:运行次数 | Score :最终分数 | Units:单位每秒操作次数 |
|---|---|---|---|---|---|
| LoopHelperTest.testForEachLoopMaxInteger | 1000 | thrpt | 10 | 1572.310 ± | ops/ms |
| LoopHelperTest.testForEachLoopMaxInteger | 100000 | thrpt | 10 | 15.391 ± | ops/ms |
| LoopHelperTest.testForMaxInteger | 1000 | thrpt | 10 | 1555.872 ± | ops/ms |
| LoopHelperTest.testForMaxInteger | 100000 | thrpt | 10 | 15.926 ± | ops/ms |
| LoopHelperTest.testIteratorMaxInteger | 1000 | thrpt | 10 | 1592.788 ± | ops/ms |
| LoopHelperTest.testIteratorMaxInteger | 100000 | thrpt | 10 | 15.151 ± | ops/ms |
| LoopHelperTest.testLambdaMaxInteger | 1000 | thrpt | 10 | 295.189 ± | ops/ms |
| LoopHelperTest.testLambdaMaxInteger | 100000 | thrpt | 10 | 2.057 ± | ops/ms |
| LoopHelperTest.testParallelStreamMaxInteger | 1000 | thrpt | 10 | 55.194 ± | ops/ms |
| LoopHelperTest.testParallelStreamMaxInteger | 100000 | thrpt | 10 | 3.818 ± | ops/ms |
为了方便对比,把数据使用折现图方式呈现
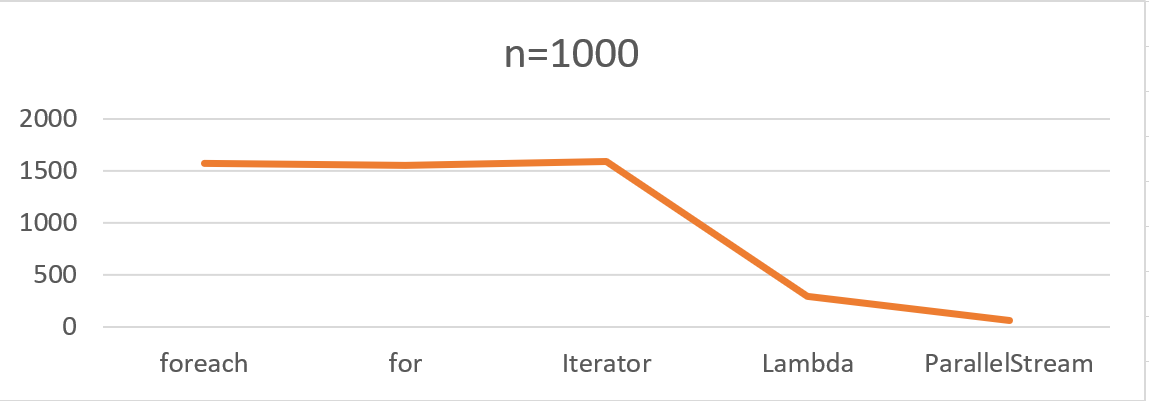
1.这是当List大小为1000的时候的结果: Iterator > for > foreach > Lambda > ParallelStream
其中Iterator、for、 foreach 的表现相差不大,ParallelStream性能表现比较差
2.这是当List大小为100000的时候的结果: for > foreach > Iterator >ParallelStream >Lambda
其中Iterator、for、 foreach 的表现相差不大,Lambda性能表现比较差
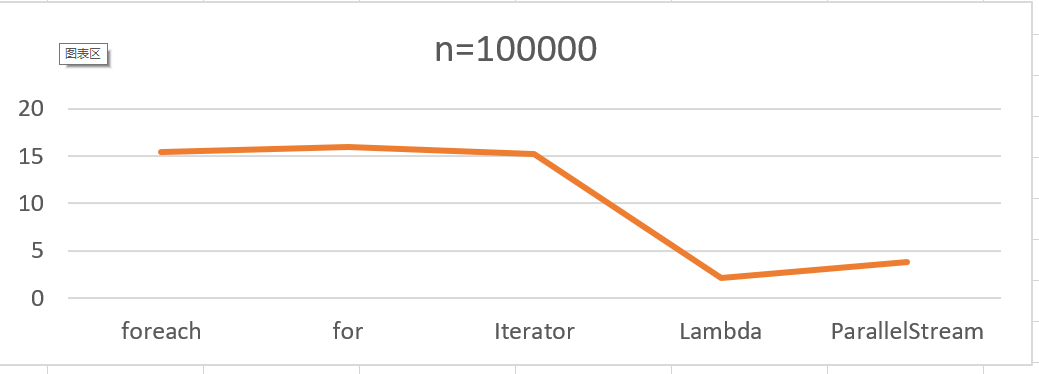
根据基准测试的结果我们可以得出以下结论:
在数据量较小或者数据量较大的时候,Lamdba以及ParallelStream循环List的性能比Iterator、for、 foreach 要差,而且不是差一点,起码3-4倍的吞吐量差异,因此假如是循环操作List,建议使用Iterator、for、 foreach。
jmh相关注解解释
@BenchmarkMode
基准测试的模式,有四种值
- Throughput(“thrpt”, “Throughput, ops/time”), 吞吐量,每一个时间单元执行的次数
- AverageTime(“avgt”, “Average time, time/op”), 每个操作的的平均时间
- SampleTime(“sample”, “Sampling time”), 随机取样,会给出满足百分之多少的情况的最坏的时间
- SingleShotTime(“ss”, “Single shot invocation time”), SingleShotTime 只运行一次。往往同时把 warmup 次数设为0,用于测试冷启动时的性能。
- All(“all”, “All benchmark modes”),以上所有都测试,最常用
@Warmup
预热,由于JIT的存在,因此预热后的数据更平稳。
为什么需要预热?因为 JVM 的 JIT 机制的存在,如果某个函数被调用多次之后,JVM 会尝试将其编译成为机器码从而提高执行速度。为了让 Benchmark 的结果更加接近真实情况就需要进行预热。
@Measurement
测试的一些基本的参数
- iterations:测试的次数
- time:每一次测试的时间
- TimeUnit:时间单位
- 每一个op调用方法的个数
@Threads
测试的线程数,可以注解在类上,也可以在方法上
@Fork
会fork出新的几个java虚拟机减少影响,需要设置一系列的参数,如果 fork 数是2的话,则 JMH 会 fork 出两个进程来进行测试。
@outputTimeUnit
基准测试的时间类型
@Benchmark
方法级的注解,每一个要测试的方法。
@Param
属性级注解,可以用来指定某项参数的多种情况,特别适合用来测试一个函数在不同的参数输入的情况下的性能。@Param 注解接收一个String数组,在 @Setup 方法执行前转化为为对应的数据类型。多个 @Param 注解的成员之间是乘积关系,譬如有两个用 @Param 注解的字段,第一个有5个值,第二个字段有2个值,那么每个测试方法会跑5*2=10次。
@Setup
方法级注解,在测试之前做一些准备工作,例如初始化参数
@TearDown
方法级注解,在测试之后进行一些结束工作
| 名称 | 描述 |
|---|---|
| Level.Trial | 默认level。全部benchmark运行(一组迭代)之前/之后 |
| Level.Iteration | 一次迭代之前/之后(一组调用) |
| Level.Invocation | 每个方法调用之前/之后(不推荐使用,除非你清楚这样做的目的) |
@State
设置一个类在测试的时候在线程间的共享状态:
- Thread: 线程私有
- Group: 同一个组里面所有线程共享
- benchmark: 所有线程共享
总结
通过上面的案例,我们基于JMH基准测试框架能得到比较准确而完整的性能测试结果,根据结果去评估程序接口/方法的性能,帮助我们解决性能瓶颈问题,优化系统性能,降低宕机几率,四舍五入就是提高工作效率,减少加班几率,再四舍五入就是升职加薪,走向职业巅峰。

希望大家在2020年也能承我吉言,一切都好~
