

你有一个思想,我有一个思想,我们交换后,一个人就有两个思想
If you can NOT explain it simply, you do NOT understand it well enough
现陆续将Demo代码和技术文章整理在一起 Github实践精选 ,方便大家阅读查看,本文同样收录在此,觉得不错,还请Star🌟
前言
创建线程有几种方式?这个问题的答案应该是可以脱口而出的吧
- 继承 Thread 类
- 实现 Runnable 接口
但这两种方式创建的线程是属于”三无产品“:
- 没有参数
- 没有返回值
- 没办法抛出异常
class MyThread implements Runnable{
@Override
public void run() {
log.info("my thread");
}
}
Runnable 接口是 JDK1.0 的核心产物
/**
* @since JDK1.0
*/
@FunctionalInterface
public interface Runnable {
public abstract void run();
}
用着 “三无产品” 总是有一些弊端,其中没办法拿到返回值是最让人不能忍的,于是 Callable 就诞生了
Callable
又是 Doug Lea 大师,又是 Java 1.5 这个神奇的版本
/**
* @see Executor
* @since 1.5
* @author Doug Lea
* @param <V> the result type of method {@code call}
*/
@FunctionalInterface
public interface Callable<V> {
V call() throws Exception;
}
Callable 是一个泛型接口,里面只有一个 call() 方法,该方法可以返回泛型值 V ,使用起来就像这样:
Callable<String> callable = () -> {
// Perform some computation
Thread.sleep(2000);
return "Return some result";
};

二者都是函数式接口,里面都仅有一个方法,使用上又是如此相似,除了有无返回值,Runnable 与 Callable 就点差别吗?
Runnable VS Callable
两个接口都是用于多线程执行任务的,但他们还是有很明显的差别的

执行机制
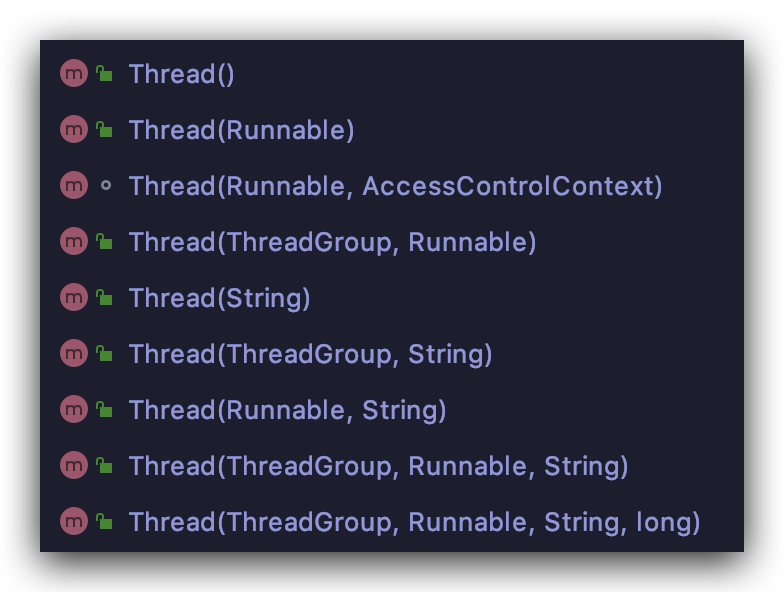
先从执行机制上来看,Runnable 你太清楚了,它既可以用在 Thread 类中,也可以用在 ExecutorService 类中配合线程池的使用;Bu~~~~t, Callable 只能在 ExecutorService 中使用,你翻遍 Thread 类,也找不到Callable 的身影
异常处理
Runnable 接口中的 run 方法签名上没有 throws ,自然也就没办法向上传播受检异常;而 Callable 的 call() 方法签名却有 throws,所以它可以处理受检异常;
所以归纳起来看主要有这几处不同点:
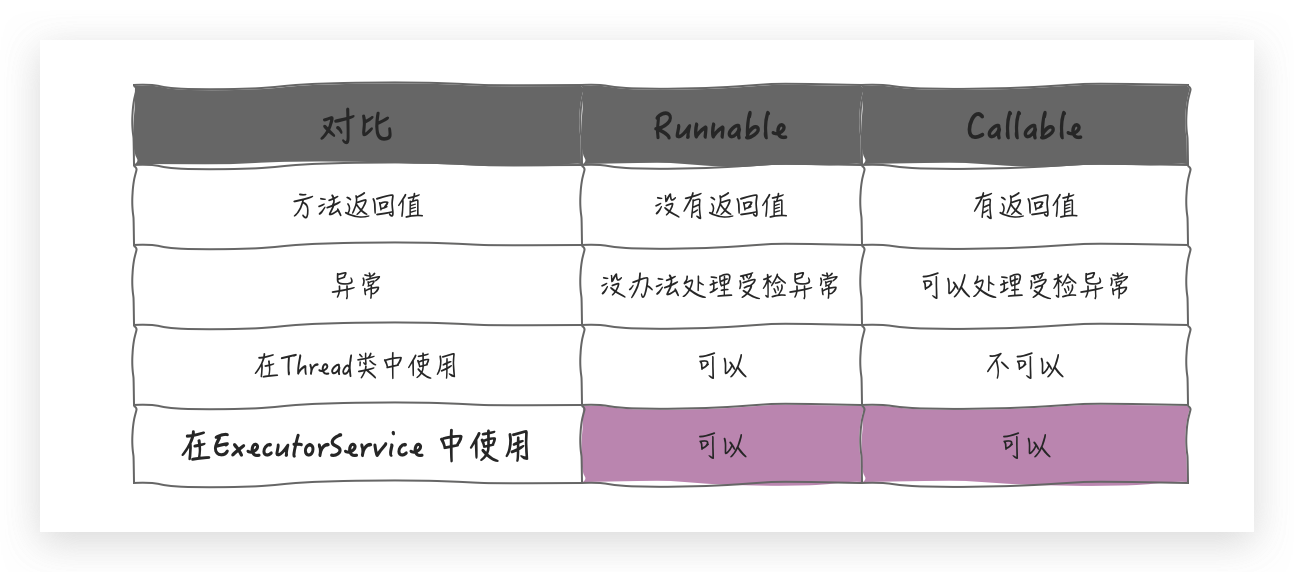
整体差别虽然不大,但是这点差别,却具有重大意义
返回值和处理异常很好理解,另外,在实际工作中,我们通常要使用线程池来管理线程(原因已经在 为什么要使用线程池? 中明确说明),所以我们就来看看 ExecutorService 中是如何使用二者的
ExecutorService
先来看一下 ExecutorService 类图
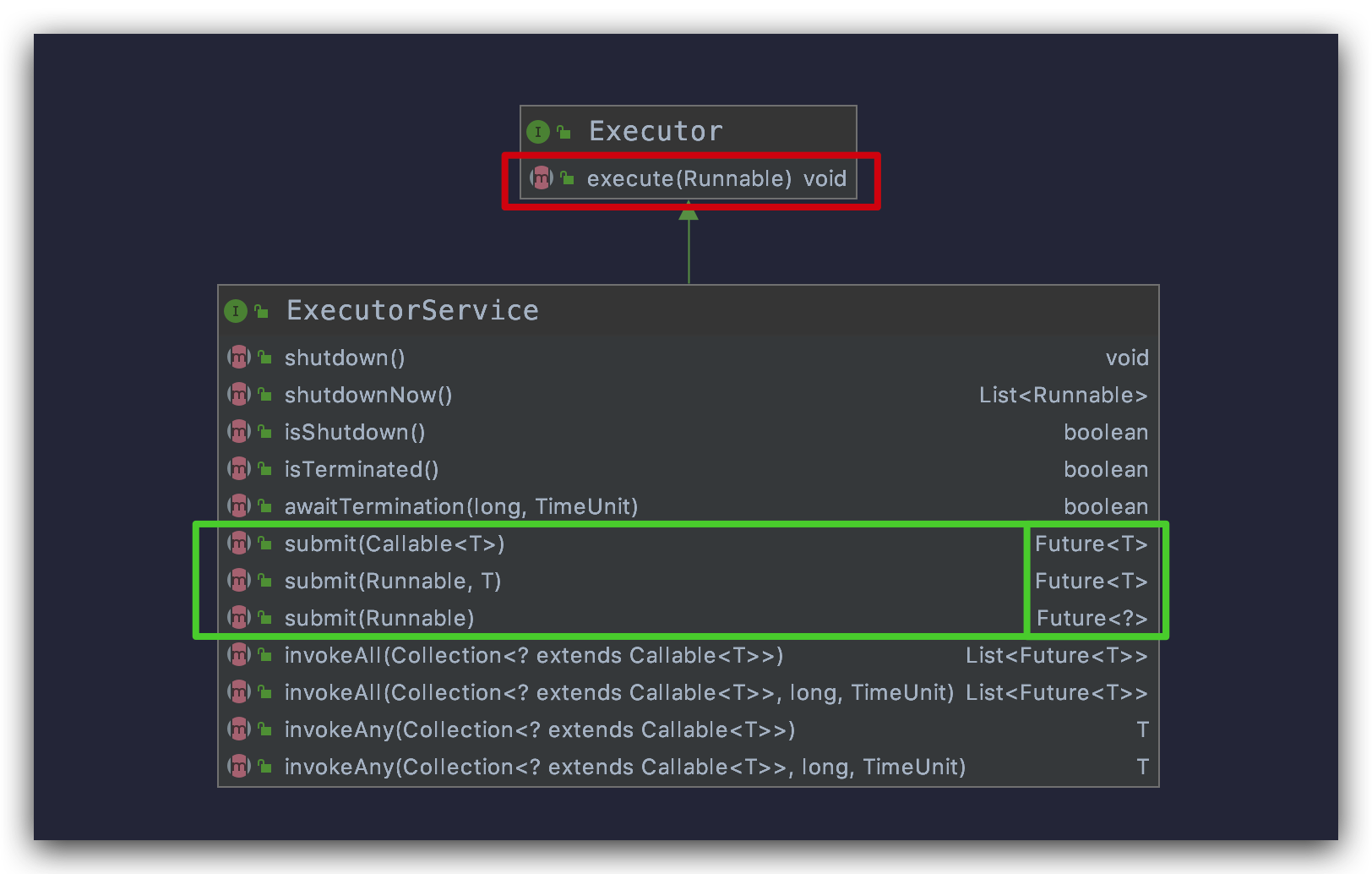
我将上图标记的方法单独放在此处
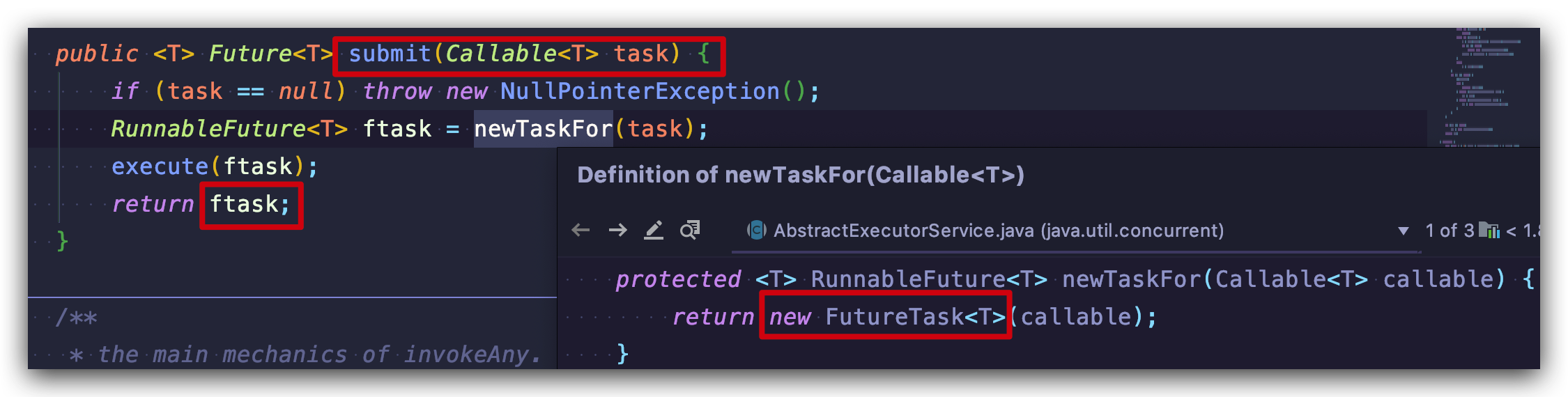
void execute(Runnable command);
<T> Future<T> submit(Callable<T> task);
<T> Future<T> submit(Runnable task, T result);
Future<?> submit(Runnable task);
可以看到,使用ExecutorService 的 execute() 方法依旧得不到返回值,而 submit() 方法清一色的返回 Future 类型的返回值
细心的朋友可能已经发现, submit() 方法已经在 CountDownLatch 和 CyclicBarrier 傻傻的分不清楚? 文章中多次使用了,只不过我们没有获取其返回值罢了,那么
- Future 到底是什么呢?
- 怎么通过它获取返回值呢?
我们带着这些疑问一点点来看
Future
Future 又是一个接口,里面只有五个方法:
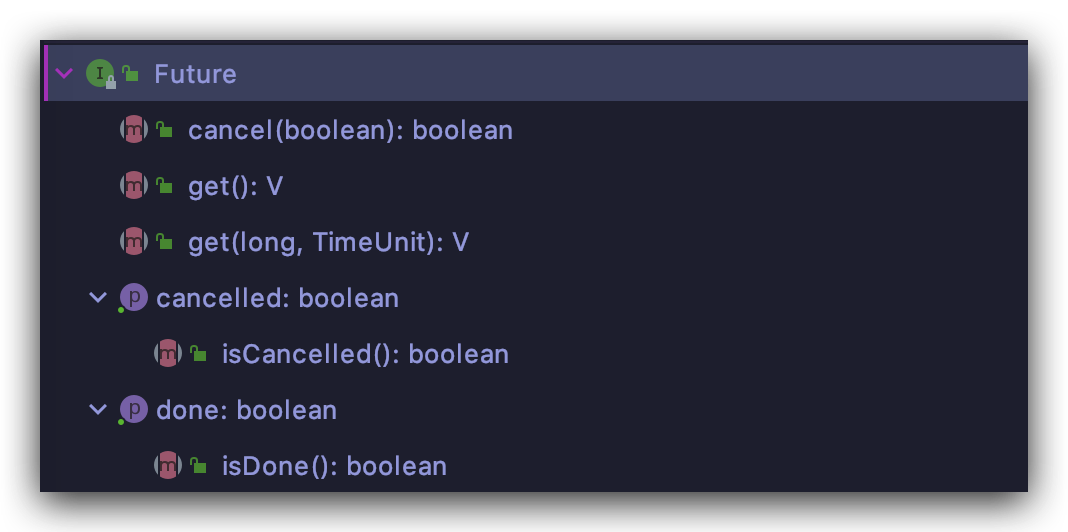
从方法名称上相信你已经能看出这些方法的作用
// 取消任务
boolean cancel(boolean mayInterruptIfRunning);
// 获取任务执行结果
V get() throws InterruptedException, ExecutionException;
// 获取任务执行结果,带有超时时间限制
V get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException;
// 判断任务是否已经取消
boolean isCancelled();
// 判断任务是否已经结束
boolean isDone();
铺垫了这么多,看到这你也许有些乱了,咱们赶紧看一个例子,演示一下几个方法的作用
@Slf4j
public class FutureAndCallableExample {
public static void main(String[] args) throws InterruptedException, ExecutionException {
ExecutorService executorService = Executors.newSingleThreadExecutor();
// 使用 Callable ,可以获取返回值
Callable<String> callable = () -> {
log.info("进入 Callable 的 call 方法");
// 模拟子线程任务,在此睡眠 2s,
// 小细节:由于 call 方法会抛出 Exception,这里不用像使用 Runnable 的run 方法那样 try/catch 了
Thread.sleep(5000);
return "Hello from Callable";
};
log.info("提交 Callable 到线程池");
Future<String> future = executorService.submit(callable);
log.info("主线程继续执行");
log.info("主线程等待获取 Future 结果");
// Future.get() blocks until the result is available
String result = future.get();
log.info("主线程获取到 Future 结果: {}", result);
executorService.shutdown();
}
}
程序运行结果如下:
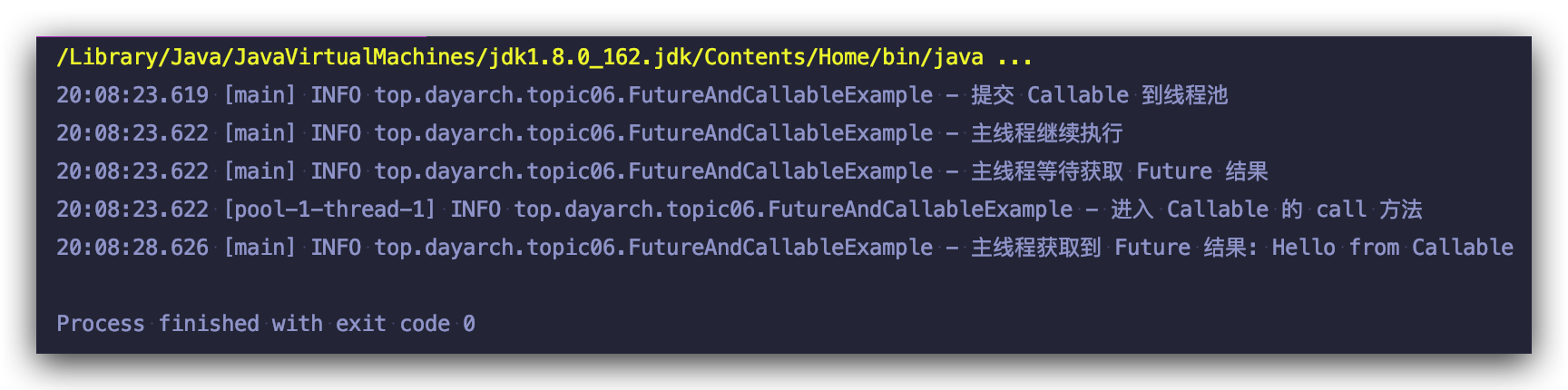
如果你运行上述示例代码,主线程调用 future.get() 方法会阻塞自己,直到子任务完成。我们也可以使用 Future 方法提供的 isDone 方法,它可以用来检查 task 是否已经完成了,我们将上面程序做点小修改:
// 如果子线程没有结束,则睡眠 1s 重新检查
while(!future.isDone()) {
System.out.println("Task is still not done...");
Thread.sleep(1000);
}
来看运行结果:
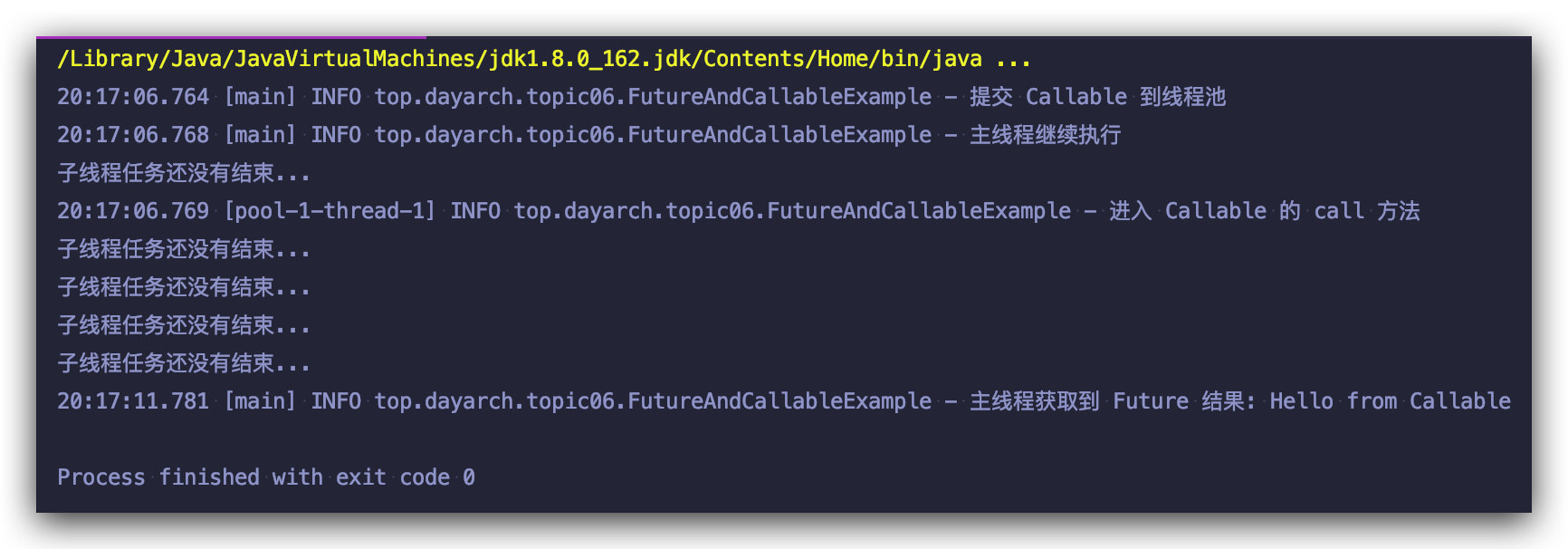
如果子程序运行时间过长,或者其他原因,我们想 cancel 子程序的运行,则我们可以使用 Future 提供的 cancel 方法,继续对程序做一些修改
while(!future.isDone()) {
System.out.println("子线程任务还没有结束...");
Thread.sleep(1000);
double elapsedTimeInSec = (System.nanoTime() - startTime)/1000000000.0;
// 如果程序运行时间大于 1s,则取消子线程的运行
if(elapsedTimeInSec > 1) {
future.cancel(true);
}
}
来看运行结果:
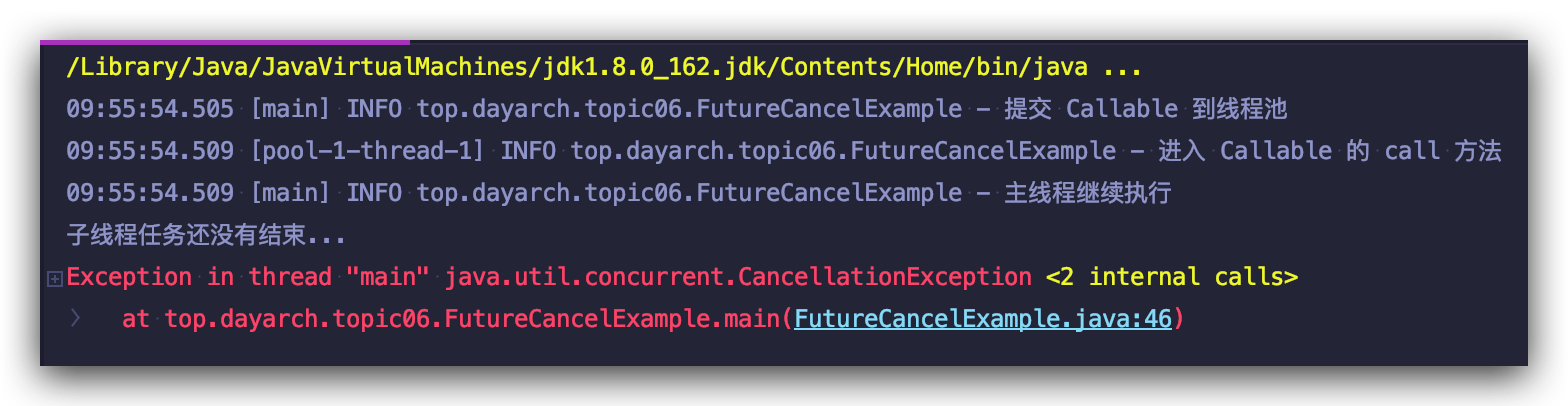
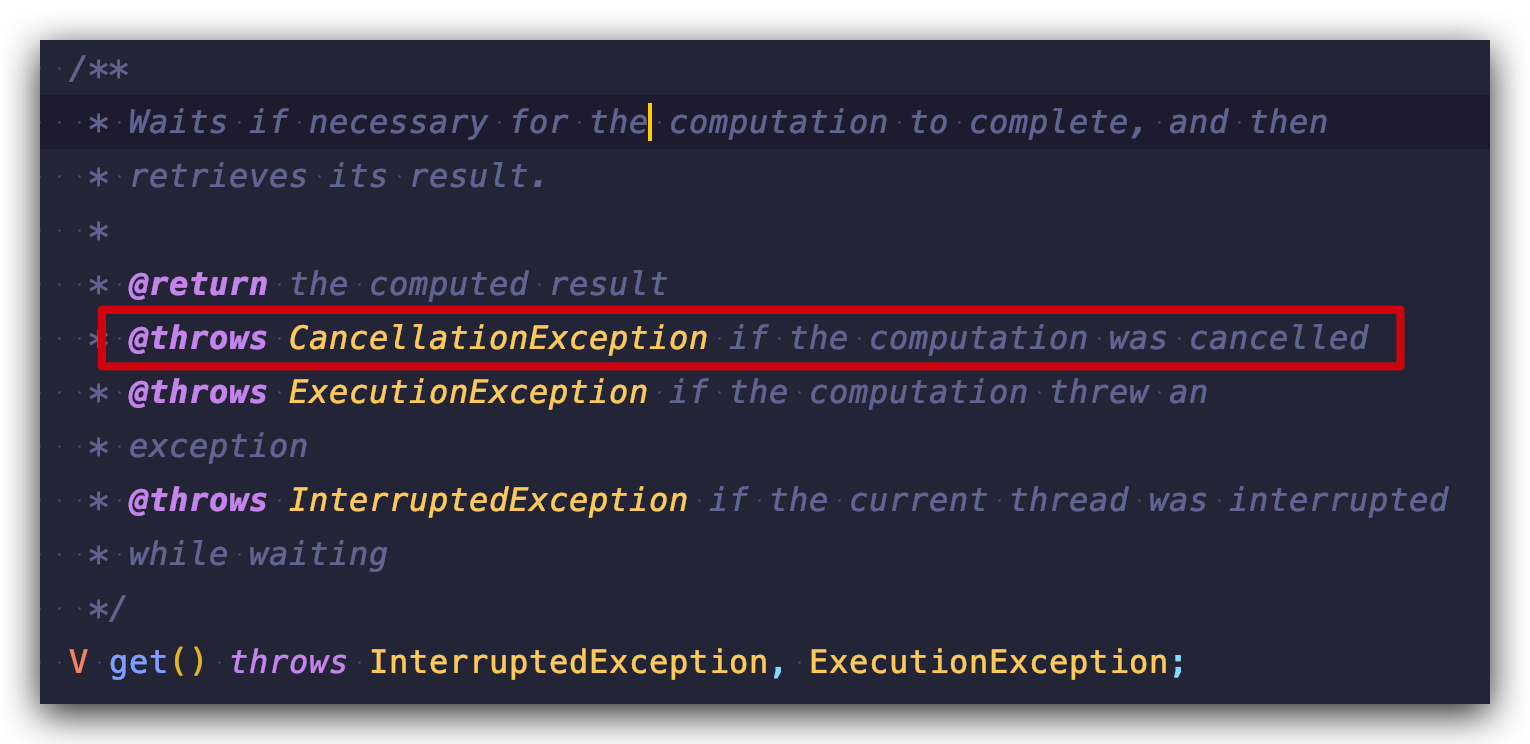
为什么调用 cancel 方法程序会出现 CancellationException 呢? 是因为调用 get() 方法时,明确说明了:
调用 get() 方法时,如果计算结果被取消了,则抛出 CancellationException (具体原因,你会在下面的源码分析中看到)
有异常不处理是非常不专业的,所以我们需要进一步修改程序,以更友好的方式处理异常
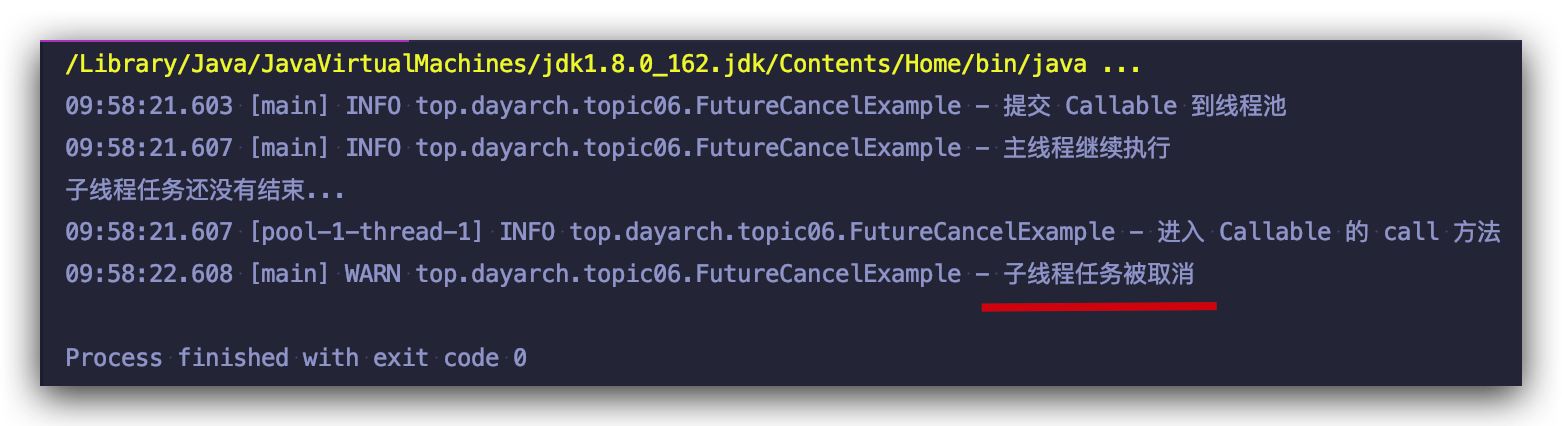
// 通过 isCancelled 方法判断程序是否被取消,如果被取消,则打印日志,如果没被取消,则正常调用 get() 方法
if (!future.isCancelled()){
log.info("子线程任务已完成");
String result = future.get();
log.info("主线程获取到 Future 结果: {}", result);
}else {
log.warn("子线程任务被取消");
}
查看程序运行结果:
相信到这里你已经对 Future 的几个方法有了基本的使用印象,但 Future 是接口,其实使用 ExecutorService.submit() 方法返回的一直都是 Future 的实现类 FutureTask
接下来我们就进入这个核心实现类一探究竟
FutureTask
同样先来看类结构
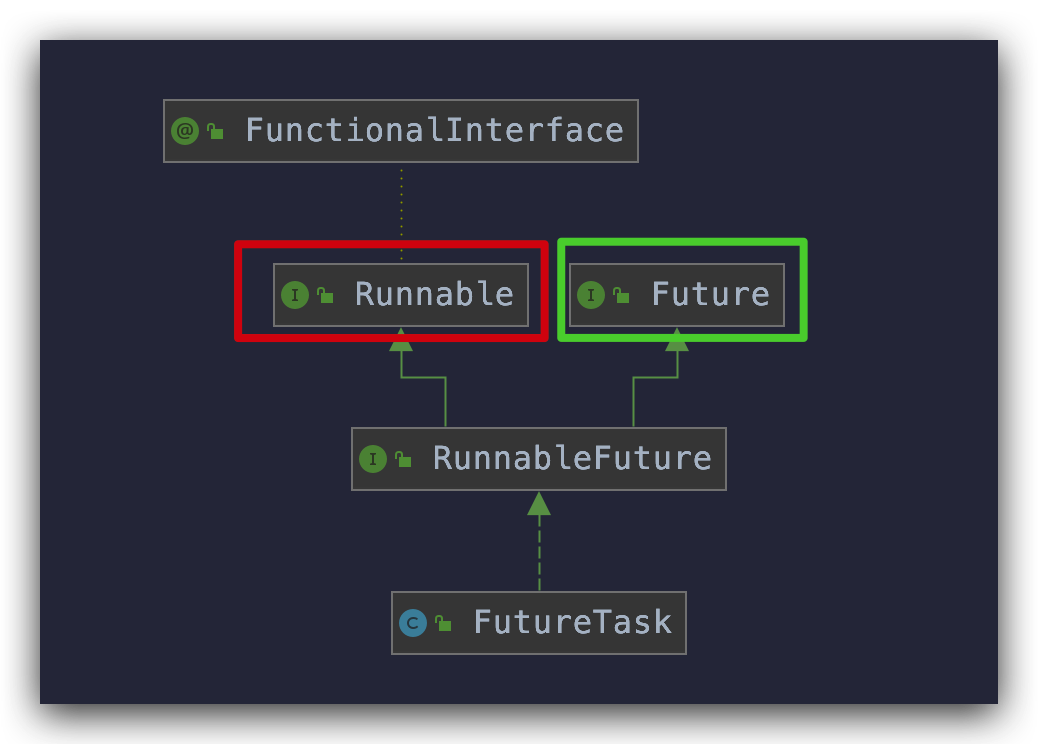
public interface RunnableFuture<V> extends Runnable, Future<V> {
void run();
}
很神奇的一个接口,FutureTask 实现了 RunnableFuture 接口,而 RunnableFuture 接口又分别实现了 Runnable 和 Future 接口,所以可以推断出 FutureTask 具有这两种接口的特性:
- 有
Runnable特性,所以可以用在ExecutorService中配合线程池使用 - 有
Future特性,所以可以从中获取到执行结果
FutureTask源码分析
如果你完整的看过 AQS 相关分析的文章,你也许会发现,阅读 Java 并发工具类源码,我们无非就是要关注以下这三点:
- 状态 (代码逻辑的主要控制)
- 队列 (等待排队队列)
- CAS (安全的set 值)
脑海中牢记这三点,咱们开始看 FutureTask 源码,看一下它是如何围绕这三点实现相应的逻辑的
文章开头已经提到,实现 Runnable 接口形式创建的线程并不能获取到返回值,而实现 Callable 的才可以,所以 FutureTask 想要获取返回值,必定是和 Callable 有联系的,这个推断一点都没错,从构造方法中就可以看出来:
public FutureTask(Callable<V> callable) {
if (callable == null)
throw new NullPointerException();
this.callable = callable;
this.state = NEW; // ensure visibility of callable
}
即便在 FutureTask 构造方法中传入的是 Runnable 形式的线程,该构造方法也会通过 Executors.callable 工厂方法将其转换为 Callable 类型:
public FutureTask(Runnable runnable, V result) {
this.callable = Executors.callable(runnable, result);
this.state = NEW; // ensure visibility of callable
}

但是 FutureTask 实现的是 Runnable 接口,也就是只能重写 run() 方法,run() 方法又没有返回值,那问题来了:
- FutureTask 是怎样在 run() 方法中获取返回值的?
- 它将返回值放到哪里了?
- get() 方法又是怎样拿到这个返回值的呢?
我们来看一下 run() 方法(关键代码都已标记注释)
public void run() {
// 如果状态不是 NEW,说明任务已经执行过或者已经被取消,直接返回
// 如果状态是 NEW,则尝试把执行线程保存在 runnerOffset(runner字段),如果赋值失败,则直接返回
if (state != NEW ||
!UNSAFE.compareAndSwapObject(this, runnerOffset,
null, Thread.currentThread()))
return;
try {
// 获取构造函数传入的 Callable 值
Callable<V> c = callable;
if (c != null && state == NEW) {
V result;
boolean ran;
try {
// 正常调用 Callable 的 call 方法就可以获取到返回值
result = c.call();
ran = true;
} catch (Throwable ex) {
result = null;
ran = false;
// 保存 call 方法抛出的异常
setException(ex);
}
if (ran)
// 保存 call 方法的执行结果
set(result);
}
} finally {
runner = null;
int s = state;
// 如果任务被中断,则执行中断处理
if (s >= INTERRUPTING)
handlePossibleCancellationInterrupt(s);
}
}
run() 方法没有返回值,至于 run() 方法是如何将 call() 方法的返回结果和异常都保存起来的呢?其实非常简单, 就是通过 set(result) 保存正常程序运行结果,或通过 setException(ex) 保存程序异常信息
/** The result to return or exception to throw from get() */
private Object outcome; // non-volatile, protected by state reads/writes
// 保存异常结果
protected void setException(Throwable t) {
if (UNSAFE.compareAndSwapInt(this, stateOffset, NEW, COMPLETING)) {
outcome = t;
UNSAFE.putOrderedInt(this, stateOffset, EXCEPTIONAL); // final state
finishCompletion();
}
}
// 保存正常结果
protected void set(V v) {
if (UNSAFE.compareAndSwapInt(this, stateOffset, NEW, COMPLETING)) {
outcome = v;
UNSAFE.putOrderedInt(this, stateOffset, NORMAL); // final state
finishCompletion();
}
}
setException 和 set 方法非常相似,都是将异常或者结果保存在 Object 类型的 outcome 变量中,outcome 是成员变量,就要考虑线程安全,所以他们要通过 CAS方式设置 outcome 变量的值,既然是在 CAS 成功后 更改 outcome 的值,这也就是 outcome 没有被 volatile 修饰的原因所在。

保存正常结果值(set方法)与保存异常结果值(setException方法)两个方法代码逻辑,唯一的不同就是 CAS 传入的 state 不同。我们上面提到,state 多数用于控制代码逻辑,FutureTask 也是这样,所以要搞清代码逻辑,我们需要先对 state 的状态变化有所了解
/*
*
* Possible state transitions:
* NEW -> COMPLETING -> NORMAL //执行过程顺利完成
* NEW -> COMPLETING -> EXCEPTIONAL //执行过程出现异常
* NEW -> CANCELLED // 执行过程中被取消
* NEW -> INTERRUPTING -> INTERRUPTED //执行过程中,线程被中断
*/
private volatile int state;
private static final int NEW = 0;
private static final int COMPLETING = 1;
private static final int NORMAL = 2;
private static final int EXCEPTIONAL = 3;
private static final int CANCELLED = 4;
private static final int INTERRUPTING = 5;
private static final int INTERRUPTED = 6;
7种状态,千万别慌,整个状态流转其实只有四种线路

FutureTask 对象被创建出来,state 的状态就是 NEW 状态,从上面的构造函数中你应该已经发现了,四个最终状态 NORMAL ,EXCEPTIONAL , CANCELLED , INTERRUPTED 也都很好理解,两个中间状态稍稍有点让人困惑:
- COMPLETING: outcome 正在被set 值的时候
- INTERRUPTING:通过 cancel(true) 方法正在中断线程的时候
总的来说,这两个中间状态都表示一种瞬时状态,我们将几种状态图形化展示一下:
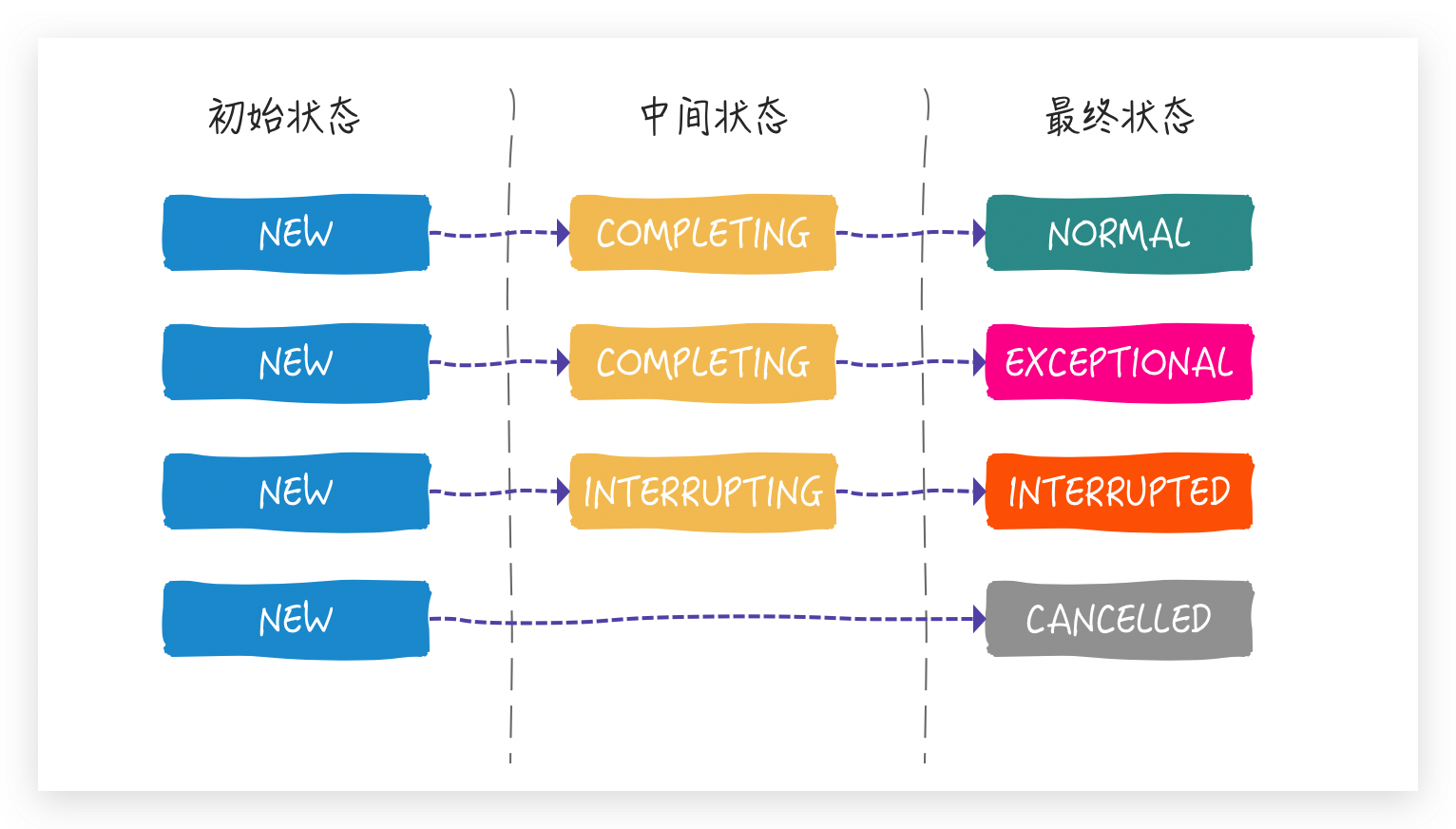
我们知道了 run() 方法是如何保存结果的,以及知道了将正常结果/异常结果保存到了 outcome 变量里,那就需要看一下 FutureTask 是如何通过 get() 方法获取结果的:
public V get() throws InterruptedException, ExecutionException {
int s = state;
// 如果 state 还没到 set outcome 结果的时候,则调用 awaitDone() 方法阻塞自己
if (s <= COMPLETING)
s = awaitDone(false, 0L);
// 返回结果
return report(s);
}
awaitDone 方法是 FutureTask 最核心的一个方法
// get 方法支持超时限制,如果没有传入超时时间,则接受的参数是 false 和 0L
// 有等待就会有队列排队或者可响应中断,从方法签名上看有 InterruptedException,说明该方法这是可以被中断的
private int awaitDone(boolean timed, long nanos)
throws InterruptedException {
// 计算等待截止时间
final long deadline = timed ? System.nanoTime() + nanos : 0L;
WaitNode q = null;
boolean queued = false;
for (;;) {
// 如果当前线程被中断,如果是,则在等待对立中删除该节点,并抛出 InterruptedException
if (Thread.interrupted()) {
removeWaiter(q);
throw new InterruptedException();
}
int s = state;
// 状态大于 COMPLETING 说明已经达到某个最终状态(正常结束/异常结束/取消)
// 把 thread 只为空,并返回结果
if (s > COMPLETING) {
if (q != null)
q.thread = null;
return s;
}
// 如果是COMPLETING 状态(中间状态),表示任务已结束,但 outcome 赋值还没结束,这时主动让出执行权,让其他线程优先执行(只是发出这个信号,至于是否别的线程执行一定会执行可是不一定的)
else if (s == COMPLETING) // cannot time out yet
Thread.yield();
// 等待节点为空
else if (q == null)
// 将当前线程构造节点
q = new WaitNode();
// 如果还没有入队列,则把当前节点加入waiters首节点并替换原来waiters
else if (!queued)
queued = UNSAFE.compareAndSwapObject(this, waitersOffset,
q.next = waiters, q);
// 如果设置超时时间
else if (timed) {
nanos = deadline - System.nanoTime();
// 时间到,则不再等待结果
if (nanos <= 0L) {
removeWaiter(q);
return state;
}
// 阻塞等待特定时间
LockSupport.parkNanos(this, nanos);
}
else
// 挂起当前线程,知道被其他线程唤醒
LockSupport.park(this);
}
}
总的来说,进入这个方法,通常会经历三轮循环
- 第一轮for循环,执行的逻辑是
q == null, 这时候会新建一个节点 q, 第一轮循环结束。 - 第二轮for循环,执行的逻辑是
!queue,这个时候会把第一轮循环中生成的节点的 next 指针指向waiters,然后CAS的把节点q 替换waiters, 也就是把新生成的节点添加到waiters 中的首节点。如果替换成功,queued=true。第二轮循环结束。 - 第三轮for循环,进行阻塞等待。要么阻塞特定时间,要么一直阻塞知道被其他线程唤醒。
对于第二轮循环,大家可能稍稍有点迷糊,我们前面说过,有阻塞,就会排队,有排队自然就有队列,FutureTask 内部同样维护了一个队列
/** Treiber stack of waiting threads */
private volatile WaitNode waiters;
说是等待队列,其实就是一个 Treiber 类型 stack,既然是 stack, 那就像手枪的弹夹一样(脑补一下子弹放入弹夹的情形),后进先出,所以刚刚说的第二轮循环,会把新生成的节点添加到 waiters stack 的首节点
如果程序运行正常,通常调用 get() 方法,会将当前线程挂起,那谁来唤醒呢?自然是 run() 方法运行完会唤醒,设置返回结果(set方法)/异常的方法(setException方法) 两个方法中都会调用 finishCompletion 方法,该方法就会唤醒等待队列中的线程
private void finishCompletion() {
// assert state > COMPLETING;
for (WaitNode q; (q = waiters) != null;) {
if (UNSAFE.compareAndSwapObject(this, waitersOffset, q, null)) {
for (;;) {
Thread t = q.thread;
if (t != null) {
q.thread = null;
// 唤醒等待队列中的线程
LockSupport.unpark(t);
}
WaitNode next = q.next;
if (next == null)
break;
q.next = null; // unlink to help gc
q = next;
}
break;
}
}
done();
callable = null; // to reduce footprint
}
将一个任务的状态设置成终止态只有三种方法:
- set
- setException
- cancel
前两种方法已经分析完,接下来我们就看一下 cancel 方法
查看 Future cancel(),该方法注释上明确说明三种 cancel 操作一定失败的情形
- 任务已经执行完成了
- 任务已经被取消过了
- 任务因为某种原因不能被取消
其它情况下,cancel操作将返回true。值得注意的是,cancel操作返回 true 并不代表任务真的就是被取消, 这取决于发动cancel状态时,任务所处的状态
- 如果发起cancel时任务还没有开始运行,则随后任务就不会被执行;
- 如果发起cancel时任务已经在运行了,则这时就需要看
mayInterruptIfRunning参数了:- 如果mayInterruptIfRunning 为true, 则当前在执行的任务会被中断
- 如果mayInterruptIfRunning 为false, 则可以允许正在执行的任务继续运行,直到它执行完
有了这些铺垫,看一下 cancel 代码的逻辑就秒懂了
public boolean cancel(boolean mayInterruptIfRunning) {
if (!(state == NEW &&
UNSAFE.compareAndSwapInt(this, stateOffset, NEW,
mayInterruptIfRunning ? INTERRUPTING : CANCELLED)))
return false;
try { // in case call to interrupt throws exception
// 需要中断任务执行线程
if (mayInterruptIfRunning) {
try {
Thread t = runner;
// 中断线程
if (t != null)
t.interrupt();
} finally { // final state
// 修改为最终状态 INTERRUPTED
UNSAFE.putOrderedInt(this, stateOffset, INTERRUPTED);
}
}
} finally {
// 唤醒等待中的线程
finishCompletion();
}
return true;
}
核心方法终于分析完了,到这咱们喝口茶休息一下吧

我是想说,使用 FutureTask 来演练烧水泡茶经典程序
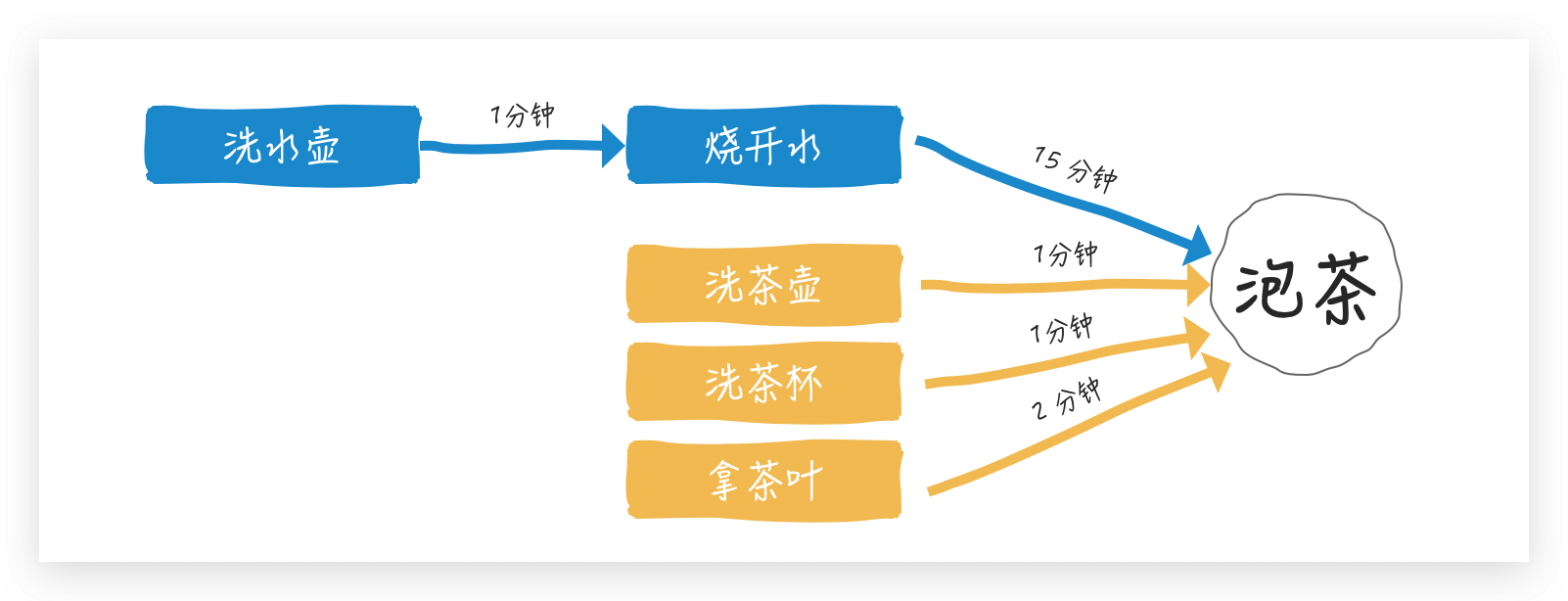
如上图:
- 洗水壶 1 分钟
- 烧开水 15 分钟
- 洗茶壶 1 分钟
- 洗茶杯 1 分钟
- 拿茶叶 2 分钟
最终泡茶
让我心算一下,如果串行总共需要 20 分钟,但很显然在烧开水期间,我们可以洗茶壶/洗茶杯/拿茶叶
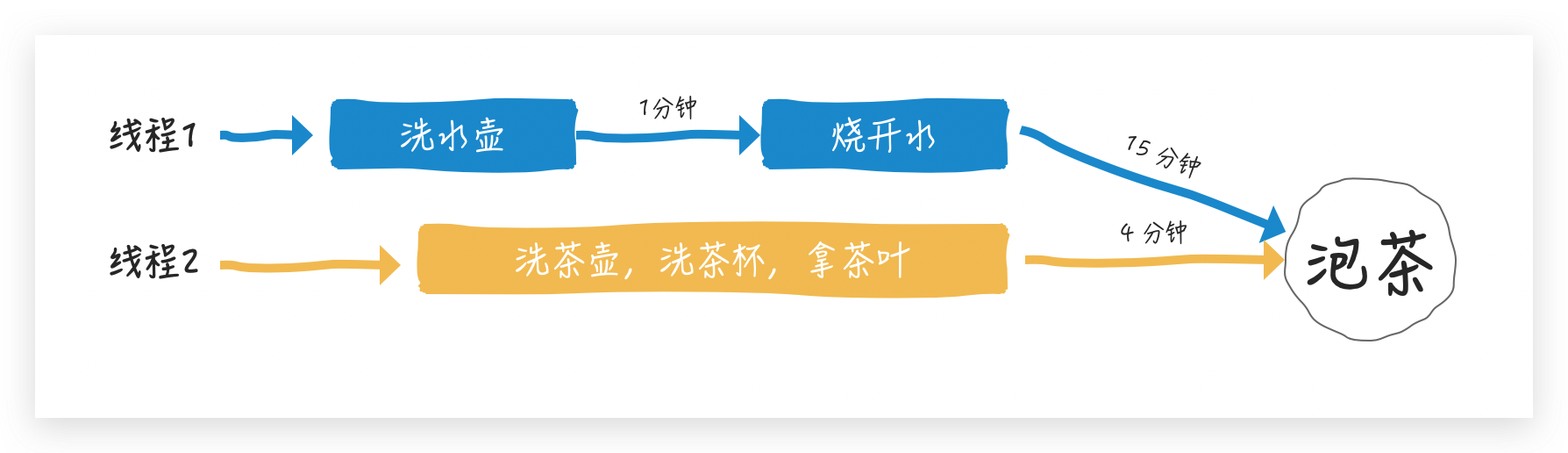
这样总共需要 16 分钟,节约了 4分钟时间,烧水泡茶尚且如此,在现在高并发的时代,4分钟可以做的事太多了,学会使用 Future 优化程序是必然(其实优化程序就是寻找关键路径,关键路径找到了,非关键路径的任务通常就可以和关键路径的内容并行执行了)
@Slf4j
public class MakeTeaExample {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService executorService = Executors.newFixedThreadPool(2);
// 创建线程1的FutureTask
FutureTask<String> ft1 = new FutureTask<String>(new T1Task());
// 创建线程2的FutureTask
FutureTask<String> ft2 = new FutureTask<String>(new T2Task());
executorService.submit(ft1);
executorService.submit(ft2);
log.info(ft1.get() + ft2.get());
log.info("开始泡茶");
executorService.shutdown();
}
static class T1Task implements Callable<String> {
@Override
public String call() throws Exception {
log.info("T1:洗水壶...");
TimeUnit.SECONDS.sleep(1);
log.info("T1:烧开水...");
TimeUnit.SECONDS.sleep(15);
return "T1:开水已备好";
}
}
static class T2Task implements Callable<String> {
@Override
public String call() throws Exception {
log.info("T2:洗茶壶...");
TimeUnit.SECONDS.sleep(1);
log.info("T2:洗茶杯...");
TimeUnit.SECONDS.sleep(2);
log.info("T2:拿茶叶...");
TimeUnit.SECONDS.sleep(1);
return "T2:福鼎白茶拿到了";
}
}
}
上面的程序是主线程等待两个 FutureTask 的执行结果,线程1 烧开水时间更长,线程1希望在水烧开的那一刹那就可以拿到茶叶直接泡茶,怎么半呢?
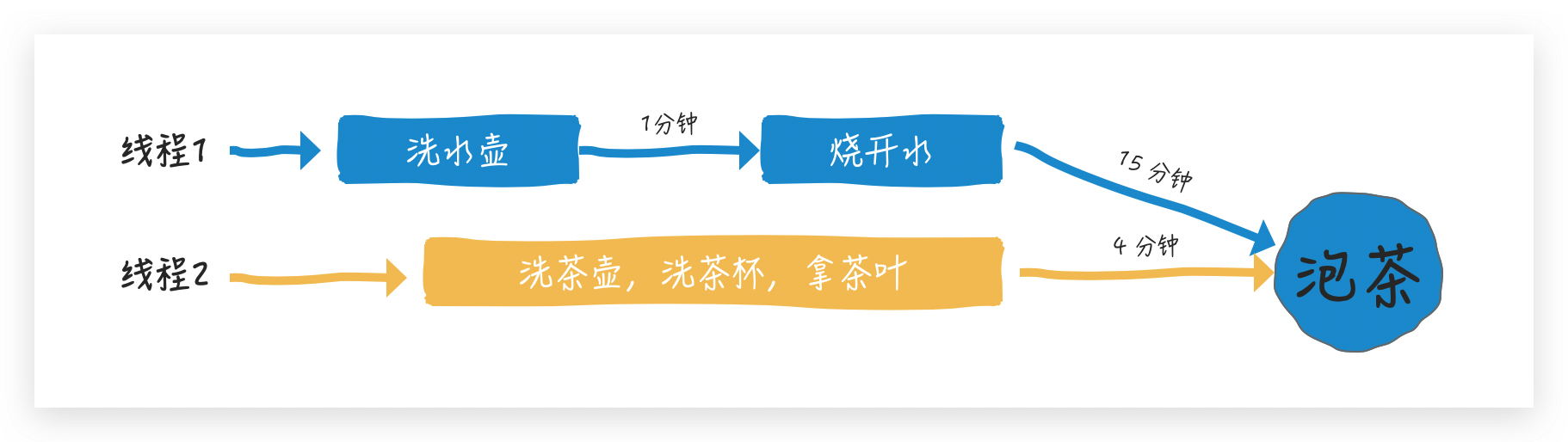
那只需要在线程 1 的FutureTask 中获取 线程 2 FutureTask 的返回结果就可以了,我们稍稍修改一下程序:
@Slf4j
public class MakeTeaExample1 {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService executorService = Executors.newFixedThreadPool(2);
// 创建线程2的FutureTask
FutureTask<String> ft2 = new FutureTask<String>(new T2Task());
// 创建线程1的FutureTask
FutureTask<String> ft1 = new FutureTask<String>(new T1Task(ft2));
executorService.submit(ft1);
executorService.submit(ft2);
executorService.shutdown();
}
static class T1Task implements Callable<String> {
private FutureTask<String> ft2;
public T1Task(FutureTask<String> ft2) {
this.ft2 = ft2;
}
@Override
public String call() throws Exception {
log.info("T1:洗水壶...");
TimeUnit.SECONDS.sleep(1);
log.info("T1:烧开水...");
TimeUnit.SECONDS.sleep(15);
String t2Result = ft2.get();
log.info("T1 拿到T2的 {}, 开始泡茶", t2Result);
return "T1: 上茶!!!";
}
}
static class T2Task implements Callable<String> {
@Override
public String call() throws Exception {
log.info("T2:洗茶壶...");
TimeUnit.SECONDS.sleep(1);
log.info("T2:洗茶杯...");
TimeUnit.SECONDS.sleep(2);
log.info("T2:拿茶叶...");
TimeUnit.SECONDS.sleep(1);
return "福鼎白茶";
}
}
}
来看程序运行结果:
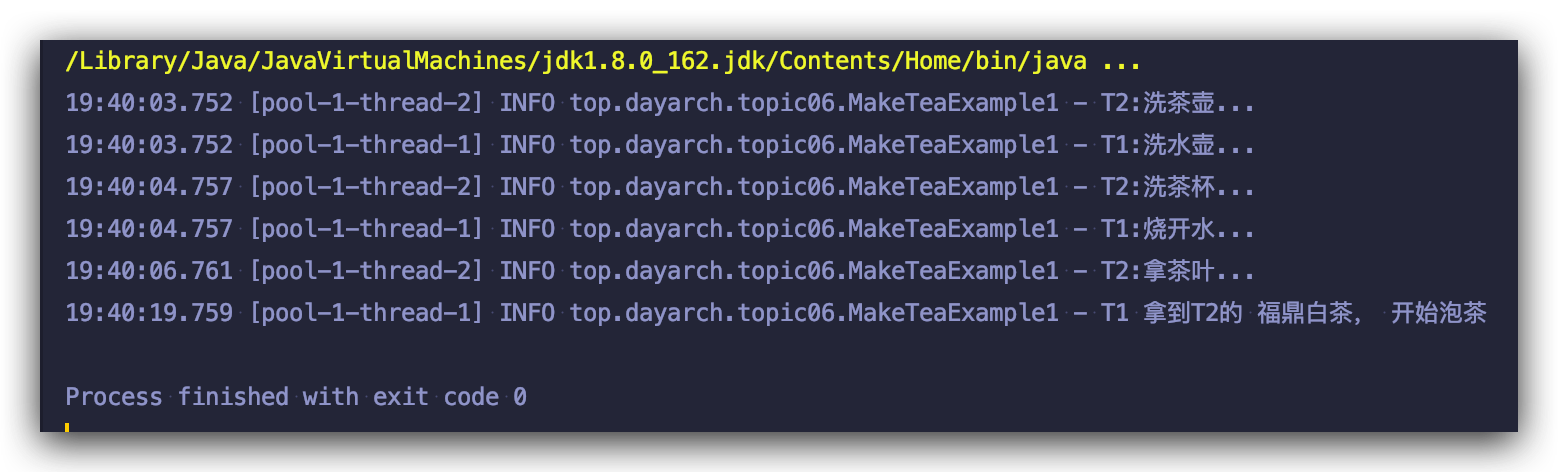
知道这个变化后我们再回头看 ExecutorService 的三个 submit 方法:
<T> Future<T> submit(Runnable task, T result);
Future<?> submit(Runnable task);
<T> Future<T> submit(Callable<T> task);
第一种方法,逐层代码查看到这里:
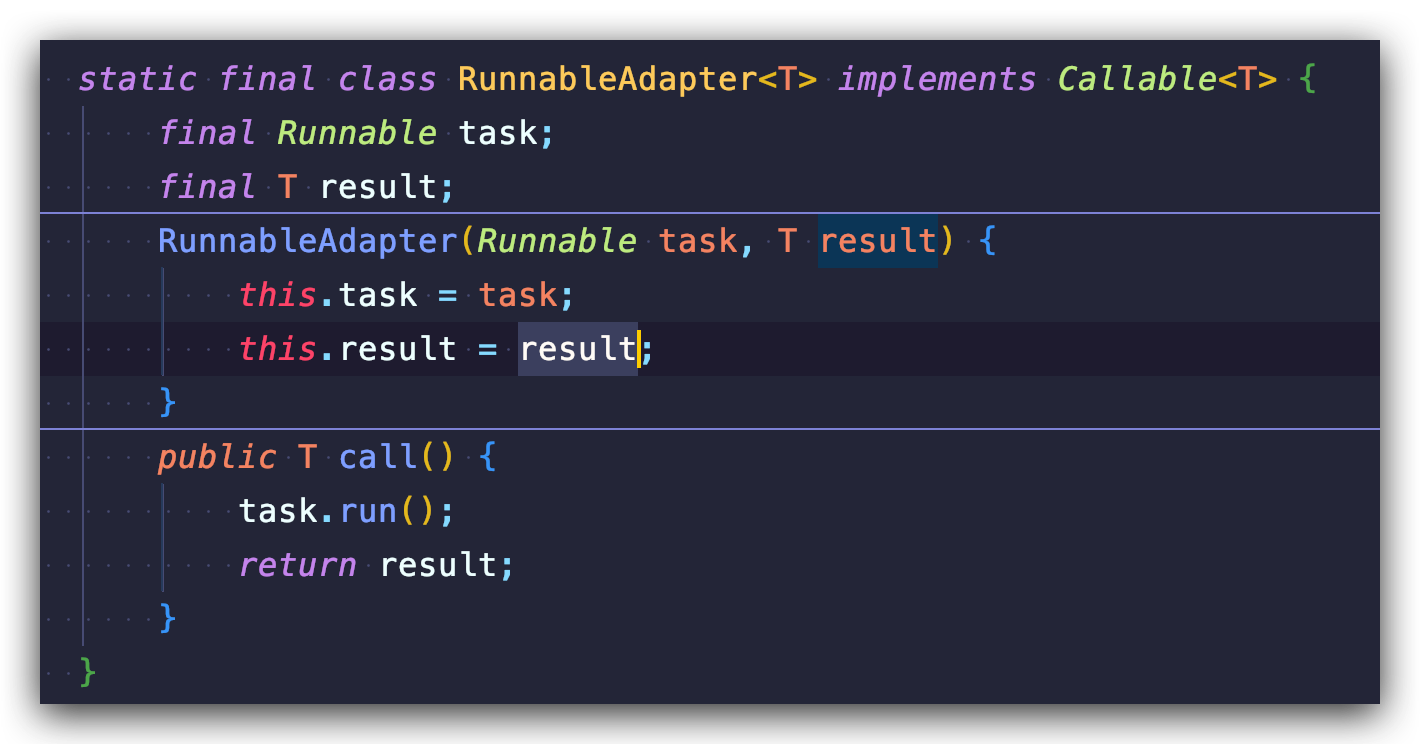
你会发现,和我们改造烧水泡茶的程序思维是相似的,可以传进去一个 result,result 相当于主线程和子线程之间的桥梁,通过它主子线程可以共享数据
第二个方法参数是 Runnable 类型参数,即便调用 get() 方法也是返回 null,所以仅是可以用来断言任务已经结束了,类似 Thread.join()
第三个方法参数是 Callable 类型参数,通过get() 方法可以明确获取 call() 方法的返回值
到这里,关于 Future 的整块讲解就结束了,还是需要简单消化一下的

总结
如果熟悉 Javascript 的朋友,Future 的特性和 Javascript 的 Promise 是类似的,私下开玩笑通常将其比喻成男朋友的承诺
回归到Java,我们从 JDK 的演变历史,谈及 Callable 的诞生,它弥补了 Runnable 没有返回值的空缺,通过简单的 demo 了解 Callable 与 Future 的使用。 FutureTask 又是 Future接口的核心实现类,通过阅读源码了解了整个实现逻辑,最后结合FutureTask 和线程池演示烧水泡茶程序,相信到这里,你已经可以轻松获取线程结果了
烧水泡茶是非常简单的,如果更复杂业务逻辑,以这种方式使用 Future 必定会带来很大的会乱(程序结束没办法主动通知,Future 的链接和整合都需要手动操作)为了解决这个短板,没错,又是那个男人 Doug Lea, CompletableFuture 工具类在 Java1.8 的版本出现了,搭配 Lambda 的使用,让我们编写异步程序也像写串行代码那样简单,纵享丝滑
接下来我们就了解一下 CompletableFuture 的使用
灵魂追问
- 你在日常开发工作中是怎样将整块任务做到分工与协作的呢?有什么基本准则吗?
- 如何批量的执行异步任务呢?
参考
- Java 并发编程实战
- Java 并发编程的艺术
- Java 并发编程之美
