

前言
对于一个树状结构的数据,如下图(图画的丑):
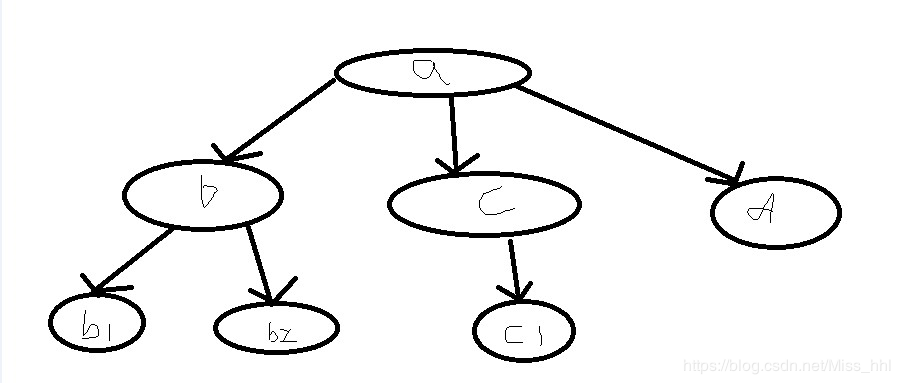
根节点a是唯一的,子节点b,c,d可以有多个(b,c,d)是同级节点,还有孙节点b1,b2等等的嵌套数据,这就是大致的树状结构数据。 那么如何遍历这样的数据呢?
- 深度遍历
- 深度遍历是从纵向的维度去思考问题,就是实现一层嵌套一层的遍历。深度遍历也可分为串行和并行。
- 串行深度遍历:从根节点a开始,先是遍历b,再遍历b下的b1,之后再遍历b2,当b的分支被遍历之后,开始遍历c的分支,与此类推。
- 并行深度遍历:从根节点开始,同级的b,c,d一起遍历,b节点下的b1,b2也一起被遍历了,同理c的分支也是,同级分支之间是并行遍历的。
- 广度遍历
- 广度遍历是从横向的维度去思考问题,关键是使用指针和队列实现遍历。广度遍历也可分为从头部开始和从尾部开始。
- 头部开始:先将根节点存在队列中(因为根节点是唯一的)。从根节点a出发,遍历a将a下的所以子节点b,c,d节点存放在队列中,再将指针往后面一位移动即到了队列的第二位,再次存放b节点下的子节点,以此类推。
- 尾部开始:以头部刚好相反的过程,指针应该是向前移动一位。 好了,了解了深度和广度那如何在node中使用呢?通过使用删除文件目录例子来更好的学习。在node中,有同步和异步的情况,所以都需要考虑到。
深度先序异步串行删除
function preParallDeep(dir,callback){
fs.stat(dir,function(err,statObj){
if(statObj.isFile()){
fs.unlink(dir,callback);
}else{
//files 是目录中文件的名称的数组(不包括 '.' 和 '..')
fs.readdir(dir,function(err,files){
files=files.map(item=>path.join(dir,item));
let index=0;
function next(){ //使用next实现异步函数
if(index==files.length) return fs.rmdir(dir,callback)
let current=files[index++];
preParallDeep(current,next);
}
next();
})
}
})
}
深度先序异步并行删除
- 通过循环+闭包+递归实现 使用闭包是为了解决循环过程中拿到每个子节点。
function preParallDeep(dir,callback){
fs.stat(dir,function(err,statObj){
if(statObj.isFile()){
fs.unlink(dir,callback);
}else{
//files 是目录中文件的名称的数组(不包括 '.' 和 '..')
fs.readdir(dir,function(err,files){
files=files.map(item=>path.join(dir,item));
if(files.length==0){ //空目录实现删除
return fs.rmdir(dir,callback);
}
for(let i=0;i<files.length;i++){ //循环同级的节点
(function(i){
//递归实现删除
preParallDeep(files[i],function(){
//回调函数实现当索引和父节点的长度-1相等则说明子节点以及完成被删除了,那么要删除父节点了
if(i==files.length-1){ //子节点
return fs.rmdir(dir,callback)
}
});
})(i)
}
})
}
})
}- 通过递归实现
function preParallDeep(dir,callback){
fs.stat(dir,function(err,statObj){
if(statObj.isFile()){
fs.unlink(dir,callback)
}else{
fs.readdir(dir,function(err,files){
files=files.map(item=>path.join(dir,item));
let index=0;
if(files.length===0) return fs.rmdir(dir,callback);
function done(){
if(++index==files.length) return fs.rmdir(dir,callback);
}
files.forEach(dir=>{
preParallDeep(dir,done)
})
})
}
})
}
- 通过Promise实现
function preParallDeep(dir){
return new Promise((resolve,reject)=>{
fs.stat(dir,function(err,statObj){ //fs.stat() 检查文件的存在性
if(statObj.isFile()){ //判断是否是文件
fs.unlink(dir,resolve);
}else{
fs.readdir(dir,function(err,files){
files=files.map(item=>preParallDeep(path.join(dir,item)));
Promise.all(files).then(()=>{
fs.rmdir(dir,resolve);
})
})
}
})
})
}
广度先序同步删除
function white(dir){
let arr=[dir];
let index=0;
let current;
while(current=arr[index++]){
let dirs=fs.readdirSync(current);
dirs=dirs.map(item=>path.join(current,item));
arr=[...arr,...dirs];
}
console.log(arr)
}
广度先序异步删除
function white(dir, callback) {
let currentDir, index = 0, arr = [dir];
function remove(dirs) {
let key=dirs.length-1;
function removeNext(){
fs.rmdir(dirs[key--],function(err){
if(key===0) return callback();
removeNext();
})
}
removeNext();
}
function next(currentDir) {
fs.stat(currentDir, function (err, statObj) { //fs.stat() 检查文件的存在性
if (statObj.isFile()) { //判断是否是文件
next(arr[++index]);
} else {
fs.readdir(currentDir, function (err, files) {
if (err) return;
files = files && files.map(item => path.join(currentDir,item));
arr = [...arr, ...files];
if (index === arr.length - 1) return remove(arr);
next(arr[++index]);
})
}
})
}
next(arr[index]);
}
总结
node的fs模块有异步和同步的api,异步和同步的处理方式也不同。在写递归函数先考虑第一层和第二层的关系,这样思路才不会乱,保持最清晰的头脑写代码,有想法可一起交流学习,来个技术思想的碰撞。最后,广度和深度遍历,对于性能一般来说深度会更好一点,广度更容易理解,当然也要看具体业务场景。
