

前言
本文重点叙述下mongodb存储特性和内部原理,
下一篇文章咱们一起来搭建下Replica Sets+Sharded Cluster的集群
存储引擎
wiredTiger引擎
1、3.0新增引擎 推荐使用 2、可以支撑更高的读写负载和并发量
所有的write请求都基于“文档级别”的lock,
因此多个客户端可以同时更新一个colleciton中的不同文档,
这种更细颗粒度的lock,可以支撑更高的读写负载和并发量。
因为对于production环境,更多的CPU可以有效提升wireTiger的性能,
因为它是的IO是多线程的
3、配置缓存
可以通过在配置文件中指定“cacheSizeGB”参数设定引擎使用的内存量,
此内存用于缓存工作集数据(索引、namespace,未提交的write,query缓冲等)
4、journal即预写事务日志
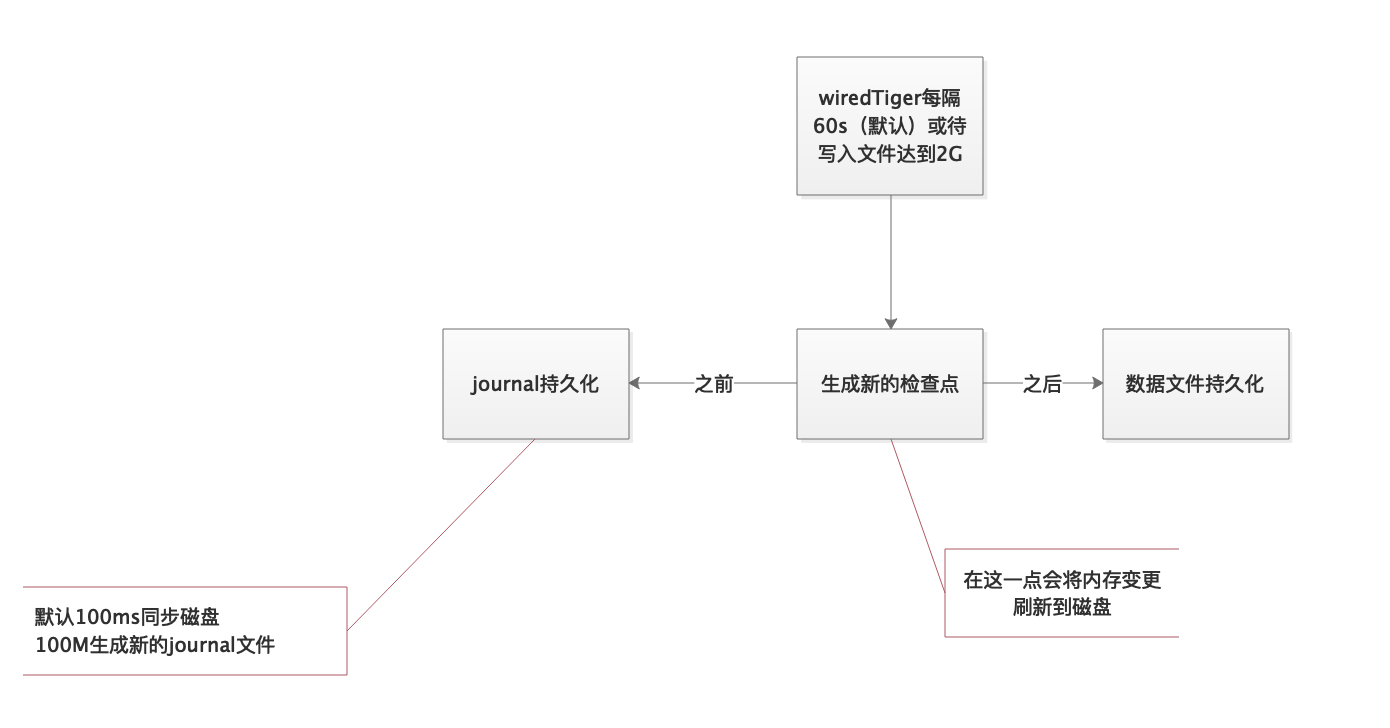
a、journal就是一个预写事务日志,来确保数据的持久性
b、wiredTiger每隔60秒(默认)或者待写入的数据达到2G时,mongodb将对journal文件提交一个checkpoint(检测点,将内存中的数据变更flush到磁盘中的数据文件中,并做一个标记点,表示此前的数据表示已经持久存储在了数据文件中,此后的数据变更存在于内存和journal日志)
c、对于write操作,首先被持久写入journal,然后在内存中保存变更数据,条件满足后提交一个新的检测点,即检测点之前的数据只是在journal中持久存储,但并没有在mongodb的数据文件中持久化,延迟持久化可以提升磁盘效率,如果在提交checkpoint之前,mongodb异常退出,此后再次启动可以根据journal日志恢复数据
d、journal日志默认每个100毫秒同步磁盘一次,每100M数据生成一个新的journal文件,journal默认使用了snappy压缩,检测点创建后,此前的journal日志即可清除。
e、mongod可以禁用journal,这在一定程度上可以降低它带来的开支;对于单点mongod,关闭journal可能会在异常关闭时丢失checkpoint之间的数据(那些尚未提交到磁盘数据文件的数据);对于replica set架构,持久性的保证稍高,但仍然不能保证绝对的安全(比如replica set中所有节点几乎同时退出时)
MMAPv1引擎
1、原生的存储引擎 直接使用系统级的内存映射文件机制(memory mapped files)
2、对于insert、read和in-place update(update不导致文档的size变大)性能较高
3、不过MMAPV1在lock的并发级别上,支持到collection级别 所以对于同一个collection同时只能有一个write操作执行 这一点相对于wiredTiger而言,在write并发性上就稍弱一些
4、对于production环境而言,较大的内存可以使此引擎更加高效,有效减少“page fault”频率
5、但是因为其并发级别的限制,多核CPU并不能使其受益
6、此引擎将不会使用到swap空间,但是对于wiredTiger而言需要一定的swap空间
7、对于大文件MAP操作,比较忌讳的就是在文件的中间修改数据,而且导致文件长度增长,这会涉及到索引引用的大面积调整
8、所有的记录在磁盘上连续存储,当一个document尺寸变大时,mongodb需要重新分配一个新的记录(旧的record标记删除,新的记record在文件尾部重新分配空间)
9、这意味着mongodb同时还需要更新此文档的索引(指向新的record的offset),与in-place update相比,将消耗更多的时间和存储开支。
10、由此可见,如果你的mongodb的使用场景中有大量的这种update,那么或许MMAPv1引擎并不太适合
11、同时也反映出如果document没有索引,是无法保证document在read中的顺序(即自然顺序)
12、3.0之后,mongodb默认采用“Power of 2 Sized Allocations”,所以每个document对应的record将有实际数据和一些padding组成,这padding可以允许document的尺寸在update时适度的增长,以最小化重新分配record的可能性。此外重新分配空间,也会导致磁盘碎片(旧的record空间)
Power of 2 Sized Allocations
1、默认情况下,MMAPv1中空间分配使用此策略,每个document的size是2的次幂,比如32、64、128、256...2MB,如果文档尺寸大于2MB,则空间为2MB的倍数(2M,4M,6M等)
2、2种优势
那些删除或者update变大而产生的磁盘碎片空间(尺寸变大,意味着开辟新空间存储此document,旧的空间被mark为deleted)可以被其他insert重用
再者padding可以允许文档尺寸有限度的增长,而无需每次update变大都重新分配空间。
3、mongodb还提供了一个可选的“No padding Allocation”策略(即按照实际数据尺寸分配空间),如果你确信数据绝大多数情况下都是insert、in-place update,极少的delete,此策略将可以有效的节约磁盘空间,看起来数据更加紧凑,磁盘利用率也更高
备注:mongodb 3.2+之后,默认的存储引擎为“wiredTiger”,大量优化了存储性能,建议升级到3.2+版本
Capped Collections
1、尺寸大小是固定值 类似于一个可循环使用的buffer
如果空间被填满之后,新的插入将会覆盖最旧的文档,通常不会对Capped进行删除或者update操作,所以这种类型的collection能够支撑较高的write和read
2、不需要对这种collection构建索引,因为insert是append(insert的数据保存是严格有序的)、read是iterator方式,几乎没有随机读
3、在replica set模式下,其oplog就是使用这种colleciton实现的
4、Capped Collection的设计目的就是用来保存“最近的”一定尺寸的document
db.createCollection("capped_collections",
new CreateCollectionOptions()
.capped(true)
.maxDocuments(6552350)
.usePowerOf2Sizes(false).autoIndex(true));//不会涉及到更新,所以可以不用power of 2
5、类似于“FIFO”队列,而且是有界队列 适用于数据缓存,消息类型的存储
6、Capped支持update,但是我们通常不建议,如果更新导致document的尺寸变大,操作将会失败,只能使用in-place update,而且还需要建立合适的索引
7、在capped中使用remove操作是允许的
8、autoIndex属性表示默认对_id字段建立索引
数据模型(Data Model)
1、mongodb支持内嵌document 即document中一个字段的值也是一个document
2、如果内嵌文档(即reference文档)尺寸是动态的,比如一个user可以有多个card,因为card数量无法预估,这就会导致document的尺寸可能不断增加以至于超过“Power of 2 Allocate”,从而触发空间重新分配,带来性能开销
3、这种情况下,我们需要将内嵌文档单独保存到一个额外的collection中,作为一个或者多个document存储,比如把card列表保存在card collection中
4、如果reference文档尺寸较小,可以内嵌,如果尺寸较大,建议单独存储。此外内嵌文档还有个优点就是write的原子性
索引
1、提高查询性能,默认情况下_id字段会被创建唯一索引;
2、因为索引不仅需要占用大量内存而且也会占用磁盘,所以我们需要建立有限个索引,而且最好不要建立重复索引;
3、每个索引需要8KB的空间,同时update、insert操作会导致索引的调整,
会稍微影响write的性能,索引只能使read操作收益,
所以读写比高的应用可以考虑建立索引
大集合拆分
比如一个用于存储log的collection,
log分为有两种“dev”、“debug”,结果大致为
{"log":"dev","content":"...."},{"log":"debug","content":"....."}。
这两种日志的document个数比较接近,
对于查询时,即使给log字段建立索引,这个索引也不是高效的,
所以可以考虑将它们分别放在2个Collection中,比如:log_dev和log_debug。
数据生命周期管理
mongodb提供了expire机制,
即可以指定文档保存的时长,过期后自动删除,即TTL特性,
这个特性在很多场合将是非常有用的,
比如“验证码保留15分钟有效期”、“消息保存7天”等等,
mongodb会启动一个后台线程来删除那些过期的document
需要对一个日期字段创建“TTL索引”,
比如插入一个文档:{"check_code":"101010",$currentDate:{"created":true}}},
其中created字段默认值为系统时间Date;然后我们对created字段建立TTL索引:
collection.createIndex(new Document("created",1),new IndexOptions().expireAfter(15L,TimeUnit.MILLISECONDS));//15分钟
向collection中insert文档时,created的时间为系统当前时间,
其中在creatd字段上建立了“TTL”索引,索引TTL为15分钟,
mongodb后台线程将会扫描并检测每条document的(created时间 + 15分钟)与当前时间比较,
如果发现过期,则删除索引条目(连带删除document)。
某些情况下,可能需要实现“在某个指定的时刻过期”,
只需要将上述文档和索引变通改造即可,
即created指定为“目标时间”,expiredAfter指定为0。
架构模式
Replica set 复制集
通常是三个对等的节点构成一个“复制集”集群,
有“primary”和secondary等多种角色
其中primary负责读写请求,secondary可以负责读请求,这又配置决定,
其中secondary紧跟primary并应用write操作;
如果primay失效,则集群进行“多数派”选举,选举出新的primary,即failover机制,即HA架构。
复制集解决了单点故障问题,也是mongodb垂直扩展的最小部署单位,
当然sharding cluster中每个shard节点也可以使用Replica set提高数据可用性。
Sharding cluster 分片集群
数据水平扩展的手段之一;
replica set这种架构的缺点就是“集群数据容量”受限于单个节点的磁盘大小,
如果数据量不断增加,对它进行扩容将时非常苦难的事情,所以我们需要采用Sharding模式来解决这个问题。
将整个collection的数据将根据sharding key被sharding到多个mongod节点上,
即每个节点持有collection的一部分数据,这个集群持有全部数据,
原则上sharding可以支撑数TB的数据。
系统配置
建议mongodb部署在linux系统上,较高版本,选择合适的底层文件系统(ext4),开启合适的swap空间
无论是MMAPV1或者wiredTiger引擎,较大的内存总能带来直接收益
对数据存储文件关闭“atime”(文件每次access都会更改这个时间值,表示文件最近被访问的时间),可以提升文件访问效率
ulimit参数调整,这个在基于网络IO或者磁盘IO操作的应用中,通常都会调整,上调系统允许打开的文件个数(ulimit -n 65535)。
数据文件存储原理(Data Files storage,MMAPV1引擎)
mongodb的数据将会保存在底层文件系统中,
比如我们dbpath设定为“/data/db”目录,
我们创建一个database为“test”,collection为“sample”,
然后在此collection中插入数条documents。我们查看dbpath下生成的文件列表:
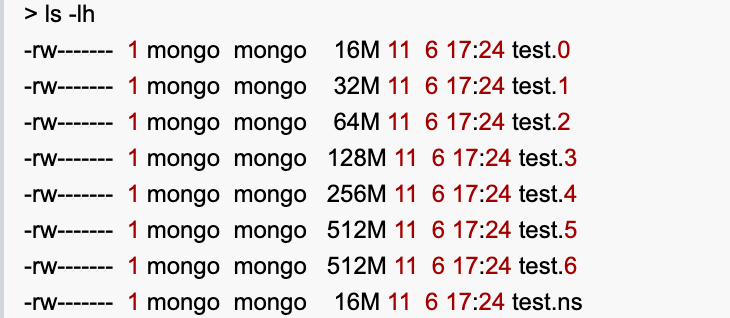
可以看到test这个数据库目前已经有6个数据文件(data files),
每个文件以“database”的名字 + 序列数字组成,
序列号从0开始,逐个递增,数据文件从16M开始,每次扩张一倍(16M、32M、64M、128M...),
在默认情况下单个data file的最大尺寸为2G,
如果设置了smallFiles属性(配置文件中)则最大限定为512M;
mongodb中每个database最多支持16000个数据文件,即约32T,
如果设置了smallFiles则单个database的最大数据量为8T。
如果你的database中的数据文件很多,
可以使用directoryPerDB配置项将每个db的数据文件放置在各自的目录中。
当最后一个data file有数据写入后,
mongodb将会立即预分配下一个data file,
可以通过“--nopreallocate”启动命令参数来关闭此选项
参考文档
https://blog.csdn.net/quanmaoluo5461/article/details/85164588
