

发展史
字节
在计算机内部,所有信息最终都是一个二进制值
位(bit)是计算机内部数据存储的最小单位,每一个二进制位(bit)有0和两种状态
字节(byte)是二进制数据的单位,一个字节通常8位长,1B(byte,字节) = 8bit(位),因此八个二进制位就可以组合成256种状态!
思考1:256种状态怎么算出来?
单位换算
- 1byte = 8bit
- 1byte = 1B
- 1KB = 1024B
- 1MB = 1024KB
- 1GB = 1024MB
- 1TB = 1024GB
进制
对于任何一种进制---X进制,就表示每一位置上的数运算时都是逢X进一位。 十进制是逢十进一,十六进制是逢十六进一,二进制就是逢二进一,以此类推,x进制就是逢x进位。
现在以十进制25举例看各种进制25的表示;
let a=0b11001;// 0b表示二进制
console.log(a);//25
let b=0o31;// 0o 八进制
let c=25;
let d=0x19;//0x 十六进制进制转换
js中的两个内置方法toString 和 parseInt;
toString可以把一个数转换为指定进制的数,parseInt是把数按照指定进制解析成十进制的数
1.任意进制转换成十进制;
console.log(parseInt('11001',2))//25console.log(parseInt('007F',16))//1272.十进制转成任意进制;
(25).toString(2)//11001
思考2:任意进制转成任意进制?
字节是计算机能够识别的单位,但是人不习惯识别字节,所以就有了字符编码的产生!
ASCII
最开始计算机只在美国用,在英语中,用128个符号编码便可以表示所有,这128个符号,只占用了一个字节的后面7位,最前面一位统一规定为0
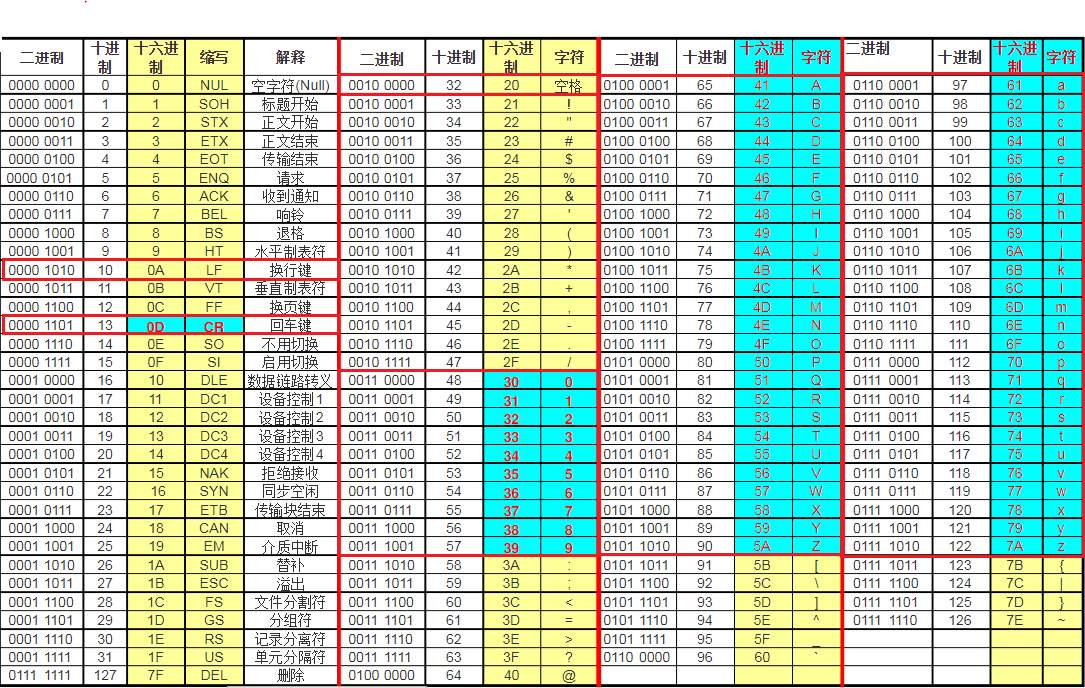
常见ASCII码的大小规则:0~9
ASCII 字符集沿用至今,但它最大的缺点在于只能表示基本的拉丁字母、阿拉伯数字和英式标点符号,于是各个国家制定了自己的字符编码规则;比如中国的GB2312;
GB2312
- ASCII 值小于 127 的字符的意义与原来 ASCII 集中的字符相同
- 但当两个 ASCII 值大于 127 的字符连在一起时,就表示一个简体中文的汉字
- 前面的一个字节(高字节)从 0xA1 拓展到 0xF7,后面一个字节(低字节)从 0xA1 到 0xFE,这样就可以组合出了大约 7000 多个简体汉字了。
- 把 ASCII 里本来就有的数字、标点、字母都统一重新表示为了两个字节长的编码,这就是我们常说的 "全角" 字符,127 号以下的那些就叫 "半角" 字符;
这就是常说的一个汉字算两个英文字符;而计算机通过识别第一个字节是否大于127,就可以知道应该是两个字节一起读取还是一个一个字节读取;
每个国家有自己独特的语言,制定了自己字符编码,为了统一所有文字的编码,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode(字符集)
为每个字符指定一个编号,这叫做"码点"
从上表可以看出汉字丁的Unicode码十六进制的表示是4E01
//js查询字符的Unicode码
console.log('丁'.charCodeAt())//19969
//字符编码转成字符串
console.log(String.fromCharCode('19969'));//丁
//十六进制表示
console.log('丁'.charCodeAt().toString(16));//4e01从Unicode开始,无论是半角的英文字符,还是全角的汉字,他们都是两个字符
- 字节是一个8位的物理存储单元
- 字符是一个文化相关的符合
Unicode 只是一个字符集,它只规定了字符的二进制代码,却没有规定这个二进制代码应该如何存储。比如汉字的Unicode编码都是三个字节,计算机怎么知道三个字节表示一个字符,而不是分别表示三个字符呢?为的便于Unicode的传输和存储,UTF应运而生!
UTF与Unicode
UTF(Unicode transformation format)Unicode转换格式,是服务于Unicode的,用于将一个Unicode码点转换为特定的字节序列。常见的UTF有UTF-8,UTF-16,UTF-32。
UTF-8(编码方式)
UTF-8 最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8 的编码规则很简单,只有二条:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
2)对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节121的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
下表总结了编码规则,字母x表示可用编码的位。
字符的Unicode编码范围 | UTF-8 编码方式
(十六进制) | (二进制)
--------------------+---------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
//Unicode都是十六进制,所有的汉字都是3个字节;
//js实现汉字的Unicode转成utf-8十六进制;
function transfer(num){
let arr=["1110","10","10"];
let str=num.toString(2);//先转成2进制;100111000100101
let len=str.length;
arr[2]+=str.substring(len-6);//截取最后6位
arr[1]+=str.substring(len-12,len-6);
arr[0]+=str.substring(0,len-12).padStart(4,'0');
return arr.map(item=>parseInt(item,2).toString(16)).join('');
}
let r=transfer(0x4e25);console.log(r);//e4b8a5以汉字严为例,演示如何实现 UTF-8 编码。
严的 Unicode 是4E25(100111000100101),根据上表,可以发现4E25处在第三行的范围内(0000 0800 - 0000 FFFF),因此严的 UTF-8 编码需要三个字节,即格式是1110xxxx 10xxxxxx 10xxxxxx。然后,从严的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,严的 UTF-8 编码是11100100 10111000 10100101,转换成十六进制就是E4B8A5。
数组sort排序方法
本文的初衷来源于sort方法没有参数时,按照ascii码进行排序的研究!
var arr=[1,2,'A','Z','a','z'];
arr.sort();
console.log(arr);//[1,2,'A','Z','a','z'];常见ascii排序规则
var a=[1,2,'A','AB','长沙','北京','a','ab','ac','z'];
a.sort();
console.log(a);// [1, 2, "A", "AB", "a", "ab", "ac", "z", "北京", "长沙"]
//对于ab之类多个字符的排序,先比较第一个字符串的unicode编码的大小,
//如果相同再比较第二个字符串unicode编码大小;所以ac排在z的前面,排在ab的后面;
'北京'.charCodeAt();//21271
'长沙'.charCodeAt();//38271//长沙的Unicode编码大于北京,所以长沙排在北京后面;通过排序规则的研究,扩展到整个计算机编码的探索!
