

MyBatis与设计模式的激情碰撞
最近一直在研究MyBatis的源码,MyBatis作为国内最为经常使用的持久层框架,其内部代码的设计也是极其优秀的!我们学习源码的目的是什么呢?
- 一方面是对该框架有一个很深入的认识,以便在开发过程中有能力对框架进行深度的定制化开发或者在解决BUG的时候更加得心应手!
- 一方面是学习代码里面优秀的设计,看看这些成名多年的框架,他们的开发者是如何设计出一个高扩展性、低耦合性的代码呢?然后在自己的开发场景中应用。
今天我们就来讨论一下,在MyBatis内部,为了提高代码的可读性究竟做了哪些设计呢?当然,如果你对MyBatis的代码特别熟悉,作者在文中有错误的地方欢迎指出来,因为作者还没有完整的通读MyBatis的源码,大概看了70%左右,后续看完之后,作者会考虑出一期关于MyBatis源码的解读,一方面是加强作者对于MyBatis源码的理解,一方面是让大家更好的学习MyBatis,话不多说,进入正题吧!
一、外观模式
外观模式,有些开发者也会把它叫做门面模式,他多用于接口的设计防,面,目的是封装系统的底层实现,隐藏系统的复杂性,提供一组更加简单易用、更高层的接口。我们将多个接口的Api替换为一个接口,以减少程序调用的复杂性,增加程序的易用性!
我们先看一段代码:
@Test
public void SqlSessionTest(){
//构建会话对象
SqlSession sqlSession = sqlSessionFactory.openSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
System.out.println(mapper.findUserByName("张三"));
}
熟悉Mybatis代码的同学应该对这个代码无比熟悉,利用会话工厂构建会话对象SqlSession,基于会话对象调用Mapper方法,但是凭什么我们只需要构建一个SqlSession对象就能够完全操作咱们的MyBatis呢?这里MyBatis的开发者使用了外观设计模式,将所有的操作Api都封装进了SqlSession内部,让使用者无需关心内部的底层实现就能够使用是不是很完美,那么内部他是如何操作的呢?由于本章内容的目的并不是为了分析源码,所以我们只需要知道如何实现的就行!我们进入到SqlSession内部
public class DefaultSqlSession implements SqlSession {
//忽略不必要代码
private final Executor executor;
//忽略不必要代码
public DefaultSqlSession(Configuration configuration, Executor executor, boolean autoCommit) {
//...
this.executor = executor;
//...
}
}
我们可以里看到SqlSession内部封装了一个Executor对象,也就是MyBatis的执行器,然后通过构造方法传递过来!后续所有的查询逻辑都是调用Executor内的方法来完成的实现,而SqlSession本身不做任何操作,所以就能仅仅通过一个对象,来构建起整个Mybatis框架的使用!
二、装饰者模式
装饰者模式:动态地给一个对象增加一些额外的职责,增加对象功能来说,装饰模式比生成子类实现更为灵活。装饰模式是一种对象结构型模式。装饰者设计模式的目的是为了给某一些没有办法或者不方便变动的方法动态的增加一些额外的功能!
鸟语说完了,转换成大白话就是,有些类没有办法经常改代码,但是有要求他在不同的场景下展示不同的功能,又想要女朋友,又想和其他美女撩骚!典型的渣男,但是装饰者模式真正为这一操作提供了可能!比如将美女装饰成自己的姐姐妹妹,阿姨大妈,那不就能痛快的撩骚了!开个玩笑,我对我家的绝对忠贞不二!那么MyBatis是如何使用这一设计模式呢?
众所周知,MyBatis存在二级缓存,但是我们有时候需要二级缓存,有时候又不需要,这个时候怎么办呢?因此MyBatis单独抽象出来了一个Executor的实现类CachingExecutor专门来做缓存相关的操作,它本身不做任何的查询逻辑,只实现自己的混村逻辑,从而可以动态的插拔MyBatis的缓存逻辑!具体的实现思路如下:
public class CachingExecutor implements Executor {
private final Executor delegate;
//.....忽略多余代码
public CachingExecutor(Executor delegate) {
this.delegate = delegate;
//.....忽略多余代码
}
//我们以二级缓存下的查询为例
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds,
ResultHandler resultHandler, CacheKey key, BoundSql boundSql)throws SQLException {
Cache cache = ms.getCache();
if (cache != null) {
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
@SuppressWarnings("unchecked")
//查询缓存是否存在
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
//不存在就调用其他执行器的 query 方法
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
//将查出来的对象放置到缓存中
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
//调用其他执行器的 query 方法
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
//.....忽略多余代码
}
我们可以看到,CachingExecutor通过构造方法传入一个真正的执行器,也就是一个真正能够查询的执行器,然后处理完缓存操作后,调用能够真正执行查询的执行器进行数据的查询,待数据查询到之后,再将数据放置到缓存内部,从而完成整个缓存的逻辑!这就是装饰者模式!
三、责任链模式
责任链设计模式:责任链模式(Chain of Responsibility)是多个对象都有机会处理请求,从而避免请求的发送者和接受者之间的耦合关系.将这些对象连成一条链,并沿着这条链传递该请求,直到有对象能够处理。
但是接下来介绍的这种事实上并没有完全遵守以上的概念,获取我们可以将这种设计模式叫做 责任链的变种:功能链,它的设计思想是分而治之,符合七大设计原则的 迪米特法则 合成复用原则 单一职责原则 ,它通过实现组合一种功能实现,链条上的每一个节点都能够处理一部分特有的操作,一直向下传递,最终完成整个操作!
我们还是基于MyBatis的二级缓存来说话,先看一张图:
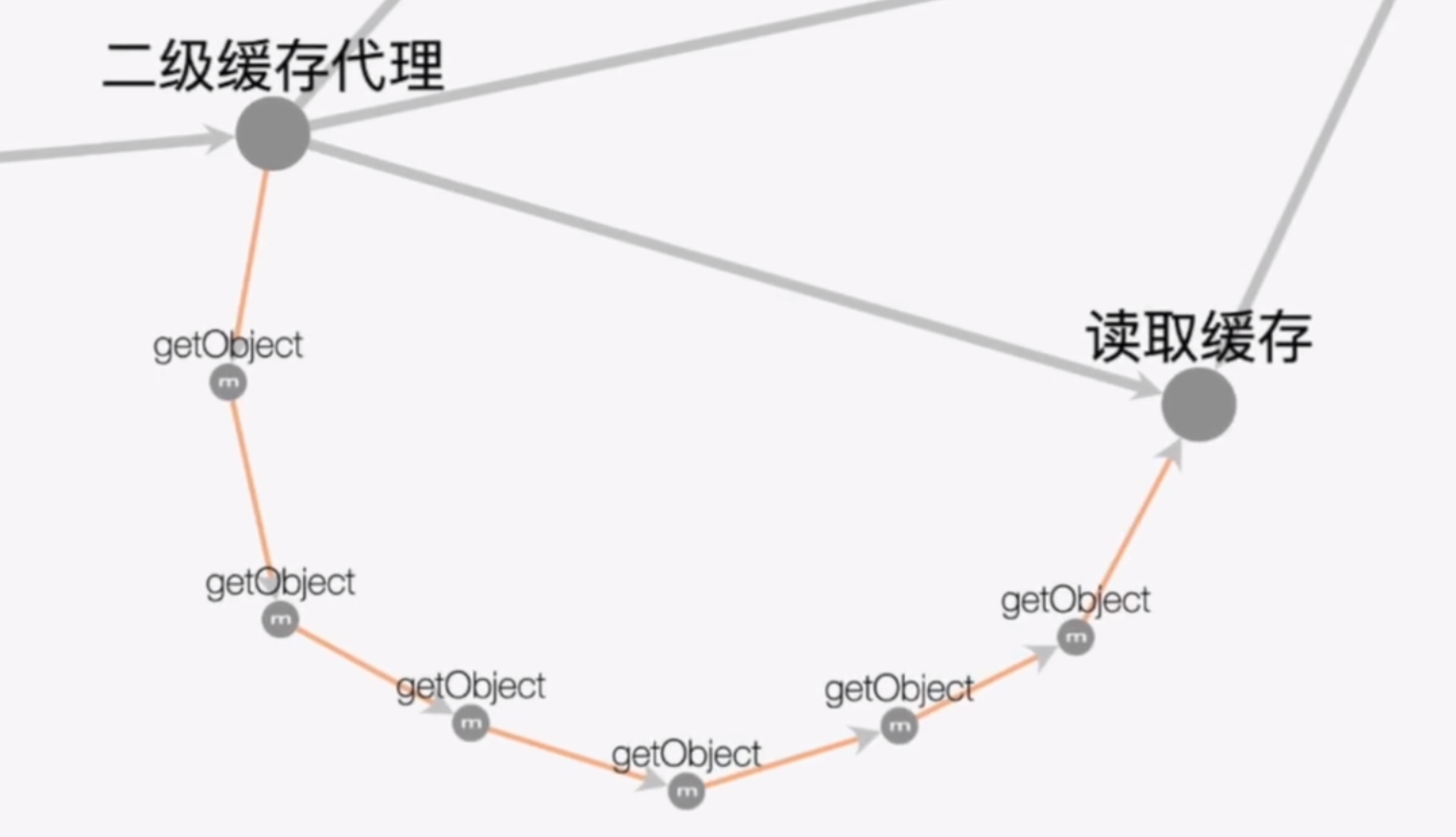
如果不懂责任链设计模式,就会懵逼,仅仅是一个缓存而已,弄这么多getObject()干嘛?事实上即使我们进入到源码中也会发现好多类似这样的逻辑:
我们先获取一个缓存对象,然后设置缓存:
@Test
public void CacheTest (){
Cache cache = configuration.getCache(UserMapper.class.getName());
cache.putObject("666","你好");
cache.getObject("666");
}
按照常规理解,他应该会把这个k-v值放置到 Map中或者执行一些逻辑操作在放到Map中,但是我们却发现下面这一段:
org.apache.ibatis.cache.decorators.SynchronizedCache#putObject
@Override
public synchronized void putObject(Object key, Object object) {
delegate.putObject(key, object);
}
你心态崩不崩,行继续往下跟:
org.apache.ibatis.cache.decorators.LoggingCache#putObject
@Override
public void putObject(Object key, Object object) {
delegate.putObject(key, object);
}
你又会发现这样一段逻辑,继续往下也一样,那么MyBatis为什么会搞这么多空方法呢?显得代码牛逼?当然不是,他这么设计肯定是有一定的用意的,什么用意呢?
事实上我们发现org.apache.ibatis.cache.decorators.SynchronizedCache#putObject这个方法上增加了synchronized属性,他是为了解决多线程的并发问题的,org.apache.ibatis.cache.decorators.LoggingCache#putObject这个方法本身没做什么,但是我们看getObject方法:
@Override
public Object getObject(Object key) {
requests++;
final Object value = delegate.getObject(key);
if (value != null) {
hits++;
}
if (log.isDebugEnabled()) {
log.debug("Cache Hit Ratio [" + getId() + "]: " + getHitRatio());
}
return value;
}
这个类是为了统计二级缓存的命中率的,诸如此类,往下还有org.apache.ibatis.cache.decorators.SerializedCache#putObject做二级缓存序列化的、org.apache.ibatis.cache.decorators.LruCache#putObject最少使用缓存淘汰策略的以及org.apache.ibatis.cache.impl.PerpetualCache#putObject真正的缓存方法,这是一个功能链条,其实这个例子与使用了一定的装饰模式,通过构造函数:
public SynchronizedCache(Cache delegate) {
this.delegate = delegate;
}
设置本次处理完成后的下一个处理节点,从而完成整个链条的调用,那么在哪里构建链条的呢?我们看一段代码,这里由于篇幅原因,作者不做太多的讲解,大家看一下就行:
private Cache setStandardDecorators(Cache cache) {
try {
MetaObject metaCache = SystemMetaObject.forObject(cache);
if (size != null && metaCache.hasSetter("size")) {
metaCache.setValue("size", size);
}
if (clearInterval != null) {
cache = new ScheduledCache(cache);
((ScheduledCache) cache).setClearInterval(clearInterval);
}
if (readWrite) {
cache = new SerializedCache(cache);
}
cache = new LoggingCache(cache);
cache = new SynchronizedCache(cache);
if (blocking) {
cache = new BlockingCache(cache);
}
return cache;
} catch (Exception e) {
throw new CacheException("Error building standard cache decorators. Cause: " + e, e);
}
}
可以看到,以上代码通过各种条件的判断往里面放置调用链节点,从而构建出一整个链条,但是事实上,Mybatis中对链条的构建远不止那么简单,这个我们以后再议!
四、动态代理模式
代理模式:为其它对象提供一种代理以控制对这个对象的访问。当无法或不想直接访问某个对象存在困难时可以通过一个代理对象来间接访问,为了保证客户端使用的透明性,委托对象与代理对象需要实现相同的接口。
MyBatis中是在哪里使用的动态代理的设计模式呢?众所周知,我们在使用MyBatis的时候,只需要将对应的Dao层抽象出一个接口,后续的调用逻辑就能够完整的调用数据库实现各种逻辑,但是你是否疑惑过,MyBatis的Mapper我们明明没有设置实现类啊,他是如何操作数据库的呢?这里就使用了动态代理设计模式!
我们先看一段代码:
@Test
public void SqlSessionTest(){
//构建会话对象
SqlSession sqlSession = sqlSessionFactory.openSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
System.out.println(mapper.findUserByName("张三"));
}
UserMapper对象是一个接口,只需要将他交给Mybatis就能够自己完成对应的逻辑,我们通过断点一步步跟下去,会发现这样一段逻辑:
protected T newInstance(MapperProxy<T> mapperProxy) {
return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface }, mapperProxy);
}
看到这里,熟悉jdk动态代理的同学可能会恍然大悟,原来它使用的是动态代理来实现的对应实现类,mapperInterface.getClassLoader()是类加载器,mapperInterface是要代理的接口,mapperProxy是真正的实现操作,他是InvocationHandler的子类,目的就是完成代理类的自定义的代码操作!它事实上会构建这么个东西:
public class MapperProxy<T> implements InvocationHandler, Serializable {
//........
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
} else {
return cachedInvoker(method).invoke(proxy, method, args, sqlSession);
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
//........
}
最终会调用mapperMethod.execute(sqlSession, args)方法来构建与底层数据库的交互操作,在使用中,你获取的事实上不是接口的实现类,而是接口的代理对象,由生成的代理对象,完成了后续的所有操作!
五、总结
本篇文章事实上很多的代码细节都是一概而过,并没有深入讲解,当然这也不是我写本篇文章的一个目的,本篇文章的目的仅仅是想要让使用者能够了解一些MyBatis的大致细节,从而对MyBatis有一个整体的认知,方便再自己调试源码的时候,不至于那么懵逼!
才疏学浅,如果文章中理解有误,欢迎大佬们私聊指正!欢迎关注作者的公众号,一起进步,一起学习!

