

关注可以查看更多粉丝专享blog~
二阶段提交(2PC)
- 第一阶段:请求/表决阶段
- 在分布式事务发起者向分布式事务协调者发送请求的时候,事务协调者向所有参与者发送事务预处理请求(vote request)
- 这个时候参与者会开启本地事务并开始执行本地事务,执行完成后不会commit,而是向事务协调者报告是否可以处理本次事务
- 第二阶段:提交/执行/回滚阶段
- 分布式事务协调者收到所有参与者反馈后,所有参与者节点均响应可以提交,则通知参与者和发起者执行commit,否则rollback
三点常见问题:
- 性能问题:从流程上面可以看出,最大的缺点就是在执行过程中节点都处于阻塞状态。各个操作数据库的节点都占用着数据库资源,只有当所有节点准备完毕,事务协调者才会通知进行全局commit/rollback,参与者进行本地事务commit/rollback之后才会释放资源,对性能影响较大。
- 单点故障问题:事务协调者是整个分布式事务的核心,一旦事务协调者出现故障,会导致参与者收不到commit/rollback的通知,从而导致参与者节点一直处于事务无法完成的中间状态。
- 消息丢失问题:在第二阶段的时候,如果发生局部网络问题,一部分事务参与者收不到commit/rollback消息,那么就会导致节点间数据不一致。
三阶段提交(3PC)
在2PC的基础上增加了CanCommit阶段,并引入了超时机制。一旦事务参与者指定时间没有收到协调者的commit/rollback指令,就会自动本地commit,这样可以解决协调者单点故障的问题。
- CanCommit阶段(提交询问)
- 分布式事务协调者询问所有参与者是否可以进行事务操作,参与者根据自身健康情况,是否可以执行事务操作响应Y/N。
- PreCommit阶段(预提交)
- 如果参与者返回的都是同意,协调者则向所有参与者发送预提交请求,并进入prepared阶段。
- 参与者收到预提交请求后,执行事务操作,并保存Undo和Redo信息到事务日志中。
- 参与者执行完本地事务之后(uncommitted),会向协调者发出Ack表示已准备好提交,并等待协调者下一步指令。
- 如果协调者收到预提交响应为拒绝或者超时,则执行中断事务操作,通知各参与者中断事务(abort)。
- 参与者收到中断事务(abort)或者等待超时,都会主动中断事务/直接提交。(超时情况下国内很多博客讲的是直接中断,但是wiki说的是直接提交,这里中断或提交都存在不确定性,都只有一半的概率做对,可能造成不一致情况,需要看不同框架的实现。此处需要TODO一下)
If, after a cohort member receives a preCommit message, the coordinator fails or times out, the cohort member goes forward with the commit.
- doCommit阶段(最终提交)
- 协调者收到所有参与者的Ack,则从预提交进入提交阶段,并向各参与者发送提交请求。
- 参与者收到提交请求,正式提交事务(commit),并向协调者反馈提交结果Y/N。
- 协调者收到所有反馈消息,完成分布式事务。(参与者包含事务发起者,比如A调用B,其实AB都参与了分布式事务)
- 如果协调者超时没有收到反馈,则发送中断事务指令(abort)。
- 参与者收到中断事务指令后,利用事务日志进行rollback。
- 参与者反馈回滚结果,协调者接收反馈结果或者超时,完成中断事务。
TCC(Try-Confirm-Cancel)
- Try
- 做业务检查及资源预留(比如冻结库存,而不是直接减库存)。
- Confirm
- 确认提交,在Try阶段所有事务参与者执行成功之后开始执行Confirm,通常情况下,TCC默认Confirm是不会出错的,认为只要Try成功,则Confirm一定成功,若Confirm真的出错了,需要采用重试机制或者人工干预。
- Cancel
- 执行回滚,在Try阶段有事务参与者执行失败则开始执行Cancel,通常情况下,TCC默认Cancel是不会出错的,认为只要Try成功,则Cancel一定成功,若Cancel真的出错了,需要采用重试机制或者人工干预。
优缺点:
- 优点:解决了性能问题,不阻塞,不占用数据库资源。
- 缺点:代码入侵强,每个事务都需要实现try,confirm和cancel,还需要保证接口幂等性,开发、维护成本高。
RocketMQ基于消息达到最终一致性
RocketMQ事务消息流程图(图片来自阿里云):
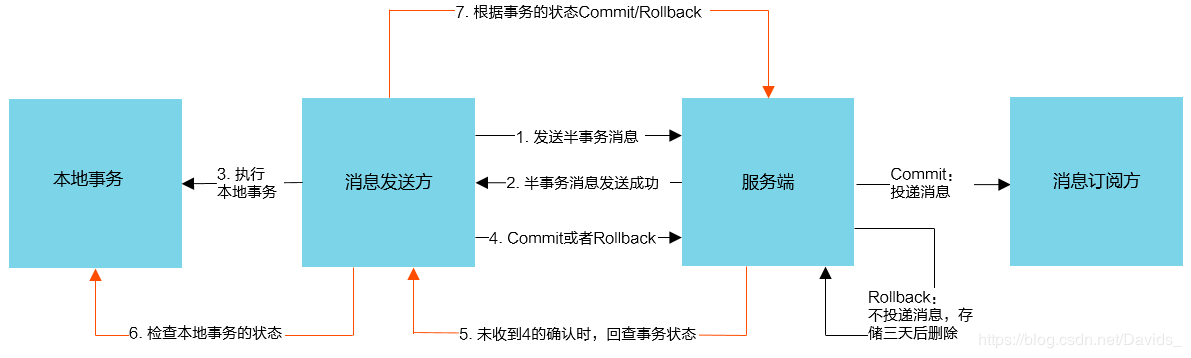
- TransactionStatus.CommitTransaction:提交事务,它允许消费者消费此消息。
- TransactionStatus.RollbackTransaction:回滚事务,它代表该消息将被删除,不允许被消费。
- TransactionStatus.Unknown:中间状态,它代表需要检查消息队列来确定状态。
执行流程:
- 消息发送方开启事务,发送半事务消息到RocketMQ,但是该消息只保存在commitlog中,对消费者是不可见的,没有保存到customerQueue中。
- 消息发送方处理完本次事务之后,进入第二阶段。
- 如果成功则发送commit确认消息到RocketMQ将半事务消息保存到customerQueue中,让customer进行消费。
- 如果失败则发送rollback消息到RocketMQ将半事务消息删除。
异常分析:
- 预备消息发送失败。(流程会中断,所以无影响)
- 预备消息发送成功,但是本地事务执行失败。(预备消息没有进入customerQueue,不会被消费到,所以无影响)
- 预备消息发送成功,本地事务执行成功,但是发送确认消息失败,导致消息不能进入customerQueue,消费者无法消费。(解决方案:消息回查机制)
消息回查机制:
- RocketMQ会定时检查commitlog中的预备消息,并回查本地业务(实现LocalTransactionChecker接口的check方法)。
- RocketMQ会根据回查状态决定commit到customerQueue还是rollback删除消息(解决异常2和异常3)。
- 为了降低代码入侵和判断的复杂度,可以单独设计一张事务(Transaction)表与具体业务解耦,会查的时候根据事务表的状态进行查询即可。
保障消费幂等性:
- RocketMQ中Message ID有可能出现冲突,所以建议使用业务唯一标识最为幂等性处理的依据。
- 在消费的时候使用redis判断消息是否消费过。
总结
强一致性分布式事务代码入侵较低,但是会阻塞,占用资源,影响性能;TCC代码和业务入侵较大;弱一致性事务异步操作就会涉及到异常情况下的回滚重试,回滚失败等。所以最后还是需要从自身业务情况触发来进行选择,以下是目前主流分布式事务实现(排名不分先后)。
