

Kubernetes Service[1] 用于实现集群中业务之间的互相调用和负载均衡,目前社区的实现主要有userspace,iptables和IPVS三种模式。IPVS模式的性能最好,但依然有优化的空间。该模式利用IPVS内核模块实现DNAT,利用nf_conntrack/iptables实现SNAT。nf_conntrack是为通用目的设计的,其内部的状态和流程都比较复杂,带来很大的性能损耗。
腾讯TKE团队[2] 开发了新的IPVS-BPF模式,完全绕过nf_conntrack的处理逻辑,使用eBPF完成SNAT功能。对最常用的Pod访问ClusterIP场景,短连接性能提升40%,p99时延降低31%;NodePort场景提升,详情见下表和性能测量章节。
一、容器网络现状
iptables模式
存在的问题:
1.可扩展性差。随着service数据达到数千个,其控制面和数据面的性能都会急剧下降。原因在于iptables控制面的接口设计中,每添加一条规则,需要遍历和修改所有的规则,其控制面性能是O(n²)。在数据面,规则是用链表组织的,其性能是O(n)
2.LB调度算法仅支持随机转发
IPVS模式
IPVS 是专门为LB设计的。它用hash table管理service,对service的增删查找都是O(1)的时间复杂度。不过IPVS内核模块没有SNAT功能,因此借用了iptables的SNAT功能。IPVS 针对报文做DNAT后,将连接信息保存在nf_conntrack中,iptables据此接力做SNAT。该模式是目前Kubernetes网络性能最好的选择。但是由于nf_conntrack的复杂性,带来了很大的性能损耗。
二、IPVS-BPF方案介绍
eBPF 介绍
eBPF[3]是Linux内核中软件实现的虚拟机。用户把eBPF程序编译为eBPF指令,然后通过bpf()系统调用将eBPF指令加载到内核的特定挂载点,由特定的事件来触发eBPF指令的执行。在挂载eBPF指令时内核会进行充分验证,避免eBPF代码影响内核的安全和稳定性。另外内核也会进行JIT编译,把eBPF指令翻译为本地指令,减少性能开销。
内核在网络处理路径上中预置了很多eBPF的挂载点,例如xdp, qdisc, tcp-bpf, socket等。eBPF程序可以加载到这些挂载点,并调用内核提供的特定API来修改和控制网络报文。eBPF程序可以通过map数据结构来保存和交换数据。
基于eBPF的IPVS-BPF优化方案
针对nf_conntrack带来的性能问题,腾讯TKE团队设计实现了IPVS-BPF。核心思想是绕过nf_conntrack,减少处理每个报文的指令数目,从而节约CPU,提高性能。其主要逻辑如下:
1.在IPVS内核模块中引入开关,支持原生IPVS逻辑和IPVS-BPF逻辑的切换
2.在IPVS-BPF模式下,将IPVS hook点从LOCALIN前移到PREROUTING,使访问service的请求绕过nf_conntrack
3.在IPVS新建连接和删除连接的代码中,相应的增删eBPF map中的session信息
4.在qdisc挂载eBPF的SNAT代码,根据eBPF map中的session信息执行SNAT
此外,针对icmp, fragmentation均有专门处理,详细背景和细节,会在后续的QCon在线会议[4]上介绍, 欢迎一起探讨。
优化前后报文处理流程的对比
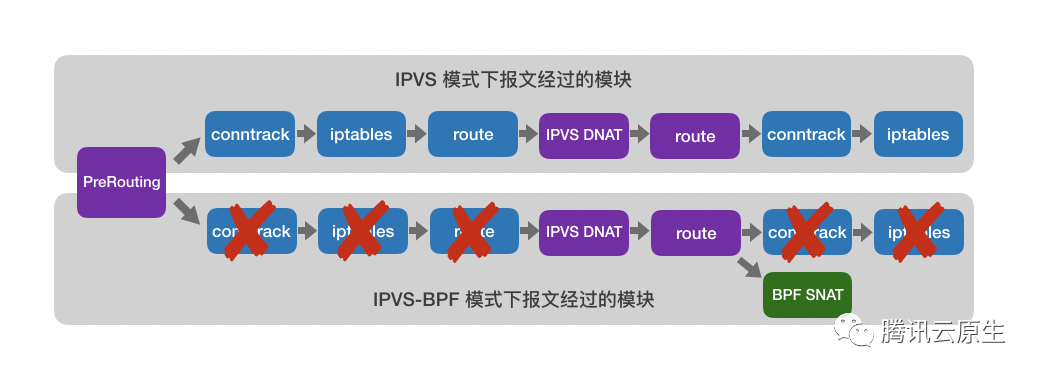
可以看到,报文处理流程得到了极大简化。
为什么不直接采用全eBPF方式
很多读者会问,为什么还要用IPVS模块跟eBPF相结合,而不是直接使用eBPF把Service功能都实现了呢?
我们在设计之初也仔细研究了这个问题, 主要有以下几点考虑:
•nf_conntrack对CPU指令和时延的消耗,大于IPVS模块,是转发路径的头号性能杀手。而IPVS本身是为高性能而设计的,不是性能瓶颈所在
•IPVS有接近20年的历史,广泛应用于生产环境,性能和成熟度都有保障
•IPVS内部通过timer来维护session表的老化,而eBPF不支持timer, 只能通过用户空间代码来协同维护session表
•IPVS支持丰富的调度策略,用eBPF来重写这些调度策略,代码量大不说,很多调度策略需要的循环语句,eBPF也不支持
我们的目标是实现代码量可控,能落地的优化方案。基于以上考虑,我们选择了复用IPVS模块,绕过nf_conntrack,用eBPF完成SNAT的方案。最终数据面代码量为:500+行BPF代码, 1000+行IPVS模块改动(大部分为辅助SNAT map管理的新增代码)。
三、性能测量
本章节通过量化分析的方法,用perf工具读取CPU性能计数器,从微观的角度解释宏观的性能数据。本文采用的压测程序是wrk和iperf。
测试环境
复现该测试需要注意两点:
1.不同的集群和机器,即使机型都一样,也可能因为各自母机和机架的拓扑不同,造成性能数据有背景差异。为了减少这类差异带来的误差,我们对比IPVS模式和IPVS-BPF模式时,是使用同一个集群,同样一组后端Pod, 并且使用同一个LB节点。先在IPVS模式下测出IPVS性能数据,然后把LB节点切换到IPVS-BPF模式, 再测出IPVS-BPF模式的性能数据。(注:切换模式是通过后台把控制面从kube-proxy切换为kube-proxy-bpf来实现的,产品功能上并不支持这样在线切换)
2.本测试的目标是测量LB上软件模块优化对于访问service性能的影响,不能让客户端和RS目标服务器的带宽与CPU成为瓶颈。所以被压测的LB节点采用1核机型,不运行后端Pod实例;而运行后端服务的节点采用8核机型
NodePort
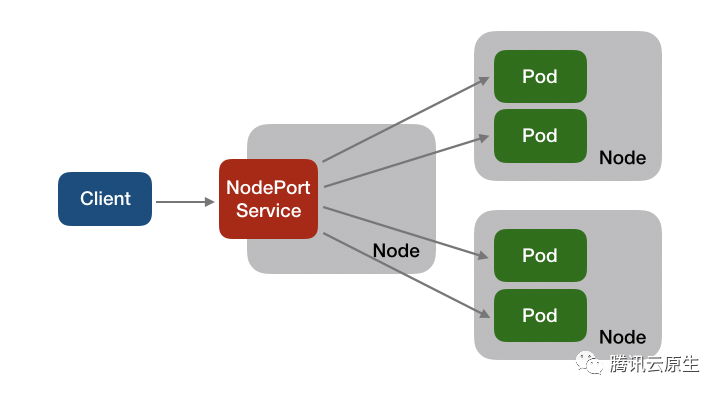
为了采集CPI等指标,这里LB节点(红色部分)采用黑石裸金属机器,但通过hotplug只打开一个核,关闭其余核。
ClusterIP
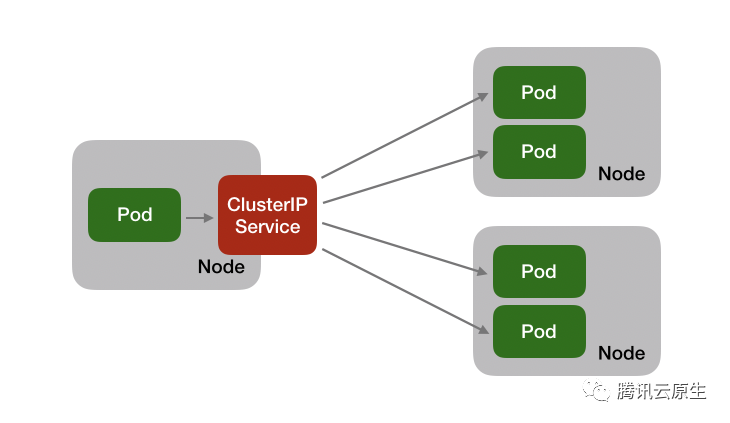
这里LB节点(左边的Node)采用SA2 1核1G机型。
测量结果
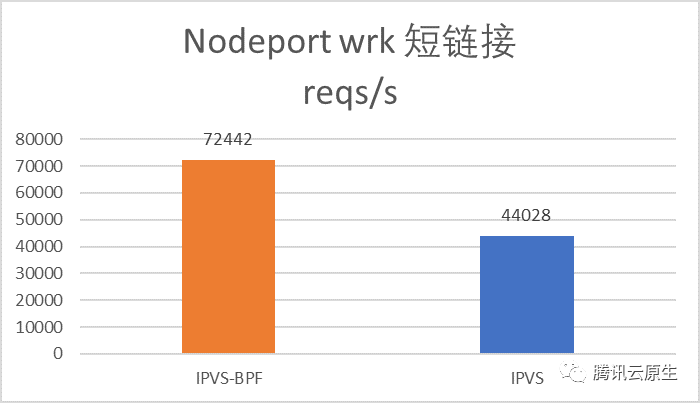

IPVS-BPF模式相对IPVS模式,NodePort短连接性能提高了64%,ClusterIP短连接性能提高了40%。
NodePort优化效果更明显,是因为NodePort需要SNAT,而我们的eBPF SNAT比iptables SNAT更高效,所以性能提升更多。
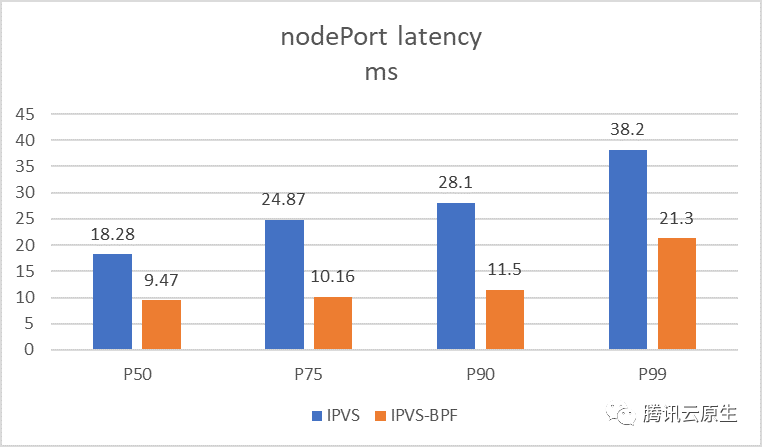
上图中,wrk测试表明NodePort 短连接p99延迟降低了47%。
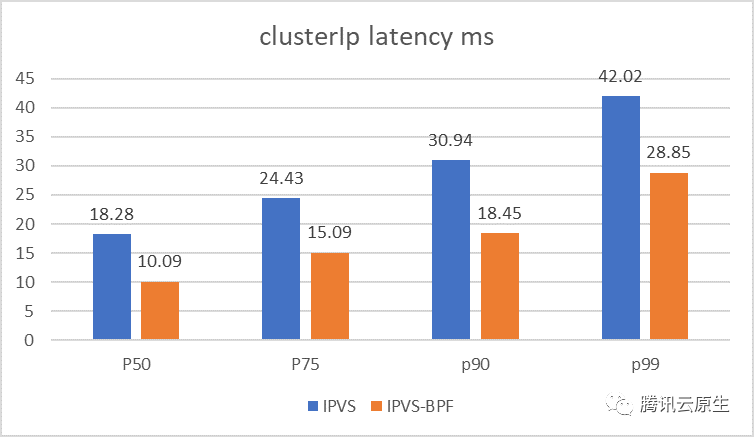
上图中,wrk测试表明ClusterIP短连接的p99延迟降低了31%。
指令数和CPI

上图中从Perf工具看,平均每个请求耗费的CPU指令数,IPVS-BPF模式下降了38%。这也是性能提升的最主要原因。

IPVS-BPF 模式下CPI略有增加,大概16%。
测试总结

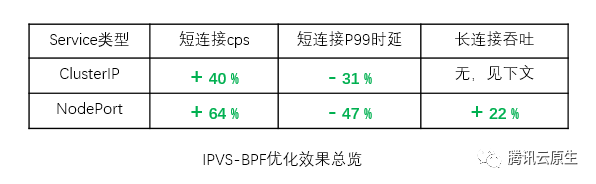
短连接cps
短连接p99延迟
长连接吞吐
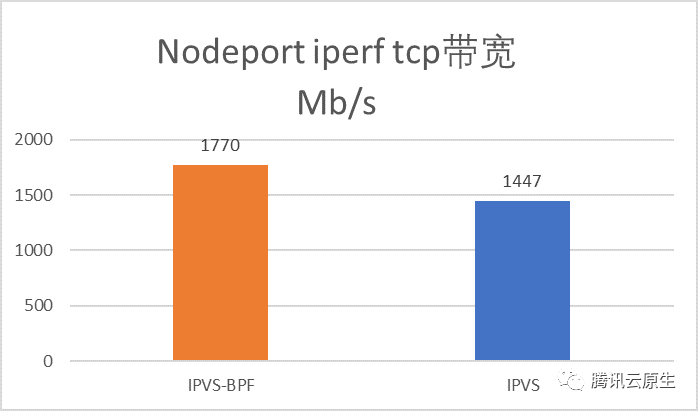
clusterIP +40% -31% 无,见下文 nodePort +64% -47% +22%
如上表,IPVS-BPF模式相对原生IPVS模式,Nodeport处理短连接性能提升了64%,p99延迟降低了47%,处理长连接带宽提升了22%;ClusterIP处理短连接吞吐量提升了40%, p99延迟降低了31%。
测试ClusterIP长连接吞吐时,iperf本身消耗了99% 的CPU,使得优化效果不容易直接测量。另外我们还发现IPVS-BPF模式下CPI有增加,值得进一步研究。
四、其他优化,特性限制和后续工作
在开发IPVS-BPF方案过程中,顺便解决或优化了一些其他问题
•conn_reuse_mode = 1时新建性能低[5]以及no route to host问题[6]
这个问题是当client发起大量新建TCP连接时,新的连接被转发到terminating的Pod上,导致持续丢包。此问题在IPVS conn_reuse_mode=1的情况下不会有。但是conn_reuse_mode=1时,有另外的新建连接性能急剧下降的bug, 故一般都设置成了conn_reuse_mode=0。我们在TencentOS内核中彻底修复了该问题,代码在ef8004f8[7], 8ec35911[8], 07a6e5ff63[9] 同时也正在向内核社区提交修复。
•DNS解析偶尔5s延时[10]
iptables SNAT分配lport到调用插入nf_conntrack,这中间是采用乐观锁机制。这中间如果发生竞争,相同的lport和五元组同时插入nf_conntrack会导致丢包。在IPVS-BPF模式下,SNAT选择lport的过程和插入hash table的过程在同一个循环中,循环次数最大为5次,从而减少了该问题的概率。
•externalIP优化[11]造成clb健康检查失败问题
详情见:github.com/kubernetes/ … 07864
特性限制
•Pod访问自身所在的service,IPVS-BPF模式会把请求转发给其他pod,不会把请求转发给Pod自己
后续工作
•借鉴Cilium提出的方法,利用eBPF进一步优化clusterIP性能
•研究IPVS-BPF模式下CPI上升的原因,探索进一步提升性能的可能性
五、如何在TKE启用IPVS-BPF模式
如下图,在腾讯云TKE控制台[12]创建集群时,高级设置下的Kube-proxy代理模式选项,选择 ipvs-bpf即可。

目前该特性需要申请白名单。请通过申请页[13]提交申请。
六、相关专利
本产品产生的相关专利申请如下:
2019050831CN 一种报文传输的方法及相关装置
2019070906CN 负载均衡方法、装置、设备及存储介质
2020030535CN 一种利用eBPF技术探测网络服务应用闲置的方法
2020040017CN 宿主机实时负载感知的自适应的负载均衡调度算法
