


前言
流光容易把人抛,红了樱桃,绿了芭蕉。悄然间墙上的钟摆已经指向了 2020 年中旬,时间就像是一只藏在黑暗中温柔的手,在你一出神一恍惚之间,斗转星移。2020 年对人类来说是异常坎坷的一年,无论是澳大利亚的森林火灾还是席卷全球的瘟疫,都给地球蒙上了一层灰色的面纱,然而人类并没有坐以待毙,而是奋起反击!京东作为国民品牌,更是承担起社会责任,始终奋斗在抗争的第一线。
京东 PLUS 会员,是京东为向核心客户提供更优质的购物体验推出的服务,在庚子年间,历经半载,茁壮成长:几大频道页轮番改版换新颜,联名卡也迎来了腾讯 QQ 音乐、芒果 TV 的强势入驻,计算器页面改版以及 PLUS 会员自建风控体系的建立,无论是在用户吸引度还是在项目可配置化上都下足了功夫,比如:
频道首页增加弹窗信封动画,增强趣味性,加入挽留弹窗功能,减少佛系用户来去匆匆,不带走一片云彩的情况;

改版页面增加沉浸式以及楼层换肤功能,烘托氛围,增强用户感知;以及整个页面实现配置化,减少后期前端维护上线成本。

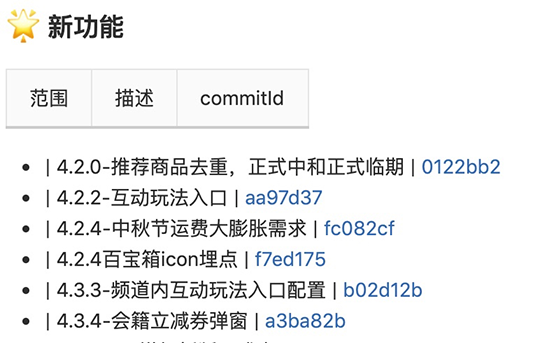
此外,2020 年上半年主要从页面改版、新增权益、优化完善功能、研发优化等方面支持了以下需求:
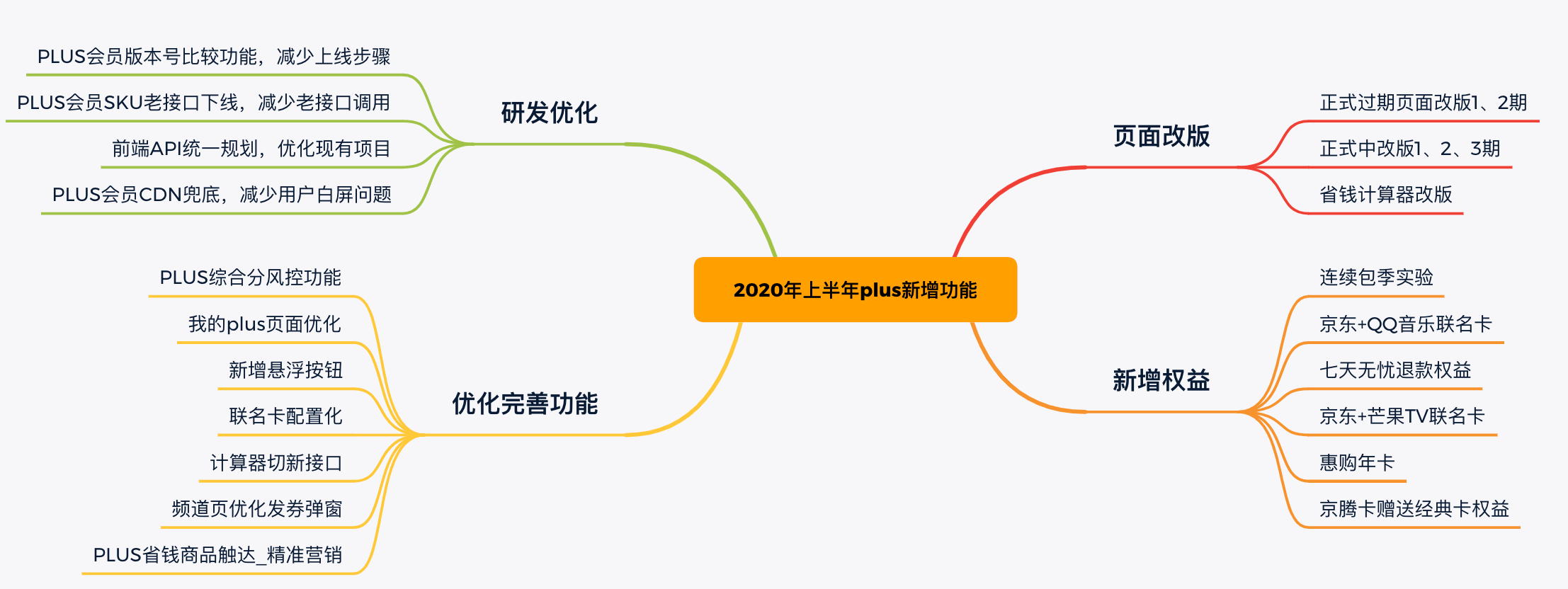
目前正式用户已经接近两千万大关,一切是那么的欣欣向荣、朝气蓬勃。
然而沉下心来,无论是技术的升级,还是项目的不断完善,在《2019年京东PLUS会员前端开发之路》一文中所提及的优化,都相当于万里长征第一步,我们要做的事情还很多,尤其是随着一次次需求的快速迭代,一些新的问题逐渐暴露出来,我们逐渐意识到一个优秀的项目,必须能够建立起完善的架构以及周边系统,才能保证项目的不断更新迭代和高效的开发。诚然,到目前为止我们可以做的仍然有很多,但是不妨暂停脚步,回首梳理一下这半年来走过的路,取其精华,弃其糟粕。
接下来本文将从提高开发效率、优化项目架构、完善用户体验等方面入手,和大家分享我们在 2020 年上半年开发项目过程中的心得体会,旨在抛砖引玉,共同学习。
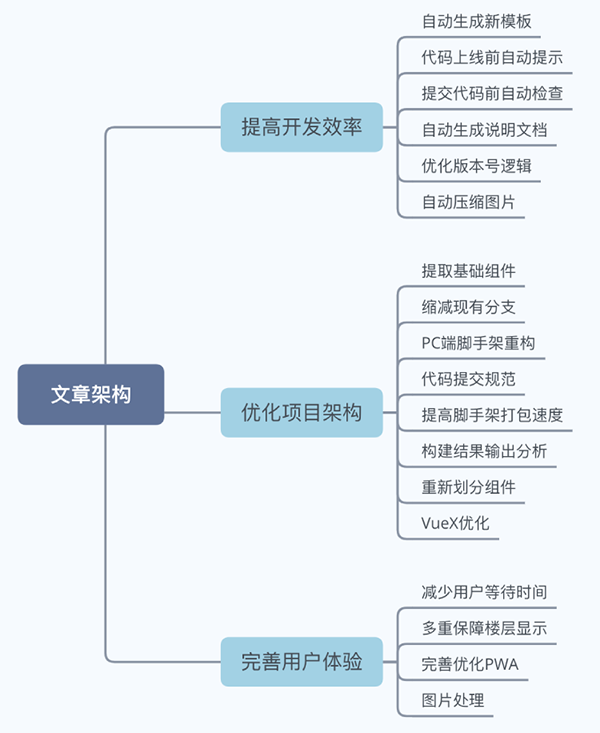
一、提高开发效率
在项目开发过程中,往往不起眼的优化,总能带来意想不到的收获。持续不断的发现开发中遇到的问题,如何改进过程,提高开发效率,也是我们孜孜不倦的追求。
1.1 自动生成新模板
随着需求的迭代,以前的频道页逐渐无法满足当前的需求,尤其是 PLUS 会员自建风控体系页面、频道页改版的需求,都要新增页面,那么新增一个页面需要几个步骤呢?
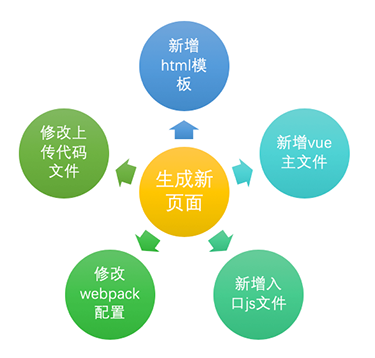
如上图所示,新增一个页面,需要五个步骤:
1、首先要新增一个 Html 页面,用于挂载加载静态资源和骨架屏等内容;
2、新增入口 JS 文件,是新页面的入口文件,即 Webpack 打包的入口文件;
3、新增 Vue 主文件,用于开发新页面的逻辑;
4、修改 Webpack 配置文件,增加 entry 入口,以及增加对应的 Html 插件配置,例如:
new HtmlWebpackPlugin({
template: './src/template/new-expired.html',
filename: path.resolve(__dirname, 'build/new-expired.html'),
inject: false
}),
5、修改上传代码组件,添加新增加的入口 JS;
因此,每次新增页面,都要修改上面的五个配置,步骤繁琐不说,偶尔遗漏一项,导致页面发生错误也不是没有发生过。那么如何简化新增页面的步骤呢?
于是借鉴团队的 NutUI 组件库 新增组件,自动生成相应配置文件的思路,我们引入 inquirer 库,一个用户与命令行交互的工具。执行一个命令,即可自动生成修改以上五个配置文件岂不美哉。
首先引入用户与命令行交互工具,用来输入新页面的名称:
// 关键代码
inquirer.prompt([
{
type: 'input',
name: 'pageName',
message: '新建页面英文名称:',
validate(value) {
const pass = value && value.length <= 20;
if (pass) {
return true;
}
return '不能为空,且不能超过20个字符';
},
}
])
.then(function (answers) {
createDir(answers);
});
执行该文件,则在命令行展示如下所示:

待我们输入新文件的英文名称,以及中文标题之后,就可以继续往下进行了,比如向指定文件夹中生成 Html 新文件:
function createHtml(value) {
const htmlCode = templateHtml.replace(/\{template\}/g, value.pageName).replace(/{title}/g, value.pageTitle);
const createHtml = path.resolve(__dirname, `../createTemplate/${value.pageName}.html`);
fs.writeFileSync(createHtml, htmlCode);
}
此外,还需自动修改 json 格式的配置文件,
function createJson(value) {
entrys[value.pageName] = `./src/entry/${value.pageName}.js`;
const createJson = path.resolve(__dirname, './entrys.json');
fs.writeFileSync(createJson, JSON.stringify(entrys));
}
根据自动生成的 json 文件,在后续启动本地服务或者打包编译代码时,Webpack 就可以生成对应的 entry 入口和 HtmlWebpackPlugin 插件等配置项。
const entryConfigs = require('./templates/entrys.json');
Reflect.ownKeys(entryConfigs).forEach( key => { //循环遍历对象
webpackConfig.plugins = (webpackConfig.plugins || []).concat([
new HtmlWebpackPlugin({
template: `./src/template/${key}.html`,
filename: path.resolve(__dirname, `build/${key}.html`),
inject: false
})
])
});
这样,原来每次新增页面都要修改或者新建五个文件的历史一去不复返了,一行命令就可以完成新页面的构建,即提高了效率,又减少了人为操作带来遗漏的风险。
1.2 代码上线前自动提示
俗话说大礼不辞小让,细节决定成败。人生如此,程序亦如此。由于需求迭代快且平均每周要并行开发五六个需求,我们采用多个分支并行开发,每次上线更新版本号来避免用户静态资源的缓存,然而设想一下如果辛辛苦苦的开发完需求,满怀期待的上线后,突然发现没有合并之前分支代码!或者没有更改版本号!想必犹如五雷轰顶,脑海中肯定一万头羊驼飞奔而过。。。 不要问我为何会想到这个问题,那肯定是痛苦的回忆!永远不要靠人为的记忆来保证上线前的必要操作,否则你将和我感同身受。那么我们如何来避免这类问题的发生呢?能不能在上线前有人告诉我一下,检查一下必要的操作呢?
梳理一下要实现这个功能需要满足以下要求:
-
开发者提交代码到 master 分支上,才触发该提示功能;
-
拦截提交代码进程,提示开发者注意事项,如果开发者选择了 true,则继续提交代码进程,否则退出提交代码。
于是我把目光转向了 git-hook 技术,
项目要使用 git 进行代码提交时,使用 pre-commit 的 git 钩子,在调用 git commit 命令时自动执行某些脚本检测代码,若检测出错,则阻止 commit 代码,也就无法 push,保证了出错代码只在我们本地,不会把问题提交到远程仓库。
git-hooks 存在在 git 仓库的 .git/hooks 文件夹下,包含了很多的 hooks,这些文件都是在创建 git 仓库的时候自动生成的,打开 hooks 文件夹可以看到:
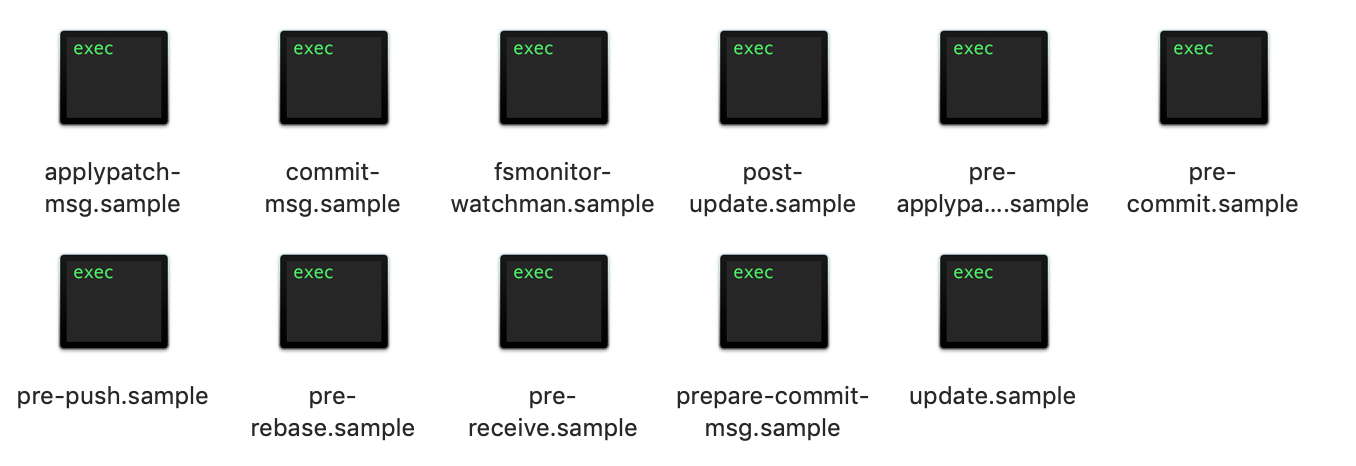
后缀为 .sample 表示默认是不生效的,所以我们要做的就是生成 pre-commit 文件,该文件会在提交代码时执行该文件的代码,因此我们就可以把提示功能的代码放在该文件中开发。
如下所示,再提交代码时,首先判断是否为 master 分支,如果是 master 分支,表示要上线了,于是执行 pre-commit 文件中的代码,如下图所示:
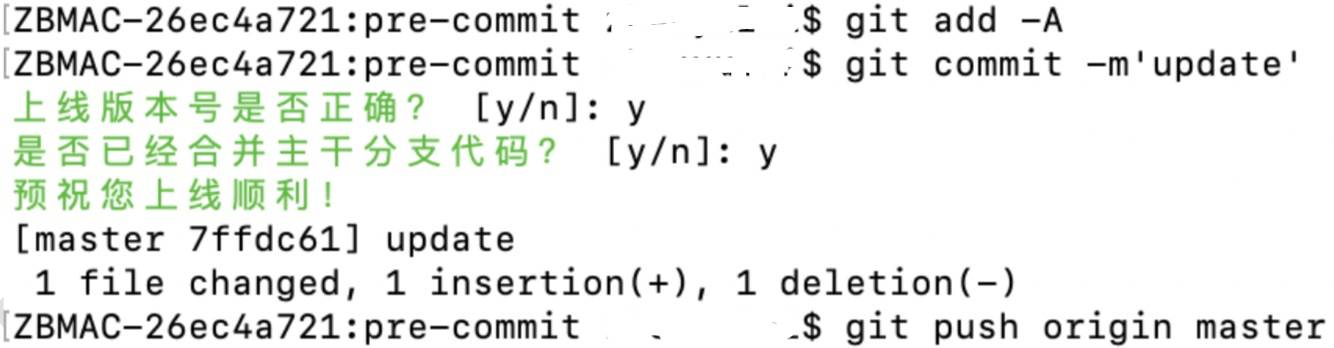
只有所有回答为 y,才会继续提交代码进程。
那么还有个问题,如何让全团队的人都用到该功能呢?难道要让每个成员都在本地添加这个文件吗?我们在运行一个项目时,一般都会运行 npm run dev,也就是本地启动服务,所以我们可以利用这一个必要步骤,把修改 pre-commit 文件的代码放在这一步骤中,这样每个成员在启动本地服务的时候,就会向 hooks 中加入该文件,于是就在团队成员神不知鬼不觉的情况下注入了 pre-commit 功能,待小伙伴上线前发现这个彩蛋吧~
1.3 提交代码前自动检查
虽然 1.2 中的方法只是在上线前进行了提示拦截,在开发过程中是否还有可操作空间呢?下面先来看几种常见场景:
1、新需求在开发的过程中,主干分支可能已经更新过很多次了,所以我们要及时合并主干分支,来保持当前的开发分支是最新的;
2、不同开发者使用一个分支的时候,经常会忘记其他人合并代码就编译上传,导致别人的代码被覆盖;
3、自己合并完主干分支,偶尔会忘记上传;
实现目标
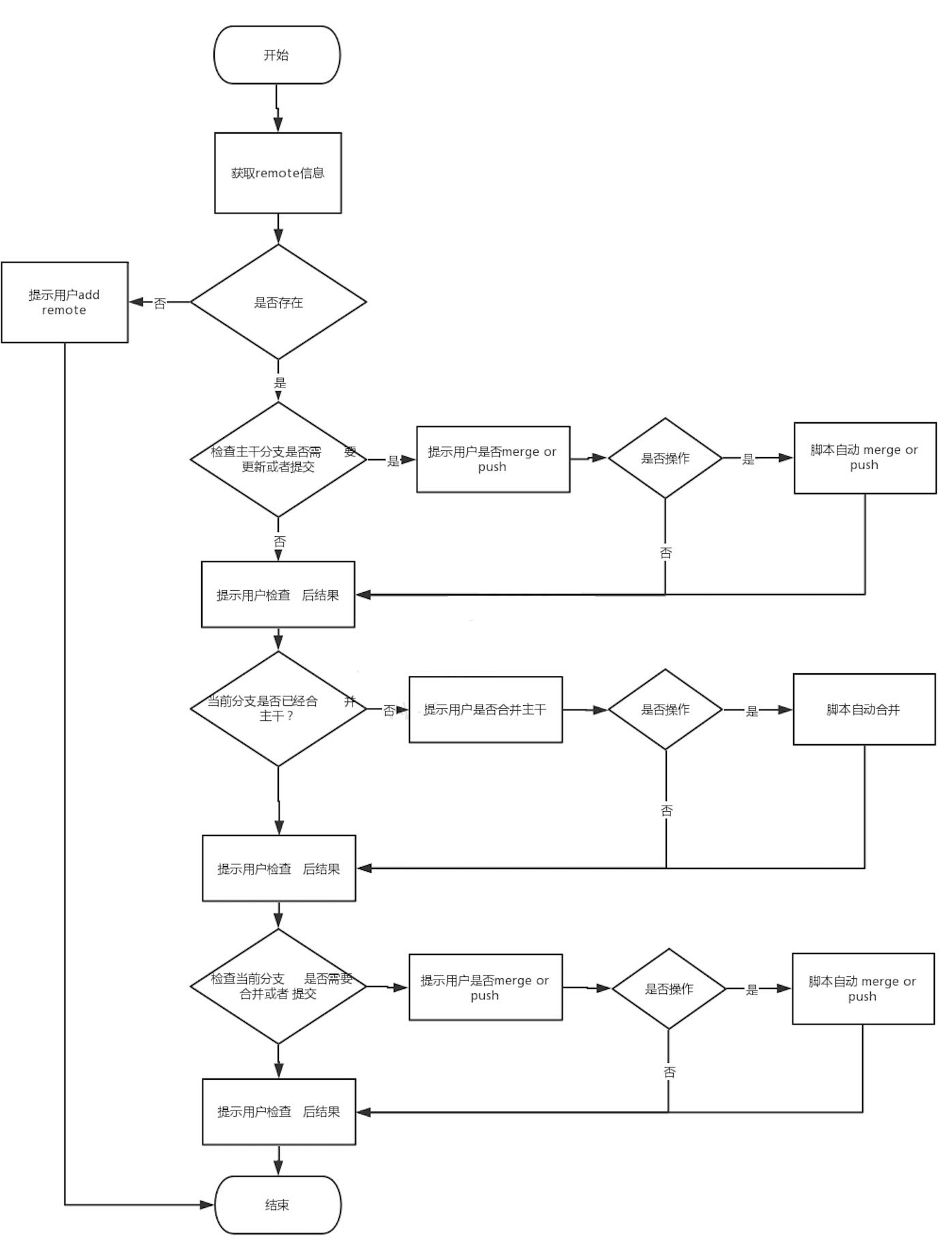
这些问题,我们可以靠脚本去运行,用脚本去逐条检查所有的项目是否完成。下面我们先来看下实现方法。 在更新之前首先要定义我们要实现的目的:自动检查当前分支和本地分支的状态。
1、需要把所有的文件fetch到本地
因为只有本地和线上保持同步才能进行正确的判断,这个操作只会把服务器的下载到本地不会合并。
git fetch
2、检查主干分支是否有未提交或者待更新内容
在 master 分支下,我们可以通过命令去查看当前的状态,下面可能有两种状态,ahead or behind 代表了跟远程分支的一种关系,待更新 or 待提交,下图就是一种待提交的状态
git status

3、判断当前分支与主干分支的状态
如果当前所在分支不是主干分支,需要进行这项判断,如果发现有待合并,则提示用户需要合并代码。可以通过以下命令去查看当前分支已经合并过的分支来判断是否合并主干分支。
git branch --merged
4、判断当前分支是否有未提交或者待更新内容
如果当前分支不为主干分支的话则进行这项内容,判断逻辑同2。
流程图如下:
具体实现
用执行脚本的方法来代替人工操作,前端的脚手架环境为 node,第一步就是在 npm 库选择一个可操作 git 的库,我选择的是 simple-git。
1、第一步先判断是否有 remote,如果没有 remote 地址那么就无法 fetch,后面的比较也就无正确性可言。
const git = require('simple-git');
git().getRemotes(true, (err, res) => {
//do something
})
2、判断主干是否需要提交, 通过 isBehind 和 isAhead 的状态去判断主干分支的状态:
const mainBranch = master;
const behindReg = /behind(?= \d+\])/gi;
const aheadReg = /ahead(?= \d+\])/gi;
git().branch(['-vv'], (err, res) => {
const mainBranchInfo = res.branches[mainBranch]
const isBehind = mainBranchInfo.label.search(behindReg);
const isAhead = mainBranchInfo.label.search(aheadReg);
});
3、判断当前分支是否合并主干,通过如下方法去检查是否合并,如果没有合并可以提示用户:
const mainBranch = master;
git().branch(['--merged'], (err, res) => {
const isMerged = res.all.includes(mainBranch);
});
4、判断当前分支的是否需要提交,方法如下,通过判断 变量 Behind 是否需要更新:
getCurrentBehind() {
return new Promise((resolve, reject) => {
git().status((err, res) => {
if (err) reject();
else resolve(res.behind);
});
});
}
const Behind = await gitFn.getCurrentBehind();
最后形成如下提示:
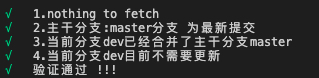
1.4 自动生成说明文档
PLUS 会员 M 端项目在不断壮大,程序的维护和调试难度也在上升,有时候我们封装的工具函数或者业务逻辑由于缺少注释,其他小伙伴在使用或者二次开发的时候理解起来较为麻烦。为了增加程序的可读性和程序的健壮性,我们在项目中加入了 API 文档,方便团队成员能够快速查询和入手项目开发,另外为了节约 API 文档的维护成本,我们使用了 jsDoc 自动化生成文档。
JsDoc可以根据规范化的注释、自动生成接口文档,举个例子:
/**
* @description 判断是否在小程序环境中
* @returns {Boolean} result 结果
*/
export function isMiniprogram() {
const plusFrom = getCookie('plusFrom');
return !!~['xcx', 'xcxplus'].indexOf(plusFrom);
}
这样一个函数就会被jsDoc收集起来,放到开发文档里了,然后我们可以自己建立一个 npm script 工作流,方便在命令行中启动:
"docs": "rimraf docs && jsdoc -c ./jsdoc-conf.js && live-server docs"
jsdoc-conf.js是jsdoc的配置文件,包括了一些文档的配置项,然后我们就可以开始进行文档的自动构建了!
执行 npm run docs,或者可以把该命令合并到 npm run dev 中执行。
接下来浏览器会在本地自动打开文档页面:
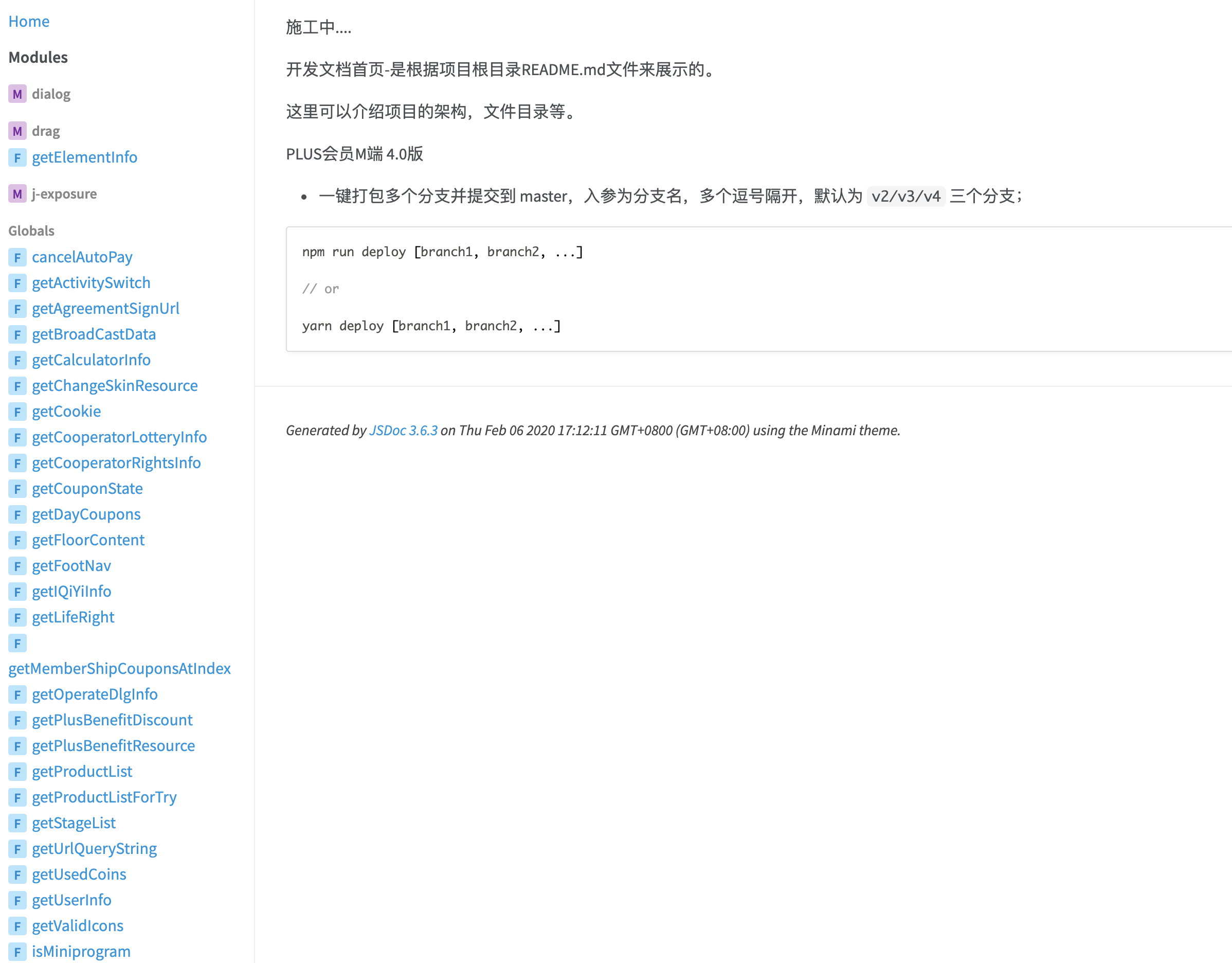
页面左边是 api 目录,Globals 下的 api 就是我们在 JS 文件里边写的工具函数了,而 Modules下的就是 Vue 组件模块,下面我们来看如何给 Vue 组件模块添加注释:
/**
* @module drag
* @description 拖拽组件,用于页面中需要拖拽的元素
* @vue-prop {Boolean} [isSide=true] - 拖拽元素是否需要吸边
* @vue-prop {String} [direction='h'] - 拖拽元素的拖拽方向
* @vue-prop {Number | String} [zIndex=11] - 拖拽元素的堆叠顺序
* @vue-prop {Number | String} [opacity=1] - 拖拽元素的不透明级别
* @vue-prop {Object} [boundary={top: 0,left: 0,right: 0,bottom: 0}] - 拖拽元素的拖拽边界
* @vue-data {Object} position 鼠标点击的位置,包含距离x轴和y轴的距离
*/
//业务代码。。。
由于 Vue 组件不能被原生的 jsDoc 支持,这里我们借助了 jsDoc-vue ,所以组件的注释写法也有所不同,具体的规范大家可以查询官方文档。然后我们就可以在 api 文档中看到这个组件相关的注释了。
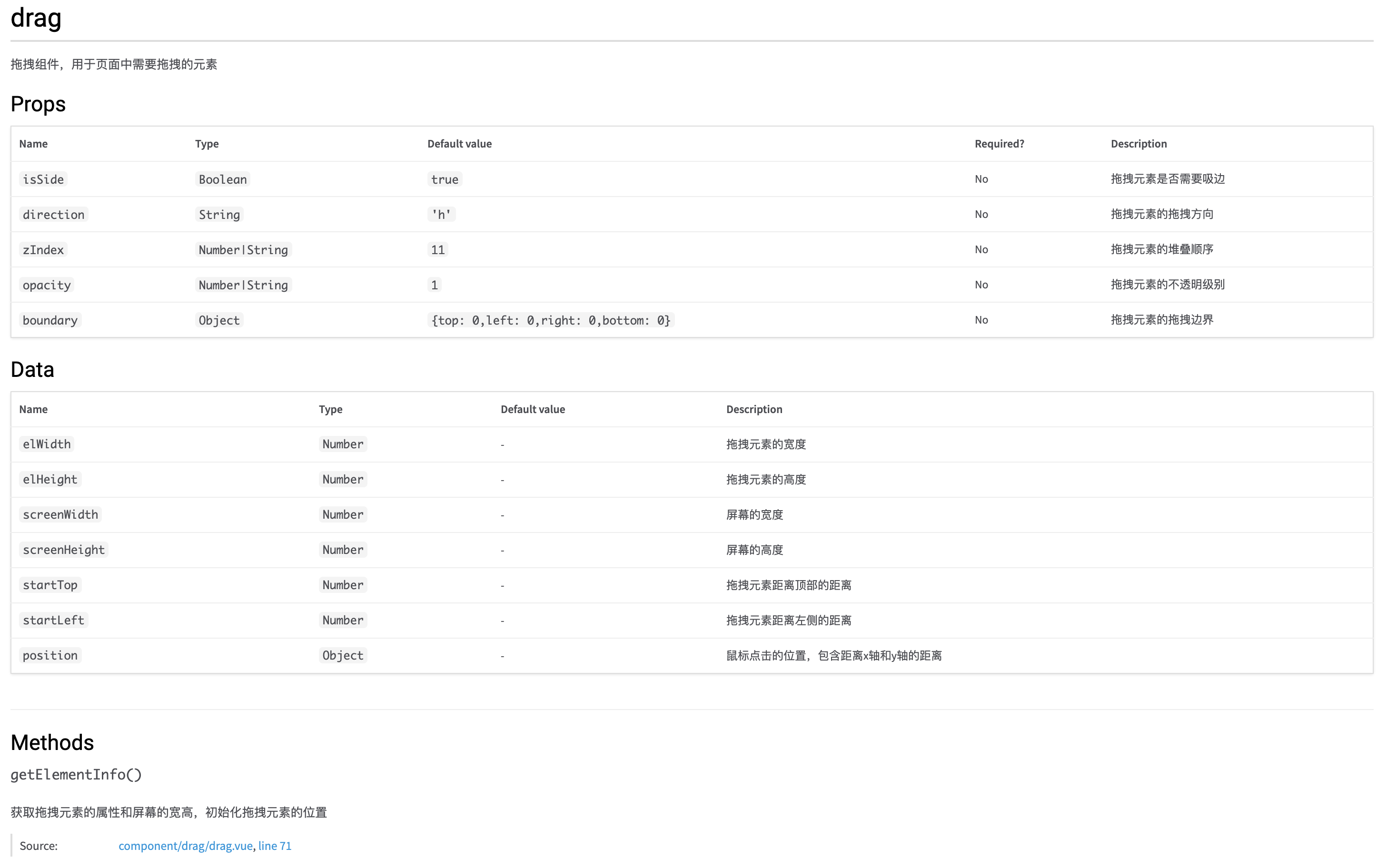
vue组件的注释规范可以查询jsdoc-vue的官方文档。当我们写完注释之后,需要执行一下npm run docs来重新生成文档。
1.5 优化版本号逻辑
为了保证每次上线后,用户都能够获取到最新的代码,而不是用缓存资源,所以要修改每次上线的版本号,比如修改下面链接中的 4.1.2:
https://static.360buyimg.com/exploit/mplus/4.1.2/v4/js/index.js
由于我们接入了公司的头尾系统,所以只需要改动头尾系统中的版本号即可。
什么是头尾系统呢?可以简单的理解为:服务器从这个系统中引入 A 配置文件,前端在 A 文件中输入代码,一键推送到指定的服务器上,来更新该服务器上引入的前端资源。
但是我们发现,每次上线的时候,都要在头尾系统中推送几十台服务器,往往总有服务器推送失败,或者上线后在预发中发现有新的问题,要紧急回滚版本号,于是又要重新推送头尾文件,往往要花费很长时间。
于是我们在想是不是有更好的方法来解决?抑或是缓解此类问题呢。这时版本号比较逻辑重新进入我们眼帘。之所以用“重新”一词,是因为这个逻辑之前就有,不过当时没有解决动态生成静态资源脚本,导致无法保证执行顺序,从而页面白屏的问题(该问题详见文章:《2019年京东PLUS会员前端开发之路》),所以当时就把该功能去掉了。现在是时候重新审视这个功能了:
1、服务器端的 Html 模板中维护一个版本号 V1;
2、前端在头尾系统中维护一个版本号 V2;
前端在 Html 中开发好版本号比较的逻辑,使用两个版本号中较大值来动态生成对应的静态资源。
/*
V1 就是放在 Html 中的版本号
V2 就是前端在头尾文件中放置的版本号
最终使用的是较大的版本号
*/
if (typeof V2 != 'undefined'
&& Number(V2.replace(/\./g, '')) > Number(V1.replace(/\./g, ''))) {
V1 = V2;
}
对应的有两种情况:
1、只需要前端上线的需求,前端在头尾系统中推送更新的版本号,这个和之前一样;
2、如果是前、后端都要上线的项目,则后端在 Html 中修改版本号 V1,根据 Html 中版本号比较逻辑,会使用两个版本号中较大的那个,则生成的静态资源使用了后端在 Html 中设置的版本号,于是前端省去了推动头尾文件的步骤,只需要后端上线即可;
不过按下葫芦瓢又起,虽然缓解了前端推送头尾文件的情况,但是从此要求保证版本号有大小顺序关系。于是我们按照需求的上线顺序,规定好每个需求的版本号,运行了一段时间,紧急需求过来了、线上 bug 紧急需求过来了,都要在原来已经排序好的版本号之间插入版本号,类似于一个有序数组,如果向数组的前面插入元素,则后续元素都要跟着变化,经过商量之后我们改为如下策略:
1、只有三个数字表示版本号,则使用前两位作为主版本号,比如:4.1.0、4.2.0...4.99.0;
2、使用第三个版本号数字表示紧急需求的版本号,比如目前版本号是 4.2.0,如果插入紧急需求则为 4.2.1;
这样扩展了主版本号的个数:前两位数字可以扩展到很大;而且插入的紧急需求版本号不会影响之前已经排序好的版本号,还能够减少上线步骤,可谓一箭三雕!
1.6 自动图片压缩
图片压缩一直是前端优化中很重要的一部分,也可以说是开发流程中必不可少的一个环节。之前 PLUS 项目的图片压缩,一直处于自发的、手动的处理状态,这就非常考验大家的细心程度和自觉性了。
为了规范这一流程,我们引入了 Gaea 脚手架中自动压缩图片及转换 webp 的功能。话不多说,上代码
const imagemin = require('imagemin');
const imageminWebp = require('imagemin-webp');
const path = require('path');
const fs = require('fs');
const tinify = require("tinify");
const config = require("./package.json");
tinify.key = config.tinypngkey;
const filePath = './src/asset/img';
const files = fs.readdirSync(filePath);
const reg = /\.(jpg|png)$/;
async function compress(){
for(let file of files){
let filePathAll = path.join(filePath,file);
if(reg.test(file)){
await new Promise((resolve,reject)=>{
fs.readFile(filePathAll,(err,sourceData)=>{
tinify.fromBuffer(sourceData).toBuffer((err,resultData)=>{
//将压缩后的文件保存覆盖
fs.writeFile(filePathAll,resultData,err=>{
resolve();
})
})
})
})
}
}
imagemin(['./src/asset/img/*.{jpg,png}'],'src/asset/img/webp',{
use:[
imageminWebp()
]
}).then(()=>{
console.log(chalk.green(`webp转换已完成~`));
})
}
compress();
在 css 中使用方式:
@mixin webpbg($url, $name) {
background-image: url($url + $name);
background-repeat: no-repeat;
@at-root .webp & {
background-image: url($url + "webp/" + (
str-slice($name, 0, str-index($name, ".") - 1)
) + ".webp");
}
}
str-slice(string, start, end) 从 string 中截取子字符串,通过 start 和 end 设置始末位置,未指定结束索引值则默认截取到字符串末尾。 str-index(string, substring) 返回 substring 子字符串第一次在 string 中出现的位置。如果没有匹配到子字符串,则返回 null。
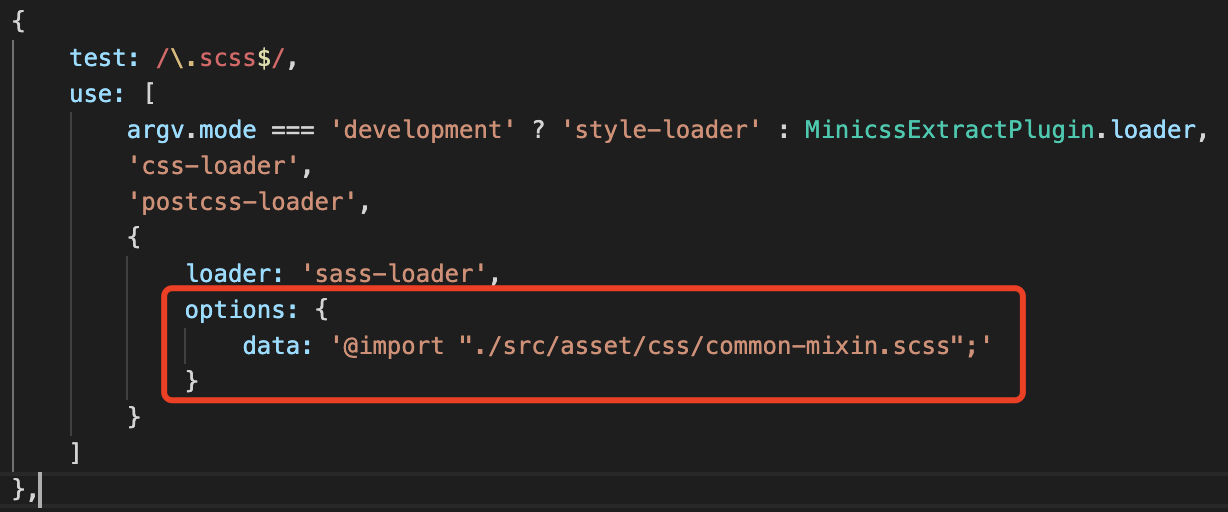
由于这个 webpbg 方法定义在公共的 common-mixin.scss 里,而调用是分布在各个组件中的,因此组件中的调用会报错找不到这个 webpbg 函数。如果要在全局使用这个 webpbg 方法,就需要在 webpack.config.js 中全局导入,修改方式如下
@include webpbg("../../asset/img/index-formal/", "formal-title.png");
结果,出师不利,竟然报错了!

我们一般是把 Mixin 放在当前 Sass 文件中,如果要在全局使用,需要在 webpack.config.js 中全局导入。
好了,图片压缩,自动转 webp,样式支持 webp,一切顺利的进行着。
然而,随着我们图片的增多,压缩次数的增加,问题又来了: 由于压缩图片用到的是 tinypng 工具,我们在使用时需要用邮箱注册得到个 key。对于免费用户,同一个 key 在同一个月中只能压缩 500 张图片。

因此,我们需要破除这个限制。除了多申请几个 key,能不能从优化策略上进行改善呢?
实际上,一般图片切好后,不会经常去改动,尤其是已上线的部分,改动的可能性更小。因此,我们可以将图片的全量压缩,改为增量压缩,只压缩修改过的或者是新增的。基于这种策略,压缩图片的数量不会很大,限制就这样破除了~ 下面来看看具体实现步骤吧:
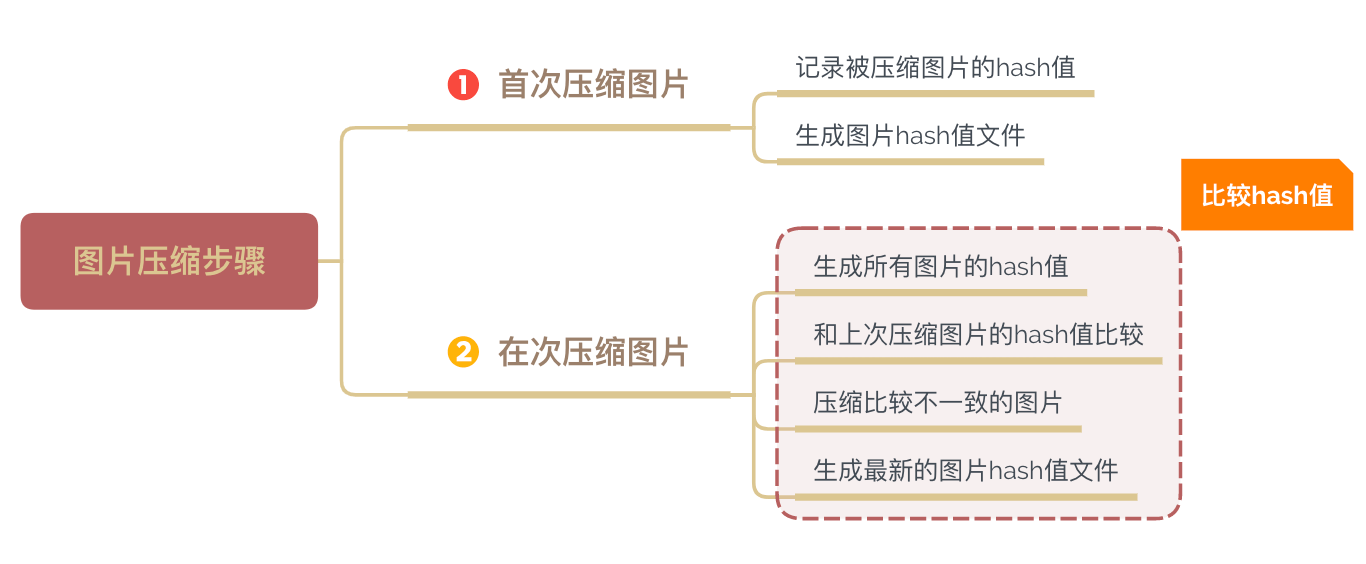
下面是生成 hash 值的代码片段:
let rs = fs.createReadStream(filedir); //打开一个可读的文件流并且返回一个fs.ReadStream对象
let hash = crypto.createHash("md5"); //创建并返回一个 Hash 对象,该对象可用于生成哈希摘要
let hex;
return await new Promise((resolve, reject) => {
//在内部不断触发rs.emit('data',数据);
rs.on("data", hash.update.bind(hash)); // hash.update使用给定的 data 更新哈希的内容
//end事件表示这个流已经到末尾了 ,没有数据可以读取了
rs.on("end", function () {
hex = hash.digest("hex"); //计算传入要被哈希的所有数据的摘要,返回字符串
result[filedir.replace(/\/|\\/g, "/")] = hex; // 统一mac及windows下的文件路径,将其作为key值,生成的hash值为value,存入result中
resolve();
});
//error事件表示出错了
rs.on("error", function (msg) {
console.log("error", filedir);
reject();
});
});
二、优化项目架构
为什么要持续进行项目架构的优化?项目就像一座建好的大厦,如果时不时的要砸掉承重墙进行装修,不及时维护的话,最终会千疮百孔,岌岌可危。类似地,京东 PLUS 会员项目作为一个长期维护的项目,随着需求的快速迭代,紧急需求的插入实现,最初没有考虑到的问题,或者阻碍项目开发进度的问题慢慢浮出水面,为了项目能够长久运行,避免代码更加臃肿,我们主要做了以下工作:
2.1 提取基础组件
一千个人眼中有一千个哈姆雷特。如何划分组件,想必每位开发者心中的认识都所有不同。那么 PLUS 会员项目的组件是如何划分的呢?
比如一个下面这个弹窗:

我们首先使用了 NutUI 组件库中的基础组件——Dialog弹窗组件,然后以该组件为基础,开发了业务计算器弹窗组件,为了更好的提高组件复用性,以及减少业务逻辑改动对组件的影响,应该是由以下形式构成:
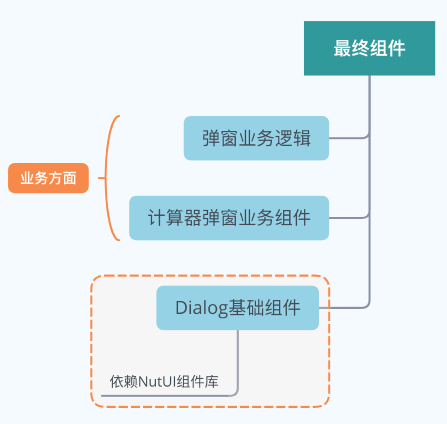
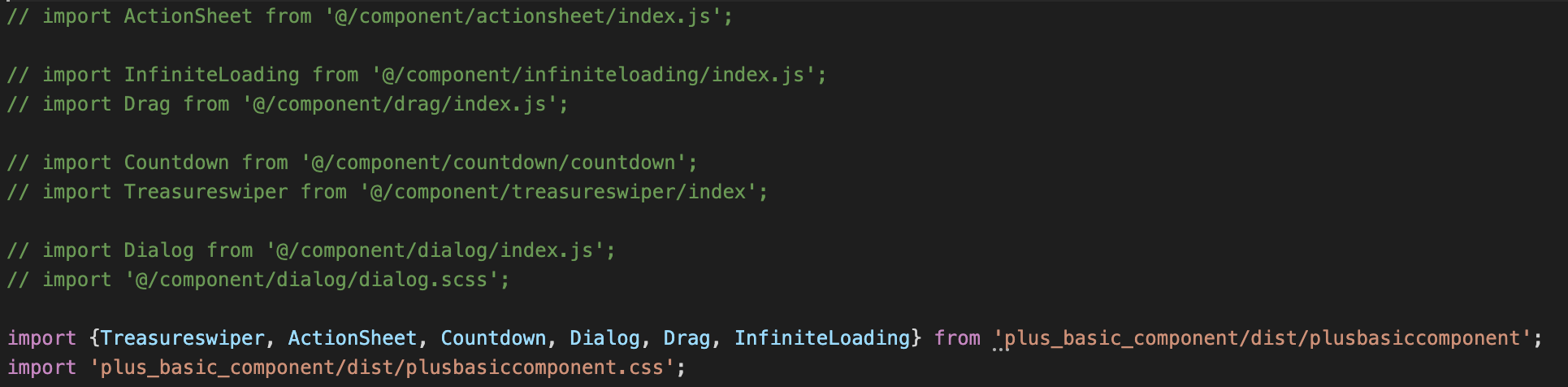
当前我们项目中的组件也在朝着这个方向努力,因为发现 PLUS 项目中引入了一些 NutUI 基础组件,之后又做一些开发来匹配业务需求。在经历了很长时间的稳定运行后,这些组件的改动很少,因此为了给项目瘦身,我们将这些基础组件抽取出来发布到 npm 中,最终将其打包到 node_modules 文件夹中,这样项目中就会大量减少这些基础组件的代码,并且不需要每次都打包编译这些组件代码。
值得一提的是,在本地开发时所有组件都完美运行,但是打包部署后却失败了。经过排查原来是 npm 包只是存放的组件源码,并未对其编译,所以在项目中直接使用就会报错,问题暴露出来了。那么要为了这几个组件,去单独搭个脚手架处理吗? 我们机智的小伙伴想到了一个借鸡生蛋的方法——使用团队的 NutUI 组件库脚手架作为载体,在组件库中中创建 PLUS 的基础组件,然后把这些需要打包的组件都通过组件库编译后导出。这样把编译后的代码部署到 npm上,就能够在项目中直接安装依赖包使用了,效果如下,可以看到,打包后项目中的引入代码也精简不少:
2.2 缩减现有分支
PLUS 项目平均每周都需要并行五、六个需求进行开发,如何才能保证并行开发的需求不会互相干扰,我们采用的是多分支的方法,每位研发从主干分支 v2、v3、v4的基础上新建分支,分支的名字使用当时需求的拼音缩写,比如正式改版需求就是:zsgb;开发完毕后,每次上线时再合并到 master 分支上准备上线,如下所示:
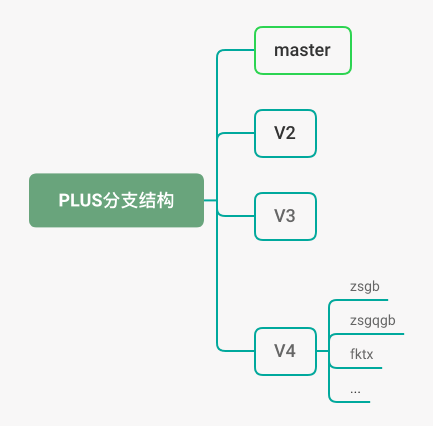
不知大家有没有发现什么端倪?这样命名分支会不会有所隐患? 在运行了半年之后,我们发现代码库中的分支越来越多,很多新建的分支在开发完之后,就不在使用了,但是每次都要人为的去删除,而需要人为自发的去操作的都是不可靠的。经过思索之后,我们决定使用每个开发成员的姓名缩写作为分支名,比如名字叫“张大胖”的同学,新建的分支就是“zdp”,如果多人开发同一个需求,则在某个人的分支上开发即可,这样的好处如下:
-
每个主分支下的子分支个数是固定的,每个研发有一个对应的子分支进行开发;
-
避免了人为的删除代码库中冗余分支步骤,且减少误删分支的情况;
-
避免了子分支的不断增多的问题;
经过上述操作,原来代码库中几十个子分支缩减到几个分支,大大减少了代码量,下载代码速度也快了起来。
2.3 PC端脚手架优化
由于历史原因,PC 端的 PLUS 会员项目用的是 React 技术栈进行的开发,且随着科技的进步,移动端所占比例越来越大,相应的 PC 端所占比例逐年缩小,很多功能也是采取的引流到 M 端,这就导致一个问题,我们对 PC 端的改动也随之变少,但是最初的 PC 端脚手架已经比较老旧,在编译的过程中会时常出现问题,比如:
1、打包代码速度巨慢,打包期间可以喝茶、嗑瓜子、打豆豆;
2、生成 hash 值命名的文件,每次联调和版本回滚都要挨个替换每个hash值,不利于心情舒畅,容易让人暴躁;
3、不支持热更新,导致每次更改都要人为的去刷新页面,副作用是可以矫正处女座强迫症;
4、不支持按需打包文件,每次打包都会把所有的文件都打包,而上线只是上其中的几个文件;
忍无可忍,则无需再忍,基于此,我们主要做了以下优化,升级了 Webpack 从 2 到 4 版本,所有的配置文件重新开发,并做了以下的优化:
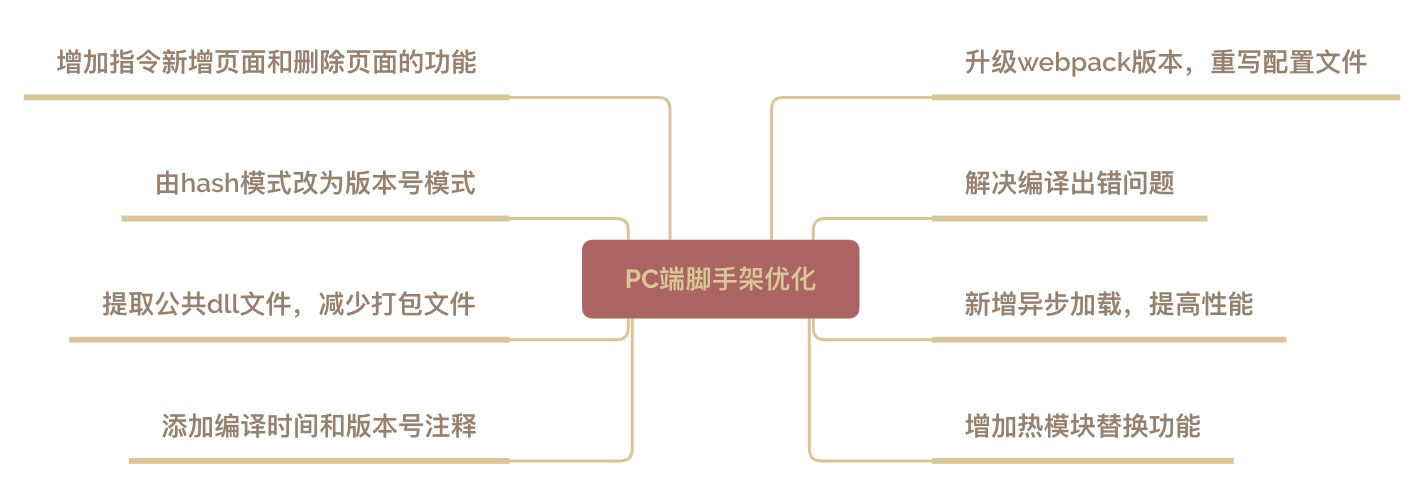
打包效率较低,开发联调比较麻烦,所以脚手架有待挑战优化。并且随着技术的发展,很多新的技术可以用于我们项目中,来提升开发效率。由于此处代码量巨大,所以只是写明了方向,有疑问的小伙伴可以在评论区留言讨论~
2.4 代码提交规范
代码提交规范化的目的是为了更好的追溯代码、筛选和快速的定位提交代码所涉及的范围和实现功能。对于 PLUS 这样一个不断开发迭代的项目,增加代码提交规范化是很有必要的。正所谓,无规矩不成方圆。因此我们在项目中引入了 vue-cli-plugin-commitlint 来约束和规范代码提交。它既可以增强团队成员对 commit 规范的概念,同时也可以统一我们代码的提交风格,更重要的是,它可以自动生成自动 ChangeLog,方便我们查找提交版本,对后期遇到问题,快速定位提供便利。
vue-cli-plugin-commitlint是开箱即用的 git commit 规范,它结合了 commitizen、commitlint、conventional-changelog-cli 和 husky。
下面我们看一下如何在项目中使用。
安装依赖
npm i vue-cli-plugin-commitlint commitizen commitlint conventional-changelog-cli husky -D
在 package.json 中添加
{
...
"scripts": {
"log": "conventional-changelog --config ./node_modules/vue-cli-plugin-commitlint/lib/log -i CHANGELOG.md -s -r 0",
"cz": "npm run log && git add . && git status && git cz"
},
"husky": {
"hooks": {
"commit-msg": "commitlint -E HUSKY_GIT_PARAMS"
}
},
"config": {
"commitizen": {
"path": "./node_modules/vue-cli-plugin-commitlint/lib/cz"
}
}
}
增加 commitlint.config.js 文件
module.exports = {
extends: ['./node_modules/vue-cli-plugin-commitlint/lib/lint']
};
然后执行 npm run cz, 这时,就会提示你选择,然后根据提示依次填写,生成符合格式的 Commit message。
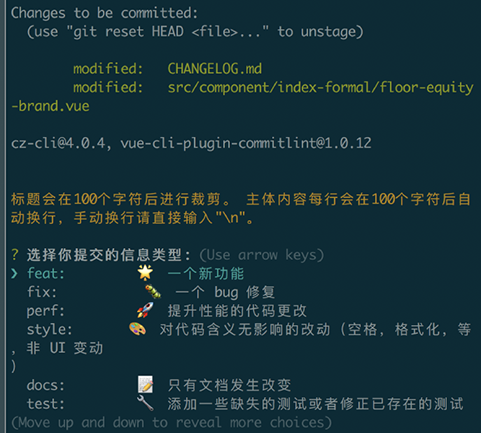
提交完成之后,会在项目根目录生成 CHANGELOG.md 日志文件,点击文件中的 commitId, 就可跳转查看对应提交内容了。
2.5 提高脚手架打包速度
随着项目的不断迭代,文件数量不断增多,项目变得庞大,从而导致 Webpack 构建变得越来越慢。每次构建都需要一定时间,提升构建速度,变得格外有必要。
众所周知,Webpack 在 Node.js 上运行都是采用单线程模型的,处理任务也是依次去执行,不能并发处理多个任务,需要排队,那是否有什么方法可以让 Webpack 同时并行处理多个任务呢?
为了解决上述疑问,我们接入了 HappyPack,它能让 Webpack 做到这点,可以把任务分解给多个子进程去并发的执行,子进程处理完后再把结果发送给主进程。HappyPack 的核心原理就是把这部分任务分解到多个进程去并行处理,从而减少了总的构建时间。
下面,我们来看一下如何在项目中接入。
安装依赖
npm install happypack -D
对 webpack.config.js 进行配置
在整个 Webpack 构建流程中,最耗时的就是 Loader 对文件的转换操作,因为要转换的文件数据特别多,而且转换操作需要依次排队处理。
配置 Loader,上代码。
module.exports = (env, argv) => {
const webpackConfig = {
//...
module: {
rules: [{
test: /\.js$/,
loader: 'happypack/loader?id=happyBabel',
// 排除 node_modules 目录下的文件
exclude: [
path.resolve(__dirname, 'node_modules'),
path.resolve(__dirname, 'jssdk.min.js')
]
},
//...
]
},
//...
}
}
我们把对 .js 的文件处理交给 happypack/loader,然后通过 id 标识确定 happypack/loader 选择哪个 HappyPack 实例处理文件。
增加对应的 HappyPack 实例。
const HappyPack = require('happypack');
const os = require('os');
const happyThreadPool = HappyPack.ThreadPool({ size: os.cpus().length });
//...
module.exports = (env, argv) => {
const webpackConfig = {
//...
plugins: [
new HappyPack({
// 唯一的id标识
id: 'happyBabel',
// 如何处理 .js 文件,用法和 Loader 的配置一样
loaders: [{
loader: 'babel-loader?cacheDirectory=true',
}],
// 共享进程池
threadPool: happyThreadPool,
// 允许 HappyPack 输出日志,默认为 true,可不写
verbose: true
}),
],
//...
}
}
我们先创建共享进程池,借助 Node.js os,让进程池中包含 os.cpus().length 个子进程,然后增加对应的 HappyPack 实例,传入之前定义好的 id 标识, 告诉 happypack/loader 去处理 .js 文件,loaders 属性和上面 Loader 配置中一样, threadPool 属性 传入 预先定义好的 happyThreadPool 参数, 告诉 HappyPack 实例都使用同一个共享进程池中的子进程去处理任务。
然后执行打包编译构建,构建完成之后我们可以看到 HappyPack 的构建日志。

我们可以看到,HappyPack 启动了8个子进程去并行处理任务。激动地鼓鼓掌!
最后,再让我们看一下,加载速度的对比图,省了1488ms,提升了将近20%。

2.6 构建结果输出分析
可视化的资源分析工具有很多,我们选用了 webpack-bundle-analyze ,它以图形的方式展示,相比其他工具更简单、直观,输出分析结果,可以让我们快速分析到问题所在。下面我们看一下如何在项目中接入。
安装依赖
npm install webpack-bundle-analyzer -D
对webpack.config.js进行配置
const BundleAnalyzerPlugin = require('webpack-bundle-analyzer').BundleAnalyzerPlugin;
...
module.exports = (env, argv) => {
const webpackConfig = {
...
plugins: [
...
new BundleAnalyzerPlugin()
],
...
}
}
配置方法也很简单,一般默认的选项就足够使用, 无需修改。
接着,我们在package.json 的 scripts 中增加
"analyz": "NODE_ENV=production npm_config_report=true npm run build"
然后执行 npm run analyz 后,浏览器会自动打开 http://127.0.0.1:8888/ ,显示分析视图界面。

如果不想每次都自动弹出,可以把参数 openAnalyzer 的值改为 false,然后按需手动打开。
通过视图,可以看到项目各模块的大小,看到文件打包压缩后真正的内容,然后分析出拿些文件占用比较大,有了分析思路,就有了优化的目标。
通过最后的分析图先发现公用的 toast.js 文件占比是比较大的,可以会对 toast.js 文件进行优化。另外占比比较大的第三方库 Swiper.js 和 lazyload.js,也可以考虑进行 DLL 抽离,进一步的提升空间。
2.7 重新划分组件
在 PLUS 项目中我们有一个 component 文件夹,这里边放的是一些公用的组件,或者一些页面的子组件。由于历史遗留问题,该文件夹经过项目的迭代和页面的增加,这里有许多冗余的组件,整个文件夹的目录显得很臃肿。所以关于重新划分组件势在必行,下面让我们来看看如何对其划分。
首先让我来看看它里边都有什么?
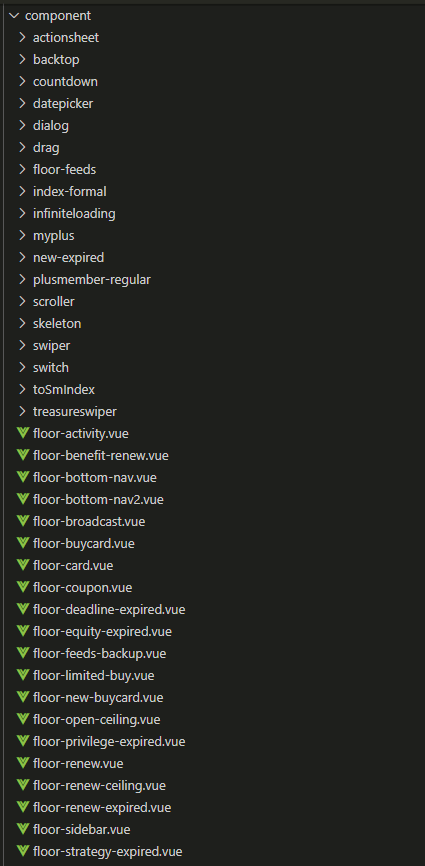
抱歉一屏截不下!
根据上图我们大致将 component 文件夹中的内容归了下类。
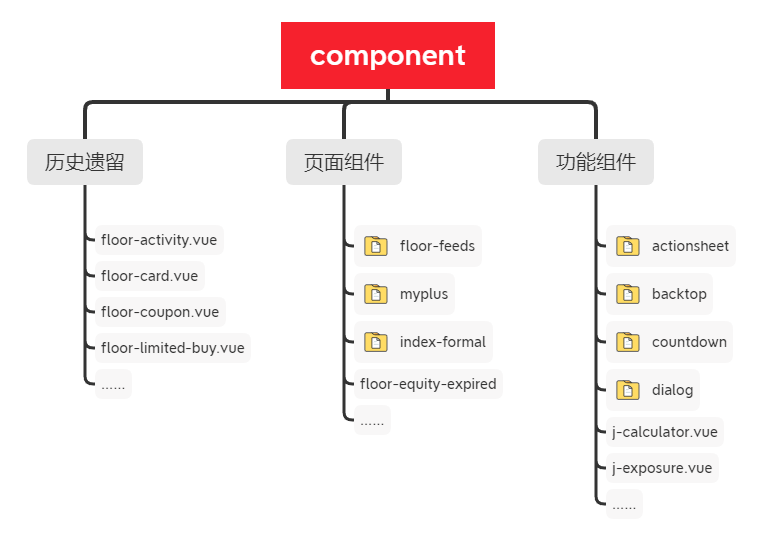
1、历史遗留类:这类文件可以追溯到初始创建的元老级文件,当时目录规划还是单页面形式的,这类文件大多是针对首页的子组件文件,也有一些根据用户状态做的页面子组件文件。
2、页面组件类:随着项目迭代,项目里新增了一些新的页面,而这些页面中复杂的子组件也散落在了 component 文件夹中。
3、功能类组件:功能类的组件如弹窗组件、返回顶部组件、计算器组件等公共组件也放到这个文件夹下边管理。
要如何划分呢?
首先,对于历史遗留类的页面文件,在改版时有意识的将其归类到其对应的页面文件夹中,方便维护。对于零散的页面子组件,也统一归类到其对应的页面文件夹中。
而对于有些公共的页面组件,我们创建一个公共的业务组件文件夹 plus-components将其统一放到里边管理。
像上边提到的功能类的组件如 dialog 、 countdown 等我们用npm的形式去引用,不再占用本地文件夹,缩减了 component 目录。优化后如下:
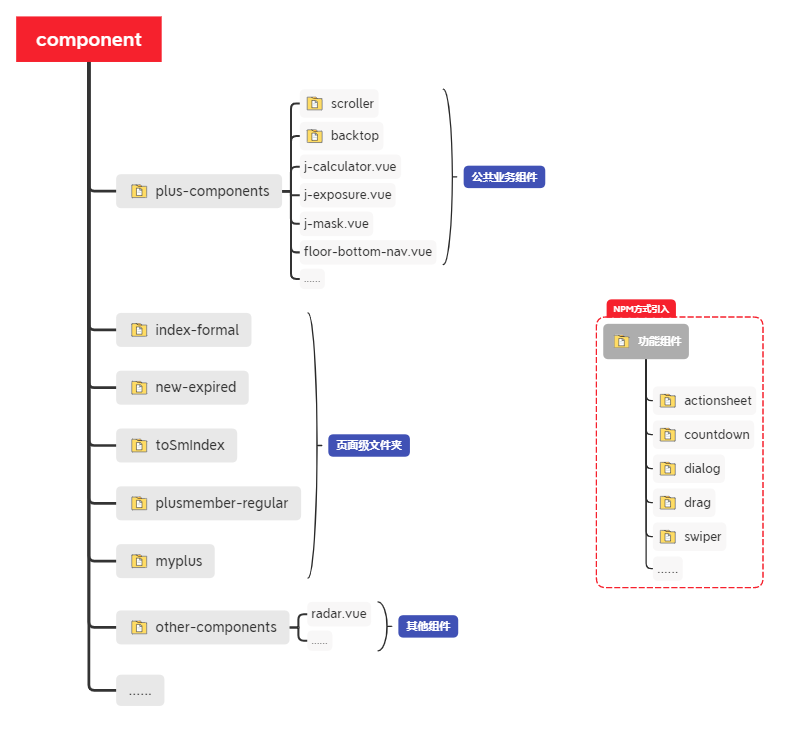
从上图可以看出优化后的 component 文件夹根目录下创建了 plus-components 文件夹存放公用业务组件,同级存放着各个页面的页面文件夹,并且在跟目录下创建了一个 other-components文件来管理其他功能组件。这样一来 component 的目录结构看起来是不是清晰很多,更方便管理。
2.8 Vuex 优化
Vuex 是 Vue 项目中的一种状态管理模式,通俗点说就是集中管理项目中所有组件公享状态的一个机制。Vuex 一般运用在中大型的单页面应用中,如果是简单的单页面项目就不建议使用它,因为 Vuex 对于简单的应用可能是繁琐冗余的。
而对于 PLUS 项目来说,Vuex 的存在是非常必要的,因为 PLUS 项目有太多需要共享的状态了。
我们先来看下项目原有的 Vuex 代码:
import Vue from 'vue';
import Vuex from 'vuex';
Vue.use(Vuex);
export default new Vuex.Store({
state: {...},
getters: {...},
mutations: {...},
actions: {...}
});
原有 Vuex 代码把所有的公共状态写在同一个 index 文件中,state、getters、mutations、actions 全部是统一管理。这样写没有错,大多数中小型项目也都是这么做的。但对于一个大型项目来说,所有页面的共享状态都放在一起,会使整个 Vuex 文件看起来很臃肿,不利于维护。并且有些公共方法经过需求的迭代及改动,会产生很多冗余代码,而一些公共方法针对不同页面的引用会产生耦合使用问题。
所以对于优化 Vuex ,我们尝试引入modules来模块化管理 Vuex。
我们在store的根目录创建一个 modules文件夹,在文件夹中创建 refund文件。
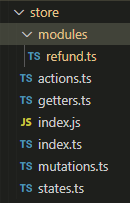
modules 文件夹中可以放任意你想区分管理的模块,这里仅以 refund 为例。在 modules 文件夹中创建好 js 或 ts 模块后,在 index 根文件中引入。
import Vue from 'vue';
import Vuex, { StoreOptions } from 'vuex';
import state from './states';
import mutations from './mutations';
import actions from './actions';
import getters from './getters';
import refundModule from './modules/refund';
Vue.use(Vuex);
export default new Vuex.Store({
state,
mutations,
actions,
getters,
modules:{
refundModule
}
});
上述代码展示了在 store 根目录下的 index.ts 中引入 refund,并将其命名为 refundModule 以便调用。而对于 refund 文件,我们可以向以往写 Vuex 一样将需要的state 、action、 mutation 写在里边。
const state = {
orderId: null,
};
const actions = {
getOrderId: ({ commit }, data) => {
commit("setOrderid", data);
}
};
const mutations = {
setOrderId: (state, data) => {
state.orderId = data;
},
};
export default {
namespaced: true, // module 命名空间,
state,
actions,
mutations
};
如代码所示,该文件中记录了与 refund 页面有关的 state、action、mutations。另外可以看到代码中多了一行 namespaced:true。折行代码意思是开启命名空间,既当模块被注册后,它的所有 getter、action 及 mutation 都会自动根据模块注册的路径调整命名。简单来说,它是用来区分你调用的是哪个模块中的 state、getter、action、mutations的。
在做完以上工作后,要如何调用呢?
如果你是用 JS 写的 Vuex,可以这么引用:
import { mapState, mapActions } from "vuex";
export default {
computed:{
...mapStated('模块名(比如:menuNav/getNavMenus)',{
a:state=>state.a,
b:state=>state.b
})
},
methods:{
...mapActions('模块名(比如:menuNav/getNavMenus)',[
'foo',
'bar'
])
}
在 Vuex 官网有很多类似的例子,感兴趣的同学可以查阅官网关于 modules 的饮用方法。
如果你是用 TS 写的 Vuex,在页面中调用 modules 可以这么写:
import {Component, Prop, Vue, Watch} from 'vue-property-decorator';
import {State, Action, Getter,namespace} from 'vuex-class';
const refundMdl = namespace('refundModule')
@Component
export default class Refund extends Vue {
@refundMdl.State(state => state.orderId) orderId;
@refundMdl.Action('getOrderId') getOrderId;
}
在调用时一定要引入 namespace ,并且通过 namespace 去调用 modules 的公用状态和方法。
经过上边对 Vuex 模块化的改造,我们可以有针对性的对需要被区别开的模块状态进行管理,为 Vuex 文件减重。
三、优化用户体验
在 2020 年伊始,PLUS 会员几个频道首页轮番改版换新颜,产品团队也是呕心沥血的给用户呈现更加友好的界面和功能,作为前端团队,除了完成需求之外,也有自己的小九九,我们作为其中的一份子,也想给用户体验作出应有的优化改善:
3.1 减少用户等待时间
在 PLUS 会员多个频道页大刀阔斧的进行改版之后,每个人展示的楼层以及楼层顺序都有可能是不一样的,所以前端需要依赖后端接口的数据来进行楼层的展示,这就导致了页面需要等待配置接口返回数据后才能展示出来,一旦接口返回缓慢,页面很久才能渲染出来,这就对于用户体验相当不好,但是我们无法控制后端返回接口的速度,那么从前端入手,我们做了以下工作:
1、增加骨架屏,在渲染页面前就显示出页面的整体样式,减少白屏时间;
2、HTML 页面直接放置用户信息的数据,前端不用再请求接口,直接可以渲染个人卡片一些区域;
3、和产品确认首屏会出现的楼层,比如个人卡片楼层、会员尊享权益楼层,这些楼层都做了前端占位区域,在接口返回前就显示出这几个楼层的初步样式,避免待配置接口返回后,导致的楼层顺序的抖动;
4、这几个楼层,按照后端返回的数据格式,前端设置初步数据,来渲染初步的楼层页面,待接口返回数据后,再替换页面中的关键字段;
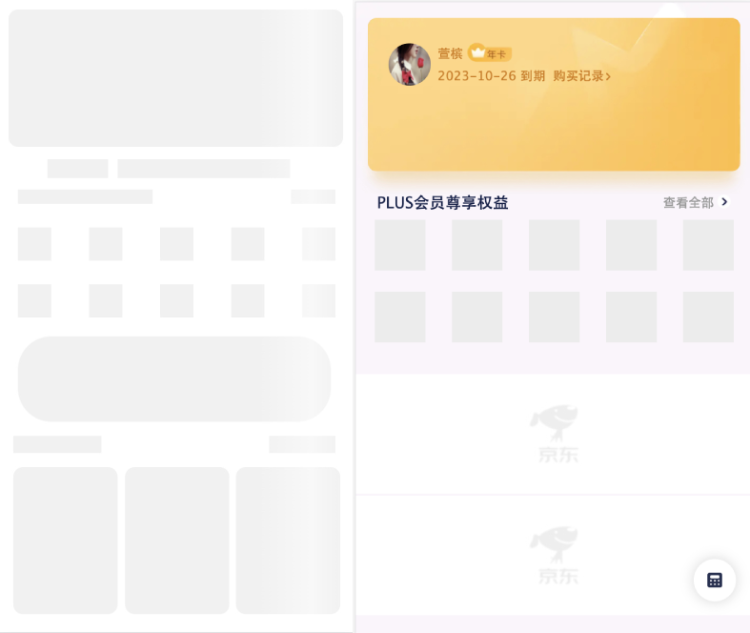
如上图所示,在还没有拿到数据接口的时候,页面已经可以显示出基本架构了,缩减了页面白屏时间,减少了用户等待时长。
3.2 多重保障楼层显示
除了上面介绍到减少用户等待时间,我们还做了多重保护页面的展示。由于整个页面的楼层都是根据接口返回的数据做的配置化显示。一般来说,一旦没有接口返回数据,则页面不再展示,甩给用户一个骨架屏。但是为了追求更好的体验,我们是不是可以采取多重保险来最大化的解决某个接口挂掉的带来的问题呢? 首先,我们要求后端直接把楼层配置信息放在 Html 页面中,前端根据返回的信息渲染首屏的楼层,这样可以直接根据接口信息判断页面要显示哪些楼层,如果这一层失败了,则再去调用对应的楼层配置接口,退一步说,这个接口也挂了,为了避免用户掀桌子的心情,我们会直接调取首屏肯定会请求的几个楼层的接口,这样经过三层接口保障,减少了因为某个接口有问题,导致页面白屏的风险。
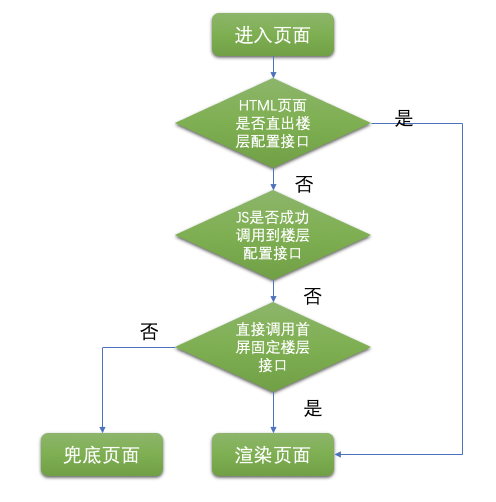
多重保证显示页面楼层,首先获取到首屏直出数据,否则获取楼层数据接口,再不行直接请求首屏楼层内部数据,避免因一层数据有误导致页面白屏,减少用户投诉;
3.3 完善优化 PWA
自从去年在风控用户状态页面增加了 PWA 缓存技术之后,原本要趁热打铁推进全量,却发现同一个域名下所有的请求都会被 serverWork 的拦截,于是戛然而止,从长计议。
那么我们怎么控制 PWA 在指定的用户状态下生效呢?
方案一
我做了很多尝试,在 PLUS 项目中不同用户状态是在不同的 Html 中,我们是不是可以在 Html 中向 serivceWorker 中发送消息,只在某些场景在起作用 在 html 中
navigator.serviceWorker.controller.postMessage()
在 serviceWorker 中
self.addEventListener('message', function(e) {
})
但是这个方案是行不通的,因为 serviceWorker 一旦注册,下次 PWA 启动是在 Html 读取成功之前,所以这个方案存在某些问题
方案二
PWA 可以设置指定的作用域
navigator.serviceWorker.register('service-worker.js', {scope: './xxx'})
但是针对我们的不同状态的域名全部为 plus.m.jd.com/index 所以这种方案也不太适合我们。
方案三
在 service-worker 的 fetch 做拦截,通过判断某些标志,去控制页面的读取。比如通过 getUserInfo 接口返回的用户状态去判断当前是否需要开启 fetch 拦截,通过黑名单的方式去禁止掉在某些状态下启动 PWA,代码如下所示:
self.addEventListener('fetch', function (event) {
event.respondWith(
caches.match(event.request).then(
(response) =>
response ||
fetch(event.request.clone()).then(function (httpRes) {
if (/getUserInfo/gi.test(event.request.url)) {
httpRes.json().then((res) => {
//do something
});
}
return httpRes;
})
)
);
});
经过上述处理,原来只要访问过风控首页,再访问同域名下的所有状态,都会经过 serviceWorker 拦截,如下图所示:
经过修改之后,在其他用户状态页面上可以禁止掉 PWA 的拦截,如下图所示:
3.4 图片处理
现如今网页中图片使用了大量的图片,能够给用户带来更为直接的视觉冲击,作为 PLUS 会员的入口,更是展示了大量的商品图,如何在图片处理上下功夫,我们也用了些心思。 PLUS 会员页面中的图片使用的都是京东图片系统,其中让我们眼前一亮的是,可以在 url 上配置参数来处理图片,譬如说:
http://img30.360buyimg.com/test/s720x540_jfs/t2362/199/2707005502/100242/616257ce/56e66b21N7b8c2be8.jpg
中 s720x540_jfs ,向业务名和文件地址间添加的参数,表示把图片缩放到宽 720、高540;
直接向url后面添加 webp 后缀,则转成访问 webp 格式的图片,这样访问服务器端的图片,就可以像以下操作了:
function imgCut(item, str) {
if (/(((img){1}\d{2})|m{1}).360buyimg.com/.test(item)) {
if (str) {
item = item.replace('jfs', 's' + str + '_jfs');
}
if (check_support_webp()) {
return item + '.webp'; //需要判断支持webp的情况下写上webp后缀
} else {
return item;
}
} else {
return item;
}
}
按照上述方式,请求服务端的图片,既可以进行图片的裁剪,保证页面中图片的尺寸一致,并且还可以无缝转换 webp 图片,真是研发一大利器!注意的是,该功能是处理的向服务端请求的图片,而不是前端本地提供的图片。
总结
回首望去,PLUS 会员项目从最初的懵懂,转眼间已经汇集了数十个复杂逻辑的页面,迭代了多个版本,建立了数个分支。最近从项目中脱离出来,才发现缺少从一个大局上把握项目的走向,保证一个项目能够历经迭代需求,PLUS 会员项目仍有很多待以完善的地方,在此期间也收到了一些团队的大力支持和很好的建议,之后我们会继续打磨下去,建立完善的机制,提高代码质量,完善用户体验,为 PLUS 会员保驾护航。
最后,用我最喜欢的一句话结尾 “我虽只身前行,仿佛率领百万雄兵。身在井隅,心向星光,眼里有诗,自在远方!”,对生活,对未来充满希望,与君共勉之~
