

append and copy
通过copy或者append的方式减少临时切片的创建,减少内存的分配
下面代码使用了临时切片的方式,
var a []int
a = append(a[:i], append([]int{x}, a[i:]...)...) // 在第i个位置插入x
a = append(a[:i], append([]int{1,2,3}, a[i:]...)...) // 在第i个位置插入切片
使用copy的方式
a = append(a, x...) // 为x切片扩展足够的空间
copy(a[i+len(x):], a[i:]) // a[i:]向后移动len(x)个位置
copy(a[i:], x) // 复制新添加的切片
另外,使用0切片减少空间分配,
func TrimSpace(s []byte) []byte {
b := s[:0]
for _, x := range s {
if x != ' ' {
b = append(b, x)
}
}
return b
}
线程栈说明
首先,每个系统级线程都会有一个固定大小的栈(一般默认可能是2MB),这个栈主要用来保存函数递归调用时参数和局部变量。固定了栈的大小导致了两个问题:一是对于很多只需要很小的栈空间的线程来说是一个巨大的浪费,二是对于少数需要巨大栈空间的线程来说又面临栈溢出的风险。针对这两个问题的解决方案是:要么降低固定的栈大小,提升空间的利用率;要么增大栈的大小以允许更深的函数递归调用,但这两者是没法同时兼得的。相反,一个Goroutine会以一个很小的栈启动(可能是2KB或4KB),当遇到深度递归导致当前栈空间不足时,Goroutine会根据需要动态地伸缩栈的大小(主流实现中栈的最大值可达到1GB)。因为启动的代价很小,所以我们可以轻易地启动成千上万个Goroutine。
原子操作+互斥锁构造单例模式
atomic.AddUint64函数调用保证了total的读取、更新和保存是一个原子操作。
互斥锁的代价比普通整数的原子读写高很多,在性能敏感的地方可以增加一个数字型的标志位,通过原子检测标志位状态降低互斥锁的使用次数来提高性能。
type singleton struct {}
var (
instance *singleton
initialized uint32
mu sync.Mutex
)
func Instance() *singleton {
if atomic.LoadUint32(&initialized) == 1 {
return instance
}
mu.Lock()
defer mu.Unlock()
if instance == nil {
defer atomic.StoreUint32(&initialized, 1)
instance = &singleton{}
}
return instance
}
我们可以将通用的代码提取出来,就成了标准库中sync.Once的实现:
type Once struct {
m Mutex
done uint32
}
func (o *Once) Do(f func()) {
if atomic.LoadUint32(&o.done) == 1 {
return
}
o.m.Lock()
defer o.m.Unlock()
if o.done == 0 {
defer atomic.StoreUint32(&o.done, 1)
f()
}
}
基于sync.Once重新实现单件模式:
var (
instance *singleton
once sync.Once
)
func Instance() *singleton {
once.Do(func() {
instance = &singleton{}
})
return instance
}
make(T,args) 说明
make(T,args)返回初始化之后的 T 类型的值,这个值并不是 T 类型的零值,也不是指针 *T,是经过初始化之后的 T 的引用。make() 只适用于 slice、map 和 channel。
是不是T结构体拷贝?
项目初始化顺序
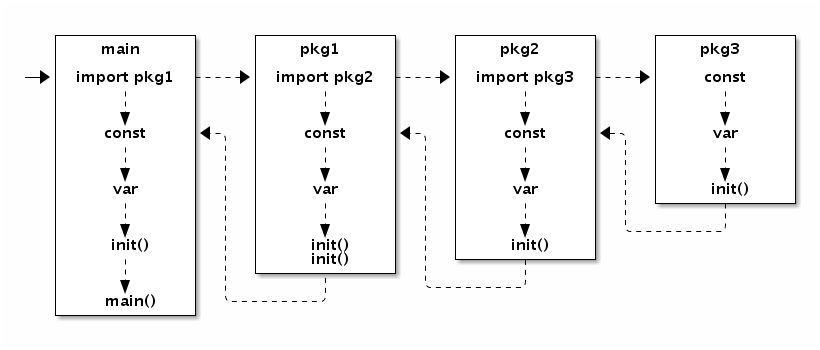
变量初始化
- 函数内:
从左至右,从上至下。
- 函数外(同一package):
未被引用的先初始化,引用了其他变量的后初始化。
包文件初始化
1、同一包的文件的初始化规则:包内所有的常量 先于 包内所有的变量 先于 包内所有的init函数。
2、不同的包,按照引用和被引用的关系,被引用的包初始化完成(包括常量,变量,init函数执行完成),再初始化引用方。
3、在main.main函数执行之前所有代码都运行在同一个Goroutine中,也是运行在程序的主系统线程中。如果某个init函数内部用go关键字启动了新的Goroutine。的话,新的Goroutine和main.main函数是并发执行的。
具体示例代码参看下面两篇文章:
顺序一致性模型,所见非所得
同一个goroutine中代码是顺序执行的,但是该goroutine对于另外的goroutine却是未可知的。
var a string
var done bool
func setup() {
a = "hello, world"
done = true
}
func main() {
go setup()
for !done {}
print(a)
}
上面的示例代码中,存在两个goroutine,对于main goroutine,done = true可能比a = "hello, world"先执行,或者更加糟糕的是,setup goroutine的执行情况对于main goroutine根本就是不可见的。
所以,在Go语言中使用chan的方式在不同的goroutine中去通信。
接口变量和nil的比较
Go语言中的错误是一种接口类型。接口信息中包含了原始类型和原始的值。只有当接口的类型和原始的值都为空的时候,接口的值才对应nil。其实当接口中类型为空的时候,原始值必然也是空的;反之,当接口对应的原始值为空的时候,接口对应的原始类型并不一定为空的。
func returnsError() error {
var p *MyError = nil
if bad() {
p = ErrBad
}
return p // Will always return a non-nil error.
}
如上,变量p的值为nil,但是p的类型不为nil,所以p不为nil。
